deeplearning笔记4:卷积神经网络
卷积神经网络
为什么要用卷积神经网络-卷积神经网络的作用
防止model overfitting
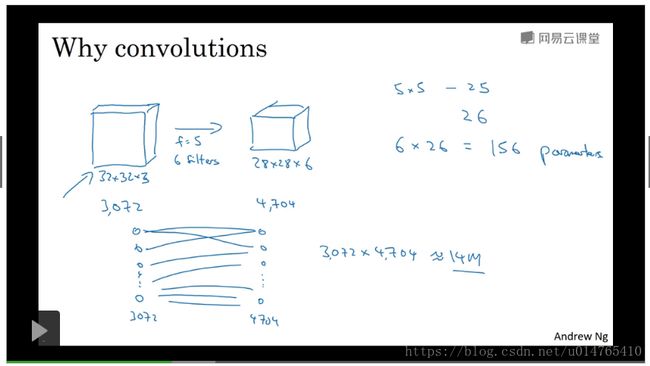
在计算机视觉中,input vector往往维度很高,将其直接应用于neural network很有可能会造成overfitting,以下图为例:
在“cat recognition”中,cat image为64643的vector,将其转换到一维空间,则其维度为12288,如此高维的input直接输入neural network会造成overfitting现象。

在“卷积神经网络”中,可以用convolution operation对原始input进行降维,从而防止neural network过拟合。
边缘检测
convolution operation除可用于“降维”,还可用于“边缘检测”,如下图所示:
在人脸识别中,convolution operation可以识别人脸的局部边界——人脸局部——整个人脸;
在object recognition中,convolution operation可以识别image中“垂直部分”和“水平部分”;
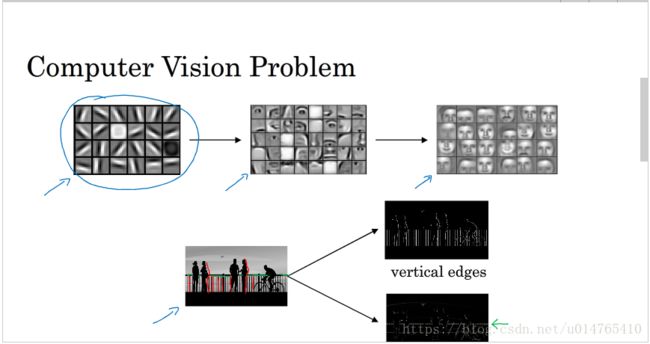
利用convolution operation进行边缘检测的原理如下:
- 首先,先介绍一下什么叫“convolution operation”:
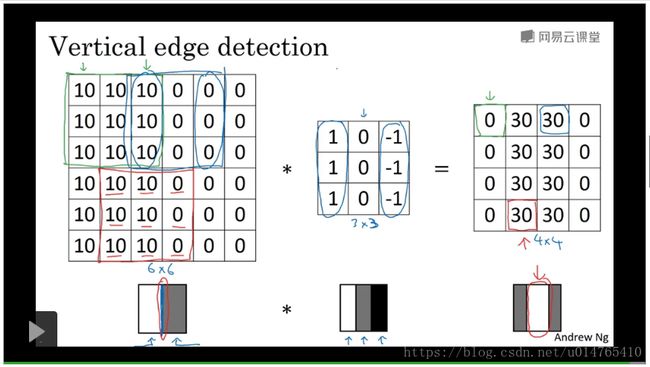
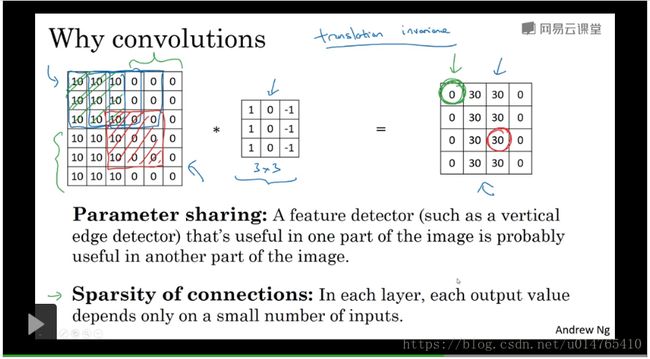
下图中,最左边的matrix为input,中间matrix为filter,最右边matrix为output。convolution operation是指将filter matrix映射于input matrix,并且将他们的对应元素相乘后求和,将最终结果作为output,如:说先将filter matrix与input matrix在upper-left 元素上对齐:其convolution operation为:
110+110+110-110-110-110=0,则output[0][0]=0。将filter matrix在input matrix上依次移动,求convolution operation value作为相应位置的output。 - 利用convolution operation进行边缘检测
如下图所示:
我们首先定义在input matrix中,元素=10,表示“白色”,元素=0,表示“灰色”。灰色与白色之间的那个边界即为我们要检测的“边界”。
将filter在input上进行映射,得到output,可以看出,output为“中间白色,两边灰色”的image,其中间的那条白色条纹,即为我们要检测的“边界”。
利用convolution operation进行边界检测的关键在于,选好filter,用其过滤出input的边界。
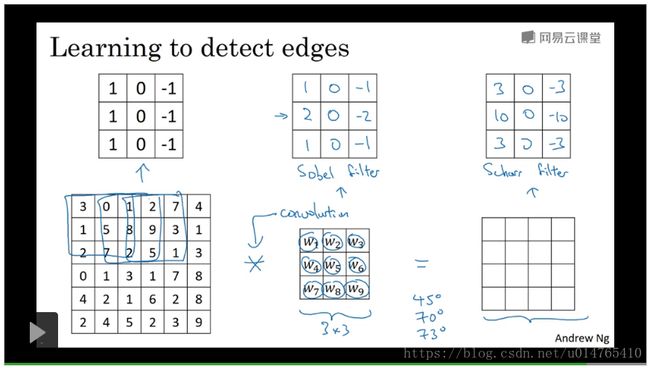
值得一提的是,convolution operation除可进行“垂直检测”以外,也可进行任何“角度的检测”,具体方法如下图所示:
将filter中的各个元素设为未知数w_i,利用backward propagation求解参数w_i,使得output为某个角度的“边缘检测”。
卷积神经网络的基本组成部分-convolution operation
在上一节中已经讲了convolution operation的原理,本节主要讲述一下convolution operation涉及的几个过程:
- padding
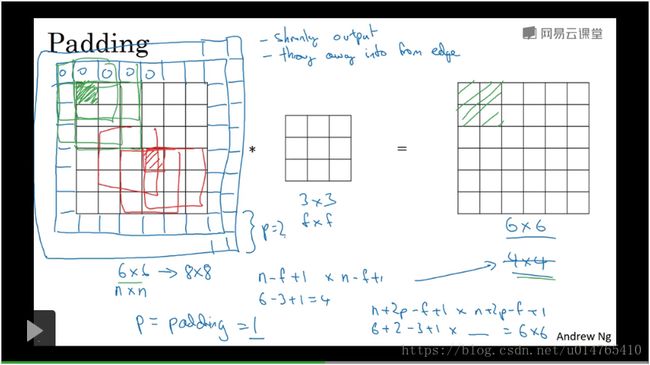
利用原来的convolution operator有两个缺点:1)shrink output from 66 to 44;2)throw away information from edge since the corner pixel in image use less compared to the center pixel;
To solve this,we can use padding;
Padding的目的是向image边上加border,从而可以抵消上述两个downside的负面影响;
对于(nn) imgae 利用 (ff) filter进行convolution operation ,得到(n-f+1 * n-f+1) image;而如果使用Padding后,得到的imgae为( n+2p-f+1 * n+2p-f+1);
padding具体操作如下图所示:
向最左边的input matrix加入padding,实际上就是在其边缘在加入几层border,从而可以使output与input具有同样的维度,且,可以使原input的边缘value能够得到更好的应用(如果不加padding,input边缘元素只能被用一次,而加入padding后,在执行convolution operation时,input边缘元素可以被用多次。)
- stride
在上一节(边缘检测)中执行的convolution operation,filter的移动步长为1,在实际应用中,我们可以让filter在input matrix上一次移动n个步长,下图为stride=2的情况:

- summary of convolutions
下图为(n,n)的image经过filter=(f,f),padding=p,stride=s convolution operation后output的维度(note that:当计算出的output的dimension为小数时,向下取整):

- convolution operation中的filter
convolution operation中的filter有3种:CONV,pooling,FC,通过这3种filter分别可以得到对应的3中layer:CONV,pooling,FC:
(1) conv filter:在这种filter中,会将filter与input对应元素相乘然后求和。
(2) pooling filter:有两种,分别为Max pooling和Average pooling,Max pooling中,是将filter对应的input部分的元素中的最大值作为output返回,如下图所示:
Max POOL之所以效果良好,是因为:假如将input看成feature,Max POOL可以将最显著的feature留下,从而最大的保留Image的信息。
比起average pooling,max pooling使用更频繁。

在Average booling中,是将filter对应的input部分的元素的mean作为output返回。如下图所示(实际中,除了将其应用于image compression外,average pooling很少被使用):

在pooling filter中,没有参数weight,只有hyperparameter:filter size,filter stride,这些超参数可以通过cross-validation选出最优值,下图为summary of pooling filter:

(3) FC(fully connected) filter:它首先将input展开为一个1维向量(m,1),利用FC filter weight(n,m),可以将展开的input从(m,1)转为(n,1)。它实际上就是一个linear model。
note that:与FC相比,CONV filter具有更少的参数,能够有效防止overfitting,如下图所示:
上述3种filter中,pooling filter只有hyperparameter:stride,filter size,可以通过cross-validation获得最优值。而另外两种filter,FC,CONV,其参数的求解可以通过gradient descent(GD/Adam/RMS prop)进行。
卷积神经网络cost function
在convolution neural network中,其cost function为“最大似然函数”,如下图所示:

convolution operation on volumes
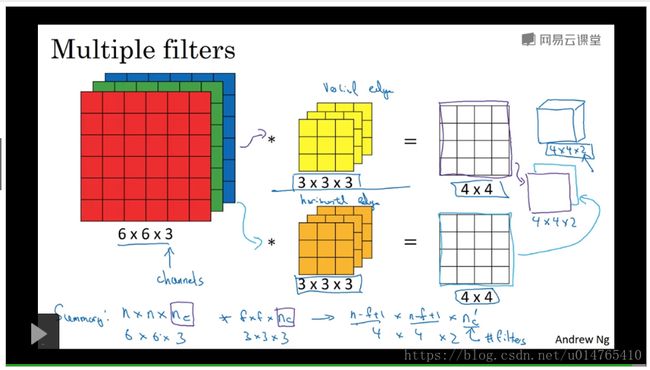
前面讲的convolution operation是在“二维空间”进行的,这节讲的convolution operation是在“三维空间”进行的,它与前面所讲的convolution operation操作相近,只是filter也从二维上升到了三维,如下图所示:
对于一个(6,6,3)的input,其filter为(n,n,3),二者的convolution operation,即:将filter与input相应位置的元素相乘然后进行加法运算,得到最终的output。
下图中,给input运用了2个filter(3,3,3),每个filter会得到一个output(4,4,1),将两个output叠加,即为最终的输出(4,4,2)。
单层卷积神经网络
- 单层卷积神经网络
卷积神经网络与普通的神经网络类似,每层hidden layer均包含以下几个要素:weight,bias,input,z,acitve function g,a。
z = w * x + b
a = g(z)
在卷积神经网络中,weight即为filter,如下图所示:将input与filter进行convolution operation,得到z值,然后,将z值输入active function(ReLu),获得active value a。

- summary of notation
下面列出了 l 层layer的各个notation:

卷积神经网络示例
- 简单的ConvNet example
以下PPT示例了一个简单的convNet:(assuming network is a cat recognition classifier)
Input matrix: 39393
Output matrix:7740
得到Output以后,将matrix展开, 为1维vector,利用该vector 拟合 logistic/softmax function,得到最终的一个输出结果y;通过y即可判断image的类别;
Note that: softmax function is a generalization of logistic function;
- 结合了CONV,FC,Pool 3种filter的卷积神经网络
下述PPT为识别(0~9)的分类器:
下述PPT是一个common 卷积神经网络,他结合了CONV,POOL,FC三种layers,最后用softmax作为output function,得到(10,1)的vector,每一个元素代表一个类别的概率值;
Hyperparameter的选取,以及具体设定可查看文献 ,从别人的设定中吸取经验;


上述PPT为对此节中分类器的总结:
Note that:If activation size drops too quickly ,it is not good for neural network performance;
Technical note on cross-correlation VS convolution
在前几节中,我们所讲的convolution operation,filter都不会进行mirring action(flipping),严格来讲,在教科书中,这种操作叫做cross-correlation;
如果在进行convolution operation之前,首先将filter 翻转,然后在用flipped filter进行convolution operation,则可以将这种操作严格定义为convolution operation。这种filter flipping使得convolution operation有以下性质:(AB)C=A(BC);这种操作在“信号处理”中,可以取得better performance,但是In deep learning ,一般不需要刻意进行filter flipping,也可取得good performance;
filter flipping操作如下图所示:
首先将fiter在“垂直和水平方向”进行flipping,然后,对input和flipped filter进行convolution operation。

深度卷积网络:实例探究
本节主要讲解一些经典的“卷积神经网络”(如下图所示),为读者构建自己的“卷积神经网络”提供一些参考。

经典网络
- LeNet - 5
其结构为:input -[conv filter, average pool filter, conv filter, average pool filter, FC, FC] - output
各个filter的size,stride,active function如下图所示:

- AlexNet
比起LeNet-5,AlexNet更加bigger,其具体结构如下图所示:

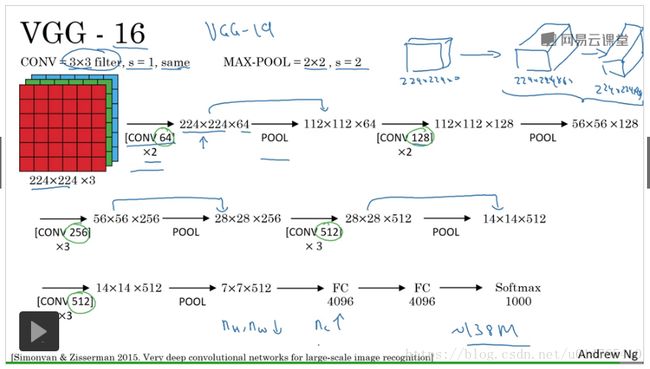
- VGG -16
VGG-16中16表示有16个Layer有weight;
The number of channel goes up :64,128,256,512… by conv
The height and width of input goes down:224,112,56,28,14…by POOL
其parameter is up to 138 million;这样庞大的network即便放在当代也是非常庞大的;
VGG-16具体结构如下图所示:
在VGG-16中,conv filter size = 33,stride=1,padding使得convolution operation前后的input,output具有相同的维数。MAX-POOL size=22,stride=2;
[CONV 64] *2表示:前2层layer都是利用conv filter进行convolution operation,且filter 的channel number=64;
残差网络
-
残差网络块的构建
在普通的神经网络(plain neural network)中,要训练一个deep neural network是很难的,因为,deep neural network可能会导致weight exploding或weight vanishing的现象。"残差网络"能够很好的解决“deep neural network”中weight exploding or vanishing的现象。
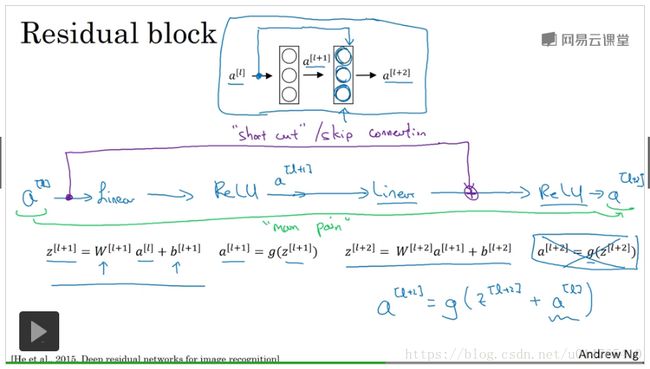
残差网络:是由残差网络块 构成的,残差网络块 的构建如下:
在普通的神经网络中,a[l]到a[l+2]的构建过程如下:
z[l+1]=w[l+1]a[l]+b[l+1],a[l+1]=g(z[l+1]),
z[l+2]=w[l+2]a[l+1]+b[l+2],a[l+2]=g(z[l+2]);
在残差网络中,a[l]到a[l+2]的构建过程如下:
z[l+1]=w[l+1]a[l]+b[l+1],a[l+1]=g(z[l+1]),
z[l+2]=w[l+2]a[l+1]+b[l+2],a[l+2]=g(z[l+2]+a[l]);
可以看出,普通神经网络和残差神经网络的主要区别在于a[l+2]的构建,这种差异,可以防止在构建深层神经网络时,发生weight exploding or vanishing现象。
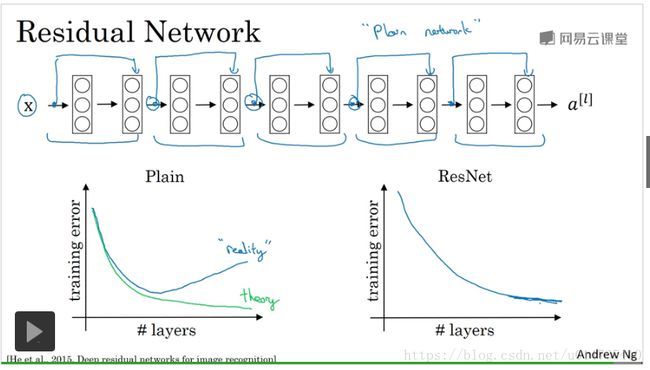
上图讲解了残差网络块的构建方法,下图中,给出了“普通神经网络(plain neural network)”和“残差神经网络”,随着layer 层数的增加,training error的变化情况:
如图所示:在plain neural network中,随着layer数量的增加,training error是呈现“先降低后增加”的趋势的,这与theory并不一致。而在ResNet中,随着layer数量的增加,training error是一直呈现“降低”趋势的。
造成plain neural network中,training error先降后增趋势的主要原因,是因为,构建“深层网络”的难度会逐渐加大。
-
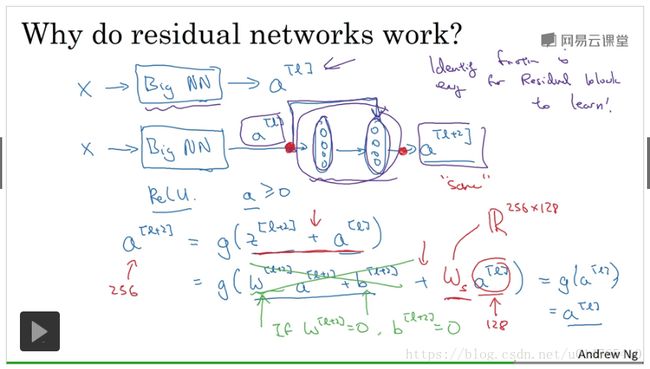
为什么使用残差网络能够构建“深层神经网络”
“残差网络”之所以能够构建“深层神经网络”,是因为,随着layer数量的增加,对于plain neural network来说,为了不hurt neural network的performance,需要通过调节weight来使得a[l+2]与a[l]相同,这对于plain neural network来说,是很难办到的。而在“残差网络”中,为了使a[l+2]与a[l]相同,我们可以根据公式:a[l+2]=g(w[l+2]a[l+1]+b[l+2]+a[l]),使得w[l+2],b[l+2]都等于0,这样:a[l+2]=g(a[l]),由于active function是一个ReLu,因此,a[l+2]=g(a[l])=a[l]。“残差网络”利用这种办法,可以防止在layer较多时,performance下降,从而可以构建一个“深层神经网络”。
在上述公式:a[l+2]=g(z[l+2]+a[l])中,要保证z[l+2]和a[l]具有相同的维度,方法具体有如下两种:
1、可以利用ws矩阵来保证z[l+2]和ws*a[l]具有相同的维度,ws可以是未知数,用gradient descent求得;(ws中,多处的部分可以用0来填充,相当于0 padding)
2、使用“same convolution(即:卷积前后,维度相同)”,来保证z[l+2]和a[l]具有相同的维度。
-
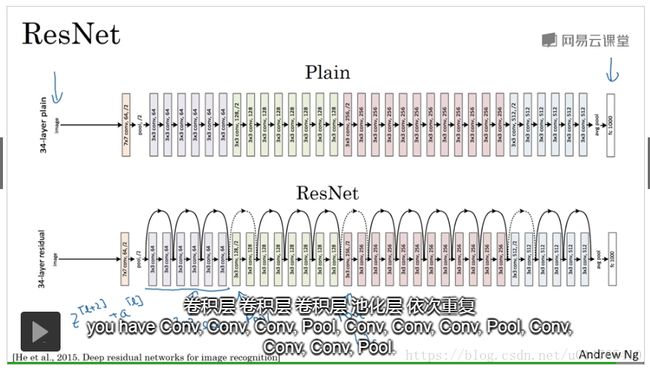
将plain neural network变为ResNet
将plain neural network转化为ResNet,只需要每隔两层,将a[l]添加与a[l+2]的计算中,即:a[l+2]=g(z[l+2]+a[l]);(需确保z[l+2]和a[l]具有相同的维度)
1*1 convolution(network in network)
11 convolution的实质,就是将一个number乘到各个input element上,并对channel方向上的各个“multiplication value”相加。
11 convolution的主要作用是控制output的channel dimension。
如下图所示:对于一个 6632的input,可以通过1132的filter,将其output的dimension降维:661,从而降低“电脑计算量”。
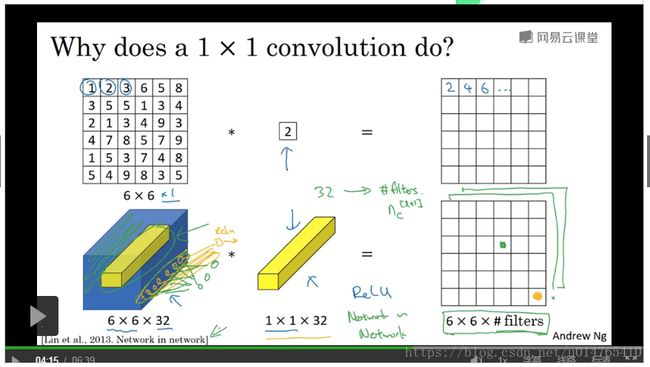
如下图所示,通过11 convolution可以给出任意channel的output。
下图中:2828192 input,与32个11192 filter,进行convolution operation之后,得到一个282832的output。
谷歌的inception network中便运用了11 convolution,具体看下节inception network。

inception network
inception neural network中,会利用11 convolution来降低input channel,从而减少计算量,如下图示:
将2828192 input,利用各种filter,得到output layer,最后将这些output layer 堆叠起来,便得到最终的output。在这个过程中,存在一个问题:input channel很大,因此,需要花费很多的计算量。为了降低计算量,我们可以通过引入11 convolution来解决。
(convolution operation中的各个数值如图示)

下图为引入11 convolution后,卷积神经网络的计算过程,从图中可以看出,引入16个11*192 convolution后,可以将input channel降低至16,在这个基础上,进行各种convolution operation,将极大的降低计算量。

上图中,展示了一个inception network block,其具体由几部分构成:1、利用11 convolution对input channel进行降维;2、对降维后的input进行各种convolution operation。
下图展示了一个简单的inception neural module:其convolution operation中,整合了很多的11 convolution的使用。
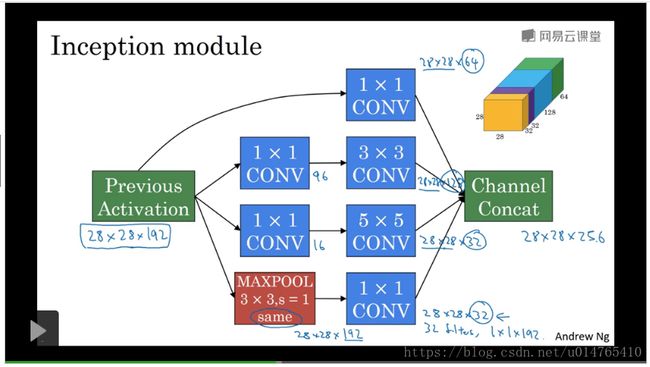
下图中为一个完整的inception network:
该inception network是由上述inception network module组合而成的,在这个inception network中,很多hidden layer直接应用了FC filter — softmax(output可以用于预测input的label)。这种做法可以使得inception在不同的layer 深度进行label的预测,从而有效防止overfitting。

使用开源的实现方案
利用github中已训练出的一些neural network,作为你训练工作的“初始点”,可以,帮助你更快的得到fitted model。此外,利用github中的这些neural network,也可以展开“迁移学习”。
迁移学习
可以将github中的一些“开源network”,应用于“迁移学习”中:
1、“小型数据”的“迁移学习”
将softmax function的output设为现在的number of classification label ,保持其它的neural network 不变。
在进行transfer learning时,可将原input -> last layer of network 的计算值保存在disk上,然后,根据最后一层Layer计算得出的feature vector,利用Gradient descent计算softmax function的参数。用于predict;
2、“中型数据”的“迁移学习”
可以冻结前几层layer的weight,修改softmax function。然后,训练后边的network的参数:1)后边network的训练,其初始值可以选用原来的weight。
2)后边network,可以使用自己自定义的network,然后,利用GD训练weight。
3、“大型数据”的“迁移学习”
可以使用原训练的weight,作为初始值,训练network。
Ps:记得修改softmax function;
在computer vision中,可利用transfer learning ,利用别人的code去训练自己的模型,往往能达到很好的效果;
数据扩充
在“计算机视觉”中,可用的training dataset往往较小,针对这种情况,可以用以下提及的“数据扩充方法”增加training dataset的size。
- 对于一个Image,可以通过mirroring,cropping等手段,增加数据量,除此以外,还可利用right-hand of PPT 去增加数据量,但是这些方法在实际中应用较少,因为,比较复杂;

- In practice,R,G,B are drawn from some distribution。(PCA color augmentation)。Color distorting make your algorithm more robust to color changes.

- 如果你的数据量很大,且存储在harddisk上,则“数据传入CPU,进行distort”,以及“training”这两个step,可以在不同的thread中进行,通常这两个不同的step可以进行“并行计算”。

在data augmentation中,也有一些hyperparameter to tune,you can use open source ,but if you want to have more invariance in data augmentation ,you can also tune hyperparameter by yourself。
计算机视觉现状
- 计算机视觉现状:
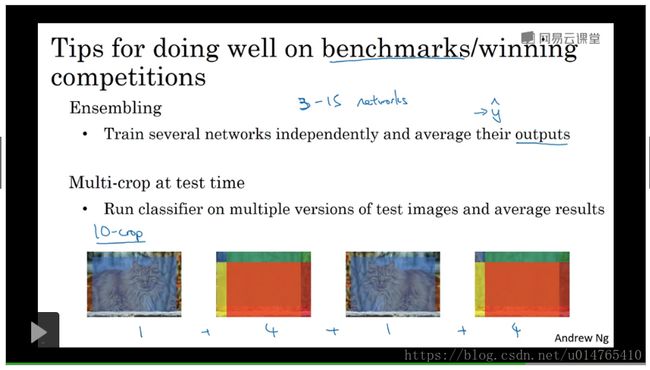
缺少数据来进行training,特别是对于object detection而言,更是如此。在数据量非常有限的情况下,常常需要hand-engineering,来辅助training。 - tips for doing well on benchmarks/winning competitions
如果想做benchmark,或者win competition,以上两个建议可采纳:1)训练多条神经网络,然后将其output平均,得到最终的output结果。这往往能够提高准确率1%-2%。但是这样,非常消耗computer memory,computation,因此,不适用于实际的生产系统。
2)通过data augmentation 增加测试集数量(一种augmentation,形成一个测试集),平均各个测试集的结果,获得最终的精确度。这个相比1)使用的计算资源和内存资源较少,可以用于实际的生产系统中。 (如下图示)
- use open source code
在训练自己的classifier,可以利用别人的code,architectures,pretrained models,open source implementations。(如下图示)

目标检测
目标定位
利用image classification可以识别“image”中的object;
而classification with localization能够锁定要识别的object,进而用于“目标检测”;

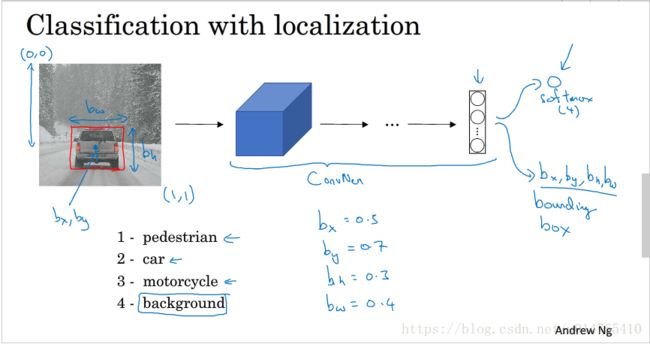
以下图为例说明:
在目标检测中:
首先将image中的object进行锁定,如图image中的red bound;
然后对锁定的object 进行classification;
在下述例子中,object的类别有4中,pedestrian,car,motorcycle,background;
用于锁定object的red bound可以用坐标表示:bx(中心点x坐标),by(中心点y坐标),bh(red bound的高度),bw(red bound的宽度);
Pc用于表示image中是否有object。
将image input输入 model,即可得到上述8个output的值,具体,见下一张PPT。
如下PPT中,展示了model的output{Pc,bx,by,bh,bw,C1,C2,C3},其中Pc={0:image中没有object,1:image中有object},bx,by,bh,bw为红框坐标值,C1,C2,C3为1时,分别表示image中存在pedestrian,car,motorcycle。
在“目标检测”中,cost function可以使用如下形式:
1)对于不同的output,其cost function的形式不同:
Pc:可以用logisitc/max likelihood;
bx,by,bw,bh:可以用“squared error”;
C1,C2,C3:可以用softmax/max likelihood;
将3种形式的cost function相加,即为model的cost function.
这种cost function在实际中比较常用;
2)除使用上述形式的cost function以外,对于不同的output,也可以统一使用“squared error cost function”。
在cost function计算中,如果:
Pc=1,则其他的output对于cost function比较重要,需要关注;
Pc=0,说明image中没有object,其他的output don’t care。

特征点检测
目标检测,可以应用于很多实际场景,如:
识别人的表情:通过标识人脸的关键部位(landmark)坐标,来判断一个人此时此刻的表情;
计算机图形化:如给人的头部加上一顶皇冠:同样的,首先识别人脸landmark的坐标,然后,根据该坐标值,判断皇冠的具体位置(坐标);
判断人现在的motion:标识人体关键部位的坐标,如:肩,手臂关节等,通过landmark的坐标值,判断人此时此刻的动作。
具体操作步骤:
step1:构建trainingdata{X:image input,y:人工标记的image中各个landmark的坐标}
step2:将training data投入“卷积神经网络”,训练network的参数;
step3:将一个test sample input投入训练好的“卷积神经网络”,即可得到test sample中各个landmark的坐标值。进而可以根据这些坐标值,判断image中人的面部表情,进行计算机图形绘制,人的motion等等。
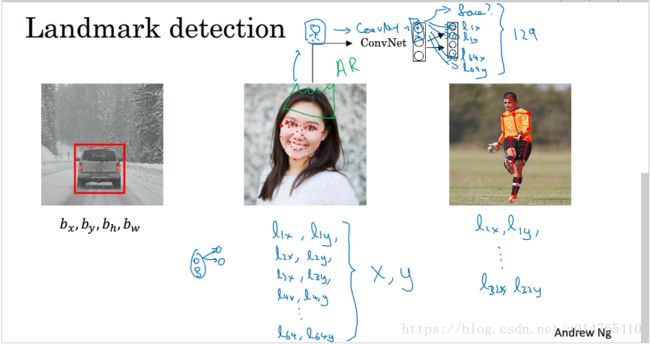
目标检测(sliding window detection)
我们执行目标检测的步骤如下:
step1:利用一个定常的bounding box,在image中移动,形成一个个小的image(cropped image);
step2:将这些cropped image输入已经训练好的ConvNet,判断其是否为object。
下图为car detection task:将image 以指定体积 切成多个sub_image,然后,将这些sub_image送入训练好的ConvNet,判断其是否为car。

在实际工作中,我们要将不同size的bounding box在image中以不同的sliding stride移动,从而得到若干sub_image,将这些sub_image送入以训练好的ConvNet,判定这些sub_image是否为object。
在实际应用中要注意,sliding stride不能太大,否则,可能会漏掉object。
由于要以不同size的bounding box游走整个image,并且将这些sub_image送入ConvNet中进行预测,因此,即便只是预测一个image,也会花费很大的计算量。为了克服这个难点,学者提出了“卷积的滑动窗口实现”。

卷积的滑动窗口实现
在上一节中,我们提到,sliding window object detection的使用,会花费很多的计算量。为了解决这一问题,学者提出了“卷积的滑动窗口实现”,其核心思想是:将原input,利用ConvNet,进行降维预测,每一个output代表一个bounding box image的预测结果,通过这种方式,可以一次性的对image上的所有bounding box image进行object detection,从而大大降低了计算量。
具体实现,如下图所示:
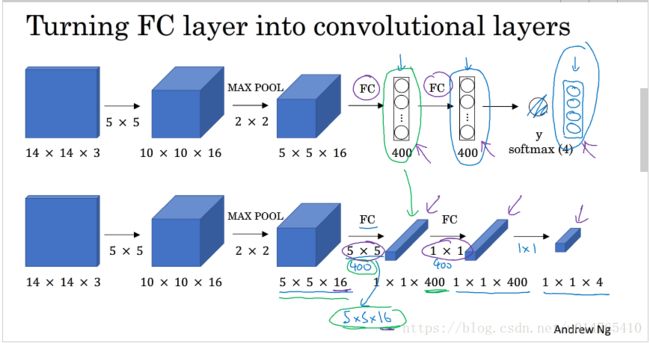
- 首先,先介绍一下FC layer 向 convolutional layer的转化:
PPT中,upper ConvNet中最后的几层layer是由FC实现的,below ConvNet中,将FC实现部分,改为通过CONV实现,具体讲:
第一个FC layer的CONV实现:是通过400个5516 filter实现的;
第二个FC layer的CONV实现:是通过400个11400 filter实现的;
最后的output:是通过4个11400 filter实现的;
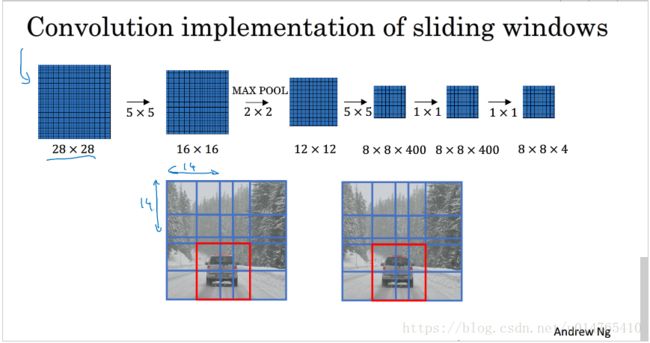
- 其次,介绍一下“卷积窗口的实现方式”
下PPT中,FC layer的实现,均采用convolutional way。
我们来看中间的那个ConvNet:
首先,将image的bounding box设定为14*14,其sliding stride为:2,因此,在图中image中,会获得4个bounding box sub_image,如果按照“sliding window object detection”的做法,需要将这些sub_image投入训练好的ConvNet,从而判定各个sub_image中是否有object。但是在“卷积窗口滑动”种,该ConvNet会直接输出4个output,分别用来表示4个bounding box sub_image中的object检测结果。图(中)output中的upper left表示upper bounding box的object detection结果,upper right表示upper bounding box的object detection结果,below left表示below left bounding box object detection结果,below right表示below right bounding box object detection结果。
缩小bounding box size,从而得到更多的sub_image,根据sub_image的数量n,将ConvNet的输出设定为相应的n个output。这n个output即为对应的sub_image的object detection结果(如图(下))。

以car detection为例说明“卷积窗口实现”的应用:
step1:将image用bounding box切分成n个sub_image。
step2:以image为input,构建ConvNet结构,训练ConvNet,使得其n个output分别代表n个sub_image的object detection结果。通过这个步骤,可以避免independently将sub_image输入ConvNet,进行object detection,从而大大降低了算法的计算量。
虽然“卷积窗口的实现”与“sliding window object detection”相比,能够极大降低计算量,但是,他也有一个缺点,即:The position of bounding box is not that accurate(边界框的位置无法精确定位)。针对这一问题,学者提出了一种解决算法:YOLO algorithm。
Bounding box 预测
通过YOLO algorithm可以得到the accurate position of bounding box。
下面介绍YOLO的核心思想:
YOLO的核心思想是将image切分成nn份sub_image(下图n=3),利用一个ConvNet同时预测nn个sub_image的label。
在下图中,其label为81的vector(Px,bx,by,bh,bw,c1,c2,c3)。
因此,如果将image切分成33的grid,ConvNet的output将为338,每个118为一个sub_image的label的预测值。在上述预测过程中,整个image为ConvNet的input,ConvNet的output为338 matrix。
与“sliding widow object detection”相比,YOLO能够更精确的定位bounding box的位置,而在"sliding window object detection"中,由于bounding box一直slide with a specific stride,因此无法准确定位某个bounding box的具体位置。除以以外,YOLO能够一次性的预测出所有bounding box sub_image的output(like 卷积窗口实现),而sliding window object detection中,每个sub_image都需要单独进行预测,计算量庞大。
在YOLO中,有以下几个注意事项:
1)当object位于多个bounding box中,将object中心点所在bounding box作为其所在bounding box。
2)在YOLO算法中,通过将切分粒度细化,可以防止同一个bounding box中,包含多个object。

上述例子中,bounding box中object的编码方法如下:
假设每个bounding box的upper left point坐标为(0,0),below right point坐标为(1,1)。根据这个坐标系来判断object中心点的位置(bx,by),然后,根据object占bounding box边长的比例,来确定bw,bh。
其中,bx,by取值[0,1]。bw,bh取值可以>1,因为object的size可能大于bounding box edge size。

交并化 (IOU) intersection over union(used for evaluationg object algorithm or adding one element to make object detection algorithm work better)
- IOU的计算公式如下PPT,为:两个bounding box的intersection / 两个bounding box的union;
- IOU作用:
1.判断两个bounding box的相似度;
2.判断一个bounding box是否正确覆盖object(这种说法是假设我们知道一个image中object的正确的bounding box,然后估算algorithm中产生的bounding box是否能够正确覆盖object,当二者IOU>0.5时,被认为algorithm中的bounding box可以覆盖object);
在下一节“non-max suppression”中,我们将通过IOU去除多个覆盖object的bounding box,具体做法参见下节。

非极大值限值(non-max suppression)
在object detection中,可能存在这样的现象,即:多个bounding box都覆盖同一个object,为了避免overestimate object的数量,我们期望,每个object,只有一个bounding box,“非极大值限值”即可实现上述目的。
“非极大值限值”核心思想:
如下图所示,image中的两个car,均有很多bounding box覆盖他们,以image中right-hand car为例说明:为了使car 只有一个bounding box我们可以进行下述操作:
step1:利用ConvNet获得各个grid的probability;
step2:将probability
step4:选出一个最大的probability作为car的bounding box(记为B);
step5:计算其他的bounding box与B的IOU,当IOU>0.5(认为设定)时,将其他的bounding box去除;
step6:剩下的bounding box即为各个object的bounding box;

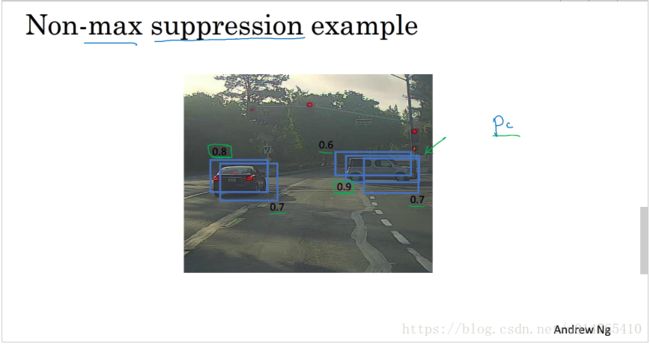
下述PPT为car detection的non-max suppression algorithm:

如果想要同时对image中的car,motor,pedstrain进行检测,则在进行Non-max suppression时,应该分开进行,即在上述algorithm的基础上在加一个for loop: for e in [car,motor,pedestrain],使得non-max suppression algorithm每次只针对一个object进行。
上述的object detection中,每个grid只能detect only one object,为了使得grid能够识别多个object,可以引入“anchor boxes”,如下节所示。
anchor boxes
anchor boxes的核心思想是:对于给定的grid,赋予其两个预先定义好的(在本节例子中为2个,实际也可为>2个)anchor boxes。
如下图所示:middle point所在的grid同时覆盖两个object, 为了能够同时识别这两个object,我们引入预先设定的anchor boxes{anchor box1:代表行人,anchor box2:代表car},并用这两个anchor boxes去与grid的bounding box相比较,与anchor box1相似,说明有pedestrain,与anchor box2相似,说明有car。针对anchor box,将原output修改为(16,1),前8个output代表anchor box1的检测结果,后8个output代表anchor box2的检测结果。
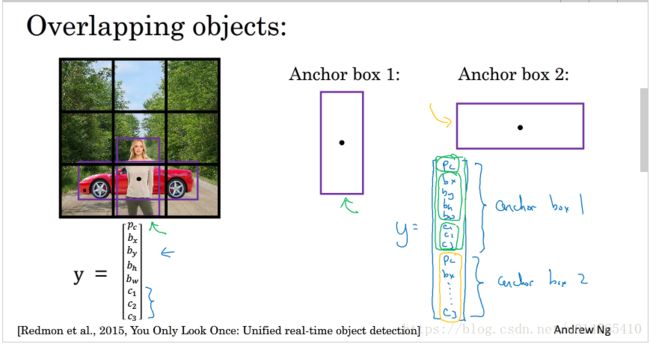
上几节中,我们所讲的object detection与anchor box object detection区别如下PPT所示:

Note that:
当一个grid中包含3个object,或者2个object都全部覆盖于一个grid时,又或者一个anchor box同时与2个object相符合时,anchor box object detection效果不好,需要采取一些机制,smooth这些problem。
anchor box可以人为设定(如上例中,认为设定表示“行人”和“车”的anchor box shape),也可以利用一些algorithm形成(自己查阅文献)。
YOLO算法
-
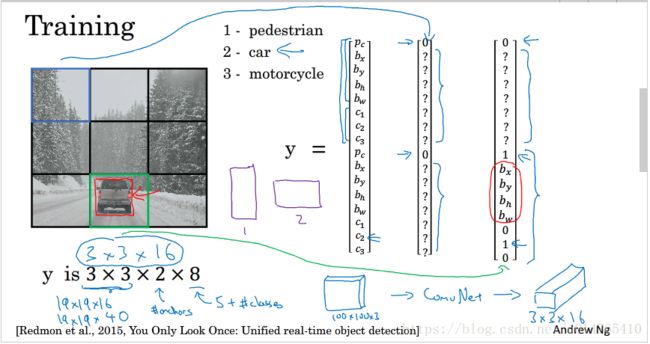
training
在利用YOLO算法训练时,我们要得到的是将training data切分为332 slice(In pratical :19195)(其中2指2个anchor box)后,每个slice的预测结果。
利用YOLO进行训练的具体操作如下:
step1:制作training data为:{X:1001003的image,y:人工标记好的332个slice的预测结果(3328)},target y包括每个grid下产生的bounding box的坐标,这些坐标由人工标注,用于training。
step2:利用这个training data训练一个ConvNet,使得输入一个test sample,输出为该image的332个slice的预测结果3328;
每一个111*8为一个grid cell(slice)的一个anchor box的预测结果;
需要注意的是,在output y 中,如果pc<0.5,说明没有object,则可不对其他的element进行预测;
解析:各个grid的output可以通过一个ConvNet实现,这些output包括(Pc,bounding box坐标,3个class的类别)。在每个grid上加入anchor box后,在进行人工标记时,会标注每个anchor box下的(Pc,bounding box,3个class的类别),note that,anchor box是人为设定的,给定一个grid时,其anchor box相当于是基于此grid的中心点,又设定了两个固定长宽的box。
根据上述的描述,每个grid的每个anchor box有一个bounding box,而object可能位于多个grid中,因而使得一个object可能有多个bounding box,为了解决这个问题,可以对每一类的object分别使用non-max suppression。
Note that:每一个grid的每一个anchor box的output为(Pc,bx,by,bh,bw,c1,c2,c3),因此,每个anchor box都会形成一个bounding box。这里bounding box也是output的一部分。
在训练阶段,训练样本中的image中各个grid的各个anchor box的bounding box的坐标是人工标注的。
-
prediction
在获得object detection的output之后,即可确定每个grid的probability,以及各个grid 的 bounding box,并且将概率值在IOU>0.5的bounding box中,选出probability最大的bounding box作为object的bounding box,其他的bounding box去掉。
上述解决方案为one object detection,对于multi object detection,在做non-max suppression时,需要对每一个object independently做,具体如下:
For loop(每一类object (如:car)):
在IOU>0.5的bounding boxes中,留下probability最大的那一个bounding box,去掉其他的bounding boxes,最终留下的bounding boxes即为各个car的bounding box。

-
output the non-max suppressed outputs
在anchor object detection中,对于每个grid会获得两个bounding boxes。
将image中所有的bounding box中probability对于每一类object:采用non-max suppression,从而确保每一个object只有一个bounding box。

RPN网络
在“sliding window object detection”中,你需要花费很多时间对没有object的blank grid进行预测,这显然是非常低效的,为了改进这一downside,学者提出了“region proposals”的概念,如下图(3)所示:
region proposals的核心思想是:切分出可能有object的区域,然后,对这些区域进行分别预测,判断其是否为一个object,并且预测其bounding box的坐标。

在上述的"region proposals"方法中,有几个可以改进的点(如下图所示):
普通的R-CNN步骤:1)切分出regions;2)依次对每个region进行分类,输出label+bounding box;
Fast-R-CNN:1)切分出regions;2)用“卷积窗口实现”一次性对所有regions做出预测,输出所有region的label+bounding box;
Faster R-CNN:上述Fast-R-CNN的一个limitation是,region segmentation耗时较长,为了解决这一limitation,学者提出“利用 ConvNet 来切分regions”;
Note that:即便是Faster R-CNN,其对test sample的预测依然需要分两步进行,相比YOLO algorithm,其依然需要花费较高的时间复杂度。
AndrewNg personal view:比起R-CNN,“卷积窗口实现”在computer vision中更具前景,因为,他不需要分步进行,只用一个ConvNet便可对test sample进行预测。

特殊应用:人脸识别和神经风格转换
什么是人脸识别
下边的PPT讲述了“face verification”和“face recognition”的区别:
Face verification:
input image,name,algorithm会验证所输入的image是否是声称的人。
Face recognition:
输入image,如果database中有这个人,algorithm将返回其name/ID。
与Face verification相比,Face recognition难度更大。在Face verification中,如果algorithm精确度为99%,可用。而在Face recognition中,如果algorithm精确度为99%,其对于Face recognition ,精确度依然太低,不可用。造成这种差别的原因是因为:在face verification中,input:comparision object=1:1,当algorithm精确度为99%时,其错误率仅为1%。而在face recognition中,input:comparision object=1:k,当algorithm精确度为99%时,其错误率为k%。k为face recognition中database的image数量。

One-shot学习
-
什么叫one-shot learning
for most face recognitions, you need to recognize a person given just one single image, or given just one example of that person’s face。
如下图所示:
在一个“人脸识别系统”中,database中每个人的image只有一张,要训练一个ConvNet,使得输入一张image,然后判断该image是否与database中的某一张image相似,这种做法是非常不可取的,原因如下:1)本身拥有的training data size过小;2)如果新来一个同事,database将又增加一个image,那么,我们将要重新训练PPT所示的ConvNet,效率过低。

-
One-shot learning的正确打开方式
一种学习One-shot learning的方式是:设计一个d(image1,image2)公式,计算像个image的距离,距离越小,说明相似度越大,越有可能是同一个人。
如下图所示:
对于给定的input image,计算其与database中的image2的d(image1,image2),如果d
Siamese network
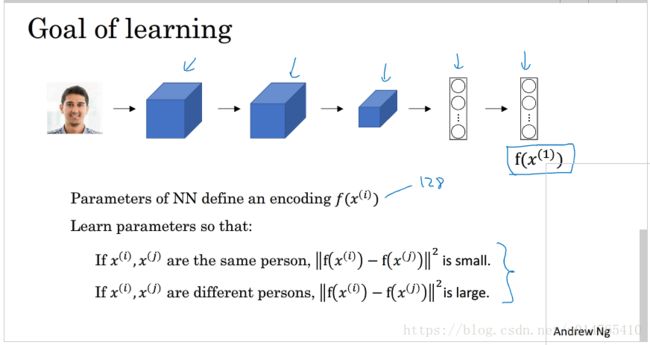
Siamese network的主要工作是,对输入的image重新编码,使得该编码最能代表image。其内在机理如下图所示:
给定一个Siamese network,当输入x(i)时,其输出x(i)的编码f(x(i))。则两个image x(i),x(j)之间的距离可用 ||f(x(i))-f(x(j))||2 表示。

- Siamese network参数求解方法
Siamese network的参数求解主要是根据下述规则进行的:
1、对于给定的两个image,如果两个image为同一个人,则使得:||f(x(i))-f(x(j))||2尽可能的小;
2、如果这两个image为不同的人时,则使得:||f(x(i))-f(x(j))||2尽可能的大;
根据上述规则,利用backward propagation,即可求解Siamese network的parameter。
现在,我们已经知道Siamese network 参数的大致求解思路,但是,在实际应用中,其“目标函数”如何定义呢?下一节将为你解开答案。
Triplet损失
- Triplet 损失函数的定义
在实际应用中,Siamese network的目标函数为Triplet 损失函数,他可用于训练Siamese network的参数。Triplet损失函数的核心思想如下图所示:
在Triplet中,一个training sample包含3个image,分别为(anchor,positive,negative),其中anchor和positive为同一个人,anchor和negative为不同的人。假设anchor的编码为f(A),positive的编码为f§,negative的编码为f(N)。Triplet的目标是使得:||f(A)-f§||2与||f(A)-f§||2之间的差值最大,其中||f(A)-f§||2代表两个相同的image的距离,应尽可能的小,而||f(A)-f§||2代表两个不同的image的距离,应尽可能的大。Triplet具体可表示为: ||f(A)-f§||2- ||f(A)-f§||2 <= 0,其中,由于当f(i)=0时,||f(A)-f§||2- ||f(A)-f§||2 = 0 ,但是,此时的Siamese network并不能得到一个有效的编码,为了,避免这种训练结果的发生,我们可以在上式 左端加入一个正数 alpha,从而防止||f(A)-f§||2- ||f(A)-f§||2 = 0 。
此时,Triplet为: ||f(A)-f§||2- ||f(A)-f§||2 + alpha <= 0

给定一个training dataset(A,P,N),Triplet损失函数可以定义如下:
L(A,P,N) = max(||f(A)-f§||2 - ||f(A)-f(N)||2 + alpha , 0) ;
J = sum(L(A(i), P(i), N(i))) ; 根据backward propagation,即可求得Siamese network的parameter。
question:L(A,P,N) = max(||f(A)-f§||2 - ||f(A)-f(N)||2 + alpha , 0)在实际计算中,如何体现||f(A)-f§||2 - ||f(A)-f(N)||2 + alpha <= 0的思想?
个人理解1:可以initialize L(A,P,N)=0,则||f(A)-f§||2 - ||f(A)-f(N)||2 = -alpha。根据||f(A)-f§||2 - ||f(A)-f(N)||2的初始值,求得一组weight,然后,利用backward propogation,在此weight的基础上,继续更新weight,从而使得L(A,P,N)不断减小。
个人理解2:或者直接初始化一组weight,然后利用backward propogation,不断更新weight,直到L(A,P,N)达到一指定的threshold,停止iteration。

- Triplet中,training data的创建
如果随机选取training data(A,P,N),则 Triplet 损失函数,很容易就可以实现,这样训练出来的Siamese network 非常的松散,无法应对anchor和negative较为相近的情况,为了避免训练出一个非常松散的Siamese network,需要认真挑选那些training data(A,P,N),其中A,N应该尽可能相近,从而使得训练出的Siamese network具有较强的robust,能够应对一些较为困难的face recognition任务。

面部验证与二分类(alternative of Triplet loss , to compute the parameter of Siamese)
-
将face recognition看成是一个二分类问题
不同于上一节的Triplet loss function,本节中将face recognition看成是一个binary classification,利用logistic likelihood以及backward propogation来求解Siamese network parameter以及logistic中的parameter,具体过程如下所示:
1、首先说明“该二分类任务”的工作过程:
在model的前端为Siamese network,用来encode image,将2张image的编码输入到logistic regression(其公式为 g(w*d(image1,image2)+b)),求得logistic的预测值:{output=1 : 2个image为同一人,output=0 : 2个image为不同的人}。
需要注意的是:d(image1,image2)可以使用不同的公式来表示,如下PPT所示,可以使用欧几里得,也可以使用X2。
2、Siamese network和logistic 中参数的求解
个人理解:可以将“最大似然函数”作为“目标函数”,通过backward propagation求解model中所有参数;
3、face recognition 实际应用的一些技巧
在实际的face recognition task中,可以利用已经训练好的Siamese network将database中的image进行encode,并将其作为image的特征存储在database中(precomputed),这样在进行一个face recognition task时,只需要计算input image的Siamese encoding,而不用在去计算database中的image code,可以节省face recognition时间。

-
在该binary classification中,training data的创建方式
在该binary classification(face recognition)中,一个training sample是有“2张image”构成,其对应的target y为{0:different person,1:same person},如下图所示。

总结,2种实现one-shot learning的方式:
1、通过计算2个image的距离,判断二者是否为同一个人:
具体方法:利用Triplet loss训练一个Siamese network,利用该network给image编码,并将编码看作image的特征,利用该特征计算2个image的距离。
在Siamese network + Triplet loss中,为“unsupervised learning”,training data为(anchor,positive,negative);
2、通过拟合binary classification model (logistic),将2个image输入model中,利用output来预测2个image是否为同一个人:
具体方法:首先利用Siamses network给2个image编码,在将该编码喂给logistic,使其根据公式g(w*d(image1,image2)+b)对2个image是否相同进行预测。
个人理解:该model的目标函数为“最大似然估计”,求解方法为:backward propagation;
在Siamese network + logistic 中,为“supervised learning”,training data为{X:(image1,image2),y:{1:same thing,0:different things}}
什么是神经风格转换
如下图所示,我们将content和style作为input,可以output Generated image。这个过程称为“神经风格转换”。
在接下来的几节中,将具体讲述“神经风格转换”的实现方式。

深度卷积网络在学什么?
在每层layer中,学习到的每个image patch都会最大化active function value。如下图所示:
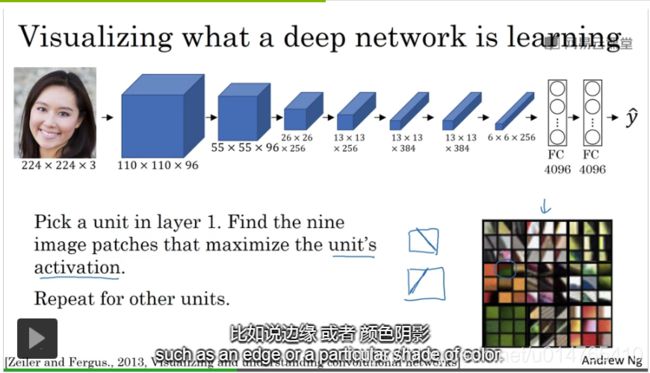
在深度卷积网络中,shallow layer主要学习“small piece of image”,如:“边、颜色阴影”的。而在deeper layer会学习“large image region”,如:“animal,people,car”等,如下图所示:





代价函数概览(neural style transform algorithm)
neural style tansfer algorithm的cost fucntion形式如下图所示:
cost function :J(G)=alpha * Jcontent(content,generated) + beta * Jstyle(style,generated);我们要做的是,最小化J(G)的值,在cost function中,generated image vector为parameter。
generated image形成方式如下:
假设generated image为 1001003 的vector
step1:初始化generated image vector中各元素的值G;
step2:更新g的值:G := G - J’(G);
step3:重复step2直到达到收敛条件。

下图(right-hand)显示了generated image形成过程中,各个iteration中,generated image的样子:

在下面2节中,将具体讲述Jcontent和Jstyle的形式。
内容损失函数
Jcontent =(1/2)* ||a[l][C] - a[l][G] ||2 ; Jcontent function中系数 1/2 并不重要。
a[l][C]:将content image输入pre-trained ConvNet,a[l][C]为ConvNet中l layer的active function value。
a[l][G]:将初始化的generated image 输入pre-trained ConvNet,a[l][G]为ConvNet中l layer的active function value。
上述的ConvNet可以是VGG等network;
note that:ConvNet hidden layer 层数l的选择,不要太大,也不要太小。
content cost function的具体计算过程如下PPT所示:

风格损失函数
-
“风格”的定义
如下图所示:
将image输入到一个ConvNet中,假设你要用ConvNet的l hidden layer来评价image的风格,则所谓image的风格是指:其在l hidden layer中,各个channel的active function value的correlation。那么这里的correlation指的是什么呢?请看intuition about style of an image。
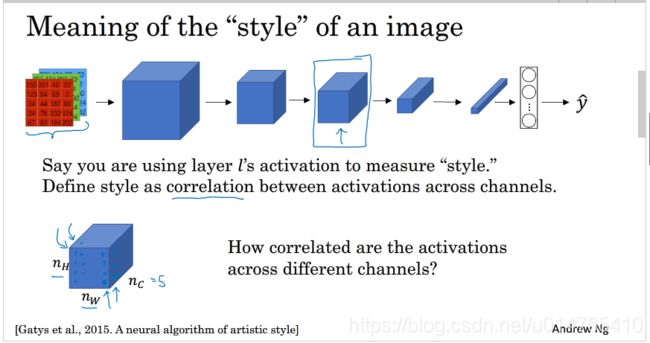
-
intuition about style of an image
在上一部分中提到的l hidden layer各个channel的 active function value的correlation的意义通过下图来讲解:
假设下图style image的red channel形成的activation为patch image中的第[1][2]个image patch。orange channel形成的activation为patch image中的第[2][1]个image patch。假设generated image与style image具有相同的风格,那么:generated image的red channel形成的activation也为patch image中的第[1][2]个image patch。orange channel形成的activation也为patch image中的第[2][1]个image patch。即:所谓correlation between channel,是指,在一种风格的image中,当channel1出现时,channel2也出现,此时,这两个channel相关度较高。

-
风格损失函数
风格损失函数求解过程:
step1:将style image 和 初始化的generated image输入到pre-trained的ConvNet中。
step2:以ConvNet的l hidden layer来计算“风格损失函数”。
step3:求l hidden layer中,style image和generated image 不同channel的correlation,具体公式如下:
G[l][s]kk’:style image在l hidden layer中不同channel之间的correlation;
G[l][G]kk’:generated image在l hidden layer中不同channel之间的correlation;
step4:风格损失函数 Jstyle(S,G) =系数* || G[l][s]kk’ - G[l][G]kk’||2 ;前面的系数并不重要;
具体公式如下图所示:

在实际应用中,我们可以用多个hidden layer来计算“风格损失函数”,每层hidden layer被赋予一个系数lambda,具体公式如下图所示:
在求得“风格损失函数”以后,联合上一节所讲的“内容损失函数”,即可求得neural style tranform algorithm 中的cost function J(G),其中G为generated image 的input vector的 element。

一维到三维的推广
- 2维到1维的推广
如下图所示:对于1D convolution来说,其filter也是1D,下图filter为5,将其与1D input(8)进行convolution operation,即可得到 output(4)。

- 2维到3维的推广
如下图所示:3维input image为(x,y,z),其filter对应也应为3D(f1,f2,f3)。
3维vector(x,y,z) :1)可以应用于movie,其中z的各个值可以看作是一个时间点,(x,y)为一个image; 2)也可以应用于“医学领域,如:CT scan”。
