牛客网刷题(垃圾回收+Socket+串池+类加载+事务)
目录
垃圾回收
事务隔离级别
字符串
Socket通信编程
ServerSocket类
Socket类
引用
垃圾回收
开发人员是不能参与GC机制的,System.gc(),只是一个提醒,具体什么时候GC是不知道的,而且提醒的是Full GC,并不是Minor GC;
复习一下:
首先得判断哪些是垃圾,一般现在用的是可达分析法,类似树的遍历,从GC root进行遍历访问,只要是这个链条上的对象都是可以访问的,起点必须是GC Root,否则都是垃圾;
具体五种引用:
(30条消息) JVM-02阶段学习_Fairy要carry的博客-CSDN博客
然后再讲下怎么清除垃圾(垃圾回收算法):
标记清除:标记垃圾直接清除,会产生垃圾碎片。
标记整理:标记清除后,再集中没有被回收的对象,需要移动对象,效率受到影响,而且地址发生改变,时间换空间。
复制:标记并清除对象后,将没被回收的放在另外一个内存中,空间换时间;
然后就是分代:实际上就是用的上面三种基本算法,只是根据堆内存中的区域用不同的算法清除垃圾;
分代实际上就是对号入座,以便提高效率,试想一下,如果堆内存没有区域划分,所有的新创建的对象和生命周期很长的对象放在一起,随着程序的执行,堆内存需要频繁进行垃圾收集,而每次回收都要遍历所有的对象,遍历这些对象所花费的时间代价是巨大的,会严重影响我们的GC效率,这简直太可怕了。
有了内存分代,情况就不同了,新创建的对象会在新生代中分配内存,经过多次回收仍然存活下来的对象存放在老年代中,静态属性、类信息等存放在永久代中,新生代中的对象存活时间短,只需要在新生代区域中频繁进行GC,老年代中对象生命周期长,内存回收的频率相对较低,不需要频繁进行回收,永久代中回收效果太差,一般不进行垃圾回收,还可以根据不同年代的特点采用合适的垃圾收集算法。
JVM堆内存模型:
新生代:用完就可以丢到的对象
老年代:经常要用的,活的久
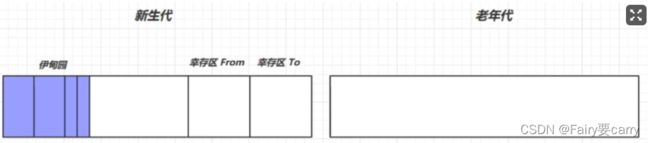
回收流程:
1.对象首先分配在伊甸园区域
2.新生代空间不足时,触发 minor gc,伊甸园和 from 存活的对象使用 copy 复制到 to 中,存活的对象年龄加 1并且交换 from to
3.minor gc 会引发 stop the world,暂停其它用户的线程,等垃圾回收结束,用户线程才恢复运行
4.当对象寿命超过阈值时,会晋升至老年代,最大寿命是15(4bit)
5.当老年代空间不足,会先尝试触发 minor gc,如果之后空间仍不足,那么触发 full gc,STW的时间更长
一些GC分析
1.大对象处理,如果对象>>伊甸园,直接老年代
2.线程内存溢出,不会让其他线程结束,而是自己占据的资源全部释放
(30条消息) JVM-02阶段学习_Fairy要carry的博客-CSDN博客
垃圾回收算法完了,还有垃圾回收器:
大致分类:
1.串行:单线程的垃圾回收器(其他线程会因为他的垃圾回收而暂停):堆内存较小的时候,适合个人电脑;->就跟保洁打扫楼区卫生一样;
2.吞吐量优先:
多线程->就是多找几个保洁,去加快速度(适合堆内存较大的场景,多核cpu);
为什么要多个cpu?
因为你多个保洁如果放在一个cpu上的话,就会并发,你·清一下,我清一下,这样切换浪费时间,也就是说轮流垃圾回收,这样就很慢了;
所以我们多个cpu就可以实现并行操作,以至于实现堆内存较大时的垃圾回收;
3.响应时间优先:
多线程,多个保洁—>堆内存较大,并发,
吞吐量优先和响应时间优先的不同之处:
吞吐量优先是注重效率的:一次垃圾回收清理的较多,其他线程等待耗时较长——>吞吐量优先,也就是垃圾回收器回收时间更长;
响应式时间优先:是注重时间的,意思就是它会将垃圾回收分很多次,以此来加快时间,但是每次清理的内存没有吞吐量优先那么多;
事务隔离级别
这题实属大意了,问的是事务隔离级别是谁实现的,由数据实现的,因为它是数据库系统本身的一个功能,而java程序只是设定事务的隔离级别而不是实现它;
(30条消息) Spring事务_Fairy要carry的博客-CSDN博客
字符串

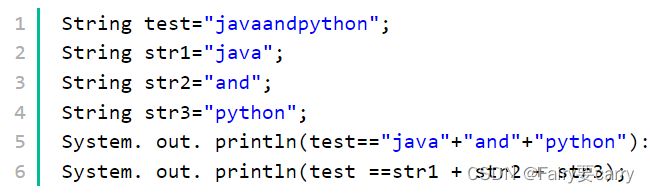
下面这条语句一共创建了多少个对象:String s="welcome"+"..._Java专项练习_牛客网 (nowcoder.com)
对于上面这段代码,结果是true false
这是因为字符串字面量拼接操作是在Java编译器编译期间就执行了,也就是说编译器编译时,直接把"java"、"and"和"python"这三个字面量进行"+"操作得到一个"javaandpython" 常量,并且直接将这个常量放入字符串池中,这样做实际上是一种优化,将3个字面量合成一个,避免了创建多余的字符串对象(只有一个对象"javaandpython",在字符串常量池中)。而字符串引用的"+"运算是在Java运行期间执行的,即str1 + str2 + str3在程序执行期间才会进行计算,它会在堆内存中重新创建一个拼接后的字符串对象。且在字符串常量池中也会有str1,str2与str3,这里创建多少个新的对象与原来字符串常量池中有没有str1\str2\str3有关,如果之前存在就不会创建新的对象。
总结来说就是:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算实在运行时进行的,新创建的字符串存放在堆中。
然后突然又联系到了JVM中类加载机制,其实字符串引用拼接就是类加载的准备阶段——>将Java类的二进制代码合并到JVM 运行状态之中。;
那么再来看这题,很明显只在编译期间在字符串常量池中创建了"welcometo360"一个字符串
(30条消息) JVM-02阶段学习_Fairy要carry的博客-CSDN博客
Socket通信编程
Socket,又称套接字,是在不同的进程间进行网络通讯的一种协议、约定或者说是规范。
对于Socket编程,它更多的时候是基于TCP/UDP等协议做的一层封装或者说抽象,是一套系统所提供的用于进行网络通信相关编程的接口。
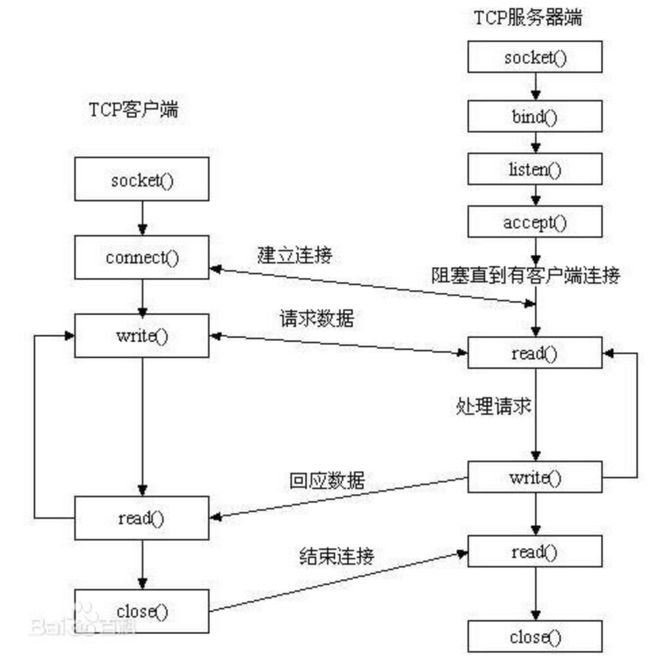
可以看到本质上,Socket是对TCP连接(当然也有可能是UDP等其他连接)协议,在编程层面上的简化和抽象。
ServerSocket类
创建一个ServerSocket类,同时在运行该语句的计算机的指定端口处建立一个监听服务,如:
| 1 |
|
这里指定提供监听服务的端口是600,一台计算机可以同时提供多个服务,这些不同的服务之间通过端口号来区别,不同的端口号上提供不同的服务。为了随时监听可能的Client端请求,执行如下的语句:
| 1 |
|
该语句调用了ServerSocket对象的accept()方法,这个方法的执行将使Server端的程序处于阻塞状态,程序将一直阻塞直到捕捉到一个来自Client端的请求,并返回一个用于与该Client端通信的Socket对象。此后Server程序只需要向这个Socket对象读写数据,就可以向远端的Client端读写数据。结束监听时,关闭ServerSocket:
| 1 |
|
ServerSocket一般仅用于设置端口号和监听,真正进行通信的是Server端的Socket与Client端的Socket。
Socket类
当Client端需要从Server端获取信息及其他服务时,应创建一个Socket对象:
| 1 |
|
Socket类的构造方法有两个参数,第一个参数是欲连接到的Server端所在计算机的IP地址(请注意,是IP,不是域名),第二个参数是该Server机上提供服务的端口号。
如果需要使用域名表示Server端所在计算机的地址:
| 1 2 |
|
Socket对象建立成功之后,就可以在Client端和Server端之间建立一个连接,通过这个连接在两个端之间传递数据。利用Socket类的方法getInputStream()和getOutputStream()分别获得用于向Socket读写数据的输入/输出流。
当Server端和Client端的通信结束时,可以调用Socket类的close()方法关闭连接。
引用
Java中ServerSocket与Socket的区别-原文转载未标出处-CSDN
Socket编程入门(基于Java实现)-Lumin-掘金