数据湖 | 还不知道什么是Iceberg?一篇文章带你走进Iceberg的世界!
文章目录
-
- 1. Iceberg是什么?
- 2. Iceberg能力与优势
- 3. Iceberg能力验证
-
- 3.1 Time travel
- 3.2 table evolution
- 4. 流式数据入湖(Iceberg结合Flink)
-
- 4.1 using Flink SQL Client
- 4.2 using Flink DataStream Api
- 5. Iceberg应用场景
- 参考文档
近年来“数据湖”的概念在大数据领域如火如荼。delta、Apache Iceberg和Apache Hudi是市面上流行的三大数据湖解决方案,那到底这些方案是什么?又怎么使用?本文参考官网文档,带你快速入门iceberg,并从几个简单的例子出发,感受iceberg的能力。
1. Iceberg是什么?
Iceberg定位在计算引擎之下,存储之上,通过特定的方式将数据和元数据组织起来,它是一种数据存储格式。引用官网的定义“Apache Iceberg is an open table format for huge analytic datasets”,Iceberg是一种“数据组织格式”、“表格式”、“table format”。
2. Iceberg能力与优势
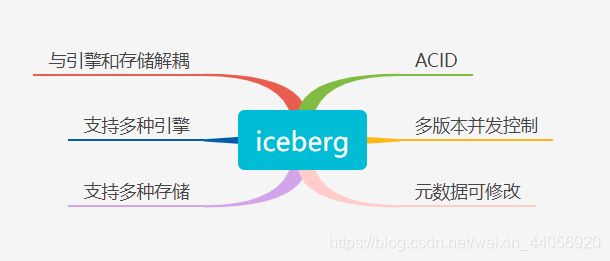
| 能力与优势 | 详情 |
|---|---|
| ACID | Iceberg提供了锁的机制来提供ACID的能力,确保表的修改是原子性的,提供了乐观锁降低锁的影响,并使用冲突回退和重试机制来解决并发所造成的冲突问题。支持隔离级别。提供“行”级别数据修改删除、能力。 |
| MVCC (多版本并发控制) |
每次写操作都会产生一个新的快照,快照始终是向后线性递增,确保了线性一致性。利用iceberg的time travel能力,提供了用户快照回滚和数据重放的能力。可以方便的基于snapshot的历史实现增量消费。 |
| 解耦 (接口抽象程度高) |
与上层数据处理引擎和底层数据存储格式的解耦。对接上层,提供了丰富的表操作接口,非常容易与上层数据处理引擎对接。对接下层,屏蔽了底层数据格式的差异,提供了对Parquet, ORC和Avro格式的支持。可支持多种存储和计算引擎,同时支持流批处理。 |
| table evolution | 表schema, 分区方式可修改。schema修改支持 add, drop, rename, update(提升数据类型),recorder(调整列顺序) 可更新已有表的分区信息 (因为查询语句并不直接引用分区值) |
| 隐式分区 | iceberg可根据用户query自动进行partition pruning,过滤掉不需要数据,用户无需利用分区信息可以优化查询。 |
3. Iceberg能力验证
3.1 Time travel
假设当前有10条数据,然后执行了insert overwrite,覆盖插入2条数据。此时表中最新的数据只有2条,可以查到上个快照版本的id是8936850315328731234, 通过此ID可以回溯到上个版本,查询到之前的10条数据。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable(
"hdfs://xx.xxxx.xx:9000/home/iceberg/iceberg_db/sample"); //iceberg数据存储所在hdfs地址
DataStream<RowData> ds = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false)
.snapshotId(8936850315328731234L)
.build();
ds.print();
env.execute();
3.2 table evolution
① schema evolution(删除data列, 新增data2列,并将sign字段数据格式由INT改为BIGINT)
Iceberg 使用唯一 ID 来跟踪表中的每一列。添加列时,会为其分配一个新 ID。
TableLoader tableLoader = TableLoader.fromHadoopTable(
"hdfs://xx.xxxx.xx:9000/home/iceberg/iceberg_db/sample");
//注意需要此句,从hadoopConf创建HadoopTables(uses the Hadoop FileSystem)
tableLoader.open();
Table sampleTable = tableLoader.loadTable();
sampleTable.updateSchema()
.deleteColumn("data")
.addColumn("data1",new Types.StringType())
.renameColumn("id","id1")
.updateColumn("sign",Types.LongType.get()) //注意这里要用get(只能 widen the type)
.commit();
运行前表结构
Flink SQL> desc sample;
2021-02-04 14:41:14,195 WARN org.apache.hadoop.hdfs.DFSClient [] - DFSInputStream has been closed already
2021-02-04 14:41:14,198 INFO org.apache.iceberg.BaseMetastoreCatalog [] - Table loaded by catalog: hadoop_catalog.iceberg_db.sample
root
|-- id: BIGINT
|-- data: STRING
|-- sign: INT
运行后表结构(注意:需要重新启动shell才能看见表结构改变)
Flink SQL> desc sample;
2021-02-04 14:51:39,907 WARN org.apache.hadoop.hdfs.DFSClient [] - DFSInputStream has been closed already
2021-02-04 14:51:39,910 INFO org.apache.iceberg.BaseMetastoreCatalog [] - Table loaded by catalog: hadoop_catalog.iceberg_db.sample
root
|-- id1: BIGINT
|-- sign: BIGINT
|-- data1: STRING
② partition evolution
验证了添加分区,修改分区(删除分区暂时未验证成功)
//System.out.println("分区修改之前:" + sampleTable.spec());
sampleTable.updateSpec()
.addField("sign")
.commit();
//System.out.println("分区修改之后:" + sampleTable.spec());
运行结果:
分区修改之前:[
1000: id1: void(1)
]
分区修改之后:[
1000: id1: void(1)
1001: sign: void(6)
]
③ partition evolution
sampleTable.replaceSortOrder()
.asc("id1")
.commit();
4. 流式数据入湖(Iceberg结合Flink)
4.1 using Flink SQL Client
① 环境准备,启动Flink SQL client
# 启动Flink集群
./bin/start-cluster.sh
# 引入hadoop环境变量
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# 启动Flink sql-client并加载iceberg的包
./bin/sql-client.sh embedded -j /home/xxx/iceberg/iceberg-flink-runtime-0.10.0.jar shell
② 创建catalog
# 创建catalog
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://xxx:9000/home/iceberg',
'property-version'='1'
);
# 使用此catalog
USE CATALOG hadoop_catalog;
③ 创建database
# 创建database
CREATE DATABASE iceberg_db;
# 使用此database
USE iceberg_db;
④ 创建表
CREATE TABLE test_sample (
id BIGINT COMMENT 'unique id',
data1 STRING,
data2 STRING
);
⑤ 写入数据并查看
INSERT INTO test_sample VALUES (1, 'a', 'b');
4.2 using Flink DataStream Api
① 需要额外引入依赖
<dependency>
<groupId>org.apache.iceberggroupId>
<artifactId>iceberg-flinkartifactId>
<version>0.10.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.2version>
dependency>
② 本地创造两条数据写入iceberg表中
注意:流式数据写入iceberg时,需要开启Flink checkpoint,并且在完成checkpoint时,数据才可以流式入湖.
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.types.Row;
import org.apache.iceberg.flink.TableLoader;
import org.apache.iceberg.flink.sink.FlinkSink;
import java.util.ArrayList;
import java.util.List;
public class WriteTableByApi {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<Row> data = new ArrayList<>();
data.add(Row.of(1L, "123", "346"));
data.add(Row.of(2L, "456", "123"));
DataStreamSource<Row> input = env.fromCollection(data);
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://xxx:9000/home/iceberg/iceberg_db/test_sample");
TableSchema tableSchema = TableSchema.builder()
.field("id", DataTypes.BIGINT())
.field("data1", DataTypes.STRING())
.field("data2", DataTypes.STRING())
.build();
FlinkSink.forRow(input, tableSchema).tableLoader(tableLoader).writeParallelism(1).build();
env.execute();
}
}
5. Iceberg应用场景
(1) 集成Hive(可以通过 Hive 创建和删除 iceberg 表,通过 HiveSQL 查询 Iceberg 表中的数据,基于Spark进行数据修正)
(2) 流式数据入库,引入iceberg作为Flink Sink(打造实时数仓)
(3) 数据湖(海量数据,快速查找,统一存储)
(4) 集成Implala(用户可以通过 Impala 新建 iceberg 内表外表,并通过 Impala 查询 Iceberg 表中的数据)
参考文档
[1] iceberg官方文档
[2] iceberg github地址
[3] Neflix 提供的 Flink Iceberg connector 原型
[4] Iceberg 在基于 Flink 的流式数据入库场景中的应用
[5] Delta Lake、Iceberg 和 Hudi 三大开源数据湖不知道如何选?那是因为你没看这篇文章…
[6] iceberg时间旅行