Pytorch之动手学习深度学习(PyTorch)
dive into DL PyTorch
basic knowledge
main tools
torch.utils.data模块提供了有关数据处理的工具,
torch.nn模块定义了大量神经网络的层,
torch.nn.init模块定义了各种初始化方法,
torch.optim模块提供了模型参数初始化的各种方法
softmax回归适用于分类问题。它使用softmax运算输出类别的概率分布。
softmax回归是一个单层神经⽹网络,输出个数等于分类问题中的类别个数。
交叉熵适合衡量两个概率分布的差异。
activation function
多层感知机在输出层与输入层之间加入了一个或多个全连接隐藏层,并通过激活函数对隐藏层输出进行变换。
常用的激活函数包括ReLU函数、 sigmoid函数和tanh函数。
overfit
由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。机器学习模型应关注降低泛化误差。
可以使用验证数据集来进行模型选择。
欠拟合指模型无法得到较低的训练误差,过拟合指模型的训练误差远小于它在测试数据集上的误差。
应选择复杂度合适的模型并避免使用过少的训练样本。
我们可以通过使用丢弃法(dropout)应对过拟合。
丢弃法(dropout)只在训练模型时使用。
back propagation, forward propagation
正向传播沿着从输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
反向传播沿着从输出层到输⼊层的顺序,依次计算并存储神经网络中间变量和参数的梯度。
在训练深度学习模型时,正向传播和反向传播相互依赖。
init parameters
深度模型有关数值稳定性的典型问题是衰减和爆炸。当神经⽹网络的层数较多时,模型的数值稳定性容易易变差。
我们通常需要随机初始化神经网络的模型参数,如权重参数。
通常需要对真实数据做预处理。
可以使用K折交叉验证来选择模型并调节超参数。
Module
可以通过继承 Module 类来构造模型。
Sequential 、 ModuleList 、 ModuleDict 类都继承⾃ Module 类。
虽然 Sequential 等类可以使模型构造更加简单,但直接继承 Module 类可以极大地拓展模型构造的灵活性。
可以通过 Module 类⾃自定义神经⽹网络中的层,从⽽可以被重复调用
state_dict
在 PyTorch 中 , Module 的可学习参数(即权重和偏差),模块模型包含在参数中(通过
model.parameters() 访问)。 state_dict 是⼀个从参数名称隐射到参数 Tesnor 的字典对象。
只有具有可学习参数的层(卷积层、线性层等)才有 state_dict 中的条⽬。优化器(optim )也有⼀个 state_dict ,其中包含关于优化器器状态以及所使用的超参数的信息。
PyTorch中保存和加载训练模型有两种常见的方法:
- 仅保存和加载模型参数( state_dict );
- 保存和加载整个模型。
通过 save 函数和 load 函数可以很方便地读写 Tensor 。
通过 save 函数和 load_state_dict 函数可以很方便地读写模型的参数。
convolution
深度学习中的卷积运算实际上是互相关运算(滑动,对应位置相乘相加)
二维卷积层的核心计算是二维互相关运算。在最简单的形式下,它对二维输⼊数据和卷积核做互相关运算然后加上偏差。
我们可以设计卷积核来检测图像中的边缘。
我们可以通过数据来学习卷积核。
feature map
二维卷积层输出的二维数组可以看作是输⼊在空间维度(宽和⾼)上某一级的表征,也叫特征图(feature map)。影响元素的前向计算的所有可能输⼊区域(可能⼤于输⼊的实际尺⼨)叫做感受野(receptive field)。可以通过更深的卷积神经网络使特征图中单个元素的
感受野变得更更加广阔,从而捕捉输⼊上更大尺⼨的特征。
padding & stride
out_size = (in_size - kernel_size + 2*padding) / stride + 1
卷积神经网络经常使用奇数高宽的卷积核,如1、 3、 5和7,所以两端上的填充padding个数相等。
kenel_size = 3, padding = 1情况下,输出输入的尺寸一样。
填充可以增加输出的高和宽。这常用来使输出与输⼊具有相同的高和宽。
步幅可以减小输出的高和宽,例如输出的高和宽仅为输⼊的高和宽的 1/n( n为大于1的整数)。
channel
使用多通道可以拓展卷积层的模型参数。
假设将通道维当作特征维,将高和宽维度上的元素当成数据样本,那么 1X1 卷积层的作用与全连接层等价。
1X1 卷积层通常用来调整网络层之间的通道数,并控制模型复杂度。
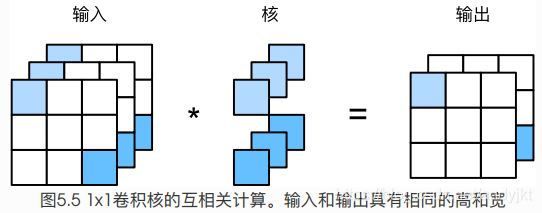
pooling
为了缓解卷积层对位置的过度敏敏感性。
在处理多通道输⼊数据时,池化层对每个输⼊通道分别池化,而不是像卷积层那样将各通道的输⼊按通道相加。这意味着池化层的输出通道数与输⼊通道数相等。
main basic network
VGG
对于给定的感受野(与输出有关的输⼊图片的局部大⼩),采用堆积的小卷积核优于采用大的卷积核,
因为可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。例如,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了了网络的深度,在一定程度上提升了神经网络的效果。

NIN
卷积层的输⼊和输出通常是四维数组(样本,通道,⾼,宽),而全连接层的输⼊和输出则通常是二维数组(样本,特征)。如果想在全连接层后再接上卷积层,则需要将全连接层的输出变换为四维。1X1卷积层可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。
因此,NiN使用卷积层来替代全连接层,从而使空间信息能够自然传递到后⾯的层中去。
NiN使⽤用卷积窗⼝口形状分别为11X11, 5X5, 3X3的卷积层,相应的输出通道数也与AlexNet中的一致。
每个NiN块后接一个步幅为2、窗口形状为3X3的最大池化层。
NiN去掉了了AlexNet最后的3个全连接层,取而代之地, NiN使⽤了输出通道数等于标签类别数的NiN块,然后使⽤用全局平均池化层对每个通道中所有元素求平均并直接用于分类。
这⾥的全局平均池化层即窗口形状等于输入空间维形状的平均池化层。
NiN的这个设计的好处是可以显著减小模型参数尺⼨,从⽽缓解过拟合。然⽽,该设计有时会造成获得有效模型的训练时间的增加。
NiN重复使用由卷积层和代替全连接层的卷积层构成的NiN块来构建深层⽹络。
NiN去除了容易造成过拟合的全连接输出层,⽽是将其替换成输出通道数等于标签类别数的NiN块和全局平均池化层。
GoogLeNet

GoogLeNet中的基础卷积块叫作Inception块, Inception块里有4条并行的线路。前3条线路使⽤窗⼝大小分别是 1X1、3X3和5X5的卷积层来抽取不同空间尺⼨下的信息,其中中间2个线路会对输⼊先做1X1卷积来减少输⼊通道数,以降低模型复杂度。第四条线路则使用最大池化层,后接1X1卷积层来改变通道数。 4条线路都使用了合适的填充来使输入与输出的⾼和宽一致。最后我们将每条线路的输出在通道维上连结,
并输⼊接下来的层中去。
Inception块相当于一个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使⽤1X1卷积层减少通道数从而降低模型复杂度。
GoogLeNet将多个设计精细的Inception块和其他层串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
GoogLeNet和它的后继者们一度是ImageNet上最高效的模型之⼀:在类似的测试精度下,它们的计算复杂度往往更低。
Batch Normalization



使⽤批量归一化训练时,我们可以将批量大小设得大一点,从而使批量内样本的均值和方差的计算都较为准确。将训练好的模型用于预测时,我们希望模型对于任意输入都有确定的输出。因此,单个样本的输出不应取决于批量归一化所需要的随机小批量中的均值和方差。一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。可⻅,和丢弃层一样,批量归⼀化层在训练模式和预测模式下的计算结果也是不一样的。
Pytorch 中 nn 模 块 定 义 的 BatchNorm1d 和BatchNorm2d 类使用起来更加简单,二者分别用于全连接层和卷积层,都需要指定输入的num_features 参数值。
ResNet


ResNet沿用了VGG全3X3卷积层的设计。残差块里首先有2个有相同输出通道数的3X3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数。然后我们将输⼊跳过这两个卷积运算后直接加在最后的ReLU激活函数前。这样的设计要求两个卷积层的输出与输⼊形状一样,从而可以相加。如果想改变通道数,就需要引⼊⼀个额外的1X1卷积层来将输⼊变换成需要的形状后再做相加运算
DenseNet

图中将部分前后相邻的运算抽象为模块A和模块B。与ResNet的主要区别在于,DenseNet⾥模块B的输出不是像ResNet那样和模块A的输出相加,而是在通道维上连结。这样模块A的输出可以直接传入模块B后面的层。在这个设计⾥,模块A直接跟模块B后面的所有层连接在了一起。这也是它被称为“稠密连接”的原因。
DenseNet的主要构建模块是稠密块(dense block)和过渡层(transition layer)。前者定义了输入和输出是如何连结的,后者则⽤来控制通道数,使之不过大。
optimizer
优化算法通常只考虑最小化目标函数。其实,任何最大化问题都可以很容易地转化为最小化问题。
很多优化问题并不存在解析解,而需要使用基于数值方法的优化算法找到近似解,即数值解。
为了求得最小化目标函数的数值解,我们将通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。
深度学习模型的目标函数可能有若干局部最优值。当一个优化问题的数值解在局部最优解附近时,由于
目标函数有关解的梯度接近或变成零,最终迭代求得的数值解可能只令目标函数局部最小化而非全局最
小化。
(补充) matplotlib


gradient descent & stochastic gradient descent



使用适当的学习率,沿着梯度反方向更新自变量可能降低目标函数值。梯度下降重复这一更新过程直到得到满足要求的解。学习率过大或过小都有问题。一个合适的学习率通常是需要通过多次实验找到的。当训练数据集的样本较多时,梯度下降每次迭代的计算开销较大,因而随机梯度下降通常更受青睐。
小批量随机梯度下降

小批量随机梯度每次随机均匀采样一个小批量的训练样本来计算梯度。在实际中,(小批量)随机梯度下降的学习率可以在迭代过程中自我衰减。通常,小批量随机梯度在每个迭代周期的耗时介于梯度下降和随机梯度下降的耗时之间。

动量法

动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。动量法使得相邻时间步的自变量更新在方向上更加一致。
AdaGrad算法
当两个变量的梯度值有较大差别时,需要选择足够小的学习率使得自变量在梯度值较大的维度上不发散。但这样会导致自变量在梯度值较小的维度上迭代过慢。动量法依赖指数加权移动平均使得自变量的更新方向更加一致,从而降低发散的可能。本节我们介绍AdaGrad算法,它根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。


AdaGrad算法在迭代过程中不断调整学习率,并让目标函数自变量中每个元素都分别拥有自己的学习率。使用AdaGrad算法时,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。
RMSPROP算法


RMSProp算法和AdaGrad算法的不同在于, RMSProp算法使用了小批量随机梯度按元素平方的指数加权移动平均来调整学习率。
AdaDelta算法

AdaDelta算法没有学习率超参数,它通过使用有关自变量更新量平⽅的指数加权移动平均的项来替代RMSProp算法中的学习率。
ADAM算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均,
所以Adam算法可以看做是RMSProp算法与动量法的结合。


Adam算法在RMSProp算法的基础上对⼩批量随机梯度也做了指数加权移动平均。
Adam算法使用了偏差修正。
命令式编程和符号式编程
命令式编程更方便。当我们在Python里使用命令式编程时,大部分代码编写起来都很直观。同
时,命令式编程更容易调试。这是因为我们可以很方便地获取并打印所有的中间变量值,或者使
用Python的调试工具。
符号式编程更高效并更容易移植。一方面,在编译的时候系统容易做更多优化;另一方面,符号
式编程可以将程序变成一个与Python无关的格式,从而可以使程序在非Python环境下运行,以
避开Python解释器的性能问题。
异步计算和GPU计算
异步计算

当两个计算任务一起执行时,执行总时间⼩于它们分开执行的总和。这表明, PyTorch能有效地实现在不同设备上自动并行计算。
多GPU计算
要想使用PyTorch进行多GPU计算,最简单的⽅法是直接⽤torch.nn.DataParallel
将模型wrap一下。 eg: net = torch.nn.DataParallel(net)
也可以指定GPU id torch.nn.DataParallel(net, device_ids=[0,3])
模型保存和加载
import torch
net = torch.nn.Linear(10, 1).cuda()
net
output:
Linear(in_features=10, out_features=1, bias=True)
import torch
net = torch.nn.DataParallel(net)
net
output:
DataParallel(
(module): Linear(in_features=10, out_features=1, bias=True)
)


图像增广
图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但⼜不同的训练样
本,从而扩大训练数据集的规模。图像增广的另⼀种解释是,随机改变训练样本可以降低模型对某些属
性的依赖,从而提高模型的泛化能力。
翻转
import torchvision
torchvision.transforms.RandomHorizontalFlip()
torchvision.transforms.RandomVertivalFlip()
裁剪
在下⾯的代码里,我们每次随机裁剪出一块面积为原面积10%~100%的区域,且该区域的宽和高之
⽐随机取自0.5~2 ,然后再将该区域的宽和高分别缩放到200像素。
import torchvision
torchvision.transforms.RandomResizedCrop(200, scale=(0.1, 1), ratio=(0.5, 2))
颜色变化
可以从4个⽅⾯改变图像的颜色:亮度( brightness )、对比度( contrast )、饱和度( saturation )和⾊调( hue )。
将图像的亮度随机变化为原图亮度的 50%(1-0.5)~150%(1+0.5)。
import torchvision
torchvision.transforms.ColorJitter(brightness=0.5)
torchvision.transforms.ColorJitter(hue=0.5)
torchvision.transforms.ColorJitter(contrast=0.5)
torchvision.transforms.ColorJitter(brightness=0.5, hue=0.5, contrast=0.5, saturation=0.5)
为了在预测时得到确定的结果,我们通常只将图像增广应用在训练样本上,而不在预测时使用含随机操作的图像增广
我们使用 ToTensor 将小批量图像转成PyTorch需要的格式,即形状为(批量大小, 通道数, 高, 宽)、值域在0到1之间且类型为32位浮点数。
import torchvision
transform = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()])
图像增广基于现有训练数据生成随机图像从而应对过拟合。
为了在预测时得到确定的结果,通常只将图像增广应用在训练样本上,而不在预测时使用含随机
操作的图像增广。可以从torchvision的 transforms 模块中获取有关图片增广的类。
fine-tune
步骤
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其
参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据
集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。 - 为目标模型添加⼀个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
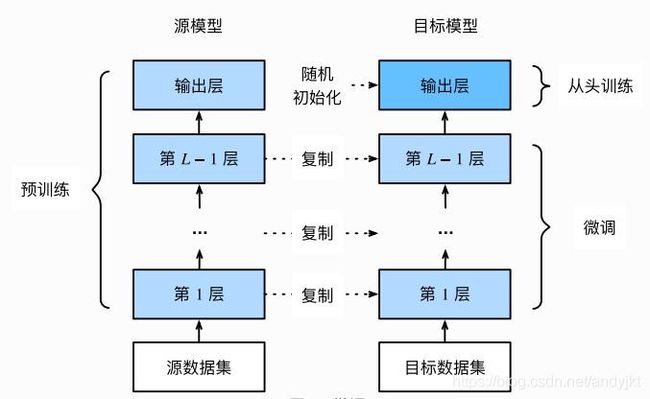
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
PyTorch可以方便的对模型的不同部分设置不同的学习参数

迁移学习将从源数据集学到的知识迁移到目标数据集上。微调是迁移学习的一种常用技术。
目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参
数。而目标模型的输出层需要从头训练。
一般来说,微调参数会使用较小的学习率,而从头训练输出层可以使用较大的学习率。
object detection
⽬标检测算法通常会在输⼊图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,
并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使
用的区域采样方法可能不同。这里我们介绍其中的⼀种方法:它以每个像素为中心生成多个大⼩和宽高
比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
bounding box

IOU




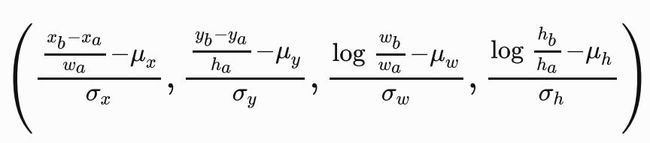


nms
在模型预测阶段,我们先为图像生成多个锚框,并为这些锚框⼀一预测类别和偏移量。随后,我们根据锚框及其预测偏移量得到预测边界框。当锚框数量较多时,同一个目标上可能会输出较多相似的预测边界框。为了使结果更加简洁,我们可以移除相似的预测边界框。常用的方法叫作非极大值抑制(nonmaximum suppression,NMS)

实践中,我们可以在执行非极大值抑制前将置信度较低的预测边界框移除,从而减小非极大值抑制的计算量。我们还可以筛选非极大值抑制的输出,例如,只保留其中置信度较高的结果作为最终输出。