opencv使用KMeans进行像素分割实例(C++与python版本)
上次写了一个KMeans的原理与实现Kmeans原理。这次使用图片进行一个实例的样本数据分割,简单来说就是对图片的各种像素值,分割为几个指定类的颜色值。
最常见的应用就是实现证件照的底色替换,或者是图像主色彩的替换,当然要完美分割不但需要KMeans的方法,还需要一些别的操作比如边缘修整等方法。
预备工作
1.将像素点作为单独的样本
在此需要使用opencv的mat函数reshape实现,便可实现将Mat对象变换到我们的样本数据
Mat cv::Mat::reshape(
int cn,
int rows = 0
)const
cn是维度,即分割为多少列,rows是图片的样本个数,即行×列
2.代码演示(C++版本)
#include 常见的读取图片操作与变量定义
// RGB 数据转换到样本数据
Mat sample_data = src.reshape(3, sampleCount);
Mat data;
sample_data.convertTo(data, CV_32F);
必须使用float类型,使用convertTo把数据转换为不同的类型
// 运行K-Means
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1);
kmeans(data, clusterCount, labels, criteria, clusterCount, KMEANS_PP_CENTERS, centers);
定义了终止条件并转换为label
// 显示图像分割结果
int index = 0;
Mat result = Mat::zeros(src.size(), src.type());
for (int row = 0; row < height; row++) {
for (int col = 0; col < width; col++) {
index = row*width + col;
int label = labels.at<int>(index, 0);
result.at<Vec3b>(row, col)[0] = colorTab[label][0];
result.at<Vec3b>(row, col)[1] = colorTab[label][1];
result.at<Vec3b>(row, col)[2] = colorTab[label][2];
}
}
关键的分割过程:首先将src复制给result,然后遍历原图的像素,并对result结果图像进行标签像素的赋值。
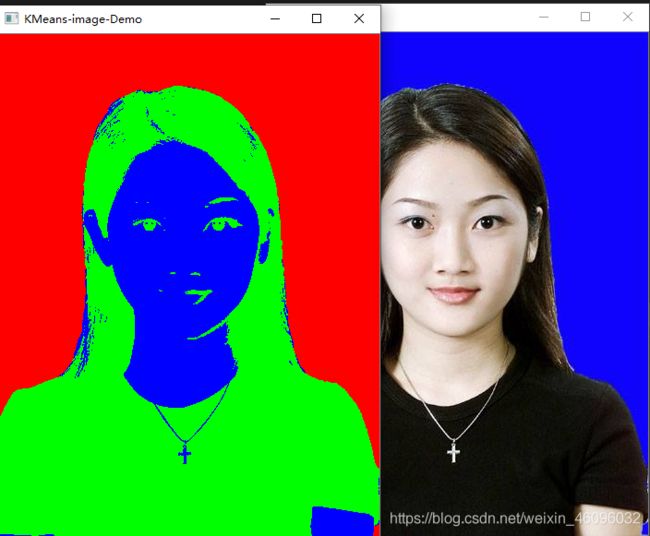
结果如图所示,可以看到原图证件照的肤色,底片蓝色和衣服头发的黑色统一分割到了一个区域,我们可以将colorTab[]第三个数据改为正常点,这样人脸部分就不会那么诡异啦。
Scalar colorTab[] = {
Scalar(0, 0, 255),
Scalar(0, 255, 0),
Scalar(211, 211, 211),
Scalar(0, 255, 255),
Scalar(255, 0, 255)
};

可以看出大部分是能够实现分割的,但是对边缘部位还是存在一定的瑕疵。
3.代码演示(python版本)
import numpy as np
import cv2 as cv
image = cv.imread('toux.jpg')
# 构建图像数据
data = image.reshape((-1,3))
data = np.float32(data)
# 图像分割
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
num_clusters = 4
ret,label,center=cv.kmeans(data, num_clusters, None, criteria, num_clusters, cv.KMEANS_RANDOM_CENTERS)
center = np.uint8(center)
res = center[label.flatten()]#使用flatten降维,赋予就近的中心label作为颜色值,进行分割分类
# 显示
result = res.reshape((image.shape))
cv.imshow('kmeans-image-demo',result)
cv.waitKey(0)
cv.destroyAllWindows()

结果显示如图