Spark3.x入门到精通-阶段一(入门&yarn集群&java和scale双语开发)
简介
Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。
特点
Apache Spark 具有以下特点:
- 使用先进的 DAG 调度程序,查询优化器和物理执行引擎,以实现性能上的保证;
- 多语言支持,目前支持的有 Java,Scala,Python 和 R;
- 提供了 80 多个高级 API,可以轻松地构建应用程序;
- 支持批处理,流处理和复杂的业务分析;
- 丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合;
- 丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行;
- 多数据源支持:支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。

集群架构
| Term(术语) | Meaning(含义) |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |

执行过程:
- 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;
- Dirver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
- Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
核心组件
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求。
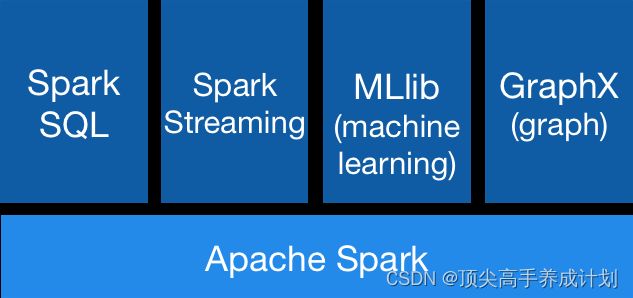
Spark SQL
Spark SQL 主要用于结构化数据的处理。其具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
- 支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性,以提高查询效率。
Spark Streaming
Spark Streaming 主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。

Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。

MLlib
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。它提供了以下工具:
- 常见的机器学习算法:如分类,回归,聚类和协同过滤;
- 特征化:特征提取,转换,降维和选择;
- 管道:用于构建,评估和调整 ML 管道的工具;
- 持久性:保存和加载算法,模型,管道数据;
- 实用工具:线性代数,统计,数据处理等。
Graphx
GraphX 是 Spark 中用于图形计算和图形并行计算的新组件。在高层次上,GraphX 通过引入一个新的图形抽象来扩展 RDD(一种具有附加到每个顶点和边缘的属性的定向多重图形)。为了支持图计算,GraphX 提供了一组基本运算符(如: subgraph,joinVertices 和 aggregateMessages)以及优化后的 Pregel API。此外,GraphX 还包括越来越多的图形算法和构建器,以简化图形分析任务。
安装集群
下载地址
Downloads | Apache Spark
链接:https://pan.baidu.com/s/1ICPb3iWvB9d7MQIHUm6gEQ
提取码:yyds
Yarn 模式
由于如果只是配置spark集群不是很通用,我们直接配置yarn运行模式
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz配置环境变量
sudo vi /etc/profile.d/my_env.sh# SPARK_HOME
export SPARK_HOME=/home/bigdata/module/spark-3.0.0-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_env.shyarn可选配置
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk/jdk1.8.0_161
export YARN_CONF_DIR=/home/bigdata/module/hadoop-3.2.3/etc/hadoop
测试提交情况
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

看到上图,说明配置成功
配置历史服务器
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled = true
spark.eventLog.dir = hdfs://master:8020/directory
spark.history.fs.logDirectory = hdfs://master:8020/directory
#yarn点击history的时候跳转到sparkhistroyserver
spark.yarn.historyServer.address = master:18080
spark.history.ui.port = 18080
hdfs目录如果不存在,需要进行创建
hadoop fs -mkdir /directory修改 spark-env.sh 文件, 添加日志配置
export JAVA_HOME=/home/bigdata/java/jdk
YARN_CONF_DIR=/home/bigdata/hadoop/hadoop/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://master:8020/directory -Dspark.history.retainedApplications=30"提交测试
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
启动spark的历史服务器
sbin/start-history-server.sh访问
http://hadoop102:18080/

弹性式数据集RDD
- 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- RDD 拥有一个用于计算分区的函数 compute;
- RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
RDD[T] 抽象类的部分相关代码如下
// 由子类实现以计算给定分区
def compute(split: Partition, context: TaskContext): Iterator[T]
// 获取所有分区
protected def getPartitions: Array[Partition]
// 获取所有依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取优先位置列表
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 分区器 由子类重写以指定它们的分区方式
@transient val partitioner: Option[Partitioner] = None原理如图

例如RDD从HDFS得到数据,更具移动数据不如移动计算的原则,匹配到每一个分区找到和自己最近的数据块进行处理,由于RDD是迭代式计算,如果想提高它的容错性,那么就的知道它前面依赖了那些数据,当数据出错的时候才能更具分区追溯回去重新计算单独分区的数据,所谓的弹性是如果它内存存 不下的时候会把一些数据存储到磁盘动态的选择存储的位置
写一个woldcount提交到集群
java版
准备一个文件
hello spark
hello java
pom.xml
org.apache.spark
spark-core_2.12
3.0.0
org.apache.spark
spark-sql_2.12
3.0.0
org.apache.spark
spark-streaming_2.12
3.0.0
org.apache.spark
spark-streaming-kafka-0-10_2.12
3.0.0
com.fasterxml.jackson.core
jackson-core
2.10.1
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
org.apache.maven.plugins
maven-shade-plugin
2.4.3
shade-my-jar
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.zhang.one.JavaWordCount
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
JavaWordCount
public class JavaWordCount {
public static void main(String[] args) {
//第一步创建配置文件
SparkConf sparkConf = new SparkConf();
//如果local表示本地运行,如果写了设置的是spark的master的url那么就是提交到spark独立模式
//启动,在用命令提交的时候注解掉,可以通过命令行参数配置,比如--master yarn就是提交到yarn
sparkConf.setMaster("local[3]")
.setAppName("javaWordCoun");
//第二步创建SparkContext
//sparkContext是会初始化DAGshedule,Taskshedule,还有注册到资源管理器
//还有Driver,Executor的资源的申请
//scala使用的是SparkContext,java使用的是JavaSparkContext
//sparksql使用的是SQLContext
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//第三步,获取数据打散以后分配到RDD的不同的分区进行处理
//textFile是读取对应的文件,得到打散以后分配到RDD的partition
JavaRDD lineTextRDD = javaSparkContext.textFile("data");
//对于partition里面的元素进行扁平化操作,元素是RDD里面最小的数据单元,
//由于textFile得到的元素一文件里面的每一行数据,所以在进行wordcount的时候
//要把一行的元素,扁平化成每一个单词
JavaRDD wordRDD = lineTextRDD.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//更具RDDF的partition里面的单词数据进行映射word->(word,1)
JavaPairRDD wordCountRDD = wordRDD.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String word) throws Exception {
return new Tuple2(word, 1);
}
});
//对于Tuple中的key相同的数据进行分组然后累加,比如(hello,1),key为hello的放到一个组里面
//reduceByKey就是v1+v2=v3,v1=v3,v2=newValue(新的值),这样一直用上一次的结果累加迭代过来的新值相加的结果
JavaPairRDD reduceCountRDD = wordCountRDD.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//上面都是一些装换操作,必须得有一个action操作他们才会执行,foreach就是其中一个action操作
reduceCountRDD.foreach(new VoidFunction>() {
@Override
public void call(Tuple2 wordCountRes) throws Exception {
System.out.println("key: "+wordCountRes._1+" count: "+wordCountRes._2);
}
});
//关闭应用上下文
javaSparkContext.close();
}
} 执行结果

打包提交到yarn执行
先在hdfa上面创建一个文件
vi data.txthello spark
hello java上传到hadoop
hadoop dfs -put data.txt /![]()
ClusterJavaWordCount
public class ClusterJavaWordCount {
public static void main(String[] args) {
//第一步创建配置文件
SparkConf sparkConf = new SparkConf();
//把setMaster("local[3]")去掉,提交的时候会指定
//sparkConf.setMaster("local[3]")
//.setAppName("javaWordCoun");
sparkConf.setAppName("javaWordCoun");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
//写成hdfs上面的路径
JavaRDD lineTextRDD = javaSparkContext.textFile("hdfs://hadoop102:8020/data.txt");
JavaRDD wordRDD = lineTextRDD.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairRDD wordCountRDD = wordRDD.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String word) throws Exception {
return new Tuple2(word, 1);
}
});
JavaPairRDD reduceCountRDD = wordCountRDD.reduceByKey(new Function2() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
reduceCountRDD.foreach(new VoidFunction>() {
@Override
public void call(Tuple2 wordCountRes) throws Exception {
System.out.println("key: "+wordCountRes._1+" count: "+wordCountRes._2);
}
});
javaSparkContext.close();
}
} maven打包

执行
bin/spark-submit --class com.zhang.one.ClusterJavaWordCount --master yarn /home/bigdata/module/spark-3.0.0-bin-hadoop3.2/original-sparkstart-1.0-SNAPSHOT.jar
提交以后foreach不打印的原因是因为foreach是在work节点指定的所以看不到
scala版本
ScalaWordCount
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaWordCount")
val context = new SparkContext(conf)
val lineTextRDD: RDD[String] = context.textFile("hdfs://hadoop102:8020/data.txt")
lineTextRDD.flatMap(line=>line.split(" "))
.map((_,1))
.reduceByKey(_+_)
.collect().foreach(println)
context.stop()
}
}打包上传执行
bin/spark-submit --class com.zhang.one.scala.ScalaWordCount --master yarn /home/bigdata/module/spark-3.0.0-bin-hadoop3.2/original-sparkstart-1.0-SNAPSHOT.jar
spark-shell版
执行
spark-shellval lineText=sc.textFile("hdfs://hadoop102:8020/data.txt")lineText.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
WordCount原理图解
