mysql 删除时间一个星期_详细MySQL基本操作

作者 | 梁凤波,Web前端工程师,慕课网认证作者
来源 | 慕课网(imooc.com)
一、数据库模型定义
创建数据库
选择数据库
修改数据库
删除数据库
查看数据库
1. 创建数据库
在MySQL中,可以使用CREATE DATABASE或CREATE SCHEMA语句创建数据库
创建数据库语法格式:
db_name 数据库命名
CHARACTER SET 指定字符集
COLLATE 指定字符集的校对规则
IF NOT EXISTS MySQL不允许同一个系统使用2个数据库相同的名字,因此需要加上IF NOT EXISTS从句,可避免错误的发生。
CREATE DATABASE [IF NOT EXISTS] db_name CHARACTER SET charset_name COLLATE collation name;实例:
实例创建一个名字为blog数据库
指定字符集为utf8mb4(关键字:CHARACTER SET)
指定字符集的校对规则(关键字:COLLATE)
加上从句IF NOT EXISTS
CREATE DATABASE IF NOT EXISTS blog DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;2. 选择数据库
在MySQL中,使用USE语句可以实现一个数据库“跳转”到另外一个数据库,在使用CREATE DATABASE 语句创建了数据库之后,该数据库不会自动成为当前数据库,需要用USE语句来指定,其语法是:
USE db_name;只有使用USE命令指定某个数据库为当前的数据库之后,才能对该数据库及其存储的数据对象执行各种的后续操作。
3. 修改数据库
在MySQL中,可以使用ALTER DATABASE或ALTER SCHEMA语句来修改已经被创建的数据库的相关参数,其语法是:
ALTER {DATABASE | SCHEMA} [db_name] alter_specification ... 实例:
修改已有数据库blog的默认字符集和校对规则
ALTER DATABASE blog DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;4. 删除数据库
在MySQL中,当需要删除已创立的数据库时,可以使用DROP DATABASE或 DROP SCHEMA语句进行删除,其语法格式是:
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name;实例:
删除名字为blog的数据库
DROP DATABASE IF EXISTS blog;选项IF EXISTS可以避免删除不存在的数据库时出现MySQL错误的信息,另外特别注意:使用DROP DATABASE或DROP SCHEMA语句会删除指定的整个数据库,该数据库中的所有表包括其数据也将永久删除,因此使用该语句时候,需要谨慎,以免错误删除。
5. 查看数据库
在MySQL中,可以使用SHOW DATABASES或 SHOW SCHEMAS语句查看可用的数据库列表,其语法是:
SHOW {DATABASES | SCHEMAS} [LIKE 'pattern']此选项中“LIKE”关键字用于匹配指定的数据库名称
查看当前数据库编码:
SHOW CREATE DATABASE db_name;实例:
SHOW DATABASES;SHOW DATABASES LIKE "blog";SHOW CREATE DATABASE blog;二、数据表定义
创建表
更新表
重名表
删除表
查看表
1. 创建表
在MySQL中,可以使用CREATE TABLE语句创建表。
语法格式为:
CREATE TABLE tbl_name(字段名1 数据类型 [列级完整性约束条件][默认值],字段名2 数据类型 [列级完整性约束条件][默认值],[...][, 表级完整性约束条件])[ENGINE=引擎类型];实例:
在已有数据库 blog 中新建一个包含客户姓名,性别,地址,联系方式等内容的客户基本信息表,要求将客户的id号设置为该表的主键。
USE blog;CREATE TABLE customers( cust_id INT NOT NULL AUTO_INCREMENT COMMENT '主键(自增长)', cust_name CHAR(50) NOT NULL COMMENT '客户姓名', cust_sex tinyint(2) NOT NULL DEFAULT 1 COMMENT '客户性别 1-男,2-女', cust_address CHAR(50) NULL COMMENT '客户地址', cust_contact CHAR(50) NULL COMMENT '客户联系方式',PRIMARY KEY(cust_id))COMMENT = '客户表' ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;介绍关键字:
数据类型 :数据类型是指系统中所允许的数据的类型,如整形的int,浮点型的double,布尔型的bool,日期和时间类型的date,时间戳timestamp,时间型time,字符串类型char,可变长字符串型varchar,空间数据类型等.
AUTO_INCREMENT:表示为数据类型为整形的列设置自增属性,从而能实现当插入数据时候,该列的值会被自动设置为“当前表中该列的最大值加1”。
DEFAULT:指定默认值,插入数据库时,如果没有明确给出某列的所对应的值,则DBMS此时允许为此列表指定的一个值。
NULL:NULL 值是指没有值或缺值,设置NULL允许插入时,可以允许不给出该列的值,该值默认NULL,如果设置NOT NULL,那么在插入或更新的时候,该列必须要有值。
PRIMARY:主键,主键值必须唯一,即表中每个行必须要具有唯一的主键值,而且主键值一定要设置为NOT NULL
COMMENT 添加注释,方便日后查看或别的伙伴看到你的代码清晰知道其意。
2. 更新表
创建MySQL表后,有时需要对创建的表的结构进行修改或调整,可以使用ALTER TABLE语句来更改原有的表结构,例如可以修改表的增加或删除列,创建或取消索引,更改原有咧的数据类型,重新命名列或表,还可以更改表的评注和表的引擎类型
2.1. 新增列
如果需要向表增加新列,可以使用 ALTER TABLE 语句中添加 ADD [COLUMN] 子句来实现,也可以同时增加多个列。
需求:
向数据库 blog 的表的 customers中添加一列,并命名为 cust_city,用于表述客户所在的城市,要求其不能为NULL,默认值为字符串’GuangZHou’,且位于原表的cust_sex列之后。
ALTER TABLE blog.customers ADD COLUMN cust_city CHAR(10) NOT NULL DEFAULT 'GuangZhou' AFTER cust_sex;2.2. 修改表中的列的名称或数据类型
如果想修改表中的名称或数据类型,可以在 ALTER TABLE 语句中添加 CHANGE [COLUMN] 子句。
CHANGE [COLUMN] 子句可同时修改指定列的名称和数据类型,且在ALTER TABLE语句中同时放入多个CHANGE [COLUMN]子句,只需彼此之间用逗号分隔。
实例:
将数据库blog中表的customers的cust_sex列重命名为sex,且将其数据类型更改为字符长度为1的字符数据类型char(1),允许其为NULL,默认值为字符常量’M’:
ALTER TABLE blog.customers CHANGE COLUMN cust_sex sex CHAR(1) NULL DEFAULT 'M';2.4. 修改或删除表中指定的默认值
修改或删除表中指定的默认值,可在ALTER TABLE 语句中添加 ALTER [COLUMN]子句。
实例:
将数据库 blog 中表 customers 的cust_city 列的默认值修改为字符常量’Beijing’:
ALTER TABLE blog.customers ALTER COLUMN cust_city SET DEFAULT 'Beijing';2.5. 修改指定列的数据类型
MODIFY [COLUMN]与CHANGE [COLUMN] 有所不同,在ALTER TABLE 语句中添MODIFY [COLUMN]子句只会修改指定列的数据类型,不会干涉他的列名,另外还可以通过关键字FIRST或AFTER修改指定列表中的位置。
实例:
将数据库 blog 中表customers中的cust_name列的数据类型由之前的字符串长度为50的定长字符数据类型char(50)更改为字符长度为20的定长字符数据类型char(20),并且将此列设置为第一列。
ALTER TABLE blog.customers MODIFY COLUMN cust_name char(20) FIRST;ALTER TABLE blog.customers MODIFY COLUMN cust_name char(20) AFTER cust_id;2.6. 删除数据表列
通过ALTER TABLE语句中添加DROP [COLUMN]子句来完成操作,一旦执行删除操作后,
原本储存的一切内容会跟着被卸除,所以执行该命令需要谨慎。
实例:
删除数据库blog 中表customers的cust_contact列
ALTER TABLE blog.customers DROP COLUMN cust_contact;2.7. 重命名表-ALTER
在 ALTER TABLE语句中,可以添加RENAME[TO]子句为表重新赋予一个表名字
实例:
使用RENAME [TO]子句,重命名数据库 blog 中表 customers的表名为backup_customers:
ALTER TABLE blog.customers RENAME TO blog.backup_customers;3. 重命名表-RENAME
使用RENAME TABLE语句来更改表的名字,并且可以同时命名多个表,其语法是:
RENAME TABLE tbl_name TO new_tbl_name [, tbl_name2 TO new_tbl_name2] ..实例:
把数据库blog的backup_customers表改名为new_customers
RENAME TABLE blog.backup_customers TO blog.new_customers;4. 删除表
如果需要删除数据库中的一个存在的表,可以通过 DROP TABLE语句来实现,其语法是:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name2] .. [RESTRICT | CASCADE]实例:
删除数据库blog的new_customers表
DROP TABLE IF EXISTS new_customers;5. 查看表
在数据库中,查看表包括显示表的名称和结构的2种情况。
5.1. 显示表的名称
在MySQL中,可以使用SHOW TABLES语句来显示指定数据库中存放的所有表名,其语法是:
SHOW [FULL] TABLES [{FROM | IN} db_name]实例:
显示数据库blog中的所有表名
USE blog;SHOW TABLES;5.2. 显示表的结构
在mysql中,可以使用 SHOW COLUMNS 语句来显示指定数据表的结构,其语法格式:
SHOW [FULL] COLUMNS {FROM | IN} tbl_name [{FROM | IN} db_name] [LIKE 'pattern' | WHERE expr]或者使用DESCRIBE 语句来完成,其语法格式为:
{DESCRIBS | DESC} tbl_name [col_name | wild]实例:
显示数据库blog中表的customers的结构
DESC blog.customers;5.3.查看表编码
SHOW CREATE TABLE tbl_name;5.4.查看字段编码
SHOW FULL COLUMNS FROM tbl_name;三、数据更新
数据更新操作有三种:向表中添加若干行数据,修改表中的数据,和删除表中的若干行数据,在SQL中有三类相对应的语句,分别是插入数据(INSERT),修改数据(UPDATE)和删除数据(DELETE)。
插入数据
删除数据
修改数据
1. 插入数据
在MySQL中,可以使用INSERT语句,向数据库中一个已有的表插入一行或多行元组数据。
INSERT语句有2种语法形式,分别是:
INSERT..VALUES
INSERT..SET
1.1. 使用INSERT..VALUES语句插入单行或多行元组数据
INSERT [INTO] tbl_name [(col_name, ...)] {VALUES | VALUE} ({expr | DEFAULT}),(...),,,实例:
向数据库blog的表customers中插入一行完整数据:(1, ‘梁凤波’, 1, ‘广州市’, ‘越秀区’)
INSERT INTO blog.customers VALUES(1, '梁凤波', 1, '广州市', '越秀区');使用INSERT .. VALUES语句向数据库blog的表customers插入一行数据,cust_id列由系统自动生成,cust_sex列选用表中默认值,另外cust_contact列值不确定,可不用确定。
INSERT INTO blog.customers VALUES(0, 'Lynn', DEFAULT, '深圳市', NULL);插入时候,每个列必须提供一个值:
INSERT INTO blog.customers(cust_id, cust_name, cust_sex, cust_address, cust_contact) VALUES(0, 'Bob', 1, '广州市', NULL);1.2.使用INSERT .. SET语句插入部分列值的数据
语法:
INSERT [INTO] tbl_name SET col_name = {expr | DEFAULT}, ...插入数据实例:
INSERT INTO blog.customers SET cust_name='Peter', cust_address='武汉市',cust_sex=DEFAULT;2. 删除数据
在MySQL中,可以使用DELETE语句删除表中的一行或多行数据。其语法格式是:
DELETE FROM tbl_name [WHERE where_condition]实例:
删除数据库blog的customers中客户id为1的数据
DELETE FROM blog.customers WHERE cust_id=1;3. 修改数据
在MySQL中,可以使用UPDATE语句来修改更新一个表中的数据,起语法格式是:
UPDATE tbl_name SET col_name={expr | DAFAULT} [,col_name2={expr | DEFAULT}].. [WHERE where_condition] [ORDER BY..] [LIMIT row_count]实例:
修改数据库blog的表customers中ID为7的客户地址更新为北京市
UPDATE blog.customers SET cust_address='北京市' WHERE cust_id=7;四、数据查询
SELECT语句查询
列的选择与指定查询
FROM子句与多表连接查询
WHERE 子句与条件查询
GROUP BY 子句与分组数据
HAVING子句
ORDER BY 子句
LIMIT子句
1. SELECT语句查询
数据查询是使用SELECT语句进行数据查询,该功能强大,使用灵活,其数学理论基础是关系数据模型中对表对象的一组关系运算,即选择,投影和连接。
SLECT语句中各子句的使用次序及说明
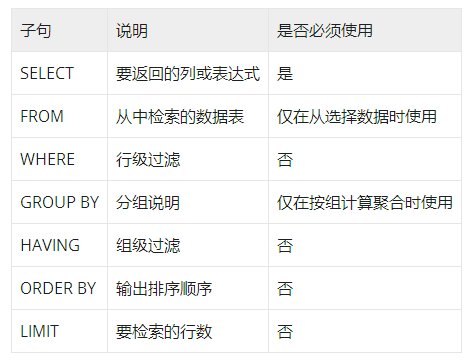
2. 选择指定的列查询
SELECT cust_name, cust_sex, cust_address FROM blog.customers;2.1. 查询表的所有信息
SELECT * FROM blog.customers;2.2. 查询定义并使用列的别名
SELECT cust_name, cust_address as 地址, cust_contact FROM blog.customers;2.3. 替换查询结果集合中的数据
SELECT cust_name, CASE WHEN cust_sex=1 THEN '男' ELSE '女' END AS 性别 FROM blog.customers;2.4. 计算列值
使用SELECT语句对列进行查询时候,在结果集中可以输出对列值计算后的值,如在查询时候,对cust_id加上数字100的值
SELECT cust_name,cust_sex,cust_id+100 FROM blog.customers;3. FROM子句与多表链接查询
SELECT * FROM tbl1 CROSS JOIN tbl2;SELET * FROM tb1,tb2;3.1. 内连接查询
内链接是一种最常见的连接类型,它是通过查找中设置链接条件的方式,来移除查询集合中某些数据行之后的交叉链接。简单来说就是利用条件判断表达式中的比较运算符来组合两张表的记录,其目的是为了消除交叉中的某些数据行。
其语法是:
SELECT some_columnsFROM tableINNER JOIN table2ON some_conditions;实例:
SELECT * FROM customers INNER JOIN customers2 ON customers.cust_name = customers2.cust_name;3.2. 外连接查询
SELECT * FROM customers LEFT JOIN customers2 ON customers.cust_name = customers2.cust_name;尽管优肯对2张表分别使用内连接和外连接之后,可能返回的结果相同,但实质上这两类连接操作的语义是不同的,他们的差别在于外连接一定会在结果集中提供数据行,无论该行数据能否在另外一张表找出相匹配的数据行。
4.WHERE子句与条件查询
比较运算符

4.1. 条件查询
在数据库blog的表customers中查找所有男性客户的信息
SELECT * FROM blog.customers WHERE cust_sex=1;4.2. 判断范围查询
4.2.1.在数据库blog的表customers中查询客户id在1~100直接的信息数据
SELECT * FROM bolog.customers WHERE cust_id BETWEEN 1 AND 100;4.2.2.在数据库blog的表customers中查询客户id号1,9,和19号的三个客户信息
SELECT * FROM blog.customers WHERE cust_id IN(1,9,19);4.2.3.判断空值
当需要判定一个表达式是否为空值时,可以使用关键字“IS NULL”来实现
SELECT cust_name FROM blog.customers WHERE cust_contact IS NULL;4.3子查询
子查询,即可嵌套在其他SELECT查询中的SELECT查询
例如:学生信息登记表tb_sudent和学生成绩表tb_score,使用子查询的方式查询所选课程高于80分的学生学号和姓名信息
SELECT studentNo,studentName FROM tb_sudent WHERE studentNo IN(SELECT studentNo FROM tb_score WHERE score > 80);5.GROUP BY 子句与分组数据
在SELECT语句中,运行试验GROUP BY子句,将结果集合的数据进行根据选择列的值进行逻辑分组:
其语法格式为:
GROUP BY {col_name | expr | postion}[ASC |DESC], ... [WITH ROLLUP]实例一:在数据库blog的表customers中查询获取一个数据结果集,要求该结果中分别包含每个相同地址的男性客户人数和女性客户人数。
SELECT cust_address,cust_sex, COUNT(*) AS '人数' FROM blog.customers GROUP BY cust_address,cust_sex;输出结果:
+--------------+----------+--------+| cust_address | cust_sex | 人数 |+--------------+----------+--------+| 北京市 | 1 | 1 || 武汉市 | 0 | 2 |+--------------+----------+--------+2 rows in set (0.00 sec)实例二:在数据库blog的表customers中查询获取一个数据结果集,要求该结果中包含每个相同地址的男性客户人数,女性客户人数,总人数以及客户的总人数。
SELECT cust_address,cust_sex, COUNT(*) AS '人数' FROM blog.customers GROUP BY cust_address,cust_sex WITH ROLLUP;输出结果:
+--------------+----------+--------+| cust_address | cust_sex | 人数 |+--------------+----------+--------+| 北京市 | 1 | 1 || 北京市 | NULL | 1 || 武汉市 | 2 | 2 || 武汉市 | NULL | 2 || NULL | NULL | 3 |+--------------+----------+--------+5 rows in set (0.00 sec)6.HAVING子句
在SELECT子句中,除了能使用GROUP BY子句分组数据之外,还可以使用HAVING子句来过滤分组
SELECT cust_name,cust_address FROM blog.customers GROUP BY cust_address,cust_name HAVING COUNT(*) <= 3;输出结果:
mysql> SELECT cust_name,cust_address FROM blog.customers GROUP BY cust_address,cust_name HAVING COUNT(*) <= 3;+-----------+--------------+| cust_name | cust_address |+-----------+--------------+| Peter | 北京市 || Peter | 武汉市 |+-----------+--------------+7.ORDER BY 子句
在SELECT语句中,可以使用ORDER BY子句将集中的数据按一定的顺序进行排序,否则结果集中数据行的顺序是不可预料的。其语法格式为:
DRDER BY {col_name | expr | postion} [ASC | DESC], .. 实例:在数据库blog的表customers中依次按照客户姓名和地址的降序方式,输出客户的姓名和性别。
SELECT cust_name, cust_sex FROM blog.customers ORDER BY cust_name DESC, cust_address DESC;输出结果:
+-----------+----------+| cust_name | cust_sex |+-----------+----------+| Peter | 0 || Peter | 0 || Peter | 1 |+-----------+----------+3 rows in set (0.00 sec)8. LIMIT子句
当使用SELECT语句返回的结果集中行数很多时候,为了便于用户对结果浏览和操作,使用LIMIT子句来限制被SELECT语句返回的行数。其语法格式:
LIMIT {[offset,] row_count | row_count OFFSET offset}实例:在数据库blog的表customers中查找索引为1到索引3的客户姓名信息
SELECT cust_id,cust_name FROM blog.customers ORDER BY cust_id LIMIT 1,3;也可以写成这样:
SELECT cust_id,cust_name FROM blog.customers ORDER BY cust_id LIMIT 3 OFFSET 1;总结
本文章详细介绍了MySQL的基本使用,并且详细介绍了关系数据库各种基本操作的SQL语句,主要包括数据的定义,数据的更新,数据的查询等内容。
希望对你学习MySQL有帮助,谢谢!
ps:喜欢作者文章的也可点击原文链接去慕课网关注他哦。

● 用CSS3实现王者荣耀匹配人员加载页面
● JAVA 泛型意淫之旅
● 为什么部分程序员下班后只关显示器不关电脑?
● 龙岗一个月350的出租房,我搬出来了
— 完 —
