ML-Agents案例之看图配对
本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents,本文是详细的配套讲解。
本文基于我前面发的两篇文章,需要对ML-Agents有一定的了解,详情请见:Unity强化学习之ML-Agents的使用、ML-Agents命令及配置大全。
我前面的相关文章有:
ML-Agents案例之Crawler
ML-Agents案例之推箱子游戏
ML-Agents案例之跳墙游戏
ML-Agents案例之食物收集者
ML-Agents案例之双人足球
Unity人工智能之不断自我进化的五人足球赛
ML-Agents案例之地牢逃脱
ML-Agents案例之金字塔
ML-Agents案例之蠕虫
ML-Agents案例之机器人学走路
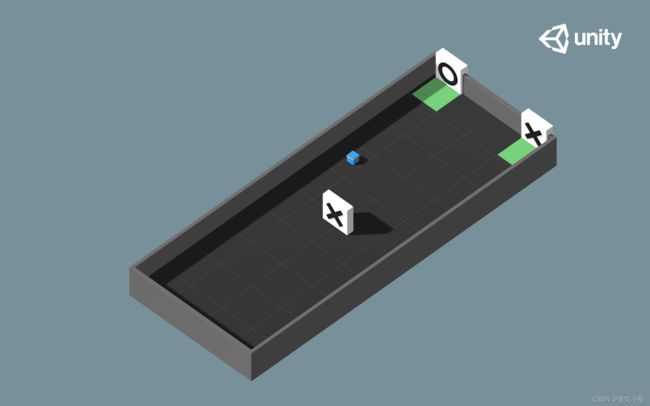
环境说明
如图所示,这个案例官方称其为Hallway,智能体需要根据前面给的符号来去后面选择对应的符号,注意,这个案例的难点在于,智能体在选择时是看不到给定的符号的,而我们的程序并不会帮助智能体去记录看过的信息,这就要求智能体自己拥有记忆功能,即神经网络能够自己学习出“以前看到过什么现在就选什么”这种行为模式,因此拥有记忆功能的循环神经网络中的大哥LSTM是必不可少的。而这在ML-Agents中只需要配置一下文件就能做到。
状态输入:首先智能体用了射线传感器Ray Perception Sensor 3D,一共发射5条射线,检测的标签有给定的O、给定的X、目标的O、目标的X、墙壁,一共5个标签。对于射线传感器的详细讲解请查看ML-Agents案例之推箱子游戏。


另外,程序中还给了一个已执行的步数除以最大步数来作为输入,随着游戏的运行而增大,当episode结束时这个值会等于1,个人认为这个输入作用不大,可有可无。
动作输出:动作输出只有一个离散输出,这个输出有0-4共5个值可供选择。0代表什么都不做,1代表前进,2代表后退,3代表右转,4代表左转。
因此Behavior Parameters设置如下:

代码讲解
智能体下挂载的脚本除去万年不变的Decesion Requester,Model Overrider,Behavior Parameters,以及刚刚说明的Ray Perception Sensor 3D,就只剩下智能体的只有文件HallwayAgent.cs了:
初始化方法Initialize():
public override void Initialize()
{
// 寻找控制环境的脚本
m_HallwaySettings = FindObjectOfType<HallwaySettings>();
// 获取刚体
m_AgentRb = GetComponent<Rigidbody>();
// 获取渲染,便于改变材质
m_GroundRenderer = ground.GetComponent<Renderer>();
// 获取初始材质
m_GroundMaterial = m_GroundRenderer.material;
// 获取配置文件中的数据
m_statsRecorder = Academy.Instance.StatsRecorder;
}
状态输入CollectObservations方法:
public override void CollectObservations(VectorSensor sensor)
{
// 可在编辑器中选择用或不用
if (useVectorObs)
{
// 输入现在已执行步数除以最大步数
sensor.AddObservation(StepCount / (float)MaxStep);
}
}
动作输出方法OnActionReceived:
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 时间惩罚,激励智能体越快完成越好
AddReward(-1f / MaxStep);
MoveAgent(actionBuffers.DiscreteActions);
}
public void MoveAgent(ActionSegment<int> act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
// 获取神经网络的第一个也是唯一一个离散输出
var action = act[0];
// 给离散输出赋予各个值的意义
switch (action)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
case 3:
rotateDir = transform.up * 1f;
break;
case 4:
rotateDir = transform.up * -1f;
break;
}
// 执行输出
transform.Rotate(rotateDir, Time.deltaTime * 150f);
m_AgentRb.AddForce(dirToGo * m_HallwaySettings.agentRunSpeed, ForceMode.VelocityChange);
}
每一个episode(回合)开始时执行的方法OnEpisodeBegin:
public override void OnEpisodeBegin()
{
var agentOffset = -15f;
var blockOffset = 0f;
// 取随机数0或1
m_Selection = Random.Range(0, 2);
// 如果是0,场上出现O,位置作一定的随机
if (m_Selection == 0)
{
symbolO.transform.position =
new Vector3(0f + Random.Range(-3f, 3f), 2f, blockOffset + Random.Range(-5f, 5f))
+ ground.transform.position;
symbolX.transform.position =
new Vector3(0f, -1000f, blockOffset + Random.Range(-5f, 5f))
+ ground.transform.position;
}
// 如果是1,场上出现X,位置作一定的随机
else
{
symbolO.transform.position =
new Vector3(0f, -1000f, blockOffset + Random.Range(-5f, 5f))
+ ground.transform.position;
symbolX.transform.position =
new Vector3(0f, 2f, blockOffset + Random.Range(-5f, 5f))
+ ground.transform.position;
}
// 初始化智能体的位置和旋转,并作一定的随机,速度归零
transform.position = new Vector3(0f + Random.Range(-3f, 3f),
1f, agentOffset + Random.Range(-5f, 5f))
+ ground.transform.position;
transform.rotation = Quaternion.Euler(0f, Random.Range(0f, 360f), 0f);
m_AgentRb.velocity *= 0f;
// 取随机数0或1
var goalPos = Random.Range(0, 2);
// 当随机数为0时,目标的O放右边,X放左边
if (goalPos == 0)
{
symbolOGoal.transform.position = new Vector3(7f, 0.5f, 22.29f) + area.transform.position;
symbolXGoal.transform.position = new Vector3(-7f, 0.5f, 22.29f) + area.transform.position;
}
// 当随机数为1时,目标的O放左边,X放右边
else
{
symbolXGoal.transform.position = new Vector3(7f, 0.5f, 22.29f) + area.transform.position;
symbolOGoal.transform.position = new Vector3(-7f, 0.5f, 22.29f) + area.transform.position;
}
// 添加用于报告的统计信息(键值对),这些值将出现在Tensorboard中
m_statsRecorder.Add("Goal/Correct", 0, StatAggregationMethod.Sum);
m_statsRecorder.Add("Goal/Wrong", 0, StatAggregationMethod.Sum);
}
这里需要说明的是最后两行代码是在Tensorboard添加了两个新的表格,第一个参数是表格的标签,即键,第二个是指,第三个是可选的变量,可选的有Average,MostRecent,Sum,Histogram。
当与别的物体开始发生碰撞执行方法OnCollisionEnter:
void OnCollisionEnter(Collision col)
{
if (col.gameObject.CompareTag("symbol_O_Goal") || col.gameObject.CompareTag("symbol_X_Goal"))
{
// 当匹配成果时
if ((m_Selection == 0 && col.gameObject.CompareTag("symbol_O_Goal")) ||
(m_Selection == 1 && col.gameObject.CompareTag("symbol_X_Goal")))
{
// 奖励1分
SetReward(1f);
// 改变成绿色的材质0.5秒
StartCoroutine(GoalScoredSwapGroundMaterial(m_HallwaySettings.goalScoredMaterial, 0.5f));
// 在Tensorboard成功项中给智能体加一分
m_statsRecorder.Add("Goal/Correct", 1, StatAggregationMethod.Sum);
}
// 当匹配失败时
else
{
SetReward(-0.1f);
StartCoroutine(GoalScoredSwapGroundMaterial(m_HallwaySettings.failMaterial, 0.5f));
// 在Tensorboard失败项中给智能体加一分
m_statsRecorder.Add("Goal/Wrong", 1, StatAggregationMethod.Sum);
}
// 结束游戏
EndEpisode();
}
}
// 携程,短暂改变材质
IEnumerator GoalScoredSwapGroundMaterial(Material mat, float time)
{
m_GroundRenderer.material = mat;
yield return new WaitForSeconds(time);
m_GroundRenderer.material = m_GroundMaterial;
}
当智能体没有模型,人想手动录制示例时可以采用Heuristic方法:
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[0] = 3;
}
else if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
else if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[0] = 4;
}
else if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
}
配置文件
PPO算法:
behaviors:
Hallway:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 1024
learning_rate: 0.0003
beta: 0.03
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory:
sequence_length: 64
memory_size: 128
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 64
summary_freq: 10000
SAC算法:
behaviors:
Hallway:
trainer_type: sac
hyperparameters:
learning_rate: 0.0003
learning_rate_schedule: constant
batch_size: 512
buffer_size: 200000
buffer_init_steps: 0
tau: 0.005
steps_per_update: 10.0
save_replay_buffer: false
init_entcoef: 0.1
reward_signal_steps_per_update: 10.0
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory:
sequence_length: 64
memory_size: 128
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 4000000
time_horizon: 64
summary_freq: 10000
可以看到,相比也平常的配置,中间加入了一部分:
memory:
sequence_length: 64
memory_size: 128
默认不加这部分的时候,我们的模型中是没有循环神经网络的,当我们设置了这个参数后,相当于给模型加入了一个LSTM,sequence_length指的是需要记住的经验序列长度,memory_size是智能体保存的记忆大小,必须是2的倍数。我们要合理设置参数,设置过大将大大降低训练速度,过小会导致记不住东西。
效果演示

后记
本案例主要探讨了ML-Agents中智能体的“记忆力”是怎么实现的,我们可以通过在配置文件中设置相应的参数来给我们的模型添加上LSTM,让智能体先观察,后做“选择题”,就能训练出一个具有记忆力的智能体。