图解BERT、ELMo(NLP中的迁移学习)| The Illustrated BERT, ELMo, and co.
看我看我
这是我翻译这位大佬的第二篇文章了,我计划是翻译四篇,(Transformer、BERT、GPT-2、GPT-3),翻译授权见最后。
之前的工作:
- 图解transformer | The Illustrated Transformer
- 图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)
这部分内容为我主观注释,和原作无关。
文章目录
- 看我看我
- 正文
-
- 举个:chestnut: :句子分类
- 模型结构
-
- 模型输入
- 模型输出
- 与卷及网络类似
- Embedding新纪元
-
- 简要回顾词嵌入Word Embedding
- ELMo: 上下文语境很重要
- ULM-FiT:将迁移学习引入NLP
- Transformer:超越LSTMs的存在
- GPT:对Transformer的Decoder进行预训练的语言模型
- 迁移到下游任务
- BERT:不用Decoder了,我们来用encoder
-
- 掩码语言模型 Masked Language Model
- 两个句子的任务
- Task specific-Models
- BERT 的特征抽取
- 带BERT出去炫
- Jay Alammar's Blog
正文
2018年是NLP模型发展的转折点。我们不断探索单词和句子的表示方法,以求能最好地捕捉其中潜在的语义和关系。此外,NLP领域已经提出了一些功能强大的组件,你可以免费下载,并在自己的模型和pipeline中使用它们(这被称为NLP领域的ImageNet时刻,类似的发展在几年前也是这么加速计算机视觉领域的机器学习的)。
我来解释一下:
在CV(Computer Vision)领域,预训练+微调已经应用很久了。他们有在ImageNet上训练好的模型可以直接拿去用。但是在NLP(Natural Language Processing)领域并没有像ImageNet那样大的带标签的数据集。因此NLP领域迟迟没有大型预训模型,还是停留在比较低层次的研究上。
GPT的出现让研究人员看到了曙光,我们使用无标签数据也能做出大模型用于微调。从原来的静态词向量到Transformer的动态词向量,再到使用无标签数据预训练模型并用于微调,简直是开创性的工作。同年又涌现出了BERT。所以那一年真的是开辟了NLP领域工作的新时代。
在后边本文的作者会说“BERT被认为是NLP新时代的开始”,我不是很同意这个说法,我认为GPT是新时代的开始。
ULM-FiT和Cookie Monster没关系,但我一时半会儿没想到别的角色表示…….
Cookie Monster是芝麻街里边一个吃饼干的蓝色小怪兽。BERT是芝麻街里另一个黄色的角色。

在这一发展过程中,最新的里程碑工作之一是BERT。BERT被认为标志着NLP新时代的开始 。BERT模型在自然语言处理任务方面打破了多项记录。
BERT论文发布不久之后代码就开源了,还提供了可以直接下载的 已经在大型数据集上预训练好的模型。
这是一个重大的发展,BERT模型可以作为一个组件,任何人都可以借助它建立一个NLP模型, 从而节省了从头开始训练语言处理模型所需的时间、精力、知识和资源。
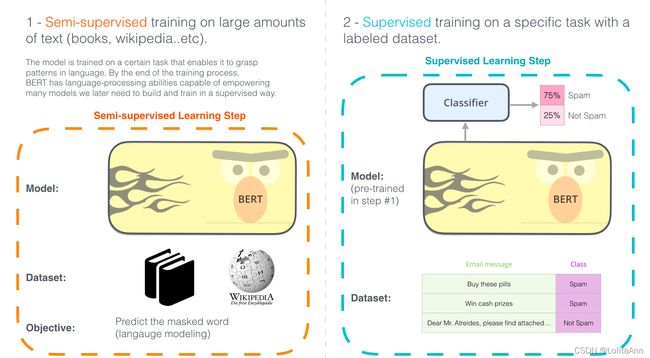
使用BERT的两个步骤:下载在步骤1中已经在无标签数据上预训练好的模型,只需要考虑步骤2的的微调。
BERT 是建立在近期NLP领域中涌现的许多聪明想法之上的,包括但不限于半监督学习、ELMo、ULMFiT、GPT 和 Transformer。
为了正确理解BERT是什么,我们需要了解许多概念。
在了解模型本身所涉及的概念之前,让我们先看看BERT的使用方法。
举个 :句子分类
使用BERT最直接的方法是使用它对一段文本进行分类。这个模型看起来是这样的:
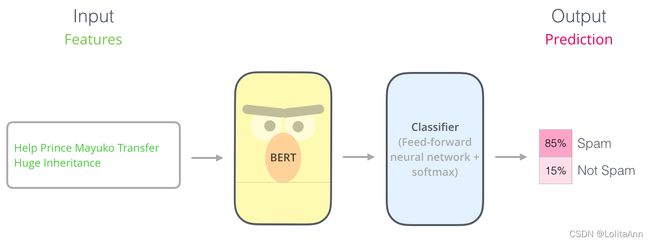
为了训练一个基于BERT的分类模型,你主要需要训练分类器(Classifier),BERT模型仅需要微小的改动,这样的训练过程被称为微调,微调起源于半监督学习和ULMFiT。
但对于不熟悉这个话题的人来说,既然我们谈论的是分类器,那么我们就进入了机器学习的监督学习领域。这意味着我们需要一个有标记的数据集来训练这样的模型。看看下边的例子,一个垃圾邮件分类器的带标签的数据集,有两部分:一个电子邮件消息列表和一个标签(标签标记每个邮件为“垃圾邮件”或“不是垃圾邮件”)。

其他用法比如:
……
BERT能做的事情有很多,现在几乎各个子任务都能看到BERT及其变体。
模型结构
现在,你已经知道了BERT如何使用的一些例子,让我们仔细看看它是如何工作的。

BERT论文中提出了两个尺寸的BERT模:
- BERT-base:和GPT一样大,因为要和GPT比较性能
- BERT-large:一个大得离谱的模型,论文中的SOTA就是这个模型实现的。
- 看一下没被紫色标记的那句话。我看论文的时候就觉得这句话写的贱嗖嗖的,指名道姓喊话GPT。
- 对于第二点,在当年来看这个模型确实大的离谱,不过身处2022年的我们可以知道,BERT已经算是普通实验室可以微调的良心小模型了。

BERT基本上是用Transformer的Encoder组件堆起来的。
是时候向你们介绍我之前写的《图解Transformer》了,这篇文章介绍了Transformer模型。想要了解我们接下来要介绍的东西,一定要先了解Transformer。

两种尺寸的BERT模型都有大量的Encoder组件(论文里叫Encoder组件为Transformer block)。
| 模型 | Encoder层数 | 隐藏单元大小 | 多头注意力数量 |
|---|---|---|---|
| Transformer | 6 | 512 | 8 |
| BERT-base | 12 | 768 | 12 |
| BERT-large | 24 | 1024 | 16 |
模型输入
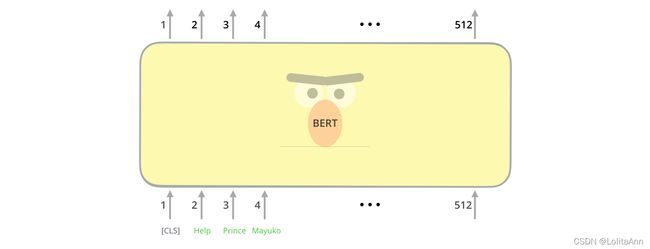
第一个输入token是默认提供的一个特殊的[CLS]token,原因后面再说明。CLS在这里代表分类。
就是你不管输入序列是什么东西,模型都会给你加上一个
[CLS]做为开头第一个token。
和Transformer的普通的encoder一样,BERT将一个单词序列作为输入,该序列在组件堆栈中不断向上流动。每一层都施加自注意力,并通过前馈网络传递其结果,然后将其传递给下一个encoder组件。

就架构而言,到目前为止,它和Transformer是相同的(除了大小,当然大小是我们可以自己设置的超参数)。在输出部分,我们才能开始看到不同的地方。
模型输出
每个位置输出一个大小为hidden_size(BERT-base为768)的向量。对于上面说的句子分类那个例子,我们只需要关注第一个位置的输出(就是我们之前传入特殊[CLS]token的那个位置)。

这个向量现在可以用作我们分类器的输入。论文中仅使用单层神经网络作为分类器就取得了很好的效果。

如果你有更多的标签(比如你是一个电子邮件服务提供者,需要将电子邮件标记为“垃圾邮件”、“非垃圾邮件”、“社交”和“推广”),那只需调整分类器的网络结构,使其可以做多分类即可。
与卷及网络类似
对于那些有计算机视觉基础的人来说,这种向量传递应该会让人联想到一些网络(例如VGG)的卷积部分和网络后边的全连接分类部分。

Embedding新纪元
新的发展带来了文字编码方式的转变。词嵌入一直是NLP模型处理语言的主力军,像Word2Vec和Glove这样的方法已经获得了广泛应用。在说新变化之前我们先来回顾一下之前的词嵌入编码方式。
简要回顾词嵌入Word Embedding
如果想用机器学习模型来处理单词的话,你需要先将单词转化为模型能够计算的数值表示。Word2Vec表明我们可以使用向量表示单词,并捕捉其语义和含义关系,以及句法和语法关系。
- 语义和含义关系例如:能够分辨单词是相似的还是相反的。能够区分像“斯德哥尔摩”和“瑞典”与“开罗”和“埃及”之间的关系是相同。
- 句法和语法关系例如:“had”和“has”之间的关系与“was”和“is”之间的关系相同。
人们很快意识到,我们可以直接在大量文本数据上预训练好embedding,而不是对每个模型的小数据都进行embedding训练。之后就可以直接下载通过Word2Vec或GloVe预训练好的单词及其embedding列表。下图单词“stick”的GloVe的词嵌入示例(embedding向量大小为200)

单词“stick”的GloVe词嵌入是由200个浮点数组成的向量(四舍五入到两位小数)。
因为这些向量都很长,画那么多格子不切实际,之后我会用这样少数几个格子来表示词嵌入向量。
![]()
ELMo: 上下文语境很重要
如果我们使用GloVe的那些词嵌入,那么不管上下文是什么,单词“stick”都将由这个向量表示。许多自然语言处理研究人员说,“(尔康手)等等!‘stick’有多种含义!具体意思取决于它的使用位置。为什么我们不根据上下文语境进行embedding呢?这样既能捕捉该语境中的含义,又捕捉其他语境信息。”
于是,语境化的词嵌入就诞生了。
许多自然语言处理研究人员 指的是
- Semi-supervised sequence tagging with bidirectional language models
- Learned in Translation: Contextualized Word Vectors
- Deep contextualized word representations


语境化词嵌入可以根据词语在句子语境中的含义赋予词语不同的embedding。
ELMo没有对每个单词使用固定的词嵌入,而是在为每个单词计算embedding之前考虑整个句子。ELMo模型使用的是特定任务上训练的bi-LSTM进行词嵌入。

ELMo为NLP的预训练任务迈出了重要一步。ELMo在大型语料库上进行预训练,在数据集语言的大规模数据集上进行训练,然后我们可以将其一个组件放到其他模型上处理语言。
ELMo的秘密是什么?
ELMo是通过预测任务进行语言理解的,这项任务称为语言建模。这样非常方便,因为这样训练不需要有标签数据,而我们有大量的文本数据可以让模型从中学习。

假设用Let’s stick to作为输入,预测下一个最可能的单词。
当在数据集上训练时,模型开始学习语言模式。在这个例子中,它不太可能准确地猜出下一个单词(improvisation)。 举个现实一点的例子,比如hang之类的单词,它大概率输出out之类的词,反正out概率肯定比camera更高。
上图我们可以看到展开的 LSTM,每个步骤的隐藏状态从 ELMo 的后脑勺向量逐步传播,一直到最顶上传给一个FFNN。 模型训练完以后,这些向量会在计算词嵌入的过程中派上用场。
看下图,ELMo 实际上不只是LSTM,而是训练了一个bi-LSTM,这样它的语言模型不仅能看到下一个词,也能看到上一个词。
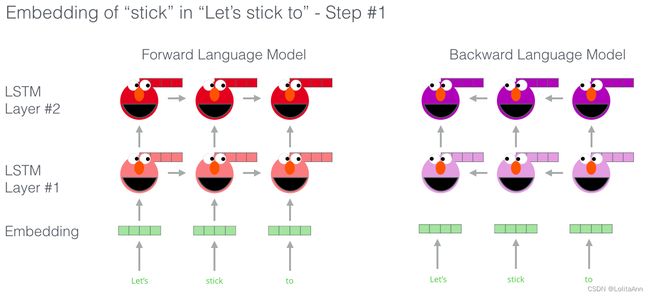
推荐一个相关PPT。
ELMo通过以某种方式将隐藏状态和初始embedding组合在一起,从而进行语境化词嵌入。

ULM-FiT:将迁移学习引入NLP
ULM-FiT引入了一些方法,可以有效地利用模型在预训练阶段学到的很多东西——不仅仅是embedding,也不仅仅是上下文信息的embedding。ULM-FiT引入了一个语言模型和一个可以有效地对该语言模型进行微调的方法,使得该模型能适应各种任务。
NLP终于有了一种像CV领域一样的迁移学习方法。
Transformer:超越LSTMs的存在
Transformer诞生之后再机器翻译等任务上取得了一些成果,让NLP领域的一些人认为它是LSTM的替代品。但是Transformer相较于LSTM,能更好地处理长期依赖关系。
Transformer的encoder-decoder结构使其非常适合机器翻译。但是如何用它来进行句子分类呢?您将如何使用它来预训练一个语言模型,以便对其他任务进行微调(下游任务是该领域所称的那些使用预训练模型或组件的监督学习任务)。
GPT:对Transformer的Decoder进行预训练的语言模型
事实证明,我们不需要整个Transformer进行迁移学习,或者为NLP任务创建预训练语言模型。我们可以只使用Transformer的decoder。Decoder是一个不错的选择,因为它天然适合语言建模,因为它采用的是masked attention,可以掩盖当前步骤之后的tokens。
GPT 由12个Transformer的decoder组成。因为模型没有encoder,因此这些decoder和Transformer原始的decoder相比是没有encoder-decoder注意力子层的,但是会保留masked self-attention子层。
使用这种结构,我们可以继续在语言建模任务上训练模型:使用大量无标签数据集预测下一个单词。 只需将 7000本书的文本扔给它,让它学习!
书籍非常适合语言建模任务,因为两个词之间被大量文本分隔,模型可以学习到如何关联一些相关信息。你使用推特或文章进行训练就不会得到这些信息。

GPT现在已经准备好接受训练了,在一个7000本书组成的数据集上进行预测任务训练。
迁移到下游任务
现在GPT已经经过了预训练,我们可以开始将它用于下游任务。
让我们先来看一下句子分类(把电子邮件分类为“spam”或“not spam”):
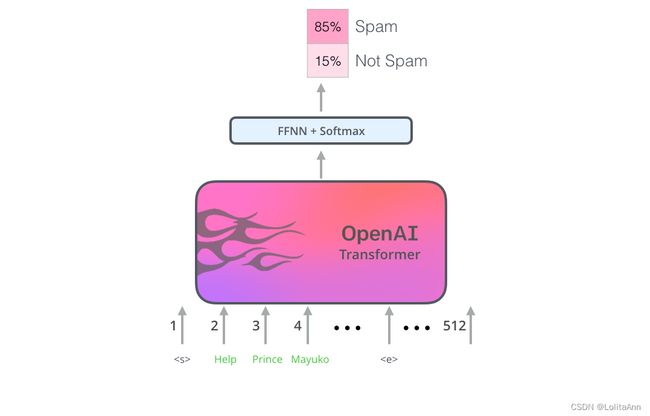
GPT怎么进行句子分类?
GPT论文中列出了一些方案:怎么转换输入以适应不同类型的任务。
下面这张图片展示了执行不同任务的模型结构和输入转换格式。

厉不厉害!
BERT:不用Decoder了,我们来用encoder
OpenAI的Transformer(GPT)为我们提供了一个基于transformer的可微调的预训练模型。但是在从LSTM到Transformer的转变过程中,有些东西消失了。
ELMo的语言模型是双向的,但是GPT只训练正向语言模型。我们能否构建一个基于Transformer的模型,它的语言模型既可以向前看,也可以向后看(用技术术语来说——“同时受左右两边上下文的约束”)?
左边是Ernie,右边是BERT。
下边这句话原文是“Hold my beer”, said R-rated BERT.
拿好我的啤酒,我要开始装逼了。引申为 看我的吧。

BERT:“看我的!”
掩码语言模型 Masked Language Model
BERT:“我们将使用Transformer的encoder!”
Ernie:“哦我的老天鹅,你疯了吧。是个人就知道双向制约在多层语境中能让文本间接看到自己的信息。”
BERT自信地说:“我们将使用mask!”

BERT的巧妙之处在于,BERT在语言建模任务中随机mask掉输入序列中15%的单词,要求模型预测缺失的单词。
找到正确的方法去训练Transformer的encoder是一个难点。BERT通过采用早期文献中的“掩码语言模型”(masked language modelnMLM)来解决这个问题。
BERT不是单纯的mask掉15%的输入,为了便于模型微调,BERT还在其中混合了其他的东西。比如有时它会随机用另一个单词替换一个单词,要求模型预测该位置的正确单词。
就是从输入中随机抽15%的词。将其中80%mask掉,10%换为其他的词,10%不做任何处理。

两个句子的任务
如果你回想一下GPT对不同任务的输入进行转换的时候,一些任务需要模型对两个句子做一些提示。(例如,给定两个输入,一个是维基百科词条作,另一个是关于该词条的问题,需要提示“我们能回答这个问题吗?”)。
为了使BERT更好地处理多个句子之间的关系,预训练过程中还有一个额外的任务。给定两个句子AB,判断B是否是A的下一句。
训练数据中50%的B是A的下一句,另外50%是随机抽取的句子。


BERT预训练的第二个任务是两个句子的分类任务。在上图中,token被简化了,BERT实际使用的是WordPieces分词作为token,而不是一个单词作为一个token。WordPieces是一些单词会被分解成更小的部分。
Task specific-Models
BERT的论文展示了在不同任务中使用BERT的多种方法。

BERT 的特征抽取
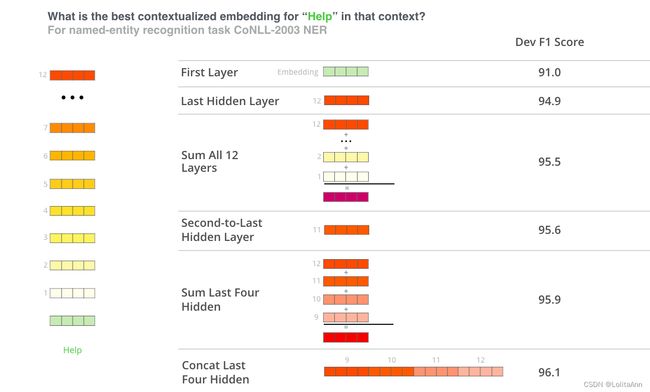
微调并不是使用BERT的唯一方法。和ELMo一样,你可以用预训练好的BERT做动态词嵌入,然后把学到的嵌入信息提供给你的模型。论文中表示,在命名实体识别等任务上,用BERT提供动态词嵌入和微调BERT的效果差不多。
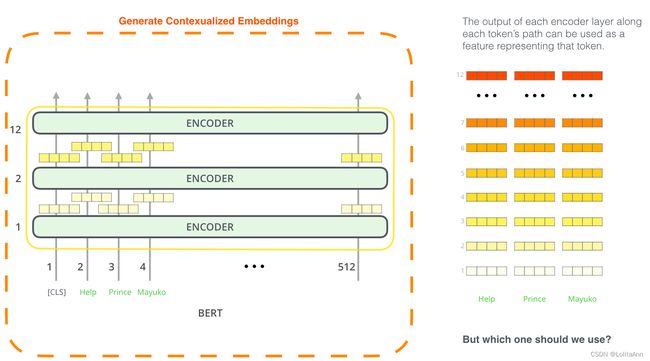
哪个向量最适合作为上下文嵌入? 我觉得这取决于任务。论文原文考虑了六种选择(与获得 96.4 分的微调模型相比):
带BERT出去炫
试用BERT的最佳方法是通过谷歌Colab上托管的云TPUs进行BERT微调。如果你以前没用过云TPU,那么这也是一个尝试的的好起点。BERT代码可以在CPU、TPU、GPU上工作。
第二步当然是看看BERT的源码:
-
模型在
modeling.py(class BertModel)中,和普通的Transformer编码器几乎相同。 -
run_classifier.py是微调过程的一个例子。它还为监督模型构建了分类层。如果你想构造自己的分类器,可以参考其中的create_model()方法。 -
有一些预先训练的模型可以直接下载使用。这些模型涵盖BERT-base、BERT-large,涵盖英语、汉语,以及wikipedia上训练的102种语言的多语言模型。
-
BERT不是把单词看做token,而是视为WordPieces。
tokenization.py是分词器,能把你的单词转化为适合BERT的WordPieces。
你也可以看一下Pytorch版本的BERT。 AllenNLP 允许任何模型使用BERT嵌入。
Jay Alammar’s Blog

作者博客:@Jay Alammar
原文链接:The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
