PyTorch学习笔记【2】:学习的机制
文章目录
- 前言
- 1. 学习是参数估计
-
- 1.1. 概念
- 1.2. 生成数据
- 1.3. 绘制散点图
- 2. 减少损失
-
- 2.1. 概念
- 2.2. 使用线性模型去拟合函数
-
- 2.2.1. 线性模型
- 2.2.2. 均方损失函数
- 2.2.3. 调用模型并检查损失
- 2.2.4. 广播机制
- 3. 沿着梯度下降
-
- 3.1. 概念
- 3.2. 减小损失
- 3.3. 分析
-
- 3.3.1. 计算导数
- 3.3.2. 将导数应用到模型中
- 3.3.3. 定义梯度函数
- 3.4. 迭代以适应模型
-
- 3.4.1. 循环训练
- 3.4.2. 过度训练
- 3.5. 归一化输入
- 3.6. 可视化结果
- 4. PyTorch自动求导:反向传播的一切
-
- 4.1. 自动计算梯度
-
- 4.1.1. 应用自动求导
- 4.1.2. 使用grad属性
- 4.1.3. 累加梯度函数
- 4.1.4. 计算图
- 4.2. 优化器
-
- 4.2.1. 优化器的种类
- 4.2.2. 使用一个梯度下降优化器
- 4.2.3. 测试其他优化器
- 4.3. 训练、验证和过拟合
-
- 4.3.1. 评估训练损失
- 4.3.2. 推广到验证集
- 4.3.3. 分割数据集
- 4.4. 自动求导更新及关闭
- 总结
前言
本文是基于《Pytorch深度学习实战》一书第五章的内容所整理的学习笔记
相关代码的解释以及对应的拓展。
本文使用的代码均基于jupyter
1. 学习是参数估计
1.1. 概念
给定输入数据和相应的期望输出(实际数据),以及权重的初始值,给模型输人数据(正向传播),并通过对输出结果与实际数据进行比较来评估读差。为了优化模型参数,即它的权重,权重单位变化后的误差变化(误差相对参数的梯度)是使用复合函数的导数的链式法则计算的(反向传播)。
训练神经网络本质上是使用几个或一些参数将一个模型变换为更加复杂的模型。即我们有一个带有一些未知参数的槙型,我们需要估计这些参数以使输出的预测值和测量值之间的误差尽可能小。
1.2. 生成数据
温度计的读数
%matplotlib inline
import numpy as np
import torch
torch.set_printoptions(edgeitems=2, linewidth=75)
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
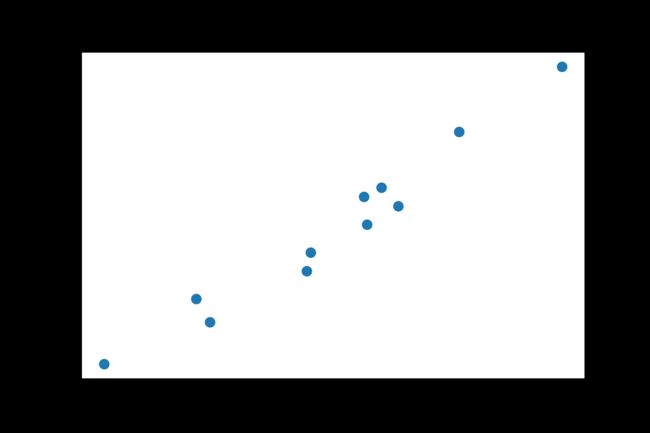
1.3. 绘制散点图
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(dpi=600)
plt.xlabel("Measurement")
plt.ylabel("Temperature (°Celsius)")
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
2. 减少损失
2.1. 概念
损失函数(或代价函数)是一个计算单个数值的函数,学习过程将试图使其值最小化。损失的计算通常涉及获取一些训练样本的期望输出与输人这些样本时模型实际产生的输出之间的差值。
从概念上讲,损失两数是一种对训练样本中要修正的错误进行优先处理的方法,因此参数更新会导致对高权重样本的输出进行调整,面不是对损失较小的其他样本的输出进行调整。
2.2. 使用线性模型去拟合函数
2.2.1. 线性模型
t_c = w * t_u + b
权重w:权重告诉我们给定的输入对输出的影响有多大
偏置b:偏置是所有输入为零时的输出
def model(t_u, w, b):
return w * t_u + b
2.2.2. 均方损失函数
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
2.2.3. 调用模型并检查损失
w = torch.ones(()) # 0维张量初始化方法
b = torch.zeros(())
t_p = model(t_u, w, b)
t_p
loss = loss_fn(t_p, t_c)
loss
2.2.4. 广播机制
广播机制指的是当满足一定条件时,较小的张量能够自动扩张成合适尺寸的大张量,使得能够进行计算
- 由后向前迭代每个索引维度,如果其一个操作数的维度大小1,那么PyTorch 将使用该维度上的单个项与另一个张量沿该维度上的每一项进行运算。
- 如果两个维度大小都大于 1,则它们的维度大小必须相同,并使用自然匹配。
- 如果一个张量的维度大于另一个张量的维度,那么另一个张量上的所有项将和这些维度上的每一项进行运算
成功示例:
x1 = torch.ones(2,3,5,7)
y1 = torch.ones(3,5,7)
s1 = x1 + y1
s1, s1.shape
x2 = torch.ones(2,1,4,1,6,1)
y2 = torch.ones(3,6,7)
s2 = x2 + y2
s2, s2.shape
错误示例:
x2 = torch.ones(2,1,4,1,6,1)
y2 = torch.ones(3,5,7)
s2 = x2 + y2
s2, s2.shape
3. 沿着梯度下降
3.1. 概念
假设我们在一台机器前面,机器上有2个旋钮,分别表示w和b。我们可以在屏幕上看到损失值,同时需要去最小化这个值。不知道旋钮对损失的影响,我们开始拨弄旋钮以确定每个旋钮朝哪个方向转动会使损失减小,然后我们决定将2个旋钮向各自可以减少损失的方向转动。假设损失离最优值还很远:我们很可能会看到损失迅速减小,然后慢慢接近最小值。我们注意到,在某一时刻,损失再次回升,所以我们将其中1个或2个旋钮向反方向旋转。我们还了解到,当损失变化缓慢时,最好更精细地调整旋钮,以免达到损失回升的点。过一段时间,损失最终收敛到最小值。
3.2. 减小损失
梯度下降的思想就是计算各参数的损失变化率,并在减小损失变化率的方向上修改各参数。
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) -
loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
也就是说,在w和b的当前值附近,w的增加会导致损失的一些变化。
- 如果变化是负的,那么我们需要增加w来最小化损失;
- 如果变化是正的,那么我们需要减小w的值
通常使用一个小的比例因子来衡量变化率,即学习率
learning_rate = 1e-2
w = w - learning_rate * loss_rate_of_change_w
loss_rate_of_change_b = \
(loss_fn(model(t_u, w, b + delta), t_c) -
loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
b = b - learning_rate * loss_rate_of_change_b
以上表示梯度下降基本参数的更新步骤。
通过重复以上评估步骤(只要我们选择一个足够小的学习率),我们将收敛到在给定数据上使损失最小的参数的最优值。
3.3. 分析
为了更精确地计算损失变化率,以更好地知道损失在哪个方向上减小得更快,我们引入梯度的概念,即计算每个参数的损失导数,并放入一个导数向量中。
3.3.1. 计算导数
运用链式法则
d ( l o s s f n ) d ( w ) = d ( l o s s f n ) d ( t p ) × d ( t p ) d w \frac{d(loss_{fn})}{d(w)} = \frac{d(loss_{fn})}{d(t_p)} \times \frac{d(t_p)}{dw} d(w)d(lossfn)=d(tp)d(lossfn)×dwd(tp)
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c) / t_p.size(0) # 均值的导数
return dsq_diffs
3.3.2. 将导数应用到模型中
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
3.3.3. 定义梯度函数
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b)
dloss_db = dloss_dtp * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.sum(), dloss_db.sum()]) # 将参数应用与模型中的整个输入向量并求和后,结果与我们隐式执行的广播相反
3.4. 迭代以适应模型
3.4.1. 循环训练
我们称训练迭代为一个迭代周期(epoch),在这个迭代周期,我们更新所有训练样本的参数。
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # 正向传播
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b) # <反向传播
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss))) # 打印日志
return params
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_u,
t_c = t_c)
通过打印日志可以发现,训练崩溃了
3.4.2. 过度训练
导致上述问题出现的原因,是因为参数接收到的更新太大了。
解决这类问题的原因通常是改变学习率的大小。
# 调整学习率
training_loop(
n_epochs = 100,
learning_rate = 1e-4,
params = torch.tensor([1.0, 0.0]),
t_u = t_u,
t_c = t_c)
因为参数接收到的更新非常小,相对的损失下降的会很慢
3.5. 归一化输入
使用归一化可以简单有效地改进模型的收敛性
在这里可以通过给t_u乘以0.1得到一个足够接近的数值
t_un = 0.1 * t_u
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
运行循环进行足够的迭代
def training_loop(n_epochs, learning_rate, params, t_u, t_c,
print_params=True):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # <1>
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b) # <2>
params = params - learning_rate * grad
if epoch in {1, 2, 3, 10, 11, 99, 100, 4000, 5000}: # <3>
print('Epoch %d, Loss %f' % (epoch, float(loss)))
if print_params:
print(' Params:', params)
print(' Grad: ', grad)
if epoch in {4, 12, 101}:
print('...')
if not torch.isfinite(loss).all():
break # <3>
return params
params = training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c,
print_params = False)
params
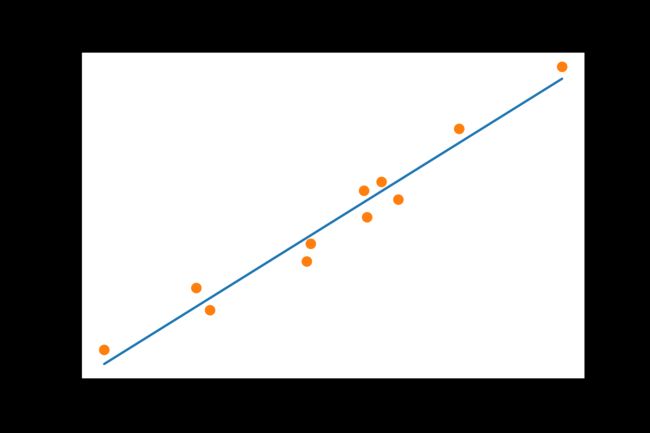
3.6. 可视化结果
%matplotlib inline
from matplotlib import pyplot as plt
t_p = model(t_un, *params) # 我们正在对归一化的位置部分进行训练,也在使用参数解包
fig = plt.figure(dpi=600)
plt.xlabel("Temperature (°Fahrenheit)")
plt.ylabel("Temperature (°Celsius)")
plt.plot(t_u.numpy(), t_p.detach().numpy()) # 画的是原始的未知数
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
4. PyTorch自动求导:反向传播的一切
%matplotlib inline
import numpy as np
import torch
torch.set_printoptions(edgeitems=2)
t_c = torch.tensor([0.5, 14.0, 15.0, 28.0, 11.0, 8.0,
3.0, -4.0, 6.0, 13.0, 21.0])
t_u = torch.tensor([35.7, 55.9, 58.2, 81.9, 56.3, 48.9,
33.9, 21.8, 48.4, 60.4, 68.4])
t_un = 0.1 * t_u
4.1. 自动计算梯度
4.1.1. 应用自动求导
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
params = torch.tensor([1.0, 0.0], requires_grad=True)
4.1.2. 使用grad属性
这个参数告诉PyTorch跟踪由对params张量进行提作后产生的张量的整个系谱树。换向话说,任何将params作为祖先的张量都可以访问以params到那个张量调用的函数链。如果这些两数是可微的(大多数PyTorch张量操作都是可微的),导数的值将自动填充为params张量的grad属性。
当你在使用 Pytorch 的 nn.Module 建立网络时,其内部的参数都自动的设置为了 requires_grad=True ,故可以直接取梯度。
我们所要做的就是以一个requires_grad为True的张量开始,调用模型并计算损失,然后反向调用损失张量:
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
params.grad
此时,params的grad属性包含关于params的每个元素的损失的导数
4.1.3. 累加梯度函数
我们可以有任意数量的requires_grad为True的张量和任意组合的函数。在这种情况下,PyTorch将计算整个函数链(计算图)中损失的导数,并将它们的值累加到这些张量的grad属性中(图的叶节点)。
导数是累加存储到grad属性中的,即调用backward()將导致导数在叶节点上累加。使用梯度进行参数更新后,我们需要显式地将梯度归零。
为了防止这种情况发生,我们需要在每次迭代时使用zero()_方法明确地将梯度归零。
if params.grad is not None:
params.grad.zero_()
完整的自动求导训练代码
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None: # 这可以在循环中调用loss.backward()之前的任何时间完成
params.grad.zero_()
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
with torch.no_grad():
params -= learning_rate * params.grad
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
with torch.no_grad:
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0], requires_grad=True), # 关键
t_u = t_un,
t_c = t_c)
4.1.4. 计算图
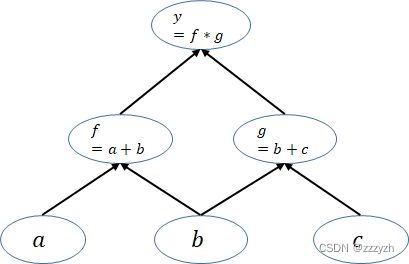
- pytorch是动态图机制,在训练模型时候,每迭代一次都会构建一个新的计算图。而计算图其实就是代表程序中变量之间的关系。y=(a+b)(b+c)这个例子可以构建如下计算图:
- 上面的计算图中每一个叶子节点都是一个用户自己创建的变量,在网络backward时候,需要用链式求导法则求出网络最后输出的梯度,然后再对网络进行优化,如下就是网络的求导过程。
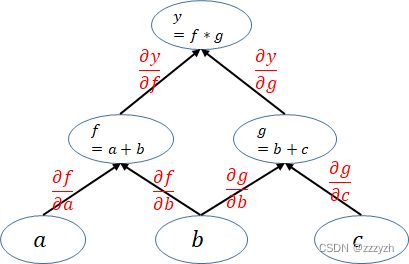
- pytorch在利用计算图求导的过程中根节点都是一个标量,即一个数。当根节点即函数的因变量为一个向量的时候,会构建多个计算图对该向量中的每一个元素分别进行求导
4.2. 优化器
4.2.1. 优化器的种类
每个优化器构造函数都接收一个参数列表(即张量,通常将requires_grad设置为True)作为第一个输入。
传递给优化器的所有参数都保留在优化器对象中,这样优化器就可以更新他们的值并访问它们的grad属性。
import torch.optim as optim
dir(optim)
4.2.2. 使用一个梯度下降优化器
这里SGD代表随机梯度下降。只要动量因子momentum参数没置w为0.0,该参数默认值也是0.0,那么优化器本身也是一种批量梯度下降算法。
“随机”一词来自这样—个事实,即梯度通常是通过对所有输入样本的一个随机子集(称为小批量)取平均值而得到的。
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-5
optimizer = optim.SGD([params], lr=learning_rate)
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
optimizer.step()
params
params的值在调用step()时更新
在将这段代码放入一个训练循环之前,我们需要把梯度归零
如果我们在一个循环中调用前面的代码,梯度就会在每次调用backward()时在叶节点中累加,那么我们的梯度下降就会遍布整个循环区域
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
t_p = model(t_un, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad() # <1>
loss.backward()
optimizer.step()
params
更新训练循环
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
training_loop(
n_epochs = 5000,
optimizer = optimizer,
params = params, # 两个params是同一个对象这一点很重要,否则优化器不知道模型使用了什么参数
t_u = t_un,
t_c = t_c)
4.2.3. 测试其他优化器
Adam优化器的学习率是自适应设置的。此外,它对参数的缩放不太敏感,所以我们可以使用原始(未归一化)的输入。
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-1
optimizer = optim.Adam([params], lr=learning_rate)
training_loop(
n_epochs = 2000,
optimizer = optimizer,
params = params,
t_u = t_u,
t_c = t_c)
4.3. 训练、验证和过拟合
过拟合:所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。
4.3.1. 评估训练损失
训练损失会告诉我们,我们的模型是否已经能够完全拟合训练集。
规则1:如果训练损失没有减少,一种可能是因为模型对数据来说太简单了;另一种可能是我们的数据没有有意义的信息以让模型对输出做出解释
4.3.2. 推广到验证集
如果在验证集中评估的损失没有随着训练集的增加而减少,这意味着我们的模型正在改进它在训练过程中看到的样本的拟合度,但是它不能推广到这个精确数据集之外的样本。一旦我们在新的、先前未见的点上评估模型先前未见的点上评估模型,损失西数的值就会很差。
规则2:如果训练损失和验证损失发散,则表明出现了过拟合现象。
解决过拟合的办法:
首先,我们应该确保我们有足够的数据用于这个过程。
其次,如果我们有足够的数据点,我们应该确保能够拟合训练数据的模型在数据点之间尽可能有规律。一种方法是在损失两数中添加惩罚项,以降低模型的成本,使其表现更平稳、变化更缓慢(直到某一点);另一种方法是在输入样本中添加噪声,人为地在训练数据样本之间创建新的数据点,并迫使模型也试图拟合这些数据点。
最后,一方面,我们需要模型有足够的能力来拟合训练集;另一方面,我们需要避免模型过拟合。因此,为神经网络模型选择合适的参数的过程分为2步:增大参数直到拟合,然后缩小参数直到停止过拟合。
4.3.3. 分割数据集
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_indices, val_indices
- randperm():
随机打乱传入的参数,并返回一个序列torch.randperm(10)
通过索引张量从数据张量开始构建训练集和验证集合
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u
val_t_un = 0.1 * val_t_u
def training_loop(n_epochs, optimizer, params, train_t_u, val_t_u, train_t_c, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params) # <1>
train_loss = loss_fn(train_t_p, train_t_c)
val_t_p = model(val_t_u, *params) # <1>
val_loss = loss_fn(val_t_p, val_t_c)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch <= 3 or epoch % 500 == 0:
print(f"Epoch {epoch}, Training loss {train_loss.item():.4f},"
f" Validation loss {val_loss.item():.4f}")
return params
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
training_loop(
n_epochs = 3000,
optimizer = optimizer,
params = params,
train_t_u = train_t_un,
val_t_u = val_t_un,
train_t_c = train_t_c,
val_t_c = val_t_c)
4.4. 自动求导更新及关闭
训练循环中的第1行对train_t_u上的模型进行评估,以生成train_t_p,然后从train_t_p评估train_loss。这将创建一个计算图,将train_t_u、 train_t_p和train_1oss 连接起来。当模型再次在val_t_u上求值时,将生成val_t_p和val_loss。在本例中,将创建一个单独的计算图,将val_t_u、val_t_p和val_loss连接起来。将单独的张量经过相同的函数,即model和1oss_fn()运算,得到单独的计算图,
如果我们对val_loss误调用backward(),则会累加val_1oss相对同一叶节点上的参数的导数。在val_1oss上调用backward(),在train_loss.backward()调用生成的结果之上,将导致梯度在 params 张量中累加。
无论如何优化,构建自动求导因都会带来额外的开销,在验证过程中我们完全可以放弃这些开销,特别是当模型有数百万个参数时。为了解決这个问题,PyTorch允许我们在不需要的时候关闭自动求导,使用上下文管理器 torch.no_grad()。在这个小问题上,我们并不会看到构建自动求导图在速度或内存开销方面有任何有意义的优势。不过,对于更大的模型,这些差异会累加起来。我们可以通过检查 val_1oss 张量上的 requires_grad 属性的值来确保这是有效的
def training_loop(n_epochs, optimizer, params, train_t_u, val_t_u,
train_t_c, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
with torch.no_grad(): # 上下文管理器
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
assert val_loss.requires_grad == False # 检查在此块中输出的requires_grad属性的值是否被强制设为False
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
def calc_forward(t_u, t_c, is_train):
with torch.set_grad_enabled(is_train):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
return loss
总结
本文主要讲解了:
- 理解算法如何从数据中学习
- 使用微分和梯度下降算法,将学习重构为参数估计
- 了解一个简单学习算法
- 了解PyTorch如何支持自动求导