使用自己的数据训练Yolov4-tiny模型,并用tensorrt运行(配置github host、编译安装opencv4.1.1+contrib和darknet、制作数据集、训练全流程)
目录
-
-
-
- 0. 修改host文件 (选做)
- 1. 编译安装opencv 4.1.1+contrib
- 2. 准备训练环境
- 3. 制作自己的数据集
- 4. 预训练权重和配置文件
- 5. 创建训练配置文件
- 6. 训练
- 7. 测试
- 8. tensorrt运行
-
- 8.1. 修改配置文件及复制权重文件
- 8.2. 修改sample_detector.cpp
- 8.3. 编译及运行
-
-
0. 修改host文件 (选做)
这一步主要为了方便从github上下载东西。如果是私人电脑或者服务器,这样修改host是可以的,对于单位服务器,则不推荐修改host文件。
进入https://www.ipaddress.com/,分别查询以下三个github相关网址
-
输入 github.com

ip地址为140.82.114.3 -
输入 github.global.ssl.fastly.net

ip地址为199.232.69.194 -
查询 raw.githubusercontent.com
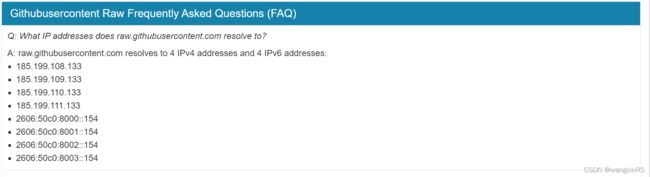
ip地址有四个,分别为
185.199.108.133
185.199.109.133
185.199.110.133
185.199.111.133 -
修改host文件
sudo vim /etc/hosts
在最后面对应输入上述ip地址,如下

- 重启以使host生效
sudo reboot now
1. 编译安装opencv 4.1.1+contrib
安装Opencv过程中,需要下载ippicv_2019_lnx_intel64_general_20180723.tgz,boostdesc_bgm.i等文件,可以直接在百度网盘中找到。
参考博客《Ubuntu18 opencv4.1.1加opencv_contrib-4.1.1(解决没有face.h的问题)编译安装(一条龙过)》
- 下载源码
链接:https://pan.baidu.com/s/1sWbgSO-MK4c7pEKHXNRqCA
提取码:f7en
百度网盘链接,下载所有内容,放置于~/Downloads目录下
注意:ippicv_2019_lnx_intel64_general_20180723.tgz不要解压! - 调整opencv源码文件,方便编译
cd ~/Downloads
unzip opencv-4.1.1.zip && unzip opencv_contrib-4.1.1.zip && unzip installFile.zip
cp -r ./installFile/* ./opencv_contrib-4.1.1/modules/xfeatures2d/src/
mv -f opencv_contrib-4.1.1 ./opencv-4.1.1
mv -f opencv-4.1.1 ../
cd ../opencv-4.1.1
mkdri build
cp -r modules/features2d/ ./build/
- 修改ippicv.cmake
sudo vim ~/opencv-4.1.1/3rdparty/ippicv/ippicv.cmake
将第47行的
"https://raw.githubusercontent.com/opencv/opencv_3rdparty/${IPPICV_COMMIT}ippicv/"修改为"file:/home/wangxinRS/Downloads/"(此处为绝对路径),然后保存退出。
- 添加一个源,方便apt安装第三方库
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
- 安装第三方库
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install build-essential libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
- 编译安装
cd ~/opencv-4.1.1/build
cmake -D CMAKE_BUILD_TYPE=Release -D OPENCV_GENERATE_PKGCONFIG=ON -D CMAKE_INSTALL_PREFIX=/usr/local -D OPENCV_EXTRA_MODULES_PATH=../opencv_contrib-4.1.1/modules ..
sudo make -j8
sudo make install
- c++环境配置
sudo touch /etc/ld.so.conf.d/opencv4.conf
sudo sh -c 'echo "/usr/local/lib" > opencv4.conf'
sudo ldconfig
- 查看opencv4安装的库和头文件
pkg-config --libs opencv4
pkg-config --cflags opencv4
- 验证
cd ~/opencv-4.1.1/samples/cpp
g++ `pkg-config --cflags opencv4` drawing.cpp `pkg-config --libs opencv4` -o drawing.out
./drawing.out
- 后期如果有卸载Opencv重装的需求,可以考虑如下操作
sudo rm /etc/ld.so.conf.d/opencv4.conf
cd ~/opencv-4.1.1/build
sudo make uninstall
2. 准备训练环境
参考AlexeyAB的官方文档,安装训练环境。
注意:我在ubuntu 18.04上训练,使用一张t4卡。
- 创建python训练环境 (个人自愿)
conda create -n TrainYolov4-tiny python=3.8 -y
conda activate TrainYolov4-tiny
- 创建训练目录
cd ~/ && mkdir TrainYolov4-tiny && cd TrainYolov4-tiny
- 下载AlexeyAB官方源码 (用代理,这样下载较快)
git clone https://ghproxy.com/https://github.com/AlexeyAB/darknet
- 编译及安装
cd darknet
mkdir build_release
cd build_release
cmake ..
cmake --build . --target install --parallel 8
3. 制作自己的数据集
主要参考博客《yolov4-tiny训练自己的数据集》,我们应将自己的数据集最终整理成VOC2007格式。
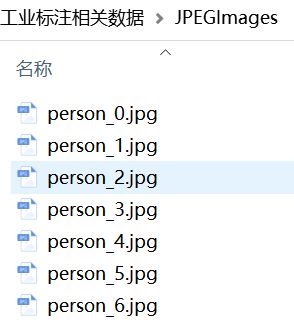
- 作为最开始的部分,默认你拥有自己的图片,以及标注信息,即以下两个文件夹

这里,JPEGImages文件夹下包含所有的图片数据,Annotations文件夹下包含各个图片对应的.xml标注文件,如下

.xml标注文件里包含标注信息,包括图片名称、图片高宽、标注类别、标注框左上角和右下角坐标等,如图

- 在
darknet源码目录下创建mydata目录,并将上述两个文件夹复制到该目录下
cd ~/TrainYolov4-tiny/darknet
mkdir mydata
cd mydata
此时,结构如下
![]()
- 用如下代码
voc1.py将所有图片分为训练集、测试集和验证集,分的结果保存在ImageSets目录中
mkdir -p ImageSets/Main
python voc1.py
# voc1.py代码,应在mydata目录中
import os
import random
trainval_percent = 1 #可以自己修改
train_percent = 0.9 #可以自己修改
xmlfilepath = './Annotations'
txtsavepath = './ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('./ImageSets/Main/trainval.txt', 'w')
ftest = open('./ImageSets/Main/test.txt', 'w')
ftrain = open('./ImageSets/Main/train.txt', 'w')
fval = open('./ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
此时,目录结构应为

其中,ImageSets/Main目录下包含trainval.txt、train.txt、test.txt和val.txt。
- 用如下代码
voc2.py将xml转化为txt格式,将结果保存在labels目录下
mkdir labels
python voc2.py
# voc2.py的代码,应在mydata目录中
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["person"] #改为自己数据集的label
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('./Annotations/%s.xml'%( image_id))
out_file = open('./labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
image_ids = open('./ImageSets/Main/%s.txt'%( image_set)).read().strip().split()
list_file = open('%s.txt'%(image_set), 'w')
for image_id in image_ids:
list_file.write('%s/JPEGImages/%s.jpg\n'%(wd, image_id))
convert_annotation(image_id)
list_file.close()
此时,mydata的目录结构应如下
![]()
4. 预训练权重和配置文件
主要参考博客《yolov4-tiny训练自己的数据集》
-
预训练权重
yolov4-tiny.conv.29可以直接下载,也可以从百度网盘中获取
链接:https://pan.baidu.com/s/1sWbgSO-MK4c7pEKHXNRqCA
提取码:f7en -
标准配置文件
yolov4-tiny.cfg位于源码darknet/cfg/目录中,该配置文件中的一些参数意义如下
[net]
batch=96 # 每次iteration训练的时候,输入的图片数量
subdivisions=48 # 将每一次的batch数量,分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration
width=512 # 大小为32的倍数
momentum=0.9 # 动量,影响梯度下降到最优的速度,一般默认0.9
decay=0.0005 # 权重衰减正则系数,防止过拟合
angle=0 # 旋转角度,生成更多训练样本
saturation=1.5 # 调整饱和度
exposure=1.5 # 调整曝光度
hue=.1 # 调整色调
learning_rate=0.001
burn_in=1000 # 学习率控制的参数,在迭代次数大于burn_in时,采用policy的更新方式:0.001 * pow(iterations/1000, 4)
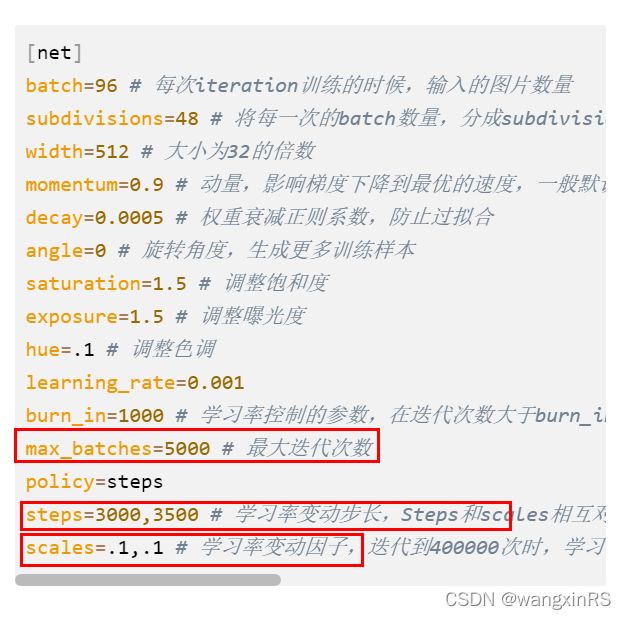
max_batches=5000 # 最大迭代次数
policy=steps
steps=3000,3500 # 学习率变动步长,Steps和scales相互对应, 这两个参数设置学习率的变化, 根据batch_num调整学习率
scales=.1,.1 # 学习率变动因子,迭代到400000次时,学习率x0.1; 450000次迭代时,学习率又会在前一个学习率的基础上x0.1
这里可能需要注意的是batch和subdivisions,如果训练时发现显存不足,则将其减小即可。
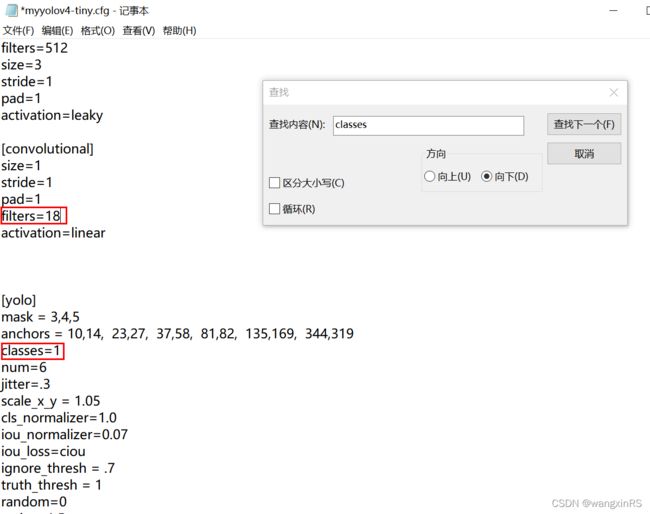
- 将
yolov4-tiny.cfg复制一份为myyolov4-tiny.cfg,修改所有yolo层的classes(两处),以及yolo层前一个卷积层的filters(计算方式为filters=(classes + 5)x3)
这里,我的类别为1,就是person,所以classes=1,filter=(1+5)x3=18。
5. 创建训练配置文件
-
在
darknet源码中,创建mytrain目录,在其中分别创建mytrain.data文件、mytrain.names文件、runs目录 -
将
mydata目录中的train.txt和val.txt复制到mytrain目录中
cd ~/TrainYolov4-tiny/darknet
mkdir mytrain
cd mytrain
cp ../mydata/train.txt ./
cp ../mydata/val.txt ./
touch mytrain.data
touch mytrain.names
mkdir runs
其中,mytrain.names文件中的内容是填写训练类别的
person # 我这里就是一个类别 person
mytrain.data文件中的内容为
classes=1
train=mytrain/train.txt
valid=mytrain/val.txt
names=mytrain/mytrain.names
backup=mytrain/runs
backup是放置训练结果的文件夹的地址,训练完成后的训练结果在runs目录下
6. 训练
cd ~/TrainYolov4-tiny/darknet
# 这里,我指定在gpu 1上训练,如果显存不够,考虑回到 4. 预训练权重和配置文件 部分修改配置文件
./darknet detector train mytrain/mytrain.data cfg/myyolov4-tiny.cfg yolov4-tiny.conv.29 -gpus 1
训练结果保存在mytrain/runs/目录下。
我将训练轮数设为5000,在第3000轮的时候学习率乘以0.1,在第3500轮的时候学习率乘再以0.1,这样最后的损失为0.03左右。
以上三个参数在 4. 预训练权重和配置文件 中可以见到,如图
此时训练的模型保存在mytrain/runs目录下,如图所示,

7. 测试
仅测试单张照片推理,使用如下命令
./darknet detector test mytrain/mytrain.data cfg/mytrain.cfg mytrain/runs/myyolov4-tiny_last.weights mytest/0.jpg
基本格式为
./darknet detector test [.data文件路径] [.cfg文件路径] [.weights文件路径] [待测试文件路径]
如果需要批量测试图片,参考博客《YOLOV4-darknet批量测试并保存图片》
8. tensorrt运行
选择的是enazoe/yolo-tensorrt的开源项目。注意,根据自己的tensorrt版本,选择对应的项目,如下,
tensorrt 7:https://hub.xn–p8jhe.tw/enazoe/yolo-tensorrt/tree/mastertensorrt 8:https://hub.おうか.tw/enazoe/yolo-tensorrt
如果网络不好,可以直接在链接下载(内含yolov3-tiny.weights, yolov4-tiny.weights)
链接:https://pan.baidu.com/s/1z6WtW69zaT8e1WmLWboBlw
提取码:66tt
下载解压项目后(这里我解压到~/目录下,项目路径为~/yolo-tensorrt),依次进行如下操作。
8.1. 修改配置文件及复制权重文件
由于我们自己训练的是1个类别的yolov4-tiny模型,因此需要修改该项目下的yolov4-tiny.cfg配置文件。具体的
vim ~/yolo-tensorrt/configs/yolov4-tiny.cfg
一样的,参考 4. 预训练权重和配置文件 方法,修改所有yolo层的classes(两处),以及yolo层前一个卷积层的filters(计算方式为filters=(classes + 5)x3,我是1个类别,所以为(1+5)x3=18)。
将训练好的yolov4-tiny权重文件myyolov4-tiny_last.weights复制到~/yolo-tensorrt/configs目录下
8.2. 修改sample_detector.cpp
示例代码为samples/sample_detector.cpp,对其进行编辑
vim ~/yolo-tensorrt/samples/sample_detector.cpp
修改如下内容
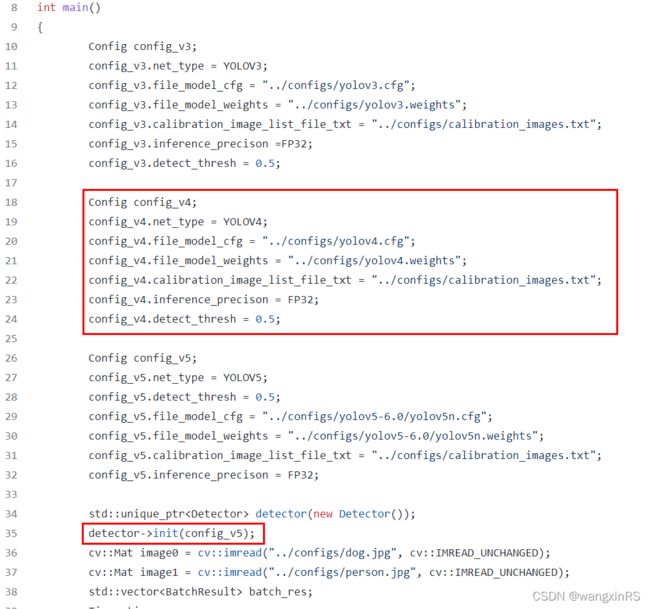
第一处红框改成
Config config_v4_tiny;
config_v4_tiny.net_type = YOLOV4_TINY;
config_v4_tiny.detect_thresh = conf_thres;
config_v4_tiny.file_model_cfg = "../configs/yolov4-tiny.cfg";
config_v4_tiny.file_model_weights = "../configs/myyolov4-tiny_last.weights";
config_v4_tiny.calibration_image_list_file_txt = "../configs/calibration_images.txt";
config_v4_tiny.inference_precison = FP16;
config_v4_tiny.detect_thresh = 0.5;
第二处红框改成
detector->init(config_v4_tiny);
8.3. 编译及运行
cd ~/yolo-tensorrt/
mkdir build
cd build/
cmake ..
make
运行命令
cd ~/yolo-tensorrt/build
./yolo-trt