Spark RDD 论文详解(七)讨论
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
目录
Spark RDD 论文详解(一)摘要和介绍
Spark RDD 论文详解(二)RDDs
Spark RDD 论文详解(三)Spark 编程接口
Spark RDD 论文详解(四)表达 RDDs
Spark RDD 论文详解(五)实现
Spark RDD 论文详解(六)评估
Spark RDD 论文详解(七)讨论
Spark RDD 论文详解(八)相关工作和结尾
思维导图
正文
7、讨论
虽然由于 RDDs 的天然不可变性以及粗粒度的转换导致它们似乎提供了有限制的编程接口,但是我们发现它们适合很多类型的应用。
特别的,RDDs 可以表达出现在各种各样的框架提出的编程模型,而且还可以将这些模型组合在同一个程序中(比如跑一个 MapReduce 任务来创建一个图,然后基于这个图来运行 Pregel)以及可以在这些模型中共享数据。
在这一章中,我们在第 7.1 节中讨论 RDDs 可以表达哪些模型以及为什么适合表达这些编程模型。
另外,我们在第 7.2 节中讨论我们推崇的 RDD 的血缘信息的好处,利用这些信息可以帮助我们 debug 模型。
7.1 已经存在的编程模型的表达
对于到目前为止很多独立提出的编程模型,RDDs 都可以高效的表达出来。
这里所说的 “高效”,不仅仅是指使用 RDDs 的输出结果和独立提出的编程模型狂简的输出结果是一致的,而且 RDDs 在优化性能方面比这些框架还要强大,比如将特定的数据保存在内存中、对数据分区以减少网络传输以及高效的从错误中恢复。
可以用 RDDs 表达的模型如下:
- MapReduce:可以利用 spark 中的 flatMap 和 groupByKey 操作来表达这个模型,或者如果需要聚合的话可以使用 reduceByKey。
- DryadLINQ:DryadLINQ 系统比 MapReduce 更多的操作,但是这些操作都是直接和 RDD 的转换操作(map,groupByKey,join 等)对应的批量操作。
- SQL:和 DryadLINQ 一样,SQL 查询都是对一个数据集进行并行的操作计算。
- Pregel:Google 的 Pregel 是一个专门解决迭代图计算应用的模型,它一开始看起来和面向数据集的编程模型的其他系统完全不同。在 Pregel 中,一个程序运行一些列的相互协调的
supersteps。在每一个superstep上,对图上的每一个顶点运行用户自定义的函数来更新这个顶点的相关的状态、改变图的拓扑结构以及向其他顶点发送下一个 superstep 需要的消息。这种模型可以表达非常多的图计算算法,包括最短路径、二部图匹配以及 PageRank。
Pregel 在每一次迭代中都是对所有顶点应用相同的用户定义的函数,这个是使的我们用 RDDs 来实现这个模型的关键点。
因此,每次迭代后,我们都可以将顶点的状态保存在 RDD 中,然后执行一个批量转换操作(apply)来应用这个函数以及生成一个消息的 RDD。
然后我们可以用这个 RDD 通顶点的状态进行 join 来完成消息的交换。
和 Pregel 一样,RDDs 允许将点的状态保存在内存中、控制它们的分区以减少网络通讯以及指出从失败中恢复。
我们在 spark 上用了 200 行代码的包实现了 Pregel,可以查看下面的资料了解详情。
M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. Franklin, S. Shenker, and I. Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. Technical Report UCB/EECS-2011-82, EECS Department, UC Berkeley, 2011.
- 迭代 MapReduce:最近提出的几个系统,包括 HaLoop 和 Twister,它们提供了可以让用户循环跑一系列的 MapReduce 任务的迭代式 MapReduce 模型。这些系统在迭代之间保持数据分区一致,Twister 也可以将数据保存在内存中。RDDs 可以很简单的表达以上两个优化,而且我们基于 spark 花了 200 行代码实现了 HaLoop。
- 批量流处理: 研究人员最近提出了一些增量处理系统,这些系统是为定期接受新数据然后根据数据更新结果的应用服务的。比如,一个应用需要实时接收新数据,然后每 15 分钟就将接收到的数据和前面 15 分钟的时间窗口的数据进行 join 聚合,将聚合的结果更新到统计数据中。这些系统执行和 Dryad 类似的批处理,但是它们将应用的状态数据存储在分布式系统中。将中间结果放在 RDDs 中可以提高处理速度。
- 阐释 RDDs 的表达力为什么这么丰富:为什么 RDDs 可以表达多种多样编程模型?原因就是 RDDs 的限制性对很多并行计算的应用的影响是很小的。特别指出的是,虽然 RDDs 只能通过批量转换而得到,但是很多的并行计算的程序都是将相同的操作应用到大量的数据条目中,这样使的 RDDs 的表达力变的丰富。类似的,RDDs 的不变性并不是障碍,因为我们可以创建多个 RDDs 来表达不同版本的相同数据集。事实上,现在很多的 MapReduce 的应用都是运行在不能对文件修改数据的文件系统中,比如 HDFS。
- 最后一个问题是为什么之前的框架没有提供这中通用型的表达能力呢? 我们相信这个是因为这些框架解决的是 MapReduce 和 Dryad 不能解决的特殊性的问题,比如
迭代,它们没有洞察到这些问题的共同原因是因为缺少了数据共享的抽象。
解析
MapReduce
关于 MapReduce 请关注我的大数据技术专栏 MapReduce
Dryad
Dryad是一种基础设施,允许程序员使用计算机集群或数据中心的资源来运行数据并行程序。
Dryad程序员可以使用数千台机器,每台机器都有多个处理器或内核,而对并发编程一无所知。
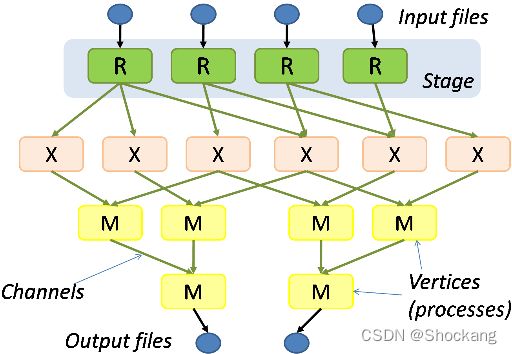
Dryad工作的结构
Dryad程序员编写几个顺序程序,并使用单向通道连接它们。
计算结构为有向图:程序是图顶点,而通道是图边。
Dryad作业是一种图形生成器,可以合成任何有向无环图。
这些图表甚至可以在执行过程中根据计算中的重要事件进行更改。
Dryad很有表现力。
它完全包含其他计算框架,如谷歌的地图还原或关系代数。
此外,Dryad还处理职位创建和管理、资源管理、职位监控和可视化、容错、重新执行、调度和审计。
DryadLINQ
要理解DryadLINQ,我们先要知道LINQ是什么。
LINQ是Language Integrated Query, 一个C#的语言特性,在C#3.5的时候被引入。
基本思想是给C#增加了query的能力,使用类似functional programming的编程方式。
LINQ支持很多标准的查询方式,包括SELECT, WHERE,JOIN, AGGREGATE等等。
LINQ在C#里面的实现是一个非常优美的编程模式,现在C#已经开源,所以这方面的code对微软以外的人也可以看到了。
LINQ实现了provider的概念,只要实现一个provider以后那么LINQ就可以跑在不同的东西上,包括SQL, XML, Arrary等等。
DryadLINQ实际上是一个LINQ的provider的实现。
通过对C#实现对LINQ的支持,DryadLINQ可以让背后的数据跑在一个Dryad的环境下。
值得说明的是,DryadLINQ实际上通过对IL(.net虚拟机的语言)层面的分析,可以做很多传统数据库上才做的优化,从而可以生成更加有效率的执行方案。
其背后的运行环境是一个Dryad平台。
Pregel
Pregel 是众多 BSP 计算框架中最有名的实现,Pregel 是首次提出将 BSP 模型应用于图计算。
关于 BSP 请参考我的博客——并行计算模型有哪些?
HaLoop
简而言之,HaLoop = Ha,Loop
HaLoop 是 Hadoop MapReduce 框架的修改版本,旨在为这些应用程序服务。
HaLoop 不仅通过对迭代应用程序的编程支持来扩展 MapReduce,还通过提高任务调度器循环感知和添加各种缓存机制来大幅提高其效率。
经过对 HaLoop 对真实查询和真实数据集进行了评估,发现与 Hadoop 相比,HaLoop平均减少了 1.85 的查询运行时间,与 Hadoop 相比,Mapper 和 Reducer 之间仅 Shuffle了4%的数据。
简而言之,HaLoop具有以下功能:
- 为循环不变数据访问提供缓存选项
- 允许用户重用应用程序 Hadoop 实现中的主要构建块
- 具有与 Hadoop 类似的工作内部容错机制。此外,HaLoop 与 Hadoop 作业向后兼容。
7.2 利用 RDDs 来 debug
原文翻译
当我们一开始设计 RDDs 通过重新计算来达到容错的时候,这种特性同时也促使了 debugging 的产生。
特别的,在一个任务中通过记录 RDDs 的创建的血缘,我们可以:
- 后面可以重新构建这些 RDDs 以及可以让用户交互性的查询它们。
- 通过重新计算其依赖的 RDD 分区来达到在一个进程 debugger 中重跑任何的任务。
和传统的通用分布式系统的重跑 debugger 不一样,传统的需要捕获和引用多个节点之间的事件发生的顺序,RDDs 这种 debugger 方式不需要依赖任何的数据,而只是需要记录 RDD 的血缘关系图。
我们目前正在基于这些想法来开发一个 spark debugger。