spark数据处理-RDD
文章目录
- spark数据处理笔记
-
- spark核心介绍
- RDD编程
-
- RDD介绍-弹性分布式数据集
- 创建RDD两种方式
- 函数传递
- 常见RDD转化操作和行动操作
-
- 常用的转化操作:
- 类集合操作
- 行动操作
- 不同RDD类型间转化
- 持久化(缓存)
- 键值对RDD操作
-
- 创建Pair RDD
- 转化操作
-
- 单RDD操作
- 两个pair RDD转化操作
- 聚合操作
- 分组操作
- 连接操作
- 排序
- 分区
- 共享变量
- 数据读写
-
- 本地文件数据读写
-
- 本地文件读取
- 文件写入本地
- HDFS文件读写
-
- 文件读取
- 把文件写入到HDFS
- JSON文件读写
- 操作示例
-
- 连续n活跃问题
学习来源:spark快速大数据分析
[美] Holden Karau [美] Andy Konwinski
[美] Patrick Wendell [加] Matei Zaharia 著
王道远 译
spark数据处理笔记
spark核心介绍
每个spark应用都是由一个驱动器程序(driver program)发起集群上的各种并行操作;驱动器程序包含应用的main函数,定义了集群上的分布式数据集及相关应用操作;驱动器通过一个SparkContext对象访问spark.shell启动时会自动创建一个SparkContext对象——一个命名为sr变量;
RDD编程
RDD介绍-弹性分布式数据集
- 弹性分布式数据集(Resilient Distributed Dataset,简 称 RDD)。RDD 是一个不可变的分布式对象集合。在 Spark 中,对数据的所有操作不外乎创 建 RDD、转化已有 RDD 以及调用 RDD 操作进行求值。Spark 会自动将 RDD 中的数据分发到集群上,并将操作并行化执行。
- RDD支持两种类型的操作:转化操作(transformation)和行动操作(action);转化操作会由一个RDD生成一个新的RDD,惰性lazy计算,在被调用行动操作之前不会开始计算(比如filter,map);行动操作对RDD计算出一个结果,把结果返回到驱动器程序中或储存到外部储存系统(如HDFS)中:返回其他数据类型,会触发实际计算;缓存是在第一次调用行动操作时触发缓存动作;
- 默认情况下,spark的RDD会在每次行动操作时重新计算,如果需要复用同一个RDD,可以使用**RDD.persist()**把RDD缓存,不然,每调用一个新的行动操作时,整个RDD都会从头开始计算;
- RDD可以通过**collection()**函数获取整个RDD中的数据,如果RDD很小,单台机器内存足以支撑,才能使用collection()方法;
创建RDD两种方式
- 读取一个外部数据集
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
// local:本地模式运行
val conf = new SparkConf().setMaster('local').setAppName("appname")
val sc = new SparkContext(conf)
lines = sc.textFile("README.md")
- 在驱动器程序里分发驱动器程序中的对象集合
- 将程序中已有的集合传给SparkContext的parallelize()
val lines = SC.parallelize(List(1,2,3,4))
函数传递
-
传递一个对象的方法或者字段时,把包含整个对象的引用,可以把需要的字段放到一个局部变量中,避免传递包含该字段的整个对象,这里在python中也是一样的;
-
所传递的函数或数据需要是可序列化的(实现了 Java 的 Serializable 接口);如果在 Scala 中出现了 NotSerializableException,通常问题是传递了一个不可序列 化的类中的函数或字段。传递局部可序列化变量或顶级对象中的函数始终是安全的。
class SearchFunctions(val query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = {
// 问题:"isMatch"表示"this.isMatch",因此我们要传递整个"this"
rdd.map(isMatch)
}
def getMatchesFieldReference(rdd: RDD[String]): RDD[String] = {
// 问题: "query"表示"this.query",因此我们要传递整个"this"
rdd.map(x => x.split(query))
}
def getMatchesNoReference(rdd: RDD[String]): RDD[String] = {
// 安全:只把我们需要的字段拿出来放入局部变量中
val query_ = this.query
rdd.map(x => x.split(query_))
}
}
常见RDD转化操作和行动操作
常用的转化操作:
- map():映射
val lines = SC.parallelize(List(1,2,3,4))
val lines1 = lines.map(e => e * e) // 所有元素取平方
- filter():过滤
val lines = SC.parallelize(List(1,2,3,4))
val lines1 = lines.filter(e => e > 2) // 筛选大于2
- flatMap()
val lines = SC.parallelize(List("hello world","scala"))
val lines1 = lines.flatMap(e => e.split(" "))
println(lines1.first()) // hello
类集合操作
RDD不是严格意义上的集合,但支持许多数据学集合操作,比如:
-
RDD.distinct()
去重:操作开销比较大,需要将所有数据通过网络进行混洗(shufflle),以确保每个元素的唯一性;
-
RDD.union(RDD1)
合并:会把两个RDD合并成一个RDD,新的RDD不会去重,sql中的union all操作会去重;
-
RDD.intersection(RDD1)
交集:类似于sql中的inner join操作,返回两个RDD共有的元素。**intersection()**在运行时会去掉所有重复操作,该操作也需要通过网络混洗拿数据来发现共有的元素;
-
RDD.subtract(RDD1)
差集:返回只存在于RDD不存在于RDD1中的元素,与intersection()一样,也需要进行数据混洗;
-
RDD.cartesian(RDD1)
笛卡尔积:返回RDD元素和RDD1元素组合(a,b)的所有组合对;
-
RDD.sample(withReplacement,fraction,[seed])
对RDD采样,以及是否替换
rdd.sample(false,0.5) // 抽样50%
行动操作
-
reduce(func)
接受一个函数作为参数,函数要求两个RDD的元素类型一致,并返回同样类型元素;
val sum = rdd.reduce((x,y) = > x + y) // 求和操作
-
fold()和reduce一样,都要求函数的返回值类型需要和我们所操作的RDD中的元素类型相同;有时候也会需要返回一个不同类型的值,例如求和和计数同时运行,这里可以对RDD进行map操作,把元素转化为该元素和1的二元组,然后再调用reduce操作;
rdd = sc.parallelize(List(1,2,3,4)) rdd.fold(0)((x,y) = > x + y) // 10 -
collect()
会将整个RDD内容返回驱动程序中,通常在单元测试中使用(RDD数据块比较小),所有数据能放入同一台机器中;不然是在各个worker节点上执行操作;
-
take(n)
返回RDD的n个元素,并且尝试只访问尽量少的分区,该操作会得到一个不均衡的集合。操作返回元素的顺序可能会与预期不一样;
-
top(n)
如果定义了顺序,top()从RDD获取前几个元素;使用默认顺序;
-
foreach(func)
可以对RDD中的每个元素进行操作,而不需要把RDD返回到本地;
-
count()
统计元素个数
-
countByValue()
统计各元素在RDD中出现的次数;
rdd = sc.parallelize(List(1,2,2,2)) rdd.countByValue() // {(1,2),(2,3)} -
takeOrdered(n)(ordering)
从RDD中按照提供的顺序返回最前面的n个元素
rdd.takeOrdered(2)(myOrdering) -
takeSample(withReplacement,num,[seed])
从RDD中返回任意一些元素
rdd.takeSample(false,1) // 返回元素非确定的 -
aggregate(zeroValue)(seqOp,comOp)
和reduce相似,但是通常返回不同类型的函数;
rdd.aggregate((0,0)) ((x, y) => (x._1 + y, x._2 + 1), (x, y) => (x._1 + y._1, x._2 + y._2))
不同RDD类型间转化
- scala将RDD转化为有特定函数的RDD是由隐式转化来自动处理的。这里需要导入模块**import or.apache.spark.SparkContext._**来使用这些隐式转化,这些隐式转换可以隐式地将一个 RDD 转为各种封装类,比如 DoubleRDDFunctions (数值数据的 RDD)和 PairRDDFunctions(键值对 RDD);
- SparkContext 对象隐式转化的 Scala 文档
- RDD隐式转化类的函数应用在scala-RDD文档里可能找不到对应函数,因为隐式转化可以把一个RDD类型转化为另一个类型;比如RDD[Double] -> DoubleRDDFunctions
持久化(缓存)
org.apache.spark.storage.StorageLevel中的持久化级别。有必要,也可以在存储级别末位加上**_2**来把持久化数据保存两份;
| 级别 | 使用的空间 | CPU时间 | 是否在内存中 | 是否在磁盘上 | 备注 |
|---|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | |
| MEMORY_AND_DISK | 高 | 中等 | 部分 | 部分 | 如果数据内存中放不下,则溢写到磁盘上; |
| MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 如果数据内存中放不下,则溢写到磁盘上;在内存中存放序列化后的数据; |
| DISK_ONLY | 低 | 高 | 否 | 是 |
val res = rdd.map(x => x + 1)
res.persist(StorageLevel.MEMORY_ONLY)
println(res.count()) // 调用行动操作
res.reduce((x,y) => x + y) // 再次调用行动reuce操作,已经缓存,无需再重新进行转化操作map计算;
数据缓存多,spark会自动利用最近最少使用的(LRU)的缓存策略把最老的分区从内存中移除。对于仅把数据存放在内存中的缓存级别,下一次要用到已经被移除的分区时,这些分区需要重新计算;对于使用内存与磁盘的缓存级别的分区来说,被移除的分区都会写入磁盘。
键值对RDD操作
- 键值对RDD(pair RDD)通常用来进行聚合计算,一般需要一些初始ETL(抽取、转化、装载)操作来将数据转化为键值对形式。键值对对RDD提供了一些新的操作接口,比如不同RDD分组合并,比如**reduceByKey()**可以分别规约每个键对应的数据、**join()**把键相同的元素组合到一起合并为一个RDD;
创建Pair RDD
- 很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的pair RDD;另外,把一个普通的RDD转化为pari RDD也可以通过调用map()函数来实现,传递的函数需要返回键值对。
// scala中使用第一个单词作为键创建一个pair RDD
val pairs = lines.map(x => (x.split(" ")(0),x))
转化操作
- pair RDD中包含了二元组,需要传递的函数应当操作二元组而不是独立元素。
val pairs = sc.parallelize(List((1,2),(3,4),(3,6)))
单RDD操作
| 函数名称 | 功用 | 示例 | 结果 |
|---|---|---|---|
| reduceByKey(func) | 合并具有相同键的值 | rdd.reduceByKey(_ + _) | {(1,2), (3,10)} |
| groupByKey(func) | 对具有相同键的值进行分组 | rdd.groupByKey() | {(1,[2]), (3, [4,6])} |
| combineByKey(createCombiner, mergeValue, mergeCombines, partitioner) |
使用不同的返回类型合并具有相同键的值 | ||
| mapValues(func) 等同于map{case (k,v) => (k,func(v))} |
对pair RDD中的每个值应用func函数,键不改变; | rdd.mapValues(_ + 1) | {(1,2), (1,3), (1,4), (1,5), (3,4), (3,5)} |
| flatMapValues(func) | 对每个pair RDD中的值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 | rdd.flatMapValues(x => x to 4) | {(1,2), (1,3), (1,4), (3,4)} |
| keys() | 返回一个仅包含键的RDD | rdd.keys() | {1, 3,3} |
| values() | 返回一个仅包含值的RDD | rdd.values() | {2, 4,6} |
| sortByKey() | 返回一个根据键排序的RDD | rdd.sortByKey() | {(1,2), (3,4), (3,6)} |
| keyBy() | 返回一个新的RDD,键不变,value为原来的键+value元组 | rdd.keyBy() | {(1,(1,2)), (3,(3,4)), (3,(3,6))} |
两个pair RDD转化操作
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
val other = sc.parallelize(List((3,9)))
| 函数名称 | 功用 | 示例 | 结果 |
|---|---|---|---|
| subtractByKey | 删掉RDD中键与other RDD中的键相同的元素 | rdd.subtractByKey(other) | {(1, 2)} |
| join | 对两个RDD进行内连接 | rdd.join(other) | {(3, (4, 9)), (3,(6, 9))} |
| rightOuterJoin | 右连接,以右RDD键为基准进行连接,类似于sql | rdd.rightOuterJoin(other) | {(3,(Some(4),9)), (3,(Some(6),9))} |
| leftOuterJoin | 左连接,类似于sql左连接,已左RDD键为基准进行合并 | rdd.leftOuterJoin(other) | {(1,(2,None)), (3,(4,Some(9))), (3,(6,Some(9)))} |
| cogroup | 将两个RDD中拥有相同键的数据分组到一起 | rdd.cogroup(other) | {(1,([2],[])), (3,([4, 6],[9]))} |
- pair RDD也是RDD,支持RDD所支持的函数;
// 筛选第二个元素长度小于10
pairs.filter{case (k,v) => v.length < 10}
-
并行度调优
- 每个RDD都有固定数目的分区,分区数决定了RDD上执行操作时的并行度;在执行聚合或分组操作时,可以自定义分区数;spark会尝试根据集群的大小推断一个有意义的默认值,有时候可能也需要对并行度进行调优获得更好的性能表现;
pairs.reduceByKey(_ + _) // 默认并行度 pairs.reduceByKey(_ + _, 10) // 自定义并行度- 分组或聚合之外,可以通过repartition()函数改变RDD的分区,repartition()函数会把数据通过网络混洗,创建新的分区集合,消耗相对较大。spark中也有一个优化版的repartition()-coalesce()。scala中可以通过rdd.partitions.size()查看RDD的分区个数;
聚合操作
-
reduceByKey()
- 与reduce类似,传入一个函数,返回由各键和对应键规约出来的结果值组成的新的RDD
-
foldByKey(0)
- 与fold类似,初始值为0;
-
mapValues()
- 对值进行map映射操作,键不变;
- 求平均值
pairs.mapValues((_,1)). reduceByKey((x,y) => (x._1 + y._1,x._2 + y._2)). mapValues(x => x._1 / x._1.toFloat). collectAsMap -
combineByKey()
- combineByKey()是最为常用基于键进行聚合的函数,可以让用户返回与输入的类型不同的返回值;combineByKey在遍历元素时,如果是一个新的元素,会调用createCombiner()函数来创建该键对应的累加器的初始值,这一过程每个分区第一次出现各个键触发;如果键存在于createCombiner创建的累加器键里面,会使用mergeValue()方法将该键的累加器对应的值与新的值进行合并;此外,每个分区都是独立的,如果有两个或者多个分区有对应同一个键的累加器,这里需要提供mergeCombiners()方法将各个分区的结果进行合并;以下为求平均值示例:
val result = input.combineByKey( (v) => (v, 1), // createCombiner初始化累加器 (acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), // mergeValue累加 // mergeCombiners()合并 (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // sum / count = avg ).map{ case (key, value) => (key, value._1 / value._2.toFloat) } // 结果转化为映射打印出来 result.collectAsMap().map(println(_))
分组操作
- groupByKey() 使用 RDD 中的键来对数据进行分组。对于一个由类型 K 的键和类型 V 的值组成的 RDD,所得到的结果 RDD 类型会是[K, Iterable[V]];groupBy()可以永固未成对的数据上,也可以根据除键相同以外的条件进行分组。可以接收一个函数,对RDD中每个元素使用该函数,将返回结果作为键再进行分组;
- rdd.reduceByKey(func)与 rdd.groupByKey().mapValues(value => value.reduce(func)) 等价,但是前
者更为高效,因为它避免了为每个键创建存放值的列表的步骤;
- rdd.reduceByKey(func)与 rdd.groupByKey().mapValues(value => value.reduce(func)) 等价,但是前
- 除了对单个 RDD 的数据进行分组,还可以使用一个叫作 cogroup() 的函数对多个共享同一个键的 RDD 进行分组。对两个键的类型均为 K 而值的类型分别为 V 和 W 的 RDD 进行cogroup() 时,得到的结果 RDD 类型为 [(K, (Iterable[V], Iterable[W]))]。如果其中的一个 RDD 对于另一个 RDD 中存在的某个键没有对应的记录,那么对应的迭代器则为空。cogroup() 提供了为多个 RDD 进行数据分组的方法;
- cogroup() 不仅可以用于实现连接操作,还可以用来求键的交集。除此之外,cogroup() 还能同时应用于三个及以上的 RDD
- reduceByKey与groupByKey的区别:
reduceByKey用于每个key对应的多个value进行merge操作,可以在本地先进行merge操作,merge操作可以通过函数自定义;
groupByKey也是对每个key操作,不过是生成一个sequence,本身不能自定义函数,需要基于生成的RDD通过map进行函数转化操作;// wordcount计数:两者都可以实现,但具体内部运算过程是不一样的; val ls = List("python","scala","java","python","scala","scala") var rdd = sc.parallelize(ls) var pairRdd = rdd.map((_,1)) val wordCountByReduce = pairRdd.reduceByKey(_ + _) // 使用groupByKey聚合map计数 val wordCountByGroup = pairRdd.groupByKey().map(x => (x._1,x._2.sum))- reduceByKey具体实现过程
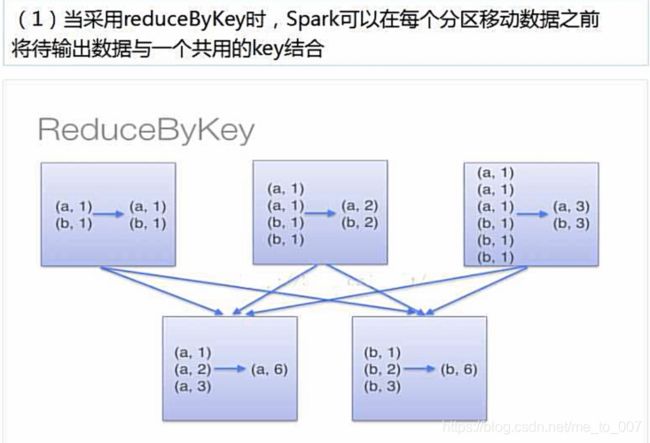
- groupByKey具体实现过程

- reduceByKey具体实现过程
- 计算平均值
// 创建键值对rdd
val rdd = sc.parallelize(Array(("python",3),("hadoop",2),("spark",5),(python,"5)))
// 先分别进行求和和计数,再使用mapValues对value进行求平均操作
rdd.mapValues((_,1)).reduceByKey((x,y) => (x._1 + y._1,x._2 + y._2)).mapValues(x => x._2 / x._1.toFloat).collect
连接操作
- 将有键的数据与另一组有键的数据可以通过键连接操作,pair RDD常用方法;连接方式有:内连接、左外连接、右外连接、交叉连接;具体作用类同于数据库中的连接;
排序
- sortByKey()函数接收一个ascending的参数,默认是true:升序;false为降序;默认是按当前键进行排序,也可以指定函数;
- 默认是每个分区内排序,全局排序需要指定分区参数numPartitions=1
val pairs = sc.parallelize(List((-100,1),(20,2)))
pairs.sortByKey(ascending=false) // 升序参数传入true,默认是true升序排序
// 全局排序
pairs.sortByKey(numPartitions=1)
- sortBy()函数
// 创建键值对rdd
val rdd = sc.parallelize(Array(("a",1),("b",19),("c",9),("d",100),("e",30),("a",200)))
// 按照key降序排序
rdd.reduceByKey(_ + _).sortByKey(false).collect
// res0: Array[(String, Int)] = Array((e,30), (d,100), (c,9), (b,19), (a,201))
// 按照value降序排序
rdd.reduceByKey(_ + _).sortBy(_._2,false).collect
// rdd.reduceByKey(_ + _).sortBy(x => x._2,false).collect 下划线匿名函数
// res1: Array[(String, Int)] = Array((a,201), (d,100), (e,30), (b,19), (c,9))
// 使用sortByKey对value进行排序,通过map函数对换key与value
rdd.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).foreach(println)
分区
RDD分区的一个分区原则是使得分区的个数尽量等于集群中的CPU核心数目;对于不同的Spark部署模式而言(本地模式、Standa Lone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值配置默认分区数目;
本地模式:默认为本地机器的CPU数目,若设置了loacl[N],则默认为N;Apache Mesos默认分区数为8;Standalone或YARN:在‘集群中所有CPU核心数目总和’和‘2’二者中取较大值作为默认值;
- 手动设置分区
- 创建RDD时:调用textFile和parallelize方法时手动指定分区个数;语法格式:textFile(path,partitionNum)
- 通过转化操作得到新的RDD时:直接调用repartition方法即可;
// 手动设置为一个分区
var rdd2 = rdd.repartition(1)
rdd2.partition.size // 查看分区个数:1
var rdd2 = rdd.repartition(4) // 设置分区个数为4
- parallelize如果没有在方法中指定分区数,默认为spark.default.parallelism;textFile如果没有指定分区数,默认为min(defaultParallelism,2);HDFS中读取文件,分区数为文件分片数,比如128MB/片;
- 分区案例
import org.apache.spark.{Partitioner,SparkContext,SparkConf}
// 自定义分区类,继承Partition类
class UserPartition(numParts:Int) extends Partitioner{
// 重写覆盖分区数
override def numPartitions:Int = numParts
// 覆盖分区号获取函数:分区划分规则
override def getPartition(key:Any):Int = {
key.toString.toInt%10 // 对10取余数
}
}
object SetPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
val sc = new SparkContext(conf)
// 模拟设置5个分区
val data = sc.parallelize(1 to 10,5)
// 根据尾号转变为10个分区,分别写到10个文件;
data.map((_,1)).partitionBy(new UserPartition(10)).
map(_._1).saveAsTextFile("file:///usr/local/output")
}
}
共享变量
- 当spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量在每个任务都生成一个副本,但有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量,为了满足这种需求,spark提供了两种类型变量:广播变量(broadcast variables)和累加器(accumulators)。广播变量用来把变量在所有节点的内存之间进行共享;累加器支持在所有不同节点之间进行累加计算(比如计数和求和);
- 广播变量允许程序开发人员在每个机器上缓存一个只读变量,而不是为机器每个任务都生成一个副本;spark的“行动”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,spark都会自动进行广播;(只广播一次,减少通信开销)
- 广播变量可以通过SparkContext.broadcast(v) 从普通变量v生成一个广播变量,通过value方法获取这个广播变量的值;
- 广播变量被创建以后,集群中的任何函数应该使用广播变量broadcastVar的值而不是原始变量v的值,这样就不会把v重复分发到这些节点上;
- 一旦广播变量创建后,普通变量v的值不能再发生修改,确保所有节点获得广播变量的值都是相同的;
// 变量广播 val broadcastVar = sc.broadcast(Array(3,4,5)) // 访问广播变量值 broadcastVar.value(1) // 4- 广播变量示例
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object BroadCastValue {
def main(args:Array[String]):Unit = {
val conf = new SparkConf().setAppName("broadcastAppname").setMaster("local[*]")
// 获取SparkContext
val sc = SparkContext(conf)
// 创建广播变量:10
val broadcastVar = sc.broadcast(10)
// 创建一个测试Array
val intArray = Array(1,2,3,4,5,6,7)
// 转化为rdd(并行化)
val rdd = sc.parallelize(intArray)
// 使用map进行转化操作:所有变量乘以广播变量值:10
val res = rdd.map(_ * broadcastVar.value)
// 打印下结果
res.foreach(println)
}
}
- 累加器是仅仅被相关操作累加的变量,通常可以被用来是先计数器(counter)和求和(sum)。spark原生地支持数值型(numeric)的累加器,开发人员也可以编写对新类型的支持;
- 一个数值型的累加器可以通过SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值;
val accum = sc.longAccumulator("My Accumulator")
// accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 651, name: Some(My Accumulator), value: 0)
sc.parallelize(Array(4,5,6,7,8)).foreach(x => accum.add(x)) // 进行累加操作
accum.value // 返回累加结果值:Long = 30
数据读写
本地文件数据读写
本地文件读取
读取本地文件,文件路径必须以**file:///**开头;转化操作是惰性计算,在未遇到行动操作时不会真实运行;所以假设在行动操作之前,假设文件不存在,也不会报错;
val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
// 如果是读取windows本地文件
val textFile = sc.textFile("file:///F:/test.txt")
文件写入本地
使用saveAsTextFile+完成路径写入本地
// 实际是生成word.txt文件夹,里面有数据分区块文件
textFile.saveAsTextFile("file:///usr/local/spark/mycode/wordcount/wordback.txt")
切换到这个目录下
cd usr/local/spark/mycode/wordcount/wordback.txt/
ls
会出现
part-0000:只有一个分区为part-0000,如果有第二个分区,会出现part-0001
_SUCCES:表示成功
加载保存的数据
// 会读取这个目录下所有文件
val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/wordback.txt")
HDFS文件读写
文件读取
// 路径localhost:9000是当时hdfs配置信息
val textFile = sc.textFile("hdfs://loaclhost:9000/user/hadoop/word.txt")
val textFile = sc.textFile("/user/hadoop/word.txt")
val textFile = sc.textFile("word.txt")
// 以上三条语句是等价的,都是读取hdfs-hadoop用户目录下的文件;这里的hadoop是用户名称
把文件写入到HDFS
val textFile = sc.textFile("word.txt")
textFile.saveAsTextFile("writeback.txt") // 文件写入到hdfs中,生成的也是一个目录
JSON文件读写
// spark安装目录下有这样一个样本文件
val jsonRdd = sc.textFile("file:///usr/local/spark/examples/src/main/resources/people.json")
scala自带有一个JSON库,scala.util.parsing.json.Json,可以解析JSON数据;
JSON.parseFull(jsonString:String)函数,输入json字符串,解析成功返回Some(map:Map[String,Any]),失败返回None;
操作示例
连续n活跃问题
- 取用户连续存在3日活跃;这里的日期暂时直接使用数字代替;
// 生成rdd;用户+数据日期
val rdd = sc.parallelize(List("123,1","234,4","123,2","123,5","344,5","123,3","234,6","007,5","007,7","007,6","234,9"))
// 转化为键值对rdd
val rdd1 = rdd.map(_.split(",")).map(e => (e(0) toInt,e(1)))
// 找出用户连续活跃最大的天数
val rdd2 = rdd1.groupByKey().mapValues(
iter => {
var num = 1
var max = 1
iter.map(x => x.toInt).toArray.sorted.reduce( // 转化成数组升序排序
(x,y) => {
if(y - x == 1){
num += 1 // 如果y,x差为1,num+1
num
}else{
num=1 // 如果y,x差不为1,另num初始为1,重新累加
num
}
if(max<num){max=num} // 该变量用户记录用户最大连续值
y // reduce这里本身不需要进行其他计算返回,只需要比较前后两个数差值机型,返回y
}
)
max // map返回用户最大连续值;
}
)
// 取出有连续大等于3天活跃记录的用户,返回到driver节点上查看;(量级少)
val result = rdd2.filter(_._2>=3).map(_._1).collect