Spark大数据分析平台搭建
1摘要
利用虚拟机实现Spark环境搭建,理解掌握大数据分析集群工作原理。
2题目解析
面对海量的各种来源的数据,如何对这些零散的数据进行有效的分析,得到有价值的信息一直是大数据领域研究的热点问题。大数据分析处理平台就是整合当前主流的各种具有不同侧重点的大数据处理分析框架和工具,实现对数据的挖掘和分析,一个大数据分析平台涉及到的组件众多,如何将其有机地结合起来,完成海量数据的挖掘是一项复杂的工作。
在搭建大数据分析平台之前,要先明确业务需求场景以及用户的需求,通过大数据分析平台,想要得到哪些有价值的信息,需要接入的数据有哪些,明确基于场景业务需求的大数据平台要具备的基本的功能,来决定平台搭建过程中使用的大数据处理工具和框架。
1)操作系统的选择。硬件资源有限,可以在个人电脑上安装两台及以上数量的虚拟机作为底层构建平台。
2)搭建Hadoop集群。Hadoop作为一个开发和运行处理大规模数据的软件平台,实现了在大量的廉价计算机组成的集群红对海量数据进行分布式计算。
3)安装和配置spark。Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用分布式并行计算框架。
3算法原理
3.1 Spark简介
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用分布式并行计算框架。
Spark 拥有Hadoop MapReduce所具有的优点,但和MapReduce的最大不同之处在于,Spark是基于内存的迭代式计算一一Spark的Job处理的中间输出结果可以保存在内存中,从而不再需要读写HDFS。除此之外,一个MapReduce 在计算过程中只有map和reduce两个阶段,处理之后就结束了,而在Spark的计算模型中,可以分为n阶段,因为它的内存是迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。
Spark采用了Scala来编写,在函数表达上Scala有天然的优势,因此在表达复杂的机器学习算法能力方面比其他语言更强且简单易懂。提供各种操作函数来建立起RDD的DAG计算模型。把每一个操作都看成构建一个RDD来对待,而RDD则表示的是分布在多台机器上的数据集合,并且可以带上各种操作函数。
因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。其不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。它是一个用来实现快速而通用的集群计算的平台。
3.2 Spark的优点
1)先进架构。Spark采用Scala语言编写,底层采用了actor model的akka作为通讯框架,代码十分简洁高效;基于DAG图的执行引擎,减少多次计算之间中间结果写到Hdfs的开销;建立在统一抽象的RDD(分布式内存抽象)之上,使得它可以以基本一致的方式应对不同的大数据处理场景。
2)高效。提供Cache机制来支持需要反复迭代的计算或者多次数据共享,减少数据读取的IO开销;与Hadoop的MapReduce相比,Spark基于内存的运算比MR要快100倍,而基于硬盘的运算也要快10倍。
3)易用。Spark提供广泛的数据集操作类型(20+种),不像Hadoop只提供了Map和Reduce两种操作;Spark支持Java,Python和Scala API,支持交互式的Python和Scala的shell。
4)提供整体解决方案。以其RDD模型的强大表现能力,逐渐形成了一套自己的生态圈,提供了full-stack的解决方案;主要包括Spark内存中批处理,Spark SQL交互式查询,Spark Streaming流式计算, GraphX和MLlib提供的常用图计算和机器学习算法。
5)可与Hadoop良好结合。Spark可以使用YARN作为它的集群管理器;读取HDFS,HBase等一切Hadoop的数据。
3.3 Spark整体框架
Spark整体框架如图:

Spark提供了多种高级工具:Shark SQL应用于即席查询(Ad-hoc query)、Spark Streaming应用于流式计算、MLlib应用于机器学习、GraphX应用于图处理。
Spark可以基于自带的standalone集群管理器独立运行,也可以部署在Apache Mesos 和 Hadoop YARN 等集群管理器上运行。
Spark可以访问存储在HDFS、Hbase、Cassandra、Amazon S3、本地文件系统等等上的数据,Spark支持文本文件,序列文件,以及任何Hadoop的InputFormat。
4实验分析
4.1环境条件
虚拟系统环境 Ubuntu64位
JDK版本 Jdk-18.0.1.1
Hadoop版本 Hadoop2.7.7
Scala版本 scala3-3.1.2
Spark版本 spark-3.1.3-bin-hadoop2.7
集群拓扑环境 两台主机
master IP:192.168.154.132
Slave IP:192.168.154.133
利用VMware安装两台Ubuntu x64的虚拟机。实验拓扑如下图所示:
4.2评价方法
搭建Spark大数据分析平台。
1)安装VMware。安装后打开能运行即安装成功。
2)在VMware上安装两台Ubuntu虚拟机。安装好后分别运行测试。
3)在两台虚拟机上配置SSH。然后ssh master,ssh slave连接成功即可。
4)安装配置JDK。配置完成后,运行 java -version能出现正确结果。
5)安装配置Hadoop。配置完成后,Hadoop能正确启动即可。
6)安装配置Scala。配置过程和JDK类似,安装完成即可。
7)安装配置Spark。配置完成后,启动Spark平台,能正常工作。
4.3实验过程
4.3.1 安装两台虚拟机
4.3.2 运行两台虚拟机,分别启动root用户
sudo passwd root #之后按提示输入两次密码,即设置成功。
su root #输入密码,进入root用户
先修改镜像源,如下图,不然执行ifconfig会报错。

apt-get install vim,自带的vi编译器很难用,vim可用性更好。
sudo vi /etc/hostname #修改机器名,一个叫master,一个叫slave。(修改后重启生效)
Sudo vi /etc/hosts #修改hosts配置,两个一样
127.0.0.1 localhost
192.168.154.132 master
192.168.154.133 slave
4.3.3 配置ssh
sudo useradd -m hadoop -s /bin/bash #创建Hadoop新用户
sudo passwd hadoop #设置密码,输入两次即可
sudo adduser hadoop sudo #给hadoop用户赋权限
apt-get install ssh #下载安装ssh
ssh master #先执行一次,不然可能没有~/.ssh路径。之后需要三次密码,随便输都行,反正都是错的
cd ~/.ssh #进入该目录
sudo ssh-keygen -t rsa #生成公钥
cat id_rsa.pub >> ~/.ssh/authorized_keys#在master节点执行
执行后即可无密码连接 ssh master
scp id_rsa.pub hadoop@slave:/home/hadoop/ #进入公钥的目录下,将公钥传输到salve节点
在salve节点执行
cd /home/hadoop #进入id_rsa.pub的路径下
cat id_rsa.pub >> ~/.ssh/authorized_keys #将公钥添加到文件中
之后在master节点执行
ssh slave #即可无密码连接到slave,ssh配置完成
4.3.4 安装JDK
cd /usr
mkdir java #创建文件夹,存放jdk
sudo tar -zxvf jdk.xxx -C /usr/java #将jdk压缩包解压到/usr/java
vi /etc/profile #配置文件,添加以下信息(教程中给的内容有问题,会报错)
export JAVA_HOME=/usr/java/jdk-18.0.1.1 #这里的为自己安装的版本信息
export CLASSPATH= J A V A H O M E / l i b / e x p o r t P A T H = JAVA_HOME/lib/ export PATH= JAVAHOME/lib/exportPATH=PATH:$JAVA_HOME/bin
source /etc/profile #更新配置文件
java -version #效果如下
sudo chmod 777 /usr/java #设置权限,在slave节点执行
Sudo scp -r /usr/java/jdk.xxx hadoop@slave:/usr/java #传输文件,避免重复配置
在slave节点一样修改配置文件/etc/profile,修改完,jdk配置完成
(这里需要注意,后续要安装spark的话,就把jdk版本降到11一下,不然spark不支持,会一直报错)

4.3.5 安装hadoop
sudo tar hadoop.xxx -C /usr/local #将Hadoop压缩包解压到/usr/local
sudo /usr/local/hadoop.xxx /usr/local/hadoop #文件夹改名
sudo chown -R hadoop:hadoop /usr/local/hadoop #修改文件权限
/usr/local/hadoop/bin/hadoop #测试Hadoop是否可用
cd /usr/local/hadoop/bin/hadoop #进入当前路径,配置后续文件
gedit salves #删除localhost,添加master和slave,这是Hadoop的工作文件,必须将两个及以上的集群机器名都写上。
以下是修改配置文件操作:
vi core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abasefor other temporary directories.
hadoop.proxyuser.spark.hosts
hadoop.proxyuser.spark.groups
vi hdfs-site.xml
dfs.namenode.secondary.http-address
master:50090
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
dfs.replication
1
cp mapred-site.xml.templete mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
cp yarn-site.xml.template yarn-site.xml
vi yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
配置好之后,执行
cd /usr/local
sudo tar -zxf ./hadoop.tar.gz ./hadoop
scp ./hadoop.tar.gz hadoop@salve:/home/hadoop
在slave上执行
sudo tar -zxvf /home/hadoop/hadoop.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/hadoop
4.3.6 启动hadoop
在master节点执行
cd /usr/local/hadoop
bin/hdfs namenode -format #第一次启动需要初始化
sbin/start-dfs.sh #启动服务
sbin/start-yarn.sh
启动成功后如图:
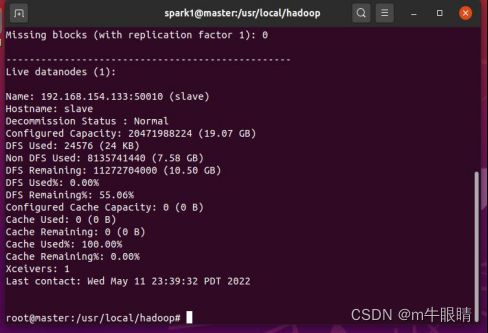
sbin/stop-dfs.sh #结束服务
sbin/stop-yarn.sh
或者sbin/stop-all.sh 直接结束所有服务
4.3.7 配置scala
步骤与配置jdk相同,换一下存储文件即可。
下载安装包并解压到/usr/scala
vi /etc/profile #修改配置文件
export SCALA_HOME=/usr/scala/scala3-3.1.2
export PATH= S C A L A H O M E / b i n : {SCALA_HOME}/bin: SCALAHOME/bin:PATH
source /etc/profile #更新配置文件,使其生效
4.3.8 配置spark
将压缩包解压到/home/hadoop路径下
vi /etc/profile #修改配置文件
export SPARK_HOME=/home/hadoop/spark-3.1.3-bin-hadoop2.7
export PATH= P A T H : PATH: PATH:SPARK_HOME/bin
export SPARK_EXAMPLES_JAR=$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.3.jar
source /etc/profile #使配置生效
cd /home/hadoop/spark.xxx/conf
cp spark-env.sh.template spark-env.sh
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk-18.0.1.1
export SCALA_HOME=/usr/scala/scala3-3.1.2
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/home/hadoop/hadoop/
注意:现在安装的spark安装包内,没有salves文件,应该执行
cp workers.template workers
(workers是spark的工作机器文件,配置好机器后将机器名写入workers中,启动spark就可以看到网页上有几个worker了,配置正确的话)
vi workers
写入master和slave
启动spark
sbin/start-all.sh
停止服务
sbin/stop-all.sh
之后再停止Hadoop服务
4.4结果分析
Cd /home/hadoop/spark.xxx #进入spark工作路径下
Sbin/start-all.sh
结果如图:

5问题与讨论
1.开始修改机器名时,修改完成后须重启虚拟机才能看到修改效果,不然一直显示机器名位ubuntu64。
2.修改hosts配置文件时,第一次执行ifconfig显示的是192.168.154.128和192.168.154.129,后面过几天再次查询的时候就变成了192.168.154.130和192.168.154.131,得再次修改hosts文件。
3.配置ssh生成密钥时,需要执行sudo ssh-keygen -t rsa,给他一个管理员权限,不然会显示生成文件失败。如图:
4.配置JDK的时候,下载的压缩包配置完成都只显示为openJDK,为JDK的阉割版本,后更换最新的ubuntu镜像文件,重新配置,即可。
5.之前配置环境的时候,有一些奇怪的错误,导致后面的spark2始终启动失败,可能是之前配置的路径出错了,所有就在相同路径下删除spark2文件夹,新建spark3,再重新安装,就成功了。
6.配置spark的文件的时候,路径中找不到slaves文件,版本更新后,相同的功能文件叫workers。
附录
文件的相关的安装包的链接如下
链接:https://pan.baidu.com/s/19MJzflroLU5jxNtoNdbckQ
提取码:gasf