【目标检测-YOLO】YOLO v4 架构以及网络详解(第二篇)
0. YOLO v4 概览
1. Bag of freebies(BoF)
不增加推理成本但能够提升目标检测精度的改变训练策略或增加训练成本的方法,称为BoF。
2. Bag of specials(BoS)
增加少量推理成本但能够提升目标检测精度的插件模块和后处理方法,称为BoS。
1. YOLO 总结
| YOLO | Input | Backbone | Neck | Head | 置信度Loss | 坐标回归Loss | 分类Loss |
| v1 | 448*448 | GoogleNet | FC*2 | MSE | |||
| v2 | 32x | DarkNet-19 | Passthrough | Conv | MSE | ||
| v3 | 32x | DarkNet-53 | FPN | Conv | BCE | (x,y)BCE; (w,h)MSE | BCE |
| v4 | 32x | CSPDarkNet-53 |
SPP FPN + PAN |
同v3 | BCE | CIOU | BCE |
2. YOLO v4 架构
2.1 整体架构图

上图通过 Netron 对 DarkNet 版本进行可视化, 然后使用PPT作图。
2.2 Backbone(CSPDarknet53)
顾名思义,CSPDarknet53 是 引入 CSP 的 Darknet53。
CSP 全称为: Cross Stage Partial。CSPDarknet53 使用 Mish激活函数。先介绍 Mish激活函数。
2.2.1 Mish激活函数
Mish激活函数的计算复杂度比ReLU要高不少,如果计算资源不是很够,可以考虑使用LeakyReLU代替Mish。在介绍之前,需要先了解softplus和tanh函数。
softplus激活函数
Softplus 函数是Sigmoid函数的原函数,即softplus函数求导的结果就是sigmoid函数。Softplus可以看做是ReLU函数的一个平滑版本,函数表达式如下:
![]()
![]()

Softplus函数加了1是为了保证非负性。Softplus可以看作是 ReLU函数max(0,x)的平滑版本。红色的即为ReLU。
Softplus 函数的导数刚好是Sigmoid函数.Softplus 函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性.
参考:深度学习笔记:如何理解激活函数?(附常用激活函数) - 知乎
激活函数(ReLU, Swish, Maxout) - 康行天下 - 博客园
softplus 比 ReLU平滑。目前普遍认为,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
tanh 公式: ![]()
Mish 公式: ![]()

蓝色为 Mish 曲线,橙色为 softplus 曲线。Mish和ReLU 一样,都是无正向边界,可以避免梯度饱和;其次Mish函数是处处光滑的,并且在绝对值较小的负值区域允许一些负值。
2.2.2 DarkNet53和CSP
DarkNet53为YOLO v3 中引入的 Backbone。这里不做介绍。
CSP结构来自于 这个论文。

图2:(a) DenseNet (b) CSPDenseNet。

图3:不同的特征融合策略。论文中采用的是 b。
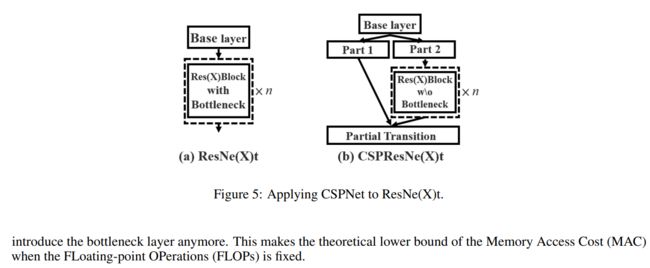
图5:CSPResNe(X)t 。
YOLO v4 实现版本众多。本文以 AlexeyAB 大神的 Darknet 版本为准。
使用模型结构可视化工具 Netron。对网络结构进行可视化,Netron提供了APP和网页2种版本。
这里我们使用网页版来看一下官方给出的网络结构。
方法是:
- 打开网页版Netron网址
- 点击Open Model...输入YOLOv4官方配置文件yolov4.cfg
- 得到可视化的网络结构
为了解读该网络,需要了解 DarkNet 的 cfg 文件 的各层功能。
对于激活函数参考:【darknet源码解析-07】activations.h和activations.c 解析_CVer-CSDN博客
特别的:
linear: f(x) = x, 什么都没干
leaky 即 leaky ReLU
[shortcut]
from=-3
activation=linear
#shortcut操作是类似ResNet的跨层连接,参数from是−3,
#意思是shortcut的输出是当前层与先前的倒数第三层相加而得到。
# 通俗来讲就是add操作
[route]
layers = -1, 36
# 当属性有两个值,就是将上一层和第36层进行concate
#即沿深度的维度连接,这也要求feature map大小是一致的。
[route]
layers = -4
#当属性只有一个值时,它会输出由该值索引的网络层的特征图。
#本例子中就是提取从当前倒数第四个层输出以上参考:【从零开始学习YOLOv3】1. YOLOv3的cfg文件解析与总结 - pprp - 博客园
为了比较,先可视化下 ResNet50,部分图如下:

其中,linear 层啥也不干,先 add(shortcut) 然后激活(leaky)。
而对于 CSPDarkNet53,如下图(608*608 输入)。单分支 route 为引出层,多分支route 为concat 层。Darknet53共有5个大残差块,每个大残差块所包含的小残差单元个数为1、2、8、8、4。
下图为 第一个 残差块,残差单元个数为1。红色虚线框中为 两个 mish 后 进行 add(shortcut)。

完整的图太长了,还是自己看吧。
2.3 Neck
目标检测任务中,为了获得更好的特征,一般在Backbone 和 Head 间插入一些层,这些层被成为 Neck。YOLO v4 的Neck为:SPP,FPN+PAN。
SPP
YOLO v3 已有 SPP 版本,YOLO v4 中还有 SPP模块。并且使用 padding 以使得输出输出大小不变。
Yolov4的作者在使用608*608大小的图像进行测试时发现,在COCO目标检测任务中,以0.5%的额外计算代价将AP50增加了2.7%,因此Yolov4中也采用了SPP模块。

FPN+PAN
YOLO v3 中使用了 FPN,而在 v4 中加入了 PAN。
FPN 是一种自上到下的特征融合模块,PAN 是自下而上的特征融合模块。这里的上下表示的是深层特征为上,底层特征为下。
原始PAN 论文中有下图:

上图中b为 add ,而在YOLO v4 中为 concat。
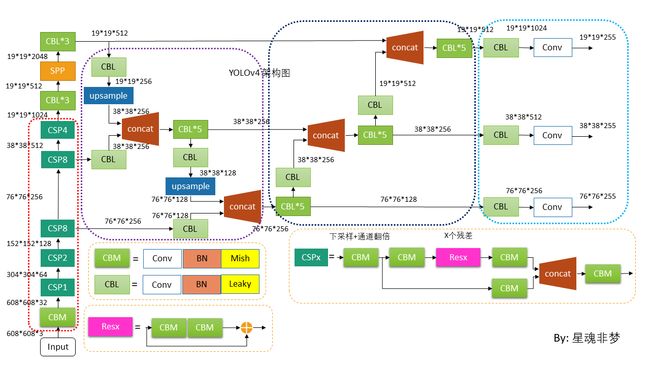
上图紫色虚线框为 FPN 模块,自上而下 进行特征融合。Upsample 采用双线性插值。
黑色虚线框为 PAN 模块,自下而上 进行特征融合。
当然,有人把二者一起称为PAN,个人觉得分开看更容易理解自上而下和自下而上的特征融合。
Head
上图,输出为:用于预测的三个特征图19*19*255、38*38*255、76*76*255。[注:255表示80类别(1+4+80)×3=255]
该部分和YOLO v3 一致。