Pytorch实现文本情感分析
文本情感分析
在本文中介绍如何使用神经网络实现情感分析任务,主要内容为:
- 加载预训练的词向量
- 介绍如何处理情感分析数据集
- 使用循环神经网络模型训练
- 使用一维卷积神经网络模型训练
参考:动手学深度学习
1、加载Glove预训练的词向量
下面创建TokenEmbedding类来加载并使用预训练的词向量。
import torch
import os
import collections
from torch import nn
from d2l import torch as d2l
from torch.utils.data import TensorDataset,DataLoader
'''
加载并使用Glove预训练的词向量
'''
class TokenEmbedding:
def __init__(self, embedding_name):
self.idx_to_token, self.idx_to_vec = self._load_embedding(
embedding_name)
self.unknown_idx = 0
self.token_to_idx = {token: idx for idx, token in
enumerate(self.idx_to_token)}
def _load_embedding(self, embedding_name):
#用于保存id-token和id-特征向量
idx_to_token, idx_to_vec = ['' ], []
data_dir = 'F:/论文数据集/glove.6B'
with open(os.path.join(data_dir, embedding_name + '.txt'), 'r',encoding='UTF-8') as f:
for line in f:
#用空格将token和词向量分开
elems = line.rstrip().split(' ')
token, elems = elems[0], [float(elem) for elem in elems[1:]]
# 跳过标题信息
if len(elems) > 1:
idx_to_token.append(token)
idx_to_vec.append(elems)
#对idx_to_vec的前面加上的词向量 全为0
idx_to_vec = [[0] * len(idx_to_vec[0])] + idx_to_vec
return idx_to_token, torch.tensor(idx_to_vec)
def __getitem__(self, tokens):
#参数为所有的词元,然后获得预训练词向量的索引
indices = [self.token_to_idx.get(token, self.unknown_idx)
for token in tokens]
#返回词向量索引所对应的词向量。
vecs = self.idx_to_vec[torch.tensor(indices)]
return vecs
def __len__(self):
return len(self.idx_to_token)
glove_6b50d = TokenEmbedding('glove.6b.50d')
len(glove_6b50d.idx_to_token),len(glove_6b50d.idx_to_vec)
(400002, 400002)
2、处理情感分析数据集
情感分析的数据集有很多,本文使用大型电影评论数据集进行情感分析。由于原数据为文本和标签,因此需要对其进行处理才能用于模型的输入。
def read_imdb(data_dir,is_train):
data,labels = [],[]
for label in ('pos','neg'):
folder_name = os.path.join(data_dir, 'train' if is_train else 'test',label)
#遍历folder_name文件夹下所有内容
for file in os.listdir(folder_name):
with open(os.path.join(folder_name, file), 'rb') as f:
#保存文本
review = f.read().decode('utf-8').replace('\n', '')
#保存标签
data.append(review)
labels.append(1 if label == 'pos' else 0)
#返回文本和标签内容
return data, labels
下面加载训练集测试上述方法
data_dir = 'F:/论文数据集/aclImdb'
train_data = read_imdb(data_dir, is_train=True)
print('训练集数目:', len(train_data[0]))
for x, y in zip(train_data[0][:3], train_data[1][:3]):
print('标签:', y, 'review:', x[0:60])
训练集数目: 25000
标签: 1 review: Bromwell High is a cartoon comedy. It ran at the same time a
标签: 1 review: Homelessness (or Houselessness as George Carlin stated) has
标签: 1 review: Brilliant over-acting by Lesley Ann Warren. Best dramatic ho
下面创建tokenize函数用于将文本序列拆分为词元列表。
#将文本拆分为单词或者字符词元
def tokenize(lines, token = 'word'):
#拆分为单词
if token == 'word':
return [line.split() for line in lines]
#拆分为字符
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
创建Vocab类用于生成词表,生成每个词与索引的一一对应。
#统计词元的频率,返回每个词元及其出现的次数,以一个字典形式返回。
def count_corpus(tokens):
#这里的tokens是一个1D列表或者是2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
#将词元列表展平为一个列表
tokens = [token for line in tokens for token in line]
#该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。
return collections.Counter(tokens)
#文本词表
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
#按照单词出现频率排序
counter = count_corpus(tokens)
#counter.items():为一个字典
#lambda x:x[1]:对第二个字段进行排序
#reverse = True:降序
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
#未知单词的索引为0
#idx_to_token用于保存所有未重复的词元
self.idx_to_token = ['' ] + reserved_tokens
#token_to_idx:是一个字典,保存词元和其对应的索引
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
#min_freq为最小出现的次数,如果小于这个数,这个单词被抛弃
if freq < min_freq:
break
#如果这个词元未出现在词表中,将其添加进词表
if token not in self.token_to_idx:
self.idx_to_token.append(token)
#因为第一个位置被位置单词占据
self.token_to_idx[token] = len(self.idx_to_token) - 1
#返回词表的长度
def __len__(self):
return len(self.idx_to_token)
#获取要查询词元的索引,支持list,tuple查询多个词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
#self.unk:如果查询不到返回0
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
# 根据索引查询词元,支持list,tuple查询多个索引对应的词元
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
创建load_array函数用于创建数据迭代器。
def load_array(data_arrays,batch_size,is_train=True):
#构造一个Pytorch数据迭代器
dataset = TensorDataset(*data_arrays)
return DataLoader(dataset,batch_size,shuffle=is_train)
创建truncate_pad函数用于将序列截断或者填充为指定长度。
def truncate_pad(line,num_steps,padding_token):
if len(line) > num_steps:
return line[:num_steps]
return line + [padding_token] * (num_steps - len(line))
最后整合上述函数,将其封装到load_data_imdb函数中,返回训练和测试数据集以及IMDb评论集的词表。
'''
返回数据迭代器和IMDb评论数据集的词表
'''
def load_data_imdb(batch_size, num_steps=500):
data_dir = 'F:/论文数据集/aclImdb'
train_data = read_imdb(data_dir, True)
test_data = read_imdb(data_dir, False)
#对句子进行分词
train_tokens = tokenize(train_data[0], token='word')
test_tokens = tokenize(test_data[0], token='word')
#构建词表,这里感觉应该将train_tokens和test_tokens一起构建词表??
vocab = Vocab(train_tokens, min_freq=5)
#将每个词元转为id,并填充截断为统一长度500
train_features = torch.tensor([truncate_pad(
vocab[line], num_steps, vocab['' ]) for line in train_tokens])
test_features = torch.tensor([truncate_pad(
vocab[line], num_steps, vocab['' ]) for line in test_tokens])
train_iter = load_array((train_features, torch.tensor(train_data[1])),
batch_size)
test_iter = load_array((test_features, torch.tensor(test_data[1])),
batch_size,
is_train=False)
return train_iter, test_iter, vocab
3、使用循环神经网络模型训练
下面搭建一个循环神经网络,并使用上面介绍的数据集对其进行训练。
首先搭建模型,使用一个两层的双向LSTM模型。
class BiRNN(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens,
num_layers, **kwargs):
super(BiRNN, self).__init__(**kwargs)
#self.embedding = nn.Embedding.from_pretrained(torch.tensor(embedding_matrix, dtype=torch.float), freeze=False)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 将bidirectional设置为True以获取双向循环神经网络
self.encoder = nn.LSTM(embed_size, num_hiddens, num_layers=num_layers, bidirectional=True,batch_first = True)
self.decoder = nn.Linear(4 * num_hiddens, 2)
def forward(self, inputs):
# inputs的形状是(批量大小,时间步数)
# 输出形状为(时间步数,批量大小,词向量维度)
embeddings = self.embedding(inputs)
self.encoder.flatten_parameters()
# 返回上一个隐藏层在不同时间步的隐状态,
# outputs的形状是(时间步数,批量大小,2*隐藏单元数)
outputs, _ = self.encoder(embeddings)
# 连结初始和最终时间步的隐状态,作为全连接层的输入,
# 其形状为(批量大小,4*隐藏单元数)
encoding = torch.cat((outputs[:,0,:], outputs[:,-1,:]), dim=1)
outs = self.decoder(encoding)
return outs
加载上一节介绍的数据集。
batch_size = 64
train_iter, test_iter, vocab = load_data_imdb(batch_size)
下面为词表中的单词加载预训练的100维Glove嵌入,得到每个词元所对应的词嵌入。
glove_embedding = TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
embeds.shape
torch.Size([49346, 100])
def try_all_gpus():
devices=[torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
'''
计算准确率
'''
def accuracy(y_hat,y):
#计算预测正确的数量
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
y_hat=y_hat.argmax(axis=1)
cmp=y_hat.type(y.dtype)==y
return float(cmp.type(y.dtype).sum())
'''
GPU上计算准确率
'''
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# Required for BERT Fine-tuning (to be covered later)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), d2l.size(y))
return metric[0] / metric[1]
'''
用多GPU进行小批量训练
'''
def train_batch(net, X, y, loss, trainer, devices):
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
scheduler.step()
train_loss_sum = l.sum()
train_acc_sum = accuracy(pred, y)
return train_loss_sum, train_acc_sum
'''
用多GPU进行模型训练
'''
def train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices = try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
embed_size, num_hiddens, num_layers = 100, 100, 2
devices = try_all_gpus()
net = BiRNN(len(vocab), embed_size, num_hiddens, num_layers)
net.embedding.weight.data.copy_(embeds)
net.embedding.weight.requires_grad = False
#初始化模型参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.LSTM:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(init_weights);
lr, num_epochs = 0.01, 5
#params = filter(lambda p: p.requires_grad, net.parameters())
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
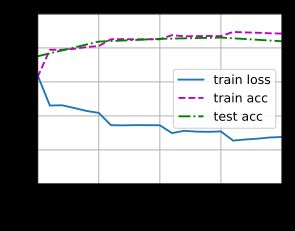
train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
loss 0.276, train acc 0.884, test acc 0.839
505.9 examples/sec on [device(type='cuda', index=0)]
4、使用一维卷积神经网络模型训练
先看看一维卷积是如何工作的。下图是基于互相关运算的二维卷积的特例。

搭建一维时间卷积模型
class TextCNN(nn.Module):
def __init__(self, vocab_size, embed_size, kernel_sizes, num_channels,embedding_matrix,
**kwargs):
super(TextCNN, self).__init__(**kwargs)
self.embedding = nn.Embedding.from_pretrained(torch.tensor(embedding_matrix, dtype=torch.float))
self.constant_embedding = nn.Embedding.from_pretrained(torch.tensor(embedding_matrix, dtype=torch.float), freeze=False)
# self.embedding = nn.Embedding(vocab_size, embed_size)
# 这个嵌入层不需要训练
# self.constant_embedding = nn.Embedding(vocab_size, embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 2)
# 池化层
#对于一个输入(B C L)的tensor进行一维的pool,变为(B,C,1)
self.pool = nn.AdaptiveAvgPool1d(1)
self.relu = nn.ReLU()
# 创建多个一维卷积层
self.convs = nn.ModuleList()
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(2 * embed_size, c, k))
def forward(self, inputs):
# 沿着向量维度将两个嵌入层连结起来,
# 每个嵌入层的输出形状都是(批量大小,词元数量,词元向量维度)连结起来
embeddings = torch.cat((
self.embedding(inputs), self.constant_embedding(inputs)), dim=2)
#print(embeddings.shape)
# 根据一维卷积层的输入格式,重新排列张量,以便通道作为第2维
embeddings = embeddings.permute(0, 2, 1)
# 每个一维卷积层在最大时间汇聚层合并后,获得的张量形状是(批量大小,通道数,1)
# 删除最后一个维度并沿通道维度连结
#单独使用三个ConvD1,将最后结构拼在一起
encoding = torch.cat([torch.squeeze(self.relu(self.pool(conv(embeddings))), dim = -1) for conv in self.convs], dim = 1)
#print(encoding.shape)
outputs = self.decoder(self.dropout(encoding))
return outputs
定义相关参数,对模型进行训练。
embed_size, kernel_sizes, nums_channels = 100, [3, 4, 5], [100, 100, 100]
devices = d2l.try_all_gpus()
net = TextCNN(len(vocab), embed_size, kernel_sizes, nums_channels,embeds)
def init_weights(m):
if type(m) in (nn.Linear, nn.Conv1d):
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights);
#net.embedding.weight.data.copy_(embeds)
#net.constant_embedding.weight.data.copy_(embeds)
#net.constant_embedding.weight.requires_grad = False
lr, num_epochs = 0.001, 5
params = filter(lambda p: p.requires_grad, net.parameters())
trainer = torch.optim.Adam(params, lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
#自己调整学习率
#scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, 10)
train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
loss 0.127, train acc 0.954, test acc 0.875
1072.4 examples/sec on [device(type='cuda', index=0)]
