80GB医学影像数据集发布!OCTA-500公开下载
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文转载自:中国图象图形学报
注:文末附数据集下载和医疗影像交流群
现代医学中,医学影像是重要的临床诊断和鉴别诊断方法,是医疗过程中最重要的环节之一。目前医院里70%的临床诊断行为需要借助医学影像的检查,影像数据已占到医院总数据量的80%~90%。
数据驱动的人工智能技术正在飞速发展,许多国际知名的数据集、样本库都成为开展科学研究、实验检测、成果推广不可缺少的重要资源,并成为学术论文的重要组成部分。
光学相干断层扫描血管造影(OCTA)是建立在光学相干断层扫描(OCT)技术上的一种崭新的成像模态,它以微米级的分辨率显示视网膜血管的三维结构,弥补了OCT无法提供血流信息的不足。由于OCTA技术起步较晚尚未完全普及,目前缺少公开的数据集供研究人员使用。
为了推进OCTA图像的处理和分析技术发展,《中国图象图形学报》编委南京理工大学陈强教授及其团队发布了目前最大的OCTA图像数据集OCTA-500。它包含500只眼睛的OCT和OCTA两种模态的三维数据,六种投影图像,四种文本标签以及两种分割标签,同时基于该数据库他们还提出了一种三维到二维分割的图像投影网络。
OCTA-500数据集下载地址
https://ieee-dataport.org/open-access/octa-500
01
OCTA-500数据集简介
光学相干断层扫描血管造影(OCTA)是一种新兴的非侵入式成像技术,通过该技术可以获得视网膜血流系统的三维结构,帮助医生观察不同视网膜层的血流信息,已经逐渐成为眼底相关疾病观测的重要工具。
目前,OCTA图像较为稀缺,公开的OCTA图像数据集极少,并且还没有一个公开数据集包含OCTA原始的三维信息,数据的稀缺限制了研究者对OCTA图像的进一步处理和分析。为了推进OCTA图像分析和处理技术的发展。来自南京理工大学陈强教授团队公开发布了目前最大的OCTA图像数据集OCTA-500。
该数据集包含500只眼睛的OCT和OCTA两种模态的三维体数据、六种投影图像、四种文本标签(年龄、性别、左右眼、疾病类型)以及两种分割标签(视网膜大血管、无血管区),数据库总大小约80GB。数据库包含内容如下:
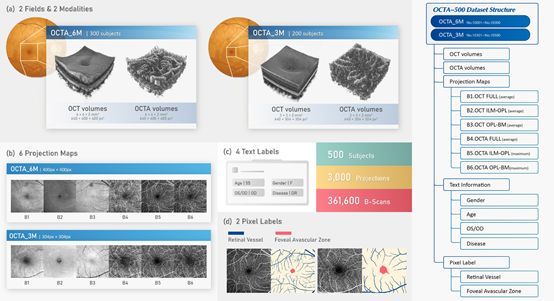
图1 OCTA-500数据集内容汇总及组织结构

图2 两种视野范围的OCT三维数据和OCTA三维数据
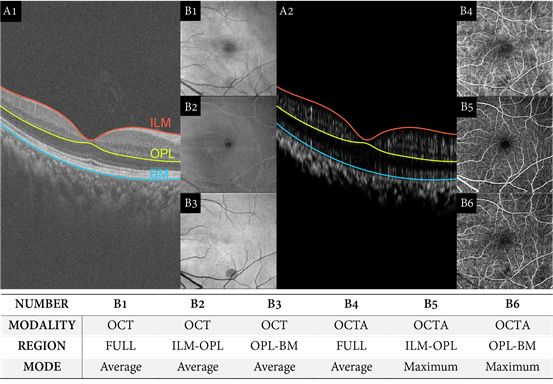
图3 通过视网膜层分割算法生成的六种常用视网膜投影图

图4 四种类型的文本标签及其在数据库中的分布情况

图5 两种像素级分割标签:大血管标签以及无血管区标签
02
相关论文及代码
相关论文1:Image Projection Network: 3D to 2D Image Segmentation in OCTA Images
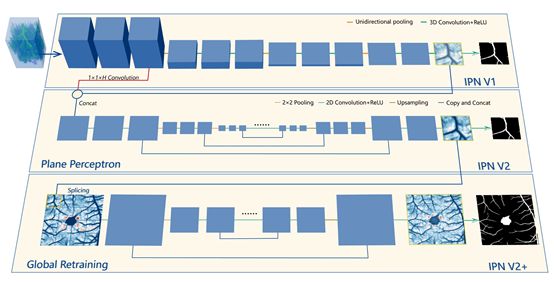
基于OCTA500数据集,提出了一种三维到二维的图像分割方法——图像投影网络,该方法可以充分利用OCTA的三维信息,不需要借助视网膜层分割算法。
方法简图:

论文作者:
Mingchao Li, Yerui Chen, Zexuan Ji, Keren Xie, Songtao Yuan, Qiang Chen, Shuo Li
录用期刊:
IEEE Transactions on Medical Imaging
全文链接:
https://ieeexplore.ieee.org/document/9085991
代码链接:
https://github.com/chaosallen/IPN_tensorflow
论文首页:

相关论文2:IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation
详细介绍了OCTA-500数据集,发布了图像投影网络-V2,提升了图像投影网络的性能,同时克服了由于分块训练带来的棋盘效应。
方法简图:
论文作者:
Mingchao Li, Yuhan Zhang, Zexuan Ji, Keren Xie, Songtao Yuan, Qinghuai Liu,Qiang Chen
全文链接:
https://arxiv.org/abs/2012.07261
代码链接:
https://github.com/chaosallen/IPNV2_pytorch
论文首页:

03
作者介绍

李鸣超,博士研究生,南京理工大学计算机科学与工程学院,主要研究方向为OCTA,医学图像处理与分析。
Email:[email protected]

陈强,教授,博士生导师,南京理工大学计算机科学与工程学院,主要研究领域:图像处理和分析,机器学习和人工智能。
E-mail: [email protected]
04
团队介绍
陈强团队致力于视网膜图像处理和分析,主要研究方向包括目标定位/检测和分割、病变预测、多模态图像生成和融合、图像质量提升、病变筛查、病变和组织可视化显示等。近十年通过与美国斯坦福大学、江苏省人民医院等紧密合作,在TMI、MedIA、MICCAI等国际顶级期刊和会议上发表了一系列高水平成果。
近期成果:
[1]Yuhan Zhang, Xiwei Zhang, Zexuan Ji, Sijie Niu, Theodore Leng, Daniel L. Rubin, Songtao Yuan, Qiang Chen. An integrated time adaptive geographic atrophy prediction model for SD-OCT images. Medical Image Analysis, 68: 101893, 2021
[2]Mingchao Li, Yerui Chen, Zexuan Ji, Keren Xie, Songtao Yuan, Qiang Chen, Shuo Li. Image projection network: 3D to 2D image segmentation in OCTA images. IEEE Transactions on Medical Imaging, 39(11): 3343-3354, 2020
[3]Xiao Ma, Zexuan Ji, Sijie Niu, Theodore Leng, Daniel L. Rubin, Qiang Chen. MS-CAM: Multi-scale class activation maps for weakly-supervised segmentation of geographic atrophy lesions in SD-OCT images. IEEE Journal of Biomedical and Health Informatics, 24(12):3443-3455, 2020
[4]Idowu Paul Okuwobi, Zexuan Ji, Wen Fan, Songtao Yuan*, Loza Bekalo, and Qiang Chen. Automated Quantification of Hyperreflective Foci in SD-OCT with Diabetic Retinopathy. IEEE Journal of Biomedical and Health Informatics, 2020, 24(4): 1125-1136
[5]Qiuzhuo Xu, Weiwei Zhang, Hongjing Zhu, Qiang Chen. Foveal avascular zone volume: a new index based on optical coherence tomography angiography images. Retina The Journal of Retinal and Vitreous Diseases, 2020, in press
[6]Yuhan Zhang, Chen Huang, Mingchao Li, Sha Xie, Keren Xie, Zexuan Ji, Songtao Yuan, Qiang Chen. Robust Layer Segmentation against Complex Retinal Abnormalities for en face OCTA Generation. International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2020, LNCS 12265: 647-655
[7] Chen Huang, Keren Xie, Yuhan Zhang, Mingchao Li, Zhongmin Wang, Qiang Chen. Adaptive Dictionary Learning Based Multimodal Branch Retinal Vein Occlusion Fusion. International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2020, LNCS 12265: 606-615
数据集下载
后台回复:OCTA-500,即可下载上述数据集
CV资源下载
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
后台回复:Trasnformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
重磅!CVer-医疗影像交流群成立
扫码添加CVer助手,可申请加入CVer-医疗影像方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!