SVM支持向量机原理及代码实现
文章目录
- 序言
- 1.数学知识补充
-
- 1.1凸函数
-
- 常见的凸函数
- 1.2对偶问题
-
- 强对偶
-
- slater条件
- 弱对偶
- KKT条件
- 1.3拉格朗日乘数法
-
- 原公式以及对偶公式的由来
- 拉格朗日乘数法的作用
- 1.4多元函数求极值
- 1.5.线性可分
- 2.SVM原理及推导
-
- 2.1原理
- 2.2目标函数推导过程
- 2.3目标函数的拉格朗日化
- 3.核技巧(kernel)
-
- 3.1常见的核:
- 4.SVM的解法:SMO
-
- 4.1坐标轮换法:
- 4.2SMO算法原理
- 4.3SMO的python实现
- 5.文末的话
序言
记得刚开始接触svm算法的时候是在sklearn的课程上,那时候对机器学习还处于一个出生婴儿的阶段,学了一大段时间之后,也就记得了初始化,拟合模型,输出预测结果三行代码。对这个算法的理解很浅,是名副其实的调包侠。所幸如今有机会在此更深入地补全svm的知识。
因为在该算法中会用到不少的数学知识,故本文会先介绍所用到的数学知识,而后阐述原理和公式部分,最后呈现上代码的解决方法。
笔者自认才疏学浅,仅略懂皮毛,更兼时间与精力有限,文中错谬之处在所难免,敬请读者批评指正。笔者微信:827062650
1.数学知识补充
此部分仅对该模型的数学知识有不理解的读者起到简单解释,抛砖引玉的作用。数学知识在算法的运用上很广泛,如果感兴趣的读者,建议查看对应的教科书,获取更准确和更深刻的解答。
1.1凸函数
多元的一般函数和凸函数如下图所示,一般的函数拥有全局最优解和局部最优解,而凸函数具有只包含一个最优解的优良性质。则在我们常见的算法中,都尽可能将目标函数转换为凸函数。而一般来说,凹函数和凸函数除符号外无本质区别,本文将具有这类性质的函数统称为凸函数。

一般函数 凸函数
定义
f ( β x + ( 1 − β ) y ) ≤ β f ( x ) + ( 1 − β ) f ( y ) x , y ∈ d o m f \\ f(\beta x +(1- \beta)y) \le \beta f(x) +(1- \beta)f(y)\\ x,y \in domf f(βx+(1−β)y)≤βf(x)+(1−β)f(y)x,y∈domf
常见的凸函数
先说明一个凸函数的优良性质:凸函数之和也为凸函数
- 线性函数
- exp(x) , -log(x) , xlog(x)
- 范数
- 逻辑回归损失函数
1.2对偶问题
任何一个求极大化的线性规划问题都有一个求极小化的线性规划问题与之对应,反之亦然,如果我们把其中一个叫原问题,则另一个就叫做它的对偶问题,并称这一对互相联系的两个问题为一对对偶问题。
对偶问题具有优良性质:无论原问题是什么,他的对偶问题都为凸函数。
例如:
L ( w , α , β ) = f ( w ) + ∑ i = 1 k a i g i ( w ) + ∑ i = 1 l β i h i ( w ) 原 问 题 : m i n w m a x α , β L ( w , α , β ) 对 偶 问 题 : m a x α , β m i n w L ( w , α , β ) 可 以 证 明 : A ( x ) = m a x α , β L ( w , α , β ) > L ( w , α , β ) > m i n w L ( w , α , β ) = B ( α , β ) 则 : A ( x ) ≥ B ( α , β ) 恒 成 立 , 则 原 问 题 的 解 必 定 大 于 或 等 于 对 偶 问 题 的 解 L(w,\alpha,\beta)=f(w)+\sum_{i=1}^ka_ig_i(w)+\sum_{i=1}^l\beta_ih_i(w)\\ 原问题:\underset{w}{min}\underset{\alpha,\beta}{max}L(w,\alpha,\beta)\\ 对偶问题:\underset{\alpha,\beta}{max}\underset{w}{min}L(w,\alpha,\beta)\\ 可以证明:A(x)=\underset{\alpha,\beta}{max}L(w,\alpha,\beta)>L(w,\alpha,\beta)>\underset{w}{min}L(w,\alpha,\beta)=B(\alpha,\beta)\\ 则:A(x) \ge B(\alpha,\beta)\quad 恒成立,则原问题的解必定大于或等于对偶问题的解 L(w,α,β)=f(w)+i=1∑kaigi(w)+i=1∑lβihi(w)原问题:wminα,βmaxL(w,α,β)对偶问题:α,βmaxwminL(w,α,β)可以证明:A(x)=α,βmaxL(w,α,β)>L(w,α,β)>wminL(w,α,β)=B(α,β)则:A(x)≥B(α,β)恒成立,则原问题的解必定大于或等于对偶问题的解
强对偶
而当原问题的解等于对偶问题的解。则为强对偶问题。
强对偶 一般情况下不成立,而在凸函数下一般会成立,在非凸函数下一般不成立。
在定义上,只要满足slater条件的凸优化问题,就是强对偶问题。(充分条件)
slater条件
m i n f ( w ) s . t . g i ( w ) ≤ 0 i = 1 , 2 , ⋅ ⋅ ⋅ ⋅ n h i ( w ) = 0 i = 1 , 2 , ⋅ ⋅ ⋅ ⋅ n min f(w)\\ s.t. \quad g_i(w)\le0 \quad i=1,2,····n\\ \quad \quad h_i(w) =0\quad i=1,2,····n\\ minf(w)s.t.gi(w)≤0i=1,2,⋅⋅⋅⋅nhi(w)=0i=1,2,⋅⋅⋅⋅n
假设g与f都是凸函数,h为仿射函数。同时假设存在w使得g(w)<0对所有i都成立,则称该问题符合slater条件。该问题为强对偶问题。
弱对偶
当原问题的解大于对偶问题的解,则为弱对偶问题。
KKT条件
KKT条件是由Karush-Kuhn-Tucker三人联合发表的,所以称为KKT条件。
当原问题为强对偶问题,则该问题必定符合KKT条件
L ( w , α , β ) = f ( w ) + ∑ i = 1 k a i g i ( w ) + ∑ i = 1 l β i h i ( w ) K K T 条 件 : w ∗ , α ∗ , β ∗ 为 最 优 解 时 的 值 ∂ L ∂ w ∗ , α ∗ , β ∗ = 0 α i ∗ g i ( w ∗ ) = 0 在 支 持 向 量 机 中 , 不 在 超 平 面 上 的 样 本 , 其 g i ( w ∗ ) ≠ 0 , 则 α i = 0 恒 成 立 。 L(w,\alpha,\beta)=f(w)+\sum_{i=1}^ka_ig_i(w)+\sum_{i=1}^l\beta_ih_i(w) \\ KKT条件:w^*,\alpha^*,\beta^*为最优解时的值\\ \frac{\partial L}{\partial w^*,\alpha^*,\beta^*}=0 \\ \bf{\alpha_i^*g_i(w^*)=0}\\ 在支持向量机中,不在超平面上的样本,其g_i(w^*)\ne0,则\alpha_i=0恒成立。 L(w,α,β)=f(w)+i=1∑kaigi(w)+i=1∑lβihi(w)KKT条件:w∗,α∗,β∗为最优解时的值∂w∗,α∗,β∗∂L=0αi∗gi(w∗)=0在支持向量机中,不在超平面上的样本,其gi(w∗)=0,则αi=0恒成立。
1.3拉格朗日乘数法
原公式以及对偶公式的由来
拉格朗日乘数法是一种求解带约束的多元函数问题的方法。该方法可以将带约束的优化问题转化为不带约束的优化问题。
直观来说就是一种求解以下方程的一种方法:
原 问 题 : m i n f ( w ) s . t . g i ( w ) ≤ 0 i = 1 , 2 , ⋅ ⋅ ⋅ ⋅ n h i ( w ) = 0 i = 1 , 2 , ⋅ ⋅ ⋅ ⋅ n 原问题: min f(w)\\ s.t. \quad g_i(w)\le0 \quad i=1,2,····n\\ \quad \quad h_i(w) =0\quad i=1,2,····n\\ 原问题:minf(w)s.t.gi(w)≤0i=1,2,⋅⋅⋅⋅nhi(w)=0i=1,2,⋅⋅⋅⋅n
s.t. 表示subject to ,“受限于”的意思。
对原式做拉格朗日乘法变换。
L ( w , α , β ) = f ( w ) + ∑ i = 1 k a i g i ( w ) + ∑ i = 1 l β i h i ( w ) 其 中 α , β 为 拉 格 朗 日 算 子 , α , β > 0 L(w,\alpha,\beta)=f(w)+\sum_{i=1}^ka_ig_i(w)+\sum_{i=1}^l\beta_ih_i(w) \\ 其中\alpha,\beta为拉格朗日算子,\alpha,\beta>0 L(w,α,β)=f(w)+i=1∑kaigi(w)+i=1∑lβihi(w)其中α,β为拉格朗日算子,α,β>0
同时可以通过证明得出下式与原问题相同
m i n w m a x α , β L ( w , α , β ) s . t . α > 0 \underset{w}{min}\underset{\alpha,\beta}{max}L(w,\alpha,\beta)\\ s.t. \alpha>0 wminα,βmaxL(w,α,β)s.t.α>0
证明过程如下:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ &当w处于原式中的不可行域内…
为了转化成凸函数方便求解,则可以推出原问题的对偶问题:
m a x α , β m i n w L ( w , α , β ) s . t . α > 0 \underset{\alpha,\beta}{max}\underset{w}{min}L(w,\alpha,\beta)\\ s.t. \alpha>0 α,βmaxwminL(w,α,β)s.t.α>0
拉格朗日乘数法的作用
- 将约束条件合并到公式内,将带约束的优化问题转化为不带约束的优化问题。
- 拉格朗日乘数法后的对偶问题一定为凸函数。
- 在svm里,可以通过证明得出,不在超平面上的点所对应的α为0。大大简化了后续的计算。(该证明建议去理解)
1.4多元函数求极值
$$
定理(必要条件):设函数 z=f(x, y) 在点 \left(x_{0}, y_{0}\right) 具有偏导数, 且在点 \left(x_{0}, y_{0}\right) 处有极值, \
则有 \quad
f_{x}\left(x_{0}, y_{0}\right)=0, \quad f_{y}\left(x_{0}, y_{0}\right)=0 .\
即:函数在点 \left(x_{\circ} , y_{0}\right) 处有偏导且有极值则该点处偏导为 0
$$
该定理将会在后续处理简化拉格朗日后的函数中使用到。
1.5.线性可分
线性可分就是说可以用一个线性函数把两类样本分开,比如二维空间中的直线、三维空间中的平面以及高维空间中的线性函数。
2.SVM原理及推导
2.1原理
接下来进入正题,开启原理的说明
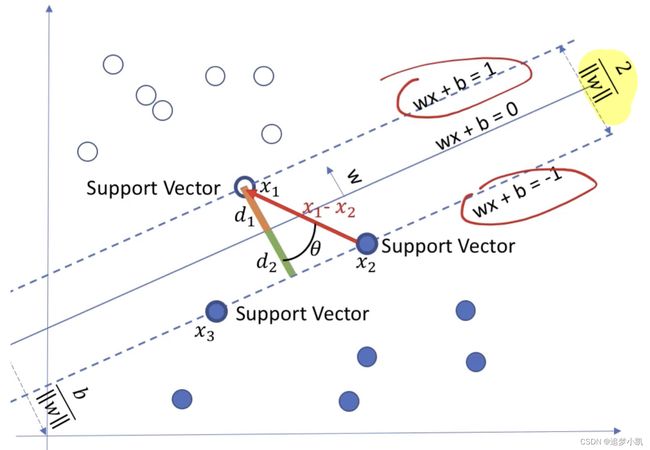
先从二维的空间展开。如上图所示,想要使用直线wx+b=0将两种不同类别的点,
而这样的直线往往不止一条,如何确定该直线呢?
习惯性将在距离分割线两边分别最近的点做一条与分割线平行的直线,计算该两直线的距离。
则当该距离最大时,此时的wx+b=0便是决策子。
推导到三维或是n维,起到该直线一样作用的称为超平面,在高维空间中的一个平面将两类点分开。w则是长度为n的矩阵
2.2目标函数推导过程
$$
取x1,x2为正负超平面上的点\
\begin{gather}
则有\quad w^Tx_1+b=1 \quad w^Tx_2+b=-1 \
(wTx_1+b)-(wTx_2+b) = 2 \
w^T(x_1-x_1)=2 \
\parallel w\parallel \parallel x_1-x_2 \parallel cos \theta = 2 \
\parallel x_1-x_2 \parallel =\frac{2}{\parallel w\parallel } \
而x_1-x_2的模即为两个超平面之间的距离,则我们的目标函数可以转化为求\parallel w\parallel的最小值
\end{gather}
$$
最终,我们的目标函数为:
M i n w 1 2 ∥ w ∥ 2 s . t . y ( i ) ( w T x ( i ) + b ) ≤ 1 \begin{aligned} &Min_{w} \frac{1}{2}{\parallel w\parallel }^{2}\\ &s.t. \quad y^{(i)}(w^Tx^{(i)}+b) \le1 \end{aligned} Minw21∥w∥2s.t.y(i)(wTx(i)+b)≤1
2.3目标函数的拉格朗日化
由拉格朗日求解的过程,先构造约束条件
y ( i ) ( w T x ( i ) + b ) ≤ 1 ⟶ g i ( w ) = y ( i ) ( w T x ( i ) + b ) + 1 ≤ 0 \quad y^{(i)}(w^Tx^{(i)}+b) \le1 \quad \longrightarrow \quad g_i(w)=y^{(i)}(w^Tx^{(i)}+b)+1 \le0 y(i)(wTx(i)+b)≤1⟶gi(w)=y(i)(wTx(i)+b)+1≤0
之后目标函数构造成拉格朗日函数
$$
\begin{align}
&L(w,b,\alpha)=\frac{1}{2}{\parallel w\parallel }{2}-\sum_{i=1}n \alpha_i[ y{(i)}(wTx^{(i)}+b)-1] \tag1 \
&\frac{\partial L}{\partial w} =w-\sum_{i=1}^n\alpha_{i} y{(i)}x{(i)}=0 \quad \Rightarrow w=\sum_{i=1}^n\alpha_i y{(i)}x{(i)} \tag2 \
&\frac{\partial L}{\partial b} = \sum_{i=1}^n \alpha_{(i)}=0 \tag3 \
&将2,3式带入1式可得\
\
&L(w,b,\alpha)=\sum_{i=1}^n \alpha_i-\frac{1}{2}\sum_{i,j=1}ny{(i)}y{(j)}\alpha_{i}\alpha_{j}(x{(i)})Tx{(j)}
\end{align}
为 方 便 求 解 , 可 将 该 函 数 转 化 为 其 对 偶 函 数 为方便求解,可将该函数转化为其对偶函数 为方便求解,可将该函数转化为其对偶函数
\begin{aligned}
&\underset{\alpha}{max} W(\alpha) =\sum_{i=1}^n \alpha_i-\frac{1}{2}\sum_{i,j=1}ny{(i)}y{(j)}\alpha_{i}\alpha_{j}(x{(i)})Tx{(j)} \
&s.t: \quad \alpha_i \ge0 ,i=1,2,···n \
&\qquad \quad \sum_{i=1}n\alpha_iy{(i)}=0
\end{aligned}
$$
最终可以解出α,w,b
得出来的决策子为:
f ( x ) = w T x + b = ( ∑ i = 1 n α i y ( i ) x ( i ) ) T x + b f(x)=w^Tx+b=(\sum_{i=1}^n\alpha_i y^{(i)}x^{(i)})^Tx+b \\ f(x)=wTx+b=(i=1∑nαiy(i)x(i))Tx+b
其中,当样本点不在两个超平面上时候,α都为0(可回上文参考KKT条件)。则模型训练完后,只需要存储在超平面上的样本点,也称这类样本点为支持向量。该模型也因此获名为支持向量机。
3.核技巧(kernel)
当出现线性不可分的情况,例如如下图所示,样本点分布得很散乱,则需要用到我们的核技巧。
在处理线性不可分的情况时,一般有两种选择,第一种是直接构建高次多项式去拟合;第二种则是将数据升维,在无穷多维下,数据一定线性可分。而支持向量机则使用第二种方法。
$$
\underset{\alpha}{max} W(\alpha) =\sum_{i=1}^n \alpha_i-\frac{1}{2}\sum_{i,j=1}ny{(i)}y{(j)}\alpha_{i}\alpha_{j}(x{(i)})Tx{(j)} \
(x{(i)})Tx^{(j)} \quad : x_i与x_j两个向量的内积,用核函数k
\underset{\alpha}{max} W(\alpha) =\sum_{i=1}^n \alpha_i-\frac{1}{2}\sum_{i,j=1}ny{(i)}y^{(j)}\alpha_{i}\alpha_{j}k
$$
而由支持向量机的公式中,可以发现,只需要算出升维后数据的内积,就可以得到所需要的结果。
通过相应的核函数,我们就可以使用升维前的样本数据计算出升维后的样本内积。
3.1常见的核:
- 多项式核(polynomial kernel)
K ( x i , x j ) = ( < x i , x J > + c ) d 当 c = 0 , d = 1 时 , 为 线 性 核 , 等 于 无 核 。 K(x_i,x_j)=(
核函数与数据升维的关系:
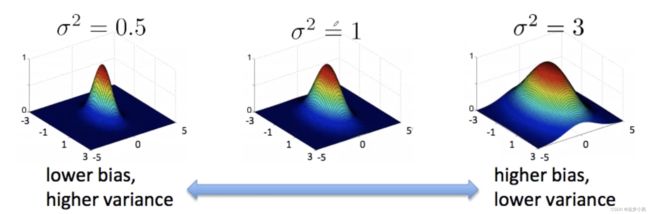
- 高斯核(RBF)
k ( x i , x j ) = e x p ( − ∥ x i − x j ∥ 2 2 2 σ 2 ) k(x_i,x_j)=exp(-\frac{\parallel x_i-x_j\parallel_2^2}{2\sigma ^2}) k(xi,xj)=exp(−2σ2∥xi−xj∥22)
当xi=xj时,内积为1,当两者距离增大,值趋于0。使用该核函数前需要将特征归一化。
当参数σ越小时,该方法越容易过拟合。
-
sigmoid kernel
该内核等价于无隐含层的简单神经网络。
k ( x i , x j ) = t a n h ( α x i T x j + C ) k(x_i,x_j)=tanh(\alpha x_i^Tx_j+C) k(xi,xj)=tanh(αxiTxj+C) -
cosine similarity kernel
该内核可用于自然语言处理
-
chi-squared kernel
该内核可用于计算机视觉
4.SVM的解法:SMO
4.1坐标轮换法:
坐标轮换法是每次允许一个变量变化,其余变量保持不变,即沿坐标方向轮流进行搜索的寻优方法。 它把多变量的优化问题轮流的转化成单变量的优化问题,因此又称变量轮换法。是一种求无约束 最优化 问题的降维方法
算法步骤如下:
1. 已 知 n 维 函 数 f ( x ) , 任 选 起 始 点 X 0 ( x 1 , x 2 , x 3 ⋅ ⋅ ⋅ x n ) 。 2. 固 定 x 2 , x 3 ⋅ ⋅ ⋅ x n , 寻 找 最 优 解 时 的 x 1 , 并 且 更 新 X 0 中 的 x 1 , 以 此 步 骤 更 新 完 x n 则 为 一 轮 。 3. 在 一 轮 结 束 后 , 判 断 条 件 ∥ X k n − X k − 1 n ∥ ≤ ε , k 为 轮 数 若 不 满 足 既 可 以 开 启 下 一 轮 , 重 复 步 骤 2 。 若 满 足 , 则 停 止 迭 代 , 输 出 最 优 解 X ∗ = X k n \begin{aligned} &1. 已知n维函数f(x),任选起始点X_0(x_1,x_2,x_3···x_n)。\\ &2. 固定x_2,x_3···x_n,寻找最优解时的x_1,并且更新X_0中的x_1,以此步骤更新完x_n则为一轮。\\ &3. 在一轮结束后,判断条件\parallel X_k^n- X_{k-1}^n \parallel \le {\varepsilon },\quad k为轮数\\ &若不满足既可以开启下一轮,重复步骤2。若满足,则停止迭代,输出最优解X^*=X_k^n \end{aligned} 1.已知n维函数f(x),任选起始点X0(x1,x2,x3⋅⋅⋅xn)。2.固定x2,x3⋅⋅⋅xn,寻找最优解时的x1,并且更新X0中的x1,以此步骤更新完xn则为一轮。3.在一轮结束后,判断条件∥Xkn−Xk−1n∥≤ε,k为轮数若不满足既可以开启下一轮,重复步骤2。若满足,则停止迭代,输出最优解X∗=Xkn
4.2SMO算法原理
SMO:序列最小优化算法。是一种用于解决支持向量机训练过程中所产生优化问题的算法。笔者认为,该方法也属于坐标轮换法的一种,只不过它每次选择两个坐标。
由2.3可知,SVM的对偶函数如下:
m a x α W ( α ) = ∑ i = 1 n α i − 1 2 ∑ i , j = 1 n y ( i ) y ( j ) α i α j ( x ( i ) ) T x ( j ) s . t : α i ≥ 0 , i = 1 , 2 , ⋅ ⋅ ⋅ n ∑ i = 1 n α i y ( i ) = 0 \begin{aligned} &\underset{\alpha}{max} W(\alpha) =\sum_{i=1}^n \alpha_i-\frac{1}{2}\sum_{i,j=1}^ny^{(i)}y^{(j)}\alpha_{i}\alpha_{j}(x^{(i)})^Tx^{(j)} \\ &s.t: \quad \alpha_i \ge0 ,i=1,2,···n \\ &\qquad \quad \sum_{i=1}^n\alpha_iy^{(i)}=0 \end{aligned} αmaxW(α)=i=1∑nαi−21i,j=1∑ny(i)y(j)αiαj(x(i))Tx(j)s.t:αi≥0,i=1,2,⋅⋅⋅ni=1∑nαiy(i)=0
该函数具有两个约束条件,而坐标轮换法是用于求无约束条件的。
求解步骤如下
1. 类 比 坐 标 轮 换 法 , 每 次 选 取 两 个 变 量 。 先 选 取 α 1 , α 2 , 根 据 约 束 条 件 可 以 得 到 α 1 y ( 1 ) + α 2 y ( 2 ) = − ∑ ( i = 3 ) n α i y ( i ) 2. 由 于 − ∑ ( i = 3 ) n α i y ( i ) 可 以 看 成 常 量 , 用 ζ 代 替 , 得 到 α 1 = ( ζ − α 2 y ( 2 ) ) y ( 1 ) 3. 原 优 化 函 数 可 以 写 为 W ( α 1 , α 2 , α 3 , ⋅ ⋅ ⋅ α n ) = W ( ( ζ − α 2 y ( 2 ) ) y ( 1 ) , α 2 , α 3 , ⋅ ⋅ ⋅ α n ) 4. 因 为 α 3 ⋅ ⋅ ⋅ α n 为 常 数 , 则 W 为 关 于 α 2 的 一 元 二 次 函 数 , 通 过 对 其 求 导 , 既 可 以 求 出 W 的 最 优 解 。 由 于 α 2 存 在 约 束 , 则 存 在 有 上 下 限 的 问 题 , 需 要 对 在 W 取 得 最 优 解 时 的 α 2 加 以 判 断 , 最 终 更 新 α 2 与 α 1 , b 的 值 。 5. 类 比 坐 标 轮 换 法 , 在 一 轮 结 束 后 , 判 断 条 件 ∥ α k n − α k − 1 n ∥ ≤ ε , α = ( α 1 , α 2 , α 3 , ⋅ ⋅ ⋅ α n ) , k 为 轮 数 若 不 满 足 既 可 以 开 启 下 一 轮 , 重 复 步 骤 2 。 若 满 足 , 则 停 止 迭 代 , 输 出 最 优 解 α ∗ = α k n \begin{aligned} &1.类比坐标轮换法,每次选取两个变量。先选取\alpha_1,\alpha_2,根据约束条件可以得到\alpha_1y^{(1)}+\alpha_2y^{(2)} = -\sum_{(i=3)}^n\alpha_iy^{(i)}\\ &2.由于-\sum_{(i=3)}^n\alpha_iy^{(i)}可以看成常量,用\zeta 代替,得到\alpha_1=(\zeta - \alpha_2y^{(2)}) y^{(1)} \\ &3.原优化函数可以写为W(\alpha_1,\alpha_2,\alpha_3,···\alpha_n)=W((\zeta - \alpha_2y^{(2)}) y^{(1)} ,\alpha_2,\alpha_3,···\alpha_n) \\\\ &4.因为\alpha_3···\alpha_n为常数,则W为关于\alpha_2的一元二次函数,通过对其求导,既可以求出W的最优解。\\ &由于\alpha_2存在约束,则存在有上下限的问题,需要对在W取得最优解时的\alpha_2加以判断,最终更新\alpha_2与\alpha_1,b的值。\\\\ &5.类比坐标轮换法,在一轮结束后,判断条件\parallel \alpha_k^n- \alpha_{k-1}^n \parallel \le {\varepsilon },\quad \alpha=(\alpha_1,\alpha_2,\alpha_3,···\alpha_n), \quad k为轮数\\ &若不满足既可以开启下一轮,重复步骤2。若满足,则停止迭代,输出最优解\alpha^*=\alpha_k^n \end{aligned} 1.类比坐标轮换法,每次选取两个变量。先选取α1,α2,根据约束条件可以得到α1y(1)+α2y(2)=−(i=3)∑nαiy(i)2.由于−(i=3)∑nαiy(i)可以看成常量,用ζ代替,得到α1=(ζ−α2y(2))y(1)3.原优化函数可以写为W(α1,α2,α3,⋅⋅⋅αn)=W((ζ−α2y(2))y(1),α2,α3,⋅⋅⋅αn)4.因为α3⋅⋅⋅αn为常数,则W为关于α2的一元二次函数,通过对其求导,既可以求出W的最优解。由于α2存在约束,则存在有上下限的问题,需要对在W取得最优解时的α2加以判断,最终更新α2与α1,b的值。5.类比坐标轮换法,在一轮结束后,判断条件∥αkn−αk−1n∥≤ε,α=(α1,α2,α3,⋅⋅⋅αn),k为轮数若不满足既可以开启下一轮,重复步骤2。若满足,则停止迭代,输出最优解α∗=αkn
α j 的 上 下 限 如 下 , 可 自 行 推 导 : , If y ( i ) ≠ y ( j ) , L = max ( 0 , α j − α i ) , H = min ( C , C + α j − α i ) If y ( i ) = y ( j ) , L = max ( 0 , α i + α j − C ) , H = min ( C , α i + α j ) \alpha_j的上下限如下,可自行推导:\\, \begin{array}{ll} \text { If } y^{(i)} \neq y^{(j)}, & L=\max \left(0, \alpha_{j}-\alpha_{i}\right), \quad H=\min \left(C, C+\alpha_{j}-\alpha_{i}\right) \\ \text { If } y^{(i)}=y^{(j)}, & L=\max \left(0, \alpha_{i}+\alpha_{j}-C\right), \quad H=\min \left(C, \alpha_{i}+\alpha_{j}\right) \end{array} αj的上下限如下,可自行推导:, If y(i)=y(j), If y(i)=y(j),L=max(0,αj−αi),H=min(C,C+αj−αi)L=max(0,αi+αj−C),H=min(C,αi+αj)
而关于SMO的详细原理,可以参考文末链接。
4.3SMO的python实现
import numpy as np
import random as rnd
class SVM():
def __init__(self, max_iter=10000, kernel_type='linear', C=1.0, epsilon=0.001):
self.kernels = {
'linear' : self.kernel_linear,
'quadratic' : self.kernel_quadratic,
'RBF' : self.kernel_RBF
} # 此处定义了两个核函数,可以指定其一
self.max_iter = max_iter # 指定最大迭代次数
self.kernel_type = kernel_type
self.C = C
self.epsilon = epsilon
def fit(self, X, y):
'''
X,y 分别为样本数据和样本标签
'''
n, d = X.shape[0], X.shape[1]
alpha = np.zeros((n))
kernel = self.kernels[self.kernel_type] # 选定核函数
if self.kernel_type == 'RBF':
X=self.normalize(X)
count = 0
while True:
count += 1
alpha_prev = np.copy(alpha)
for j in range(0, n):
# 挑选i,j两向量 生成与j不同,且未被优化的i
i = self.get_rnd_int(j, n-1, j)
x_i, x_j, y_i, y_j = X[i,:], X[j,:], y[i], y[j]
# 计算上下界
k_ij = kernel(x_i, x_i) + kernel(x_j, x_j) - 2 * kernel(x_i, x_j)
if k_ij == 0:
continue
alpha_prime_j, alpha_prime_i = alpha[j], alpha[i]
(L, H) = self.compute_L_H(self.C, alpha_prime_j, alpha_prime_i, y_j, y_i)
# 更新w和b
self.w = self.calc_w(alpha, y, X)
self.b = self.calc_b(X, y, self.w)
# 计算差值E
E_i = self.E(x_i, y_i, self.w, self.b)
E_j = self.E(x_j, y_j, self.w, self.b)
# 更新变量
alpha[j] = alpha_prime_j + float(y_j * (E_i - E_j))/k_ij
alpha[j] = max(alpha[j], L)
alpha[j] = min(alpha[j], H)
alpha[i] = alpha_prime_i + y_i*y_j * (alpha_prime_j - alpha[j])
# 判断是否达到终止条件
diff = np.linalg.norm(alpha - alpha_prev)
if diff < self.epsilon:
break
if count >= self.max_iter:
print("Iteration number exceeded the max of %d iterations" % (self.max_iter))
return
# 更新最终的w,b
self.b = self.calc_b(X, y, self.w)
if self.kernel_type == 'linear':
self.w = self.calc_w(alpha, y, X)
# 返回支持向量。
alpha_idx = np.where(alpha > 0)[0]
support_vectors = X[alpha_idx, :]
return support_vectors
def predict(self, X):
return self.h(X, self.w, self.b)
def calc_b(self, X, y, w):
b_tmp = y - np.dot(w.T, X.T)
return np.mean(b_tmp)
def calc_w(self, alpha, y, X):
return np.dot(X.T, np.multiply(alpha,y))
def normalize(self,X):
for n, i in enumerate(X):
min = np.min(i)
max = np.max(i)
for m, j in enumerate(i):
X[n, m] = (j - min) / (max - min)
return X
# Prediction
def h(self, X, w, b):
return np.sign(np.dot(w.T, X.T) + b).astype(int)
# Prediction error
def E(self, x_k, y_k, w, b):
return self.h(x_k, w, b) - y_k
def compute_L_H(self, C, alpha_prime_j, alpha_prime_i, y_j, y_i):
if(y_i != y_j):
return (max(0, alpha_prime_j - alpha_prime_i), min(C, C - alpha_prime_i + alpha_prime_j))
else:
return (max(0, alpha_prime_i + alpha_prime_j - C), min(C, alpha_prime_i + alpha_prime_j))
def get_rnd_int(self, a,b,z):
i = z
cnt=0
while i == z and cnt<1000:
i = rnd.randint(a,b)
cnt=cnt+1
return i
# Define kernels
def kernel_linear(self, x1, x2):
return np.dot(x1, x2.T)
def kernel_quadratic(self, x1, x2):
return (np.dot(x1, x2.T) ** 2)
def kernel_RBF(self, x1, x2):
sigma=3
return np.exp((-np.linalg.norm(x1-x2,2)/2*sigma**2))
5.文末的话
关于svm算法,大概的原理大概已经描述完。但要追究到细枝末节,还有很多内容需要读者自行去理解,使它能在脑海里自洽。
虽然其中还缺乏了带松弛变量来解决由异常值的情况,不过内核相似,读者感兴趣可以自行去学习。
以下是参考到的资料和视频,其中王木头爱科学的视频讲解的数学原理令人非常通透,贪心学院的课程讲解的SVM原理也很易懂,其中的python代码也是基于课程里面的程序进行的一个改进,还有很多知乎大V的文章,也能让我在山穷水尽处给予我指点:
王木头爱科学:https://space.bilibili.com/504715181
贪心学院:https://tx.greedyai.com/
SMO中求上下限,我觉得他讲的比较详细:https://zhuanlan.zhihu.com/p/433150785
斯坦福大学关于的SMO论文:http://cs229.stanford.edu/materials/smo.pdf