联邦学习之路
参考视频
参考文章
一、概念
1.1什么是联邦学习?
谷歌对于联邦学习的定义是,无需通过中心化的数据,即可训练一个机器学习模型。
联邦学习(FL)是一种机器学习设定,其中许多客户端(例如,移动设备或整个组织)在中央服务器(例如,服务提供商)的协调下共同训练模型,同时保持训练数据的去中心化及分散性。
联邦学习的长期目标:在不暴露数据的情况下分析和学习多个数据拥有者的数据。(目的:解决数据孤岛)
1.2为什么叫“联邦”学习?有什么特点?
因为学习任务是通过由中央服务器协调的参与设备(客户端)的松散联邦来解决的。(联合多个城邦)
不均衡和Non-IID(非独立同分布)的数据;分隔通过大量不可靠的设备,并且是有限的通信带宽,这是作为引入的挑战。
1.3为什么要引入“联邦学习”这个概念?
大量工作试图使用中央服务器在保护隐私的同时从本地数据中学习。目前没有任何一项工作可以直接解决FL定义下的全部挑战。“联邦学习”这个词为这一系列特征,约束和挑战提供了便捷的简写,这些约束和挑战通常在隐私至关重要的机器学习问题中同时出现。
1.4联邦学习的场景与分类?
联邦学习根据不同场景可以分为两大类:“跨设备”和“跨孤岛”。
跨设备:Gboard移动键盘
跨孤岛:医疗数据联邦学习
横向联邦学习(特征对齐):两个数据集的用户特征重叠较多、用户重叠较少,取出两方用户特征相同而用户不完全相同的数据进行训练。
例如跨国公司的客户不同但是年龄性别这些特征是相同的
纵向联邦学习(样本对齐):两个数据集的用户重叠较多、用户特征重叠较少,取出两方用户相同而用户特征不完全相同的数据进行训练。
联邦迁移学习:两个数据集的用户和用户特征都重叠较少,需要横向联邦和纵向联邦的组合。
1.5跨数据和跨孤岛的主要区别?

1.6联邦学习的步骤?

上述这种模型训练的方式有一个基本的要求:
本地模型-Local Model和云端模型- Global Model的特征必须一致:因为我们是汇总了无数本地模型的参数,基于这些参数对云端模型进行更新。如果这些模型的特征不一致,那么参数之间也没有任何参考意义。比如一个预测身高的模型,本地模型用“性别+年龄”特征,云端模型用“体重+肤色”特征,本地模型训练得到的模型参数上传到云端,云端根本毫无参考价值。
所以上述这种联邦学习我们又叫作 “横向联邦学习” ,模型之间使用的特征一致,只是使用的样本数据不一样。比如说下图本地模型使用的用户特征都是一样的,但是每个本地模型只能使用本地这一个用户的数据,无法使用其他用户的数据进行训练。
联邦学习的过程分为自治和联合两部分。
自治的部分:首先,两个或两个以上的的参与方们在各自终端安装初始化的模型,每个参与方拥有相同的模型,
其次参与方们可以使用当地的数据训练模型。由于参与方们拥有不同的数据,最终终端所训练的模型也拥有不同的模型参数。
联合的部分:接着不同的模型参数将同时上传到云端,云端将完成模型参数的聚合(FedAVG加权平均参数)与更新,
然后将更新好的参数返回到参与方的终端,各个终端开始下一次的迭代。
最后以上的程序会一直重复,直到整个训练过程的收敛。
1.7联邦学习和一般分布式机器学习的主要区别?
| 分布式训练 | 联邦学习 |
|---|---|
| 数据分布 | 集中存储不固定,可以任意打乱、平衡地分配给所有客户端 |
| 节点数量 | 1~1000 |
| 节点状态 | 所有节点稳定运行 |
1.8什么是Non-IID非独立同分布数据?
参考文章
1.8.1不同客户端数据分布不同
( x , y ) ∼ P i ( x , y ) ≠ P j (x,y) \sim \mathcal{P}_i(x,y)\not= P_j (x,y)∼Pi(x,y)=Pj
①特征分布倾斜 Feature distribution skew(convariate shift): P ( y ∣ x ) \mathcal{P}(y|x) P(y∣x)相同, P i ( x ) \mathcal{P}_i(x) Pi(x) 不同;
举例:在数字手写识别任务上,不同的人可以看作不同的客户端,小明喜欢写豪放版的"3"(特征x),而小红喜欢写苗条版的"3"(特征x),那么在小明这个客户端上的分布P i ( x ) {P}_i(x)P i(x)中豪放版的"3"概率较高,而小红则相反(也就是说不同客户端 P i ( x ) \mathcal{P}_i(x)P i (x)分布不相同)。但是呢,当 x = 豪放版"3"时,不同客户端用这个特征x预测出来的标签y=3的概率是相近的(也就是说P ( y ∣ x ) {P}(y|x)P(y∣x)分布相同)。
②标签分布倾斜Label distribution skew (prior probability shift):
P ( x ∣ y ) \mathcal{P}(x|y) P(x∣y)相同, P ( y ) \mathcal{P}(y) P(y)不同;
举例:
以MNIST数据集为例,客户端1有90%的数字1,10%的其他数字,客户端2有95%数字7,5%的其他数字…,这种情况就是不同客户端 P i ( y ) {P}_i(y)P i (y)分布不相同。而当y给定时,比如y等于7,那即使是不同的客户端,对应的特征x大概率是7的形状,所以说P ( x ∣ y ) \mathcal{P}(x|y)P(x∣y)分布相同
③标签相同,特征不同Same label, different features (concept shift):
P ( y ) \mathcal{P}(y) P(y)相同, P ( x ∣ y ) \mathcal{P}(x|y) P(x∣y)不同;
举例:P(x∣y)分布不相同可以这样去理解:同样是房子(y相同),欧洲(客户端1)的房子和中国(客户端2)的房子对应的形态是不同的(x不同)
④特征相同,标签不同Same features, different label (concept shift):
P i ( x ) \mathcal{P}_i(x) Pi(x)相同, P ( y ∣ x ) \mathcal{P}(y|x) P(y∣x)不同;
举例:P(y∣x)分布不一致,举例来说,不同读者(客户端)对于同一条新闻事件(x)持有不同的看法(y)
1.8.2数量不平衡
这种类型最简单,就是指不同客户端的训练集的数量差异很大。
客户端 i ii 有100个样本,而客户端 j jj 有2万个样本
1.9处理Non-IID数据有什么策略?
①修改现有的算法
②创建一个可以全局共享的小数据集
③不同客户端提供不同的模型(Non-IID变成一种特性)
通过特征个性化、多任务学习、本地微调和元学习
1.10联邦学习有什么数据集?
EMNIST数据集由671,585个数字图像和大小写英文字符(62个类)组成。 联邦版本将数据集拆分为3,400个不平衡客户端,这些客户端由数字/字符的原始编写者索引。 非IID分布来自每个人独特的写作风格。
Stackoverflow数据集由来自Stack Overflow的问答组成,并带有时间戳,分数等元数据。训练数据集拥有342,477多个唯一用户和135,818,730个示例。请注意,时间戳信息可能有助于模拟传入数据的模式。
Shakespeare是从The Complete Works of William Shakespeare获得的语言建模数据集。 它由715个字符组成,其连续行是客户端数据集中的示例。训练集有16,068个示例,测试集有2,356个示例。
Leafproject 提供了对EMNIST和Shakespeare的预处理,它还提供了sentiment140和celebA数据集的联邦版本。这些数据集具有足够的客户端,可以用于模拟跨设备FL场景,但是对于规模特别重要的问题,它们可能太小。在这方面,Stackoverflow提供了跨设备FL问题的最现实示例。
参考文章
二、联邦学习经典算法:
1、FedAvg
步骤:
在FedAvg中,每次选中K个客户端,在本地模型训练过程中具有相同的学习率和迭代次数E。本地SGD更新后,将w发送给服务器端,服务器对w进行平均更新全局模型。

存在问题:
本地更新次数过多后,因为每个客户端数据的异构性,产生的w与上一次服务器端全局模型w偏离过大,影响全局模型的收敛性。
2、FedProx
通过加入 proximal term,缓解了数据异构性,提高了全局模型收敛的稳定性,主要解决了设备之间non-IID问题
步骤:
在FedAvg基础上,prox在本地更新时加了一个正则化项,减去的是上一轮的全局模型,目的是使得本地更新不会过分偏离global model。(缓和Non-IId)
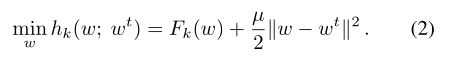
当μ=0,local solver选择SGD,不同设备在每轮global update都使用相同的local epoch,FedProx就变成了FedAvg,所以实际上,FedProx是FedAvg的一种泛化形式。
3、FedPNS
算法建立在数据异构的基础上,设计了一个选择性地让节点参与模型聚合的概率模型。通过排除不利于全局收敛的节点,提高模型收敛速度和预测精度。
摘要
联邦学习(FL)是一种分布式学习范式,它允许大量资源有限的节点在没有数据共享的情况下协作训练模型。非独立的和同分布的(Non-IID)数据样本造成了全局目标和局部目标之间的差异,使得FL模型收敛缓慢。本文提出了更好的最优聚合算法,该算法通过检查局部梯度与全局梯度的关系,识别和排除不利于全局收敛地局部更新,找到每个全局回合中参与节点局部更新的最优子集。最终提出了一个概率节点选择框架(FedPNS),根据最优聚合的输出动态地改变每个节点的选择概率。FedPNS可以优先选择能够促进更快的模型收敛速度的节点参与模型聚合。从理论上分析了FedPNS比常用的FedAvg算法的具有更快的收敛速度。并通过实验证明了其有效性。