一篇文章搞懂 HBase 的 MSLAB
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
引子
HBase 中,MemStore 从本质上来看就是一块缓存,可以称为写缓存。
众所周知在 Java 系统中,大内存系统总会面临 GC 问题,MemStore 本身会占用大量内存,因此 GC 的问题不可避免。
堆内存足够大的时候发生 Full GC 的停留时间可能长达好几分钟,解决这个问题不能完全靠 JVM 的 GC 回收策略,最好的解决方案是从应用本身入手,自己来管好自己的内存空间。
随着硬件科技的进步,现在的服务器内存可以达到 32GB 、 64GB 甚至 100GB ,人们发现就算是使用 CMS 策略来进行垃圾回收( GC ),依然会触发 Full GC 。
但是在 2GB 、 4GB 的时代,一次 Full GC 最多也就几十秒,不会超过一分钟;但是随着内存的加大, Full GC 的时间逐渐变长。
增加的速率是 8~10 秒 / G 。
采用了 CMS 后还是发生 Full GC 的原因
- 同步模式失败:在 CMS 还没有把垃圾收集完的时候空间还没有完全释放,而这个时候如果新生代的对象过快地转化为老生代的对象时发现老生代的可用空间不够了,此时收集器会停止并发收集过程,转为单线程的 STW ( Stop The World )暂停,这就又回到了 Full GC 的过程了。不过这个过程可以通过设置
-XX:CMSInitiatingOccupancyFraction=N来缓解。N 代表了当 JVM 启动垃圾回收时的堆内存占用百分比。你设置的越小, JVM 越早启动垃圾回收进程,一般设置为 70 。 - 由于碎片化造成的失败:当前要从新生代提升到老年代的对象比老年代的所有可以使用的连续的内存空间都大。比如你当前的老年代里面有 500MB 的空间是可以用的,但是都是 1KB 大小的碎片空间,现在有一个 2KB 的对象要提升为老年代却发现没有一个空间可以插入。这时也会触发 STW 暂停,进行 Full GC 。这个问题无论你把
-XX:CMSInitiatingOccupancyFraction=N调多小都是无法解决的,因为 CMS 只做回收不做合并,所以只要你的 RegionServer 启动得够久一定会遇上 Full GC 。
为什么会出现碎片内存空间?
我们知道 Memstore 是会定期刷写成为一个 HFile 的,在刷写的同时这个 Memstore 所占用的内存空间就会被标记为待回收,一旦被回收了,这部分内存就可以再次被使用,但是由于 JVM 分配对象都是按顺序分配下去的,所以你的内存空间使用了一段时间后的情况如下图所示。
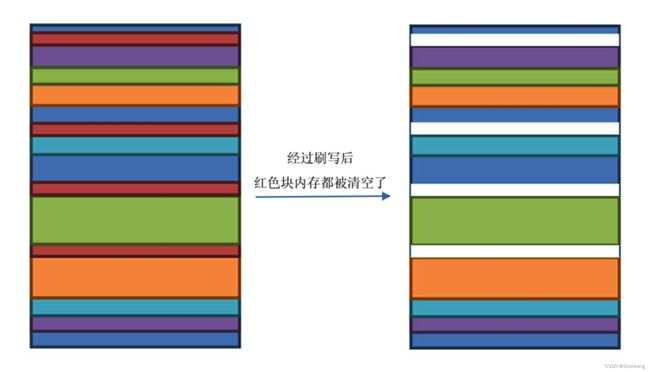
假设红色块占用的内存大小都是 1KB ,此时有一个 2KB 大小的对象从新生代升级到老生代,但是此时 JVM 已经找不到连续的 2KB 内存空间去放这个新对象了,如图下所示。
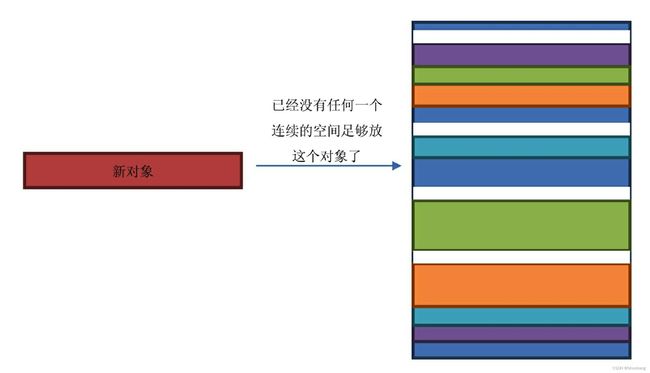
JVM 也没有办法,为了不让情况继续地恶化下去,只好停止接收一切请求,然后启用一个单独的进程来进行内存空间的重新排列。
这个排列的时间随着内存空间的增大而增大,当内存足够大的时候,暂停的时间足以让 ZooKeeper 认为我们的 RegionServer 已死。
其实 JVM 为了避免这个问题有一个基于线程的解决方案,叫 TLAB ( Thread-Local Allocation Buffer )。
可以参考我的这篇博客——new关键字在虚拟机中是怎样的一个过程?JVM构造对象的步骤都有哪些?
当你使用 TLAB 的时候,每一个线程都会分配一个固定大小的内存空间,专门给这个线程使用,当线程用完这个空间后再新申请的空间还是这么大,这样下来就不会出现。
特别小的碎片空间,基本所有的对象都可以有地方放。缺点就是无论你的线程里面有没有对象都需要占用这么大的内存,其中有很大一部分空间是闲置的,内存空间利用率会降低。不过能避免 Full GC,这些都是值得的。
但是 HBase 不能直接使用这个方案,因为在 HBase 中多个 Region 是被一个线程管理的,多个 Memstore 占用的空间还是无法合理地分开。
MSLAB
于是 HBase 就自己实现了一套以 Memstore 为最小单元的内存管理机制,称为 MSLAB ( Memstore-Local Allocation Buffers )。
这套机制完全沿袭了 TLAB 的实现思路,只不过内存空间是由 Memstore 来分配的。
MSLAB 的具体实现如下
- 引入 chunk 的概念,所谓的 chunk 就是一块内存,大小默认为 2MB 。
- RegionServer 中维护着一个全局的
MemStoreChunkPool实例,从名字很容看出,是一个 chunk 池。 - 每个 MemStore 实例里面有一个
MemStoreLAB实例。 - 当 MemStore 接收到
KeyValue数据的时候先从 ChunkPool 中申请一个 chunk ,然后放到这个 chunk 里面。 - 如果这个 chunk 放满了,就新申请一个 chunk 。
- 如果 MemStore 因为刷写而释放内存,则按 chunk 来清空内存。
由此可以看出堆内存被 chunk 区分为规则的空间,这样就消除了小碎片引起的无法插入数据问题,但是会降低内存利用率,因为就算你的 chunk 里面只放 1KB 的数据,这个 chunk 也要占 2MB 的大小。
不过,为了不发生 Full GC ,这些都可以忍。
跟 MSLAB 相关的参数是
hbase.hregion.memstore.mslab.enabled:设置为 true ,即打开 MSLAB ,默认为 true 。hbase.hregion.memstore.mslab.chunksize:每个chunk的大小,默认为 2048*1024 即 2MB。hbase.hregion.memstore.mslab.max.allocation:能放入 chunk 的最大单元格大小,默认为 256KB。hbase.hregion.memstore.chunkpool.maxsize:在整个 memstore 可以占用的堆内存中,chunkPool 占用的比例。该值为一个百分比,取值范围为 0.0~1.0。默认值为 0.0。hbase.hregion.memstore.chunkpool.initialsize:RegionServer 启动的时候可以预分配一些空的 chunk 出来放到chunkPool 里面待使用。该值就代表了预分配的 chunk 占总的chunkPool 的比例。该值为一个百分比,取值范围为 0.0~1.0,默认值为 0.0。
MSLAB 对于降低 Full GC 真的有用吗?
为了验证 MSLAB 对于降低 Fu1GC 的有效性,官方做了一个侧试实验。
这个实验主要查看在相同写入负载下开启 MSLAB 前后 RegionServer 内存中最大内存碎片的大小。
在 RegionServer JVM 启动参数中加上 -xx:PrintFLSStatistics=1 ,可以打印每次 GC 前后内存碎片的统计信息,统计信息主要包括 3 个维度: FreeSpace 、 MaxChunkSize 和 NumChunks。
FreeSpace 表示老年代当前空闲的总内存容量, MaxChunkSize 表示老年代中最大的内存碎片所占的内存容量大小, NumChunks 表示老年代中总的内存碎片数。
该实验重点关注 MaxChunkSize 这个维度信息。
测试结果如下面两图所示,上图为未开启 MSLAB 时统计的 MaxChunkSize 变化曲线,下图为开启 MSLAB 后统计的 MaxChunkSize 变化曲线。
由测试结果可以看出,未开启 MSLAB 功能时内存碎片会大量出现,并导致频繁的 Full GC (图中曲线每次出现波谷到波峰的剧变实际上就是一次 Full GC ,因为 Full GC 次数会重新整理内存碎片使得 MaxChunkSize 重新变大);而优化后虽然依然会产生大量碎片,但是最大碎片大小一直会维持在 1e + 08 左右,并没有出现频繁的 Full GC。
MemStore Chunk Pool
经过 MSLAB 优化之后,系统因为 MemStore 内存碎片触发的 Full GC 次数会明显降低。
然而这样的内存管理模式并不完美,还存在一些“小问题”。
比如一旦一个 Chunk 写满之后,系统会重新申请一个新的 Chunk ,新建 Chunk 对象会在 JVM 新生代申请新内存,如果申请比较频繁会导致 JVM 新生代 Eden 区满掉,触发 YGC。
试想如果这些 Chunk 能够被循环利用,系统就不需要申请新的 Chunk ,这样就会使得 YGC 频率降低,晋升到老年代的 Chunk 就会减少, CMS GC 发生的频率也会降低。
这就是 MemStore Chunk Pool 的核心思想,具体实现步骤如下:
- 系统创建一个 ChunkPool 来管理所有未被引用的 Chunk ,这些 Chunk 就不会再被 JVM 当作垃圾回收。
- 如果一个 Chunk 没有再被引用,将其放入 ChunkPool 。
- 如果当前 ChunkPool 已经达到了容量最大值,就不会再接纳新的 Chunk
- 如果需要申请新的 Chunk 来存储 KeyValue ,首先从 ChunkPool 中获取,如果能够获取得到就重复利用,否则就重新申请一个新的 Chunk。
G1 GC和 MSLAB可以一起用吗?
G1 GC 请参考我的博客——G1 GC是什么?
可以,他们之间并没有冲突。
你可能会觉得 G1 GC 跟 MSLAB 的实现思路非常接近,那为什么还要发明 MSLAB 策略呢?
因为 G1 GC 是 MSLAB 发明后才出现的策略。