一次ddd重构记录
父文章 [理论]领域驱动设计 DDD 是啥,cqrs是啥_个人渣记录仅为自己搜索用的博客-CSDN博客
其他文章 : 重构,可扩展设计可操作方案。_个人渣记录仅为自己搜索用的博客-CSDN博客
子文章 如何写可维护的代码 - 万物ddd ddd primitive . 封装,对象来实现可维护代码._个人渣记录仅为自己搜索用的博客-CSDN博客
原来代码存在的问题
1. 多个类似业务多套模板.
中间稍有不同. 不同的分支,依赖不同的策略点配置.
2. 没有领域设计.
2.1 表即领域类. 一个表承载了所有业务场景的字段. 没有封装,接口化.
2.1.2 ext put(key,value) get(key) 对外暴露. 对字段的生命周期查看非常难.
2.2 如2.1所述, 没有类层次设计. 领域设计为零.
3. type混乱. 几个大type走天下, 用在各种地方if else . 导致烟囱现象明显.
4. 为了复用而复用, 几个毫无业务关联的类直接抽出了父类, 导致想查看一个产品的某个uid的设置,看到的都是所有的产品set. 抽出父类也行,但需要对产品级隔离. 采用组合的组合类.get方式. 平铺或者get封装子类.
5. 没有对流程进行隔离. 只看一个流程的来龙去脉.
6. 过渡封装/接口. 当多个业务的status状态都被封装在一起后. 不仅get封装,set也封装了,封装成模板代码,状态机代码. 代码阅读难度就极大增加.特别是 业务,订单,操作都复用同一个封装类/接口后.彻底不可阅读了. 全通过配置来看理解代码
重构技巧
1. 先把原来代码原模原样拷贝一份. 然后把编译异常的地方给改掉/挪走,直到没有编译报错为止.
而不是对照着原来代码重新写.这样很容易遗留一些逻辑.
被挑战的点?
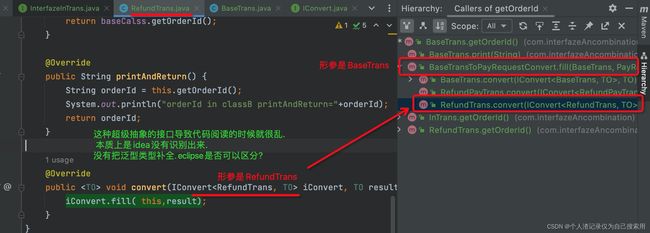
为什么ExchangeTrans里为啥一定要有account的领域类? (1对多的属性设计)
因为直接从Order里可以直接拿到. 原因是: 1.可以转换为DO,持久化. order里面两次退款后,就会覆盖掉. 1对多.
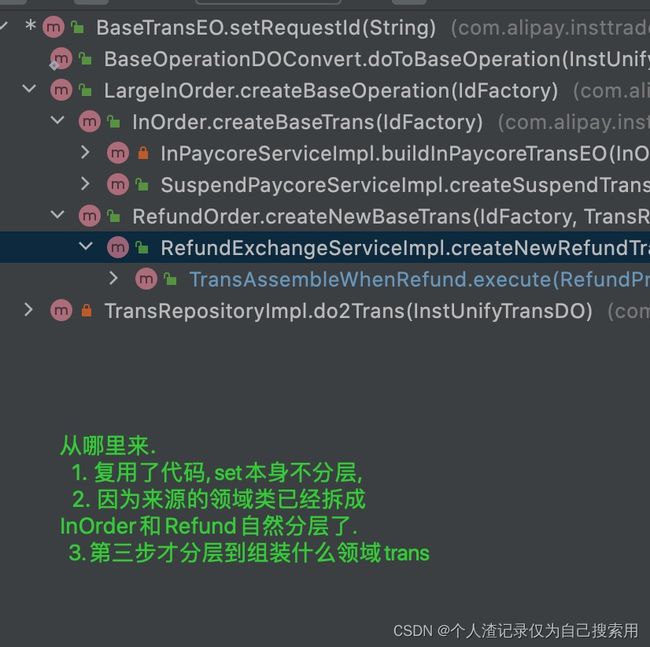
新老模式对比.
| 老 | 新 |
| 写
|
 |
| 读
|
复用了. 1. 第一层不再是In/refund,流程. 2. 第二层才是 领域组合分层. ( 如果不用组合,只用继承,就会拉平. 不分类了. ) |
| 老 命名可以传入少量的参数,非得传入整个领域类. 父类复用 |
方法的传参不再是父类 |
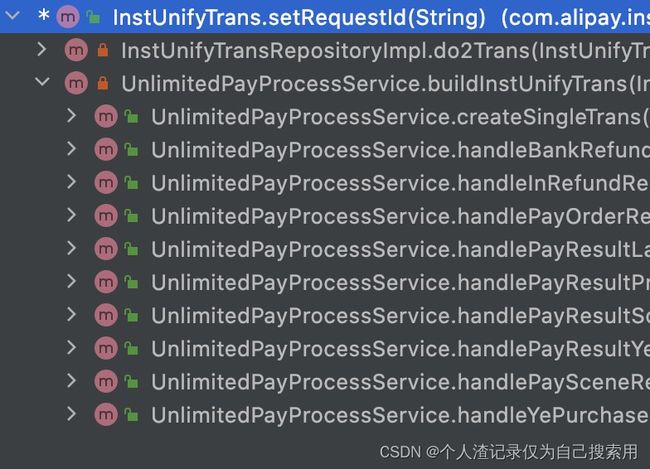
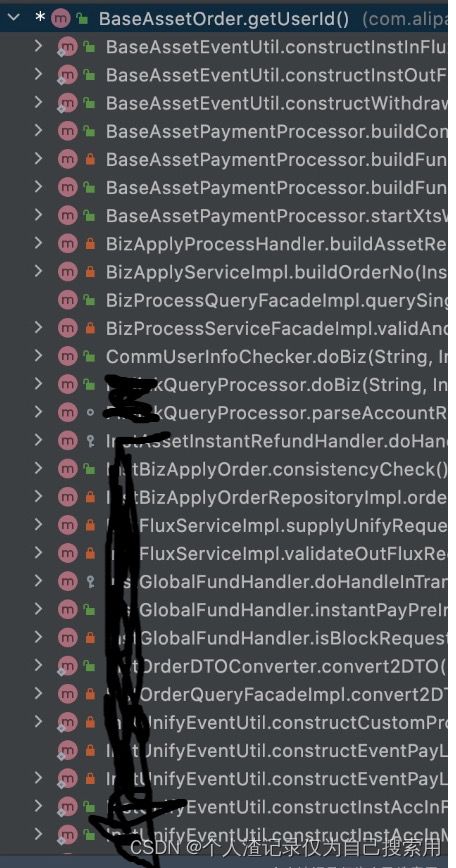
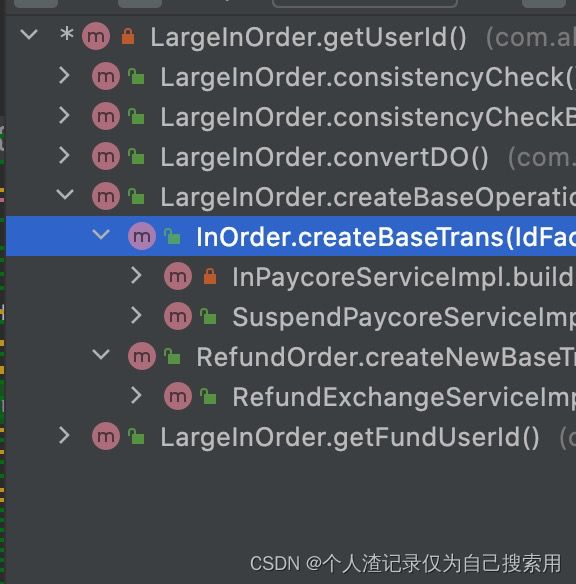
两种模式对比. 分层or组合
| 复用性好,可读性差. 既然分层组合了. 那就get到底. 少复用. 特别是不同的流程下的分层. |
public boolean isSuccessStatus() { return baseOrder.isSuccessStatus()); } |
复用性差 |
public boolean isSuccessStatus() {
return
InstUnifyOrderStatusEnum.
SUCCESS.
equals(getStatus());
}
private InstUnifyOrderStatusEnum getStatus() { return largeInOrder.getStatus(); }
|
遇到的难题和解法
组织架构和对象切换
代码不要频繁的领域对象切换. 除非有人来维护. 不然就从基类里衍生 base.get();
组合和继承
组合能够分层. 继承不能.
getBase()慎用. 仅用于复用代码. 采用接口, new 一个接口出来.复用.
1.流程封装类 里的所有属性全都在放在组合基类里.
1.1 基类封装成各个子类后, 子类暴露出get, 流程类get后需要懒惰new 封装成流程子类. ( 或者利用六边形架构 + 包可见 去实现封装. 再加些convert类) 六变形 适配层要依赖领域类+外部jar. 这样才能互相转换. 另外适配层返回给领域层的结果是领域类 含封装方法 . 而不是传统的外部VO
2. 业务分类子类. 字段各归各的.
3. 树状类需要搭配一个Factory和IService. IService里 createEO和 doSomeThing放一起. 这种接口才有了意义. createEo形参是外部request. doSomeThing形参是领域类.
3.1 领域类里所有属性都要持久化.如果有些字段不需要持久化, 那就需要通过request或者Context传递. doSomeThing的形参就是领域类 + 特定的request + 特定的processContext
4. 考虑到定时任务的需要. 所有的外部request信息都需要持久化,变成领域类里属性. 再加上动态的策略点组装成完整的领域类. 再继续执行下一个任务.
所以这里有个问题. 哪些字段是新增的,新改变的.需要专门采集收集. 这就是orm框架的作用.
5. 一个好的策略点平台应该面向产品+流程的, 且具备 同领域实体(组件)不同实例的能力. 有限或者是List结构. 组件即领域类. 一个产品切分流程, 基于流程在切分读动作,写动作. 然后梳理 领域实体. 再考虑哪些有持久化,哪些不用持久化. 哪些1对多等等
6. 复用性 可维护性 可读性
2019-03-14 面向未来编程:如何平衡代码的可读性和扩展性 - 腾讯云开发者社区-腾讯云
可读性, 可维护性是矛盾的. 体现在 1. 基类复用,导致下游系统问题. 2. 接口化后, 需要多点记1下才能看到代码.
复用性: 代码重复度低.
可维护性: 面向写, 一个bug改一个地方. 增加功能,只需要改一个地方
可读性: 想去理解一个领域字段的来龙去脉时很方便. 只关注自己的业务域即可.
在传统的模式中 复用性和可读性是相悖的, 详见下面的例子.
例子
[下游系统问题] 分布式场景底层系统的代码接口哪些是我这个系统用的.
类层级 InOrder ,refundOrder,SuspendOrder都依赖 ILargeOrder. 内部包含了所有流程的字段.
按流程 .
- InOrder
- refundOrder
- SuspendOrder
-xxxService.xxMethod(ILargeOrder order)
-xxxService.xxMethod2(ILargeOrder order)
-xxxService2.xxMethod1(ILargeOrder order)
-xxxService2.xxMethod1(ILargeOrder order)
-xxxService2.xxMethod1(ILargeOrder order)
按字段切分, 类层级RefundOperation, refundOperation都依赖了BaseOperation 内部包含了所有流程的字段.
- RefundOperation
- refundOperation
- SuspendOperation
-xxxService.xxMethod(BaseOperation order)
-xxxService.xxMethod2(BaseOperation order)
-xxxService2.xxMethod1(BaseOperation order)
-xxxService2.xxMethod1(BaseOperation order)
-xxxService2.xxMethod1(BaseOperation order)
解法
方法1: 每个子领域类,需要get出来转换成独立的BaseOperation(用子类的get来set新的BaseOperation). 然后最终利用这个BaseOperation进行复用. 然后进行unmodify封装. 缺点是, 如果需要用到新的字段,需要手动set,get.
方法2: 每次newBaseOperation接口,缺点是每次新增字段的时候. 需要改动N个匿名内部类.
方法3: 直接暴露出去, 然后注意使用. 如果没有复用的地方,就不要使用该接口.
7. 因为都是你维护,所以底层需要有一个全局的领域类. 面向流程拆分的可以. 但是面向字段拆分的不可以.
这样会导致多一层. 例如 baseOperation, PayInfo 都依赖最终 Operation . 然后 PayInOperation依赖baseOperation,PayInfo.
8 一个领域体如果字段很多以后. 如何拆?
根据每个字段的生命周期来拆分. 抽取后可能就是完全独立的领域了. 限于1:1 . 1:多这种,很容易就拆分出来.
属性
属性的封装和组合
拉平组合
废弃的模式
f
好几层的话就拉平. 这样方便阅读点.
方法2的话,复用性就很低了. 不推荐.
属性的两种get
1. 转换成可服用的bean
2.