云原生下,如何实现高可用的MySQL?
云时代的到来,无论传统行业还是互联网行业,业务越来越多样,迭代速度越来越快,使得整体数据量大幅提升。
近两年,随着 Docker + Kubernetes 等技术的兴起,大家都将业务往容器化迁移,团队的技术也在往云原生方向演进。早期的 Kubernetes 着重解决 Stateless 和 Share Nothing 的应用部署场景,然而在如今愈发复杂的应用场景中经常会遇到有状态保存的需求。
从 Kubernetes 1.9 开始,针对有状态服务的资源类型 Statefulset 进入 GA,而且 Kubernetes 1.14 版本 Local Volume、CSI 等存储功能也进入 GA 阶段,Kubernetes 对有状态服务的支持得到全面加强,这使得很多数据存储型基础中间件往 Kubernetes 迁移成为可能。
MySQL 作为当前比较受欢迎的开源关系型数据库(RDS),集可靠、易用、功能丰富、适用范围广等特点于一身,使其成为关系型数据库的主要选择。虽然备受关注,但 MySQL 在云原生浪潮中却也面临着诸多挑战。如何用 Cloud Native 的设计原则,通过沙箱隔离、计算和数据的完全分离,实现低成本、可扩展、高可用的 Cloud RDS 方案?
本文介绍一种云原生分布式 MySQL 高可用数据库方案(下称“SlightShift MySQL 高可用方案”),并对云原生场景下传统数据库的发展趋势做简要分析。

一 需求&挑战
在考虑云原生场景下的 MySQL 高可用架构时,主要有如下几个方面的挑战:
- 故障转移:主库发生宕机时,集群能够自动选主并快速转移故障,且转移前后数据一致。
- 敏捷弹性伸缩:基于副本的弹性横向扩展,扩缩容过程不中断业务访问。
- 数据安全性:数据定时冷备/实时热备,以便故障恢复和数据迁移。
- 数据强一致性:用作备份/只读副本的Slave节点数据应该和主节点数据保持实时或半实时一致。
二 目标&关键考虑点
SlightShift MySQL 高可用方案要达到的目标:
- SLA保障:一年内可接受最高 52.56 分钟服务不可用(99.99%)。
- 故障转移:主库出现异常时主从切换耗时 < 2min。
- 弹性扩展:从库理论可无限扩展,扩展从库耗时 < 2min。
- 冷备恢复:MySQL集群出现不可恢复性问题时,从冷备恢复耗时 < 10min。
除以上目标外,在技术架构设计时还需重点考虑以下关键点:
- 高可用
- 应用接入成本
- 资源占用量
- 可扩展性
- 可维护性
三 架构设计
该 MySQL 高可用方案使用一主多从的复制结构,主从数据复制采用半同步复制,保证了数据一致性和读写效率,理论上从库可无限扩展。

在数据引擎上层添加了仲裁器,使用 Raft 分布式一致性算法实现自动化选主和故障切换。
路由层使用 ProxySQL 作为 SQL 请求代理,能够实现读写分离、负载均衡和动态配置探测。
监控告警方面,采用 Prometheus-Operator 方案实现整个 MySQL 高可用系统的资源监控告警。
运维管控方面,引入 Kubernetes Operator 的管控模型来实现 DB-Operator,能够做到声明式配置、集群状态管理以及On Demand(按需创建)。另外,可以在 MySQL 控制台上进行 MySQL 的基础运维,例如:数据库管理、表管理、SQL查询,索引变更、配置变更、数据备份&恢复等。
四 关键技术
状态持久化
容器技术诞生后,大家很快发现用它来封装“无状态应用”(Stateless Application)非常好用。但如果想要用容器运行“有状态应用”,其困难程度就会直线上升。
对于 MySQL 等存储型分布式应用,它的多个实例之间往往有依赖关系,比如:主从关系、主备关系。各个实例往往都会在本地磁盘上保存一份数据,当实例被杀掉,即便重建出来,实例与数据之间的对应关系也已经丢失,从而导致应用失败。
这种实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,被称为“有状态应用”(Stateful Application)。
Kubernetes 集群中使用节点本地存储资源的方式有 emptyDir、hostPath、Local PV 等几种方式。其中,emptyDir 无法持久化数据,hostPath 方式需要手动管理卷的生命周期,运维压力大。
因此在MySQL场景中,出于性能和运维成本考虑需要使用本地存储,Local PV 是目前为止唯一的选择。
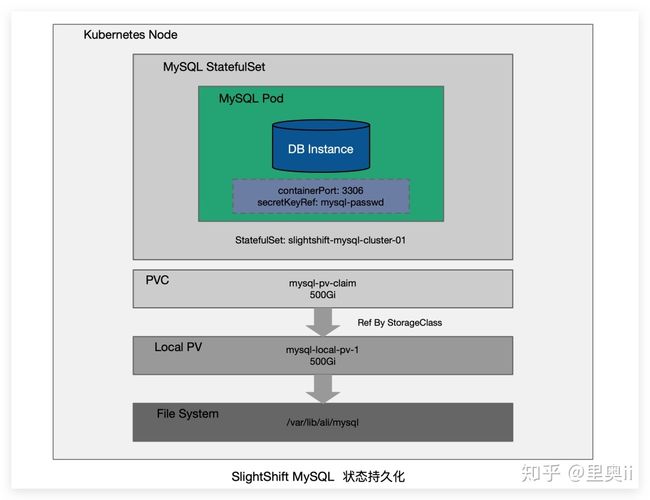
Local PV 利用机器上的磁盘来存放业务需要持久化的数据,和远端存储类似,Pod 的数据和生命周期是互相独立的,即使业务 Pod 被删除,数据也不会丢失。
同时,和远端存储相比,本地存储可以避免网络 IO 开销,拥有更高的读写性能,所以分布式文件系统和分布式数据库这类对 IO 要求很高的应用非常适合本地存储。
不同于其他类型的存储,Local PV 本地存储强依赖于节点。换言之,在调度 Pod 的时候还要考虑到这些 Local PV 对容量和拓扑域的要求。
MySQL 在使用 Local PV 时,主要用到两个特性:延迟绑定机制和 volume topology-aware scheduling。延迟绑定机制可以让 PVC 的绑定推迟到有 MySQL Pod 使用它并且完成调度后,而 volume topology-aware scheduling 则可以让 Kubernetes 的调度器知道卷的拓扑约束,也就是这个存储卷只能在特定的区域或节点上使用(访问),让调度器在调度 Pod 的时候必须考虑这一限制条件。
另外,MySQL 使用的 Local PV 还需通过 nodeAffinity 将 Pod 调度到正确的 Node 上。
下面展示了 MySQL 使用 Local PV 的简单配置示例:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
creationTimestamp: null
name: local-storage
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Delete
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
pv.kubernetes.io/bound-by-controller: "yes"
creationTimestamp: null
labels:
app: slightshift-mysql
mysql-node: "true"
name: data-slightshift-mysql-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: local-volume-storage
volumeName: mysqlha-local-pv-0
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
helm.sh/hook: pre-install,pre-upgrade
helm.sh/resource-policy: keep
volume.alpha.kubernetes.io/node-affinity: '{ "requiredDuringSchedulingIgnoredDuringExecution":
{ "nodeSelectorTerms": [ { "matchExpressions": [ { "key": "kubernetes.io/hostname",
"operator": "In", "values": ["yz2-worker004"] } ]} ]} }'
labels:
pv-label: slightshift-mysql-data-pv
type: local
name: slightshift-mysql-data-pv-0
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 500Gi
local:
path: /var/lib/ali/mysql
persistentVolumeReclaimPolicy: Retain
storageClassName: pxc-mysql-data以上是 Local PV 的基础用法,而 MySQL 还需考虑节点的弹性伸缩,这就要求底层存储也能够随着 MySQL 实例伸缩来动态配置。这里提出两种解决方案:
- 在 Kubernetes 集群中引入 LVM Manager,以 DaemonSet 形式运行,负责管理每个节点上的磁盘,汇报节点磁盘容量和剩余容量、动态创建 PV 等;再引入 local storage scheduler 调度模块,负责为使用本地存储的 Pod 选择合适(有足够容量)的节点。
- 使用开源方案 OpenEBS:iSCSI 提供底层存储功能,OpenEBS 管理 iSCSI(目前只支持PV的 ReadWriteOnce 访问模式)。
自动化选主
SlightShift MySQL 高可用架构基于 Raft 强一致协议实现分布式 MySQL 自动化选主。
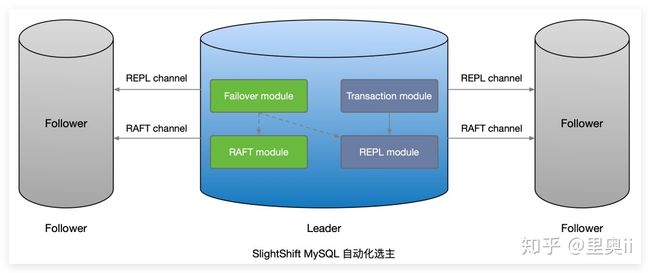
Raft 使用心跳来触发选主,当 MySQL Server 启动时状态是 follower。当 server 从 leader 或者 candidate 接收到合法的RPC时,它会保持在 follower 状态,leader 会发送周期性的心跳来表明自己是 leader。
当一个 follower 在 election timeout 时间内没有接收到通信,那么它会开始选主。
选主的步骤如下:
- 增加 current term。
- 转成 candidate 状态。
- 选自己为主,然后把选主RPC并行地发送给其他的 server。
- candidate 状态会继续保持,直到下述三种情况出现。
candidate 会在下述三种情况下退出:
- server 本身成为 leader。
- 其他的 server 选为 leader。
- 一段时间后,没有 server 成为 leader。
故障转移
在正常运行的主从复制环境中,故障转移(Failover)模块会监听集群状态,当 Master 发生故障时会自动触发故障转移。
故障转移的第一步是自动化选主,自动化选主的逻辑在上面已介绍过;其次是数据一致性保障,需最大化保证 Dead Master的 数据被同步到 New Master。

在将 Master 切换到 New Master 之前,部分 slave 可能还未接收到最新的 relay log events,故障转移模块也会从最新的 slave 自动识别差异的 relay log events,并 apply 差异的 event 到其他 slaves,以此保证所有 slave 的数据都是一致的。
关于代理层,ProxySQL 会实时探测 MySQL 实例的可读写配置,当 MySQL 实例的可读写配置发生变化时,ProxySQL 会自动调整MySQL 实例的读写分组配置,最终保证在 Failover 之后读写分离能正确运行。
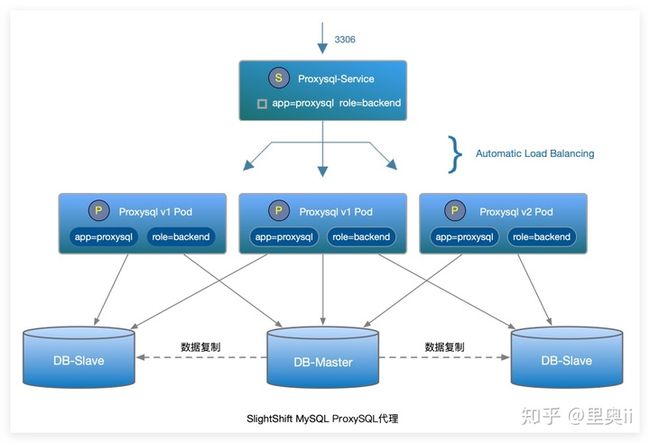
SlightShift MySQL 自动故障转移的步骤如下:
- HA-Manager 侦测到 Master Server 连接异常,启动 Failover。
- 尝试关闭 Dead Master 以避免脑裂(此步骤可选)。
- 获取最新数据 slave 的 end_log_pos,并从 Dead Master 同步 bin-log,最终保证所有 slave 的 end_log_pos 一致。
- 使用 raft 分布式算法选举 New Master。
- 将 Master 切换到 New Master。
- 回调 ProxySQL 代码服务,剔除 Dead Master 配置。
- ProxySQL 网关检测到各个 MySQL 实例的可读写配置变化,调整读写分离配置。
- 通知切换结果(邮件、钉钉群机器人)。
SlightShift MySQL 能做到秒级故障转移,5-10秒监测到主机故障,5-10秒 apply 差异 relay logs,然后注册到新的 master,通常10-30秒即可 total downtime。另外,可在配置文件里配置各个 slave 当选为 New Master 的优先级,这在多机房部署 MySQL 场景下很实用。
故障自动恢复
宕机的 Master 节点恢复时:
- 如果恢复的节点重新创建 Mysql Pod 并加入集群,Sentinel 会配置新 Pod 为 Slave,通过获取当前 Master Mysql 的 log file 和 Position 来实现新加入 Slave 的数据同步。
- 如果恢复的节点中 Mysql Pod 依然存在且可用,Sentinel 此时会发现2个 Label 为 master 的 Pod。Sentinel 会依然使用宕机期间选择的新 Master,且把恢复的 Master 强制设置为Slave,并开启只读模式。
宕机的 Slave 节点恢复时:
- 如果恢复节点重新创建 Mysql Pod 并加入集群,Sentinel会配置新 Pod 为Slave,通过获取当前 Master Mysql 的 log file 和 Position 来实现新加入 Slave 的数据同步。
- 如果恢复的节点中 Mysql Pod 依然存在且可用,调度器不会执行操作,proxysql-service 会监测到新加入的 Slave,并将其加入到 endpoints 列表。
状态管理
状态管理并非新鲜话题,它为中心化系统分发一致的状态,确保分布式系统总是朝预期的状态收敛,是中心化系统的基石之一 。
MySQL 服务由一个 Master 节点和多个从 Master 上异步复制数据的 Slave 节点组成,即一主多从复制模型。其中,Master 节点可用来处理用户的读写请求,Slave 节点只能用来处理用户的读请求。
为了部署这样的有状态服务,除了 StatefulSet 之外,还需要使用许多其它类型的 k8s 资源对象,包括 ConfigMap、Headless Service、ClusterIP Service 等。正是它们间的相互配合,才能让 MySQL 这样的有状态服务有条件运行在 k8s 之上。
在 MySQL 集群中,状态转移最常发生在 Master 发生故障,集群进行故障转移期间。当 Master 发生故障宕机时会自动触发选主逻辑,选主结束后会进行故障切换,直至 New Master 正常提供读写服务,故障转移过程是需要时间的,在故障转移过程中 MySQL 服务会处于不可写状态。
在故障转移期间,Dead Master 实例会被 k8s 集群自动拉起,Dead Master 被拉起后会认为自己是合法的 Master,这样会造成集群中同时存在两个 Master,写请求很可能会被随机分配到两个 Master 节点,从而造成脑裂问题。
为了解决这种场景下的脑裂问题,我们引入了 InitContainer 机制,再配合 Sentinel 就能很好的解决该问题。
InitContainer,顾名思义,在容器启动的时候会先启动一个或多个容器去完成一些前置性工作,如果有多个,Init Container将按照指定的顺序依次执行,只有所有的 InitContainer 执行完后主容器才会启动。
我们在每一个 MySQL 的实例中都加入了 InitContainer,在 Dead Master 被 k8s 自动拉起之后,InitContainer 会自动检测集群中是否处于 Failover 阶段,如果处于Failover 阶段会进入 Sleep 轮询状态,直至 Failover 结束。
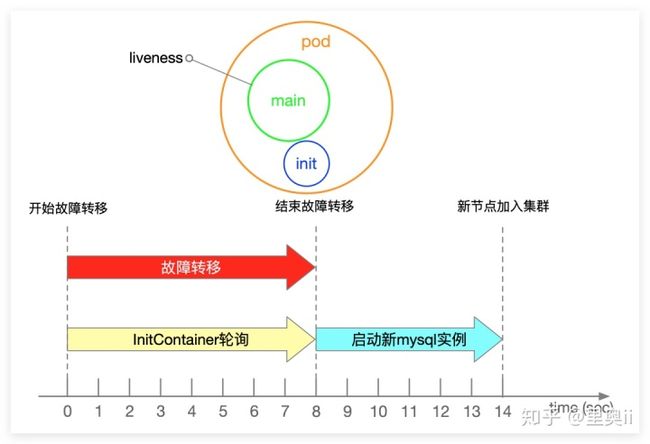
当 Failover 结束后,Sentinel 检测到 Dead Master 被拉起,会自动将 Dead Master 设置为 New Master 的 Slave 节点,以此来完成一次完整的 Failover 过程,并避免集群出现脑裂问题。
声明式运维
我们在使用 k8s 时,一般会通过 k8s 的 Resource 满足应用管理的需求:
- 通过 Deployment、StatefulSet 等 workload 部署服务。
- 通过 Service、Ingress 管理对服务的访问。
- 通过 ConfigMap、Secrets 管理服务的配置。
- etc.
上述 Resource 表征 User 的期望,kube-controller-mananger 中的 Controller 会监听 Resource Events 并执行相应的动作,来实现 User 的期望。
这种操作方式给应用管理带来了很大的便利,User 可以通过声明式的方式管理应用,不用再关心如何使用传统的 HTTP API、RPC 调用等。
Controller 会通过各种机制来确保实现 User 的期望,如通过不断检测 Object 的状态来驱使 Object 当前状态符合用户期望,这种运维模式我们称之为声明式运维。
但如果仅仅使用 k8s 提供的基础类型,对于 MySQL 这类复杂应用来说运维成本依然很高。如果能将声明式运维的模式进行扩展延伸到 MySQL 应用,会极大程度降低 MySQL 应用的部署和运维成本。
为了解决这个问题,slightshift-mysql-operator 应运而生。
slightshift-mysql-operator 本质上是 Resource + Controller:
- Resource
- 自定义资源(CRD, Custom Resource Definitions),为 User 提供一种声明式的方式描述对服务的期望。
- Controller
- 实现 Resource 中 User 的期望。
slightshift-mysql-operator 通过组合 k8s 中已有的概念,极大降低了部署和运维 MySQL 的成本:
- User 通过类似使用 Deployment 的方式描述对 MySQL 的需求
- 在 k8s 上部署 MySQL 应用的姿势与 k8s 官方资源的操作方式相同。
- 由 slightshift-mysql-operator 的 Controller 监听、处理事件请求
- 监听 Resource Events。
- 针对不同类型 (ADD/UPDATE/DELETE) 的 Events 执行相应的动作。
- 不断检测 Object 的状态来执行动作,驱使服务的状态符合 User 期望。

slightshift-mysql-operator 的设计理念:
- 声明式配置:提升可读性和运维效率,降低运维成本。
- 最终一致性:动态调整集群状态实现最终一致性。

slightshift-mysql-operator 极大程度上降低了在 Kubernetes 集群中使用和管理 MySQL 应用的成本,User 可以通过声明式的 CR 创建应用,Vendor 可将管理应用的专业知识封装,对 User 透明。
slightshift-mysql-operator 在架构层面上使用分层设计,简化了架构复杂度,同时尽可能降低了 MySQL 多个集群实例间相互干扰,实现各个实例的自治。
部署结构如下图所示:

备份与恢复
为保证数据安全性,还需对数据进行定期备份,保证用户数据在极端情况下(集群崩溃)时数据可恢复。
通过 Cronjob 对 Mysql 数据进行备份:
- 在 Kubernetes 集群中创建 Cronjob,Cronjob 会定期进行数据备份。
- 备份数据会被打上时间标签,并上传到对象存储服务器(Ceph、Minio)。
通过创建 Job 对 Mysql 进行数据恢复:
- 在集群中创建恢复 Job,Job 根据 SNAP_SHOT 到存储服务器(OSS、Minio)上获取备份数据。
- Job 把数据恢复到 Mysql Master 实例,同时 Slave 会完成数据同步。
五 技术演进
唯有进化,才能站到食物链顶端。
根据 Gartner 报告预测,数据库云平台市场份额将会在下一个五年中翻倍,而70%的用户将开始使用 dbPaaS 数据库云平台。因此,为了满足各类应用程序对数据库云平台的需求,同时为了减少私有云部署中对大量不同类型数据存储产品的运维复杂性,数据库的架构演进将是未来十年数据库转型的主要方向之一。
云原生数据库是未来数据库发展的一个重要方向,云原生数据库架构随着云化要求也需要进行相应的迭代,未来在云原生数据库架构的演进还会随着需求的变化而持续发展。

六 未来展望
中间件作为构筑上层业务系统的基石和核心技术,具有高可靠性、高扩展性、强专业性等特点。
关于未来,由于中间件的这些特点,未来云原生中间件会向着规范化、构建化、松耦合和平台化的方向发展。平台化能够更快速响应业务变化,为业务的横向发展提供集中的技术解决方案。

从终态来看,我们想做一个企业级云原生中间件 PaaS 平台,涵盖基础中间件的部署、配置、升级、伸缩、故障处理等自动化能力。
首先谈谈我对中间件平台的理解,中间件平台应该是一系列中间件解决方案集合的能力开放式技术中台,它形成了完整、久经考验、开放和组件化的解决方案,旨在为复杂多变的上层业务领域提供稳定可靠的计算、存储服务。
任何一个平台型产品的发展历程,都不是一开始就做平台的,而是先有业务需求,为了解决实际业务需求而积累了某些领域的知识,进而成为了这些领域的专家,最终再向平台转变。换句话说,平台是一个持续积累的过程,也是一个水到渠成的过程。

在企业信息平台构建过程中,有效、合理、规范化的利用中间件平台来快速构建上层业务系统,可以为企业及时响应需求变化提供有力保障,形成企业的集约化管理,进而提升企业核心力量获得可持续竞争的优势。
原作者:姜杉彪(孟宇)
原文链接: 云原生下,如何实现高可用的MySQL?
原出处:阿里技术
侵删
