在数据仓库环境中高效使用 DB2 数据迁移实用工具
在一个分区数据库环境中使用 DB2 中的数据迁移实用工具非常简单。但在使用大型数据仓库环境,而该环境在 InfoSphere Warehouse 的 Database Partition Feature (DPF) 环境中拥有多兆兆字节的 STAGING、STORE 与 DATAMART 表的时候,需要考虑其他一些事项。在本文中,我们将分析 DB2 中可用的数据迁移选项以及最适用于数据仓库环境的方法。
下表列出了 DB2 9.7 中可用的数据迁移选项,以及每个选项的使用情况说明和示例。
表 1. DB2 中可用的数据迁移选项
| 实用工具名称 | 用途 | 使用实践 | 示例 |
|---|---|---|---|
| Export | 将数据库表中的数据导出到文件中 | 如果您想将表数据保存在文件中,以供将来使用或使用当前数据刷新另一个环境,可以使用该方法。 | EXPORT TO DATAMART. F_CUST_PROF.DEL OF DEL MESSAGES DATAMART. F_CUST_PROF.EXPORT.MSG SELECT * FROM DATAMART.F_CUST_PROF; |
| Load | 快速将数据插入数据库中的某个现有表中 | 如果您主要关心数据插入性能,可以使用这个实用工具。它将格式化的页面插入数据库中,而非逐行插入。数据库管理员/用户还可以选择不将某个活动记录到事务日志中。但您要知道,此实用工具能够完全利用系统资源。 | LOAD FROM DATAMART. F_CUST_PROF.DEL OF DEL SAVECOUNT 10000 MESSAGES DATAMART. F_CUST_PROF.LOAD.MSG INSERT INTO DATAMART.F_CUST_PROF; |
| Import | 将文件中的输入插入表或视图中 | 当要插入数据的视图和表具有限制条件,而且您的目的并非将表设置为 “set integrity” 状态时,此实用工具最有用。此外,如果您建立了触发器并希望在插入数据时触发它们,也可以使用此实用工具。 | IMPORT FROM DATAMART. F_CUST_PROF.DEL OF DEL COMMITCOUNT 1000 MESSAGES DATAMART. F_CUST_PROF.IMPORT.MSG INSERT INTO DATAMART. F_CUST_PROF; 如果您有一个 IXF 格式的数据文件,可以用一条命令创建一个表并插入数据,前提是这个表并不存在于目标环境中 |
| db2move | 在模式级别(一般指多个表)上将表从一个环境复制到另一个环境 | 当您有很多表需要基于模式在环境之间复制时,使用带 COPY 选项的 db2move 可以轻松达到目的。 | 从 STAGING 模式导出所有表:db2move SourceDB EXPORT –sn STAGING 从数据库导出所有表: db2move SourceDB EXPORT 将所有表数据导入目标数据库中: db2move TargetDB IMPORT 将数据从源数据库复制到目标数据库中: db2move SourceDB COPY –co TARGET_DB TargetDB USER <sername>USING <assword> |
数据库管理员经常发现,通过网络将大量数据从一台数据库服务器复制到另一台数据库服务器非常困难。完成此任务面临的一些重大挑战包括:
- 数据量
- 数兆兆字节的数据
- 数百个表
- 包含上亿条记录的表以及数千个范围分区
- 需要更快的数据传输速度和数据重新加载速度
- 需要跨数据库分区节点均匀地分布数据
现在您已经对 DB2 中的迁移选项有了大致了解,可以详细查看使用实际代码进行数据迁移的一些技术。
在这一节中,我们会分析将 DATAMART 从源数据库迁移到目标数据库的一些可用技术。我们会评估每种方法的优点与缺点,以便减轻数据传输过程中数据库管理员的工作量。
示例使用以下配置在 IBM Balanced Warehouse D5100 上进行测试:
- 11 个物理节点和 41 个逻辑节点
- 每台服务器有 4 个 CPU,频率为 2800 MHz
- 每台服务器有 32 GB RAM
- SUSE Linux 10 2.6.16.60-0.66.1-smp
- DB2 9.5 FP7
- 数据库大小:6.8 TB
- 已对主要事实表进行范围分区,每个表中的分区数量大约为 21237 个
数据副本范围广泛,从生产 Balanced Warehouse 到类似基础架构和 DB2 版本的用户接纳测试 (UAT) Balanced Warehouse。
作为一项业务需求,已从生产环境刷新了两个 UAT 数据库模式,即 DATASTORE 和 DATAMARTS。
正如前面讨论的那样,在从一个环境到另一个环境刷新大型数据集时,DB2 中有很多技术可供使用。这些技术包括:
- 在本地数据库服务器上导出数据,传输数据文件,然后在目标数据库服务器上本地加载数据(哈希分区或非哈希分区的小型表)
- 从本地数据库服务器上导出数据,并将数据远程加载到目标数据库服务器中
- 从远程数据库服务器上导出数据,并在目标数据库服务器上本地加载数据
- 将数据导出到操作系统管道中,然后通过管道将数据导入或加载到目标远程数据库服务器中
- 在本地数据库服务器上并行导出数据(每部分位于各自的分区文件系统中),使用一个数据文件传输,然后在本地并行加载各个部分
下面通过示例分析了以上每种技术。
在本地数据库服务器上导出数据,传输数据文件,然后在目标数据库服务器上本地加载数据(哈希分区或非哈希分区的小型表)
图 1. 技术 #1
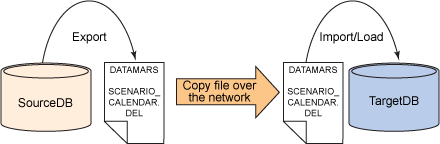
下面给出了实现这种技术的步骤。
- 在源数据库服务器上本地连接到 SourceDB。
CONNECT TO SourceDB;
- 在源数据库服务器中的表上执行 DB2 导出。
EXPORT TO DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL MESSAGES DATAMARTS.SCENARIO_CALENDAR.MSG SELECT * FROM DATAMARTS.SCENARIO_CALENDAR;
- 压缩已导出的文件,从而缩短在服务器之间进行文件传输所需的时间。
gzip DATAMARTS.SCENARIO_CALENDAR F.DEL
- 使用 sftp 或 scp 将压缩后的文件从 SourceDB 服务器传输到 TargetDB 服务器。
cd <export file path>
sftp username@<targetDB Server hostname> put DATAMARTS.SCENARIO_CALENDAR.DEL.gz OR scp DATAMARTS.SCENARIO_CALENDAR.DEL.gz username@<targetDB Server hostname>:/<PATH>
- 在目标数据库服务器上解压缩传输完毕的文件。
gunzip DATAMARTS.SCENARIO_CALENDAR.DEL.gz
- 在目标数据库服务器上本地连接到 TargetDB。
CONNECT TO TargetDB;
- 执行加载或导入。
LOAD FROM DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL SAVECOUNT 10000 MESSAGES DATAMARTS.SCENARIO_CALENDAR.LOAD.MSG INSERT INTO DATAMARTS.SCENARIO_CALENDAR;
- 如果选择使用加载命令,在操作结束时执行一次 SET INTEGRITY 命令。
SET INTEGRITY FOR DATAMARTS.SCENARIO_CALENDAR IMMEDIATE CHECKED;
- 执行 RUNSTATS,让统计数据保持最新。
RUNSTATS ON TABLE DATAMARTS.SCENARIO_CALENDAR WITH DISTRIBUTION AND DETAILED INDEXES ALL;
从本地数据库服务器上导出数据,并远程把数据加载给目标数据库服务器。
图 2. 技术 #2
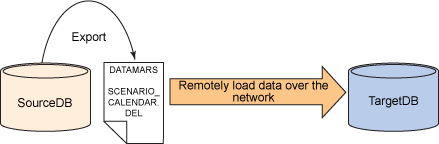
实现这种技术的步骤如下:
- 在源数据库服务器中登记目标数据库。
CATALOG TCPIP NODE TargetND REMOTE TargetDBServer.ibm.com SERVER 50001; CATALOG DATABASE TargetDB AT NODE TargetND;
- 在源数据库服务器上本地连接到 SourceDB。
CONNECT TO SourceDB;
- 从源数据库服务器上的表执行 DB2 导出。
EXPORT TO DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL MESSAGES DATAMARTS.SCENARIO_CALENDAR.msg SELECT * FROM DATAMARTS.SCENARIO_CALENDAR;
- 在目标数据库服务器上远程连接到 TargetDB。
CONNECT TO TargetDB user <username> using <Password>;
- 将数据从源数据库远程加载或导入目标数据库。
LOAD CLIENT FROM DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL SAVECOUNT 10000 MESSAGES DATAMARTS.SCENARIO_CALENDAR.LOAD.msg INSERT INTO DATAMARTS.SCENARIO_CALENDAR;
- 如果选择使用加载命令,在操作结束时执行一次 SET INTEGRITY 命令。
SET INTEGRITY FOR DATAMARTS.SCENARIO_CALENDAR IMMEDIATE CHECKED;
- 执行 RUNSTATS,让统计数据保持最新。
RUNSTATS ON TABLE DATAMARTS.SCENARIO_CALENDAR WITH DISTRIBUTION AND DETAILED INDEXES ALL;
从远程数据库服务器上导出数据,并在目标数据库服务器上本地加载数据。
图 3. 技术 #3
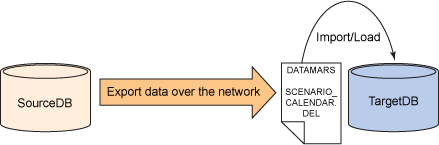
实现这种技术的步骤如下:
- 在目标数据库服务器中登记源数据库。
CATALOG TCPIP NODE SourceND REMOTE SourceDBServer.ibm.com SERVER 50001; CATALOG DATABASE SourceDB AT NODE SourceND;
- 从目标数据库服务器远程连接到源数据库。
CONNECT TO SourceDB user <username> using <password>;
- 从表远程执行 DB2 导出。
EXPORT TO DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL MESSAGES DATAMARTS.SCENARIO_CALENDAR.msg SELECT * FROM DATAMARTS.SCENARIO_CALENDAR;
- 在目标数据库服务器上本地连接到 TargetDB。
CONNECT TO TargetDB user <username> using <Password>;
- 执行本地加载或导入。
LOAD FROM DATAMARTS.SCENARIO_CALENDAR.DEL OF DEL SAVECOUNT 10000 MESSAGES DATAMARTS.SCENARIO_CALENDAR.LOAD.msg INSERT INTO DATAMARTS.SCENARIO_CALENDAR;
- 如果选择使用加载命令,在操作结束时执行一次 SET INTEGRITY 命令。
SET INTEGRITY FOR DATAMARTS.SCENARIO_CALENDAR IMMEDIATE CHECKED;
- 执行 RUNSTATS,让统计数据保持最新。
RUNSTATS ON TABLE DATAMARTS.SCENARIO_CALENDAR WITH DISTRIBUTION AND DETAILED INDEXES ALL;
导出数据到操作系统管道,然后从管道把数据导入或加载到目标远程数据库服务器。
图 4. 技术 #4
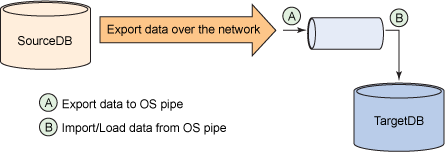
实现这种技术的步骤如下:
- 在目标数据库服务器中登记源数据库:
CATALOG TCPIP NODE SourceND REMOTE SourceDBServer.ibm.com SERVER 50001; CATALOG DATABASE SourceDB AT NODE SourceND;
- 在目标数据库服务器中创建一条操作系统管道。
mkfifo datapipe ls –ltr datapipe prw-r--r-- 1 bculinux bcuigrp 0 2011-09-18 16:32 datapipe
- 从目标服务器远程连接到源数据库。
CONNECT TO SourceDB user <username> using <password>;
- 从源数据库导出数据,并将其写入操作系统管道(数据管道)的一端。在业务场景中,数据库管理团队会从 PROD 刷新 UAT。仅适用于 2011 年的 12904084 条记录。
EXPORT TO datapipe OF DEL MODIFIED BY COLDEL, MESSAGES FACT_CUST_FPI_VALIDATION.EXP.msg SELECT * FROM DATAMARTS.F_CUST_FPI_VALIDATION WHERE REC_LOAD_DT > '2011-01-01-00.00.00.000000' WITH UR;
- 从目标服务器远程连接到源数据库。
CONNECT TO TargetDB user <username> using <password>;
- 从操作系统管道的另一端将数据导入或加载到常规哈希范围分区的表中。
IMPORT FROM datapipe OF DEL MODIFIED BY COLDEL, MESSAGES FACT_CUST_FPI_VALIDATION.IMP.msg INSERT INTO DATAMARTS.FACT_CUST_FPI_VALIDATION; LOAD FROM datapipe OF DEL MODIFIED BY COLDEL, MESSAGES FACT_CUST_FPI_VALIDATION.LD.msg INSERT INTO DATAMARTS.FACT_CUST_FPI_VALIDATION;
注意:在拥有众多范围分区的已分区数据库中使用加载命令时要当心。加载可能以 SQLCODE SQL0973N 失败告终,而您可能丢失目标表中的数据。
为目标数据库制作一份应用快照。您会看到目标数据库服务器表上出现了一次插入操作。在数据传输完成之后,您会看到服务器上在同时运行将数据导出到管道以及从管道导入数据两种操作。
以下列表总结了完成之后源服务器与目标服务器上的状态:
清单 1. 从源数据库连接
db2 "EXPORT TO datapipe OF DEL MODIFIED BY COLDEL, MESSAGES FPI_VALIDATION.EXP.msg SELECT * FROM DATAMARTS.F_CUST_FPI_VALIDATION WHERE REC_LOAD_DT > '2011-01-01-00.00.00.000000' WITH UR" Number of rows exported: 12904084 |
清单 2. 从目标数据库连接
db2 "IMPORT FROM datapipe OF DEL MODIFIED BY COLDEL, MESSAGES FPI_VALIDATION.IMP.msg INSERT INTO DATAMARTS.FACT_CUST_FPI_VALIDATION" Number of rows read = 12904084 Number of rows skipped = 0 Number of rows inserted = 12904084 Number of rows updated = 0 Number of rows rejected = 0 Number of rows committed = 12904084 |
要在完成相关操作之后删除操作系统管道,请使用以下命令:
rm datapipe |
将数据加载到数据库分区环境中的已大量使用范围分区的表中时,您可能会遇到以下错误。
SQL0973N "UTIL_HEAP_SZ" 堆中没有足够多的可用存储来处理语句。SQLSTATE=57011
下面给出了此问题的一些解决方法:
- 将 UTIL_HEAP_SZ 数据库配置参数值增加为最大可划分为 524288 个大小为 4K 的页面。然后强制关闭所有应用程序,并重新激活数据库。
- 减少 DATA BUFFER 数量,同时加载数据。
- 如果前两个步骤还不能让您完成加载,请终止加载。
- 创建一个没有范围分区的临时表 DATAMARTS.FACT_CUST_FPI_VALIDATION_TMP,然后使用不可恢复的子句从管道在临时表上执行加载,从而提高加载的速度。
- 完成之后,执行
INSERT INTO ... SELECT * FROM...。您可以执行 NOT LOGGED INITIALLY 插入,以提高数据加载的性能。下面的清单显示了这种插入。
清单 3. NOT LOGGED INITIALLY 插入
db2 +c "ALTER TABLE DATAMARTS.FACT_CUST_FPI_VALIDATION ACTIVATE NOT LOGGED INITIALLY" db2 "INSERT INTO DATAMARTS.FACT_CUST_FPI_VALIDATION SELECT * FROM DATAMARTS.FACT_CUST_FPI_VALIDATION_TMP" |
注意:如果 NOT LOGGED INITIALLY 插入由于某些原因失败,您必须重新创建表。
在本地数据库服务器上导出数据,传输数据文件,然后在目标数据库服务器上本地加载数据(哈希分区或非哈希分区的小型表)。
图 5. 技术 #5
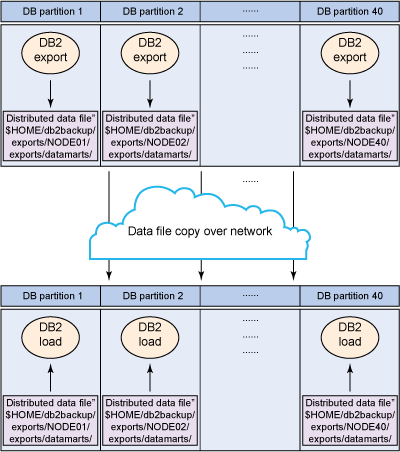
在源数据库服务器上执行以下步骤,以便导出数据。
- 创建从管理节点导出目录到所有数据节点的软链接。在这个例子中,导出目录为 $HOME/db2backup/exports。
ln -s /db2fs/bculinux/NODE0001 NODE1 ln -s /db2fs/bculinux/NODE0002 NODE2 ......... ln -s /db2fs/bculinux/NODE0040 NODE40
- 下列清单显示了创建软链接之后得到的文件。
ls –ltr lrwxrwxrwx 1 bculinux bcuigrp 24 2011-04-13 19:25 NODE1 -> /db2fs/bculinux/NODE0001 lrwxrwxrwx 1 bculinux bcuigrp 24 2011-04-13 19:25 NODE2 -> /db2fs/bculinux/NODE0002 ......... lrwxrwxrwx 1 bculinux bcuigrp 24 2011-04-13 19:28 NODE40 -> /db2fs/bculinux/NODE0040
- 在每个物理数据节点服务器中,创建类似下面的目录结构。
mkdir –p /db2fs/bculinux/NODE0001/exports/datamarts mkdir –p /db2fs/bculinux/NODE0002/exports/datamarts ......... mkdir –p /db2fs/bculinux/NODE0040/exports/datamarts
- 对于需要导出的表,请从 SYSCAT.COLUMNS 找到哈希分区列。
db2 "SELECT SUBSTR(COLNAME,1,20) COLNAME, PARTKEYSEQ FROM SYSCAT.COLUMNS WHERE TABNAME=''F_CUST_PROFTBLTY_TMP' AND TABSCHEMA='DATAMARTS'" COLNAME PARTKEYSEQ -------------------- ---------- ACCT_KEY 0 BUSS_UNIT_KEY 1 CALENDAR_MONTH_KEY 2 CRNCY_CODE 0
在这个表中,我们找到了两个哈希分区列。我们选择其中一个哈系列,以便在各自分区中导出数据。
- 使用 DB2 EXPORT 命令跨所有分区并行导出数据,如以下清单所示。
db2_all "\"|| db2 \"EXPORT TO $HOME/db2backup/exports/NODE##/exports/datamarts/ DATAMARTS.F_CUST_PROFTBLTY_TMP.del OF DEL SELECT * FROM DATAMARTS.F_CUST_PROFTBLTY_TMP WHERE DBPARTITIONNUM (BUSS_UNIT_KEY)=##\""
此命令将每个分区数据导出到各自的分区节点。
- 使用 scp 执行从每个源数据库服务器节点到目标数据库服务器的文件复制。
scp -p <File Name> <User Name>@<Host Name>:<File Name>
在目标数据库服务器上,执行以下步骤导出数据。
- 像在源数据库中一样创建软链接,如 清单 4 中所示。
- 使用 DB2 加载命令并行加载每个分区的数据。
清单 4. 并行的 LOAD 命令
db2_all "<<-0<<\" db2 -v \"LOAD FROM db2backup/exports/NODE##/exports/datamarts DATAMARTS.F_CUST_PROFTBLTY_TMP.del OF DEL INSERT INTO DATAMARTS.F_CUST_PROFTBLTY_TMP NONRECOVERABLE \""
此命令将把每个分区数据加载到各自的分区节点。
表 2 重点介绍了这些技术的优点和缺点。
表 2. 优点和缺点
| 技术 | 优点 | 缺点 |
|---|---|---|
| 1. 本地导出和本地加载 |
|
|
| 2. 本地导出和远程加载 |
|
|
| 3. 远程导出和本地加载 |
|
|
| 4. 使用管道导出和加载 |
|
|
| 5. 并行导出和并行加载 |
|
|
本文描述了如何使用 DB2 数据迁移实用工具来满足需要对多分区事实表进行特殊考虑的平衡的仓库环境中的要求。您现在应该对处理范围分区程度很高的大型事实表时可能出现的问题有了更 好的了解。如果您遇到 LBAC 保护的数据,请参考 IBM Information Center 中的更多详细信息。