浅谈RocketMQ
我们围绕下面9个问题来解答:
1.为什么要用消息队列?(消息队列的应用场景?)
2.各种消息队列产品的比较
3.消息队列的优点和缺点?
4.如何保证消息队列的高可用?
5.如何保证消息不丢失?
6.如何保证休息不被重复消费?(如何保证消息消费的幂等性?)
7.如何保证消息消费的顺序性?
8.大量消息堆积怎么处理?
9.消息过期怎么处理?
1.为什么要用消息队列?(消息队列的应用场景?)
从解耦,异步,削峰三个方面来答.
以电商应用为例,用户创建订单后,如果耦合调用库存系统,物流系统,支付系统,任何一个子系统除了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验.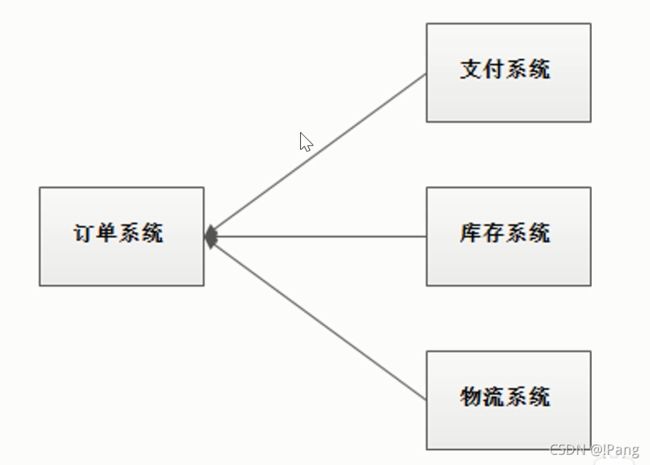
系统当中一个子系统出了异常最终会导致整个业务处理失败,例如库存系统除了问题导致下单业务跟着失败.
1.1解耦
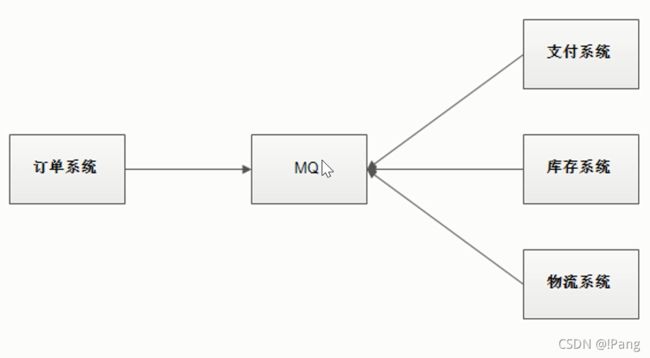
使用消息队列解耦合,系统的耦合性就会降低了.比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成.当用户的下单操作正常完成.当物流系统恢复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障.
用户通过订单系统下单,下单之后,订单系统处理完自己的业务,订单系统把其他系统需要处理业务用的数据以消息的形式转存到MQ,三个系统都是消息的消费方法,一直在监听着MQ有没有新的消息,只要有消息就会自己去取出消息进行消费.
异常情况:如果库存系统挂了,用户感知不到后台的异常,因为MQ中间解耦了,只要订单系统没有抛出异常,当前下单就成功了.但是库存系统处理失败了,等重启成功之后再去MQ拿消息消费即可,所以底层一个系统出现故障不会影响到用户下单这个行为,这就是MQ第一个应用场景叫做解耦.
1.2异步

A系统接收一个请求,需要在自己本地写库,还需要在B,C,D三个系统写库,自己本地写库要3ms,B,C,D三个系统写库分别要300ms,450ms,200ms.最终请求延时是3+300+450+200=953ms,接近1s,用户体验非常不好,一般互联网类的企业,对于用户直接的操作,一般要求是每个求情都必须在200ms以内完成,对用户几乎是无感知的,如果用户通过浏览器发起请求,等待个1s,这几乎是不可接受的.
如果使用MQ,那么系统连续发送3条消息到MQ队列中,加入耗时5ms,A系统从接收一个请求到返回响应给用户,总时长是3+5=8ms,对于用户而言,响应速度大大提升了,改善了用户的体验.
如果A响应需要用到B,C,D的处理结果,这种架构就不行了.所以要用MQ要考虑到业务场景.
1.3流量削峰
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮,有了消息队列可以将大量求情缓存起来,分散到很长一段时间处理,这样可以大大提高系统的稳定性和用户体验.
例如双十一秒杀活动,大量用户蜂拥而至,考验系统能不能扛得住,如何应对这种突然大流量的请求来了之后,保证系统稳定性,不宕机呢?
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求.这会影响用户体验,这时候如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样比不能下单体验要好很多.
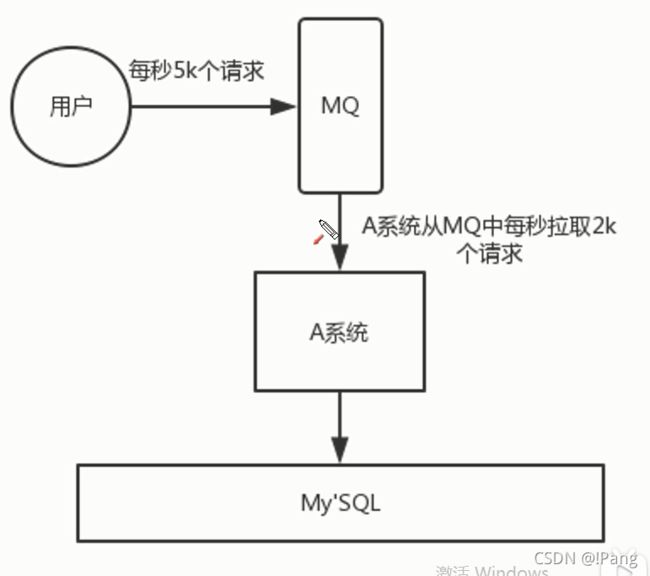
请求来了之后先放到MQ之中,MQ是个消息容器,请求过来的是数据.把数据以消息的形式封装起来存放到MQ之中,MQ会把数据放置到内存当中,内存的抗压能力比数据库强的多,假设每秒5000个请求访问数据库,由于使用了MQ,A系统每秒只拉取2000个请求下来写入数据库,数据库2.5秒可以处理完,虽然不是立即处理完,但是现在保证了系统的稳定性没有宕机.
流量削峰的经济考量
业务系统正常时间段的QPS如果是1000,流量高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这是可以使用消息队列对流量峰值进行削峰.
例如 : 我们今天要进行秒杀服务,提前判QPS峰值是10000,但是平时是1000.搭架构时候是奔着搭建1000QPS还是搭建1WQPS?
如果是1K秒杀开始系统必挂,搭建1WQPS大部分时间系统很多资源限制,1WQPS要买很多的设备,但是秒杀可能半小时就结束了.为了半小时增加这么大成本不划算.公司以盈利为主1K,1W都不靠谱,那就准备1000的设备,但是好药能抗住1W的压力,通过MQ进行流量削峰,就可以节省公司成本了.
2.各种消息队列产品的比较?
主要考察你对市面上MQ产品是否做过调研,根据当前公司业务特点做了取舍.
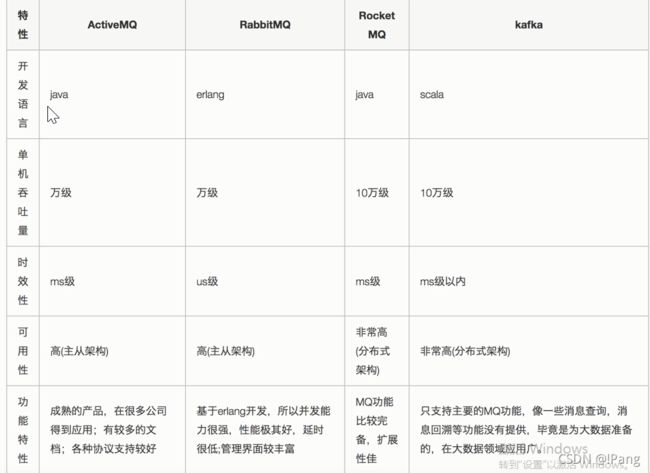
如何取舍:
ActiveMQ,早期使用的比较多,没经过大规模吞吐量场景的验证,社区也不是很活跃,但是现在确实大家用的不多了,不推荐.
RabbitMQ,开发语言erlang阻止了大量的Java工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是RabbitMQ是开源的,有比较稳定的支持,社区活跃度也高,如不考虑二次开发,追求性能和稳定性,推荐使用.
RocketMQ,开发语言是Java,在阿里内部经受过高并发业务的考验,稳定性和性能均不错,考虑后期可能二次开发,推荐使用.
kafka,大数据领域的实时计算,日志采集等场景,用kafka是业内标准的,社区活跃度很高,推荐使用.大数据领域日志采集等业务推荐使用.
3.消息队列的优点和缺点?
考察你在使用MQ的时候,不是光停留在简单的使用上,而是有自己的一个思考.在项目中引入了MQ,会加大系统的复杂度,需要额外的维护,如果MQ挂了会影响系统整体的稳定性.
优点 : 解耦,异步,削峰
缺点 : 系统的可用性降低,系统的复杂度提高,一致性等问题.
3.1 系统可用性降低
系统引入的外部依赖越多,系统稳定性越差,一旦MQ宕机,系统之间就不能通信了,系统可用性就降低了.

那么如何来保证MQ的高可用呢?如何保证MQ不挂呢?
集群,一个容易挂就整多个这样就保证了高可用.
3.2系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用.
数据通过MQ进行异步调用,数据以消息的形式封装到了message之中,会产生很多的问题.
思考:
消息丢失了怎么办?
发送重复消息问题怎么办?
如果要求按照消息发送的顺序去消费怎么办?
3.3一致性问题
A系统处理完业务,通过MQ给B,C,D三个系统发送消息数据,如果B,C系统处理成功,但是D系统处理失败了,怎么办?

业务处理的不一致,也是复杂性的体现.那么如何保证消息数据处理的一致性呢?
通常使用分布式事务去处理.
4.如何保证消息队列的高可用?
4.1 RabbitMQ高可用-普通集群
1.在多台机器上分别启动RabbitMQ实例.
2.多个实例之间可以相互通信.
3.实际数据只会放在一个RabbitMQ上,其他实例都是同步数据.,
4.消费的时候,如果连接的没有实际数据的队列,那么当前实例会从实例数据所在的队列拉取数据.
特点:
1.没有真正做到高可用.
2.有数据拉取的靠小和单实例的瓶颈问题.

元数据 : 队列的配置信息,实际数据在队列里面,通过元数据可以找到队列消息,既1,3节点里面没有实际数据,单是1,3节点通过元数据能找到实际的数据在哪里.
这种架构特点 : 当前消费者从1,3节点消费消息,但是1,3节点里面没有实际数据,会从2节点里面拿到实际数据返回给消费者,让消费者正常消费.
这种集群特点 : 如果2节点挂了,这个数据就没了,因为1,3里面没有实际数据,只有元数据.普通集群并没有做到真正的高可用,即使2节点没挂,还会有一个缺点,就是数据拉取开销会比较大,如果不仅仅三个节点的集群,而是非常多节点的集群,每个节点都需要去2节点中拉取数据,它的性能也会存在一个瓶颈问题.
4.2 RabbitMQ高可用-镜像集群
1.在多台机器上分别启动RabbitMQ实例.
2.多个实例之间可以相互通信.
3.每次生产者写消息到队列的时候,都会自动把消息同步到袄多个实例的队列中.这样每个RabbitMQ节点上队列中都有消息数据和元数据.
4.某一个节点宕机,其他节点依然保存完整的数据,不会影响客户端消费.
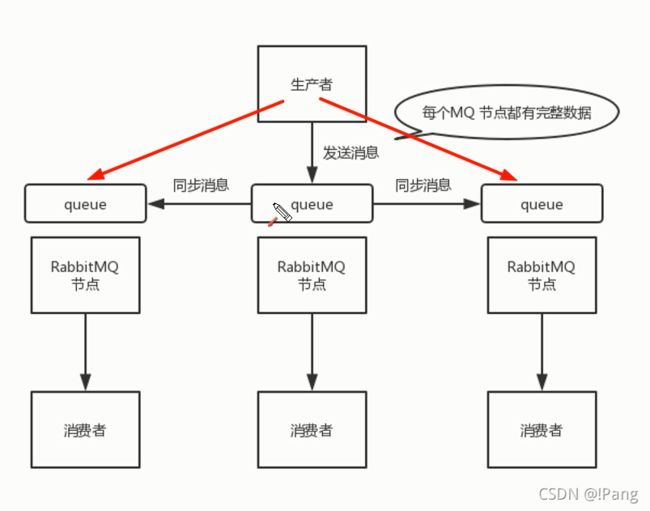
原来只有中间节点保存了元数据和消息数据,其他节点没有保存消息数据.现在让三个节点达到百分百完全一样,三个节点里面都有消息的实际数据.这样的话,如果一个节点挂了,其他两个还可以工作,就可以实现高可用.解决方案就是把实际的数据给所有节点都去同步一下,这样每一个消费者抓取任意节点都是一样的.
注意:
生产者发消息是面对一个集群去发,不是某一个节点去发.
生产者配置文件当中会配置这三个节点的网络地址,其中一个挂了就给其他节点发,只要其中一个发送成功就不再发送了.
RocketMQ高可用-双主双从
1.生产者通过 Name Server 发现 Broker.
2.生产者发送队列消息到两个Broker主节点.
3.Broker主节点分别和各自从节点同步数据.
4.消费者从主或者从节点订阅信息.
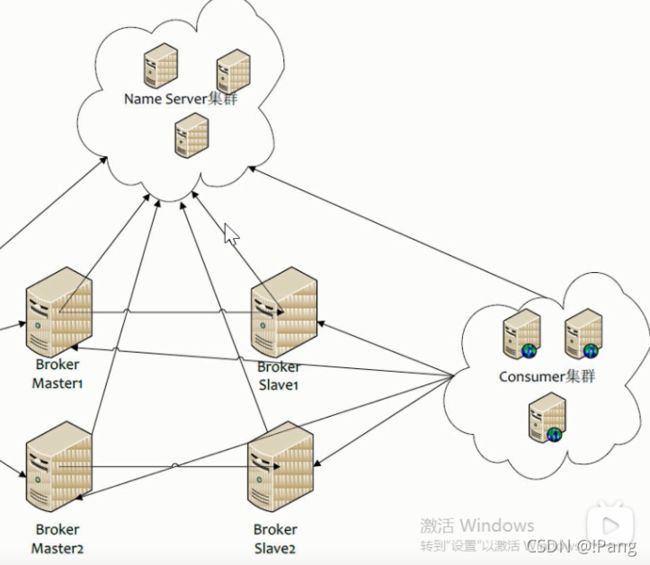
注意:
1.生产者发消息是给Broker发.
2.Broker 是接收真正数据的服务器.
3.Name Server 是管理Broker的服务器.
生产者发送消息首先回去找 Name Server 要一个可用的Broker 地址.
生产者会去给 Broker 发送消息,消费者监听到就会去消费.
双主双从保证高可用:
Name Servier 集群管理所有的 Broker 如果它挂了,生产者就无法在好到 Broker 首先就要保证 Name Server 的高可用.
如何保证 Name Server 的高可用呢?
搭建集群,启动多个节点来保证高可用.
如何保证 Broker 的高可用呢?
也是搭建集群,搭建双主双从集群,其中主节点和从节点数据会进行同步.
比如 : 数据发送到了 Broker Master1 它会将数据同步给 Slave1,保证一个数据存到了两个地方.挂了一个还有另一个可用.
双主双从 : 如果一个主节点挂了,从节点如果没有提升为主节点的时候,它是不能够去接收数据的.所以我们还要再来一套主从节点.一个主节点挂了,另外一个主节点再去接收数据,让消费者继续消费.
5.如何保证消息不丢失?
消息丢失的原因:
情况1 : 消息没有成功发送到MQ Broker.
情况2 : 消息发送到MQ Broker后,Broker宕机导致内存中消息数据段丢失.
情况3 : 消费者消费到了消息,但是没有处理完毕就出现异常导致消息丢失.
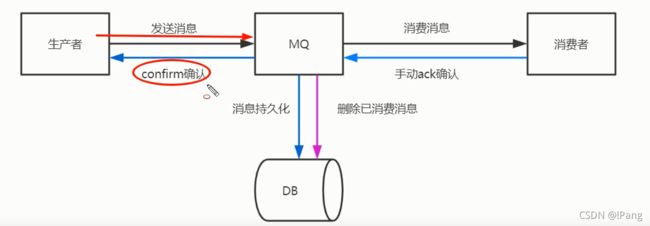
1. 生产者发送消息到MQ过程中,出现了网络断开或者MQ挂了,那么MQ接收不到数据,造成消息丢失.
2.MQ接收到了消息之后挂了,消息还在内存当中,内存中的数据存储是暂时性的.如果软件重启之后,内存中的数据就会丢失,还没来得及持久化.
3.消费者从MQ拿到消息进行消费,在处理数据过程中挂了,没有成功处理.既然已经从MQ中成功取到了数据,MQ就认为已经消费过了,就不再保存数据了.如果数据删除了,但是消费者并没成功消费,对于业务来讲这个数据还是丢失.
如何防止消息丢失呢?
生产者发送一个消息给MQ,MQ要告诉(confirm确认)生产者已经接收到了数据,要进行confirm确认,然后MQ接收到这个数据之后要立马把这个数据进行持久化,这样就会把这个数据持久化到磁盘中.重启之后数据还能从磁盘之中重新加载到MQ中,保证了消息不会的丢失.
消费者拿到数据之后,消费者处理数据,如果没有成功消费,就不要手动给MQ进行ACK确认.因为MQ一旦收到ACK确认就会认为已经成功消费了,就会把这条数据删除.如果MQ没有收到消费方的ACK确认,这条数据还会在MQ队列之中保留着,这样就保证了消费方能功能的去处理这个数据.
总结: 如何保证消息不丢失.
生产者投递可靠消息,MQ持久化,消费方进行ACK确认.
6.如何保证消息不被重复消费?如何保证消息消费的幂等性?
重复消息产生的原因?
重复消息的根本原因是网络不可达.
6.1 发送时消息重复
当一条消息已被成功发送到服务器,此时出现了网络闪断,导致服务端对客户端应答失败,如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续就会收到两条内容相同的消息.

生产者成功发送了一个消息给MQ,在消息发送的时候,由于网络波动等不确定的因素.导致MQ没有给生产者确认,生产者就认为MQ没有收到消息,生产者就会再发送一条重复的消息给服务器.
6.2 消费时消息重复
消息消费的场景下,消息已经投递到消费方并完成业务处理,当消费方给MQ服务端反馈应答的时候发生了网络闪断,导致ACK确认失败.为了保证消息至少被消费一次(MQ内部的可靠性),MQ服务端会在网络恢复后再次尝试投递之前被消费方处理过的消息,此时消费者就会收到两条内容相同的消息.
消费者要保证它能够绝对成功的把消息消费了,要进行ACK的确认,拿到了第一次消息进行消费之后,应答的时候,出现了网络波动,应答失败了.MQ没有收到ACK确认会再把这个消息发送一遍,这个时候就会导致消费方手打了两条重复的消息.
重复消息的根本原因是网络原因,因此我们无法避免重复消息的产生.
6.3消息的幂等性
1.消息发送者发送消息时携带一个全局唯一的消息id.
2.消费者获取消费后,先根据id在redis/db中查询是否存在消费记录.
3.如果没有消费过就正常消费,消费成功后写入redis/db.
4.如果消息消费过就直接舍弃.
在承认有重复消息的情况下也要解决我们的问题,就是有重复消息也要保证我们业务上没有问题,追求幂等性.
消息幂等性 : 消费者对于相同的两条消息,消费一次跟消费多次在业务上是一样的,第二条消息不会影响到业务的正确性.
重复的消息内部数据一模一样,id也是一样的.
还有一个方案 :
如果你把数据存储到数据库中,可以把全局唯一的id当做数据的主键,主键有唯一约束,这时候就不管是几个系统在处理.由于主键有唯一约束,可以保证只能成功插入一条数据.
消息携带全局id,消息方接收到消息时先查再处理,根据全局id判断是否重复,重复则丢弃.
7.如何保证消息的顺序性?
消息有序指的是可以按照消息发送顺序来消费.
例如 : 一笔订单产生了3条消息,分别是订单创建,订单付款,订单完成.
消费时,要按照顺序消费才有意义.
与此同时多笔订单之间又是可以并行消费的.
张三和李四各种产生的消息可以并行消费,而每一个人的消息又追求顺序性.
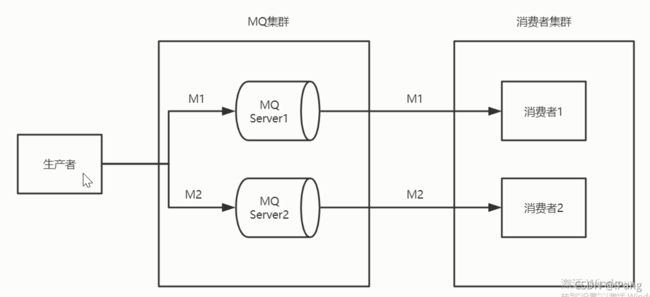
模型1 ; M1,M2按照先后顺序发送到两台Server,被两个消费者分别消费.
这个架构模型不能保证消息的顺序消费,因为生产者确实是按照顺序发送的,但是你无法保证M1先于M2到达Server,由于网络波动的原因,所以从源头上我们都不一定能保证消息的新婚徐到达,更不用说顺序消费了.
1.不能保证到达MQ的顺序.
2.不能保证消费者的顺序消费.
所以pass.
1.
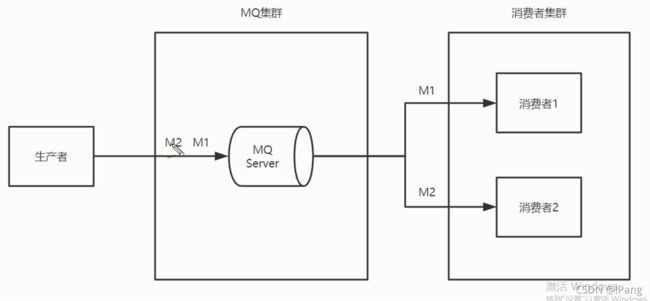
M1,M2发送到一个消息队列里面,这个模型解决了顺序到达,消费方能不能保证让M1先去,然后M2后取呢?
1.可以保证消息的顺序到达MQ.
2.消费方如果出现网络延迟问题,不能严格保证消息的顺序消费.
pass
模型3 : M1,M2按照先后顺序发送到1台Server,被两个消费者分别消费.
M1,M2顺序到达MQServer,让消费者1消费M1,消费者2先别取,等消费成功之后给了MQ一个ACK确认,告诉MQ处理完成,再让消费者2去取M2进行消费,完成之后再进行ACK确认.
1.可以保证消息顺序到达MQ.
2.M1消费完毕并成功应答后,MQServer在发送M2.
实现复杂,不推荐.!
消费者1还要管消费者2的事,1没消费完2不能消费.
pass
模型4 : 生产者 : MQServer : 消费者 = 1 : 1 : 1.
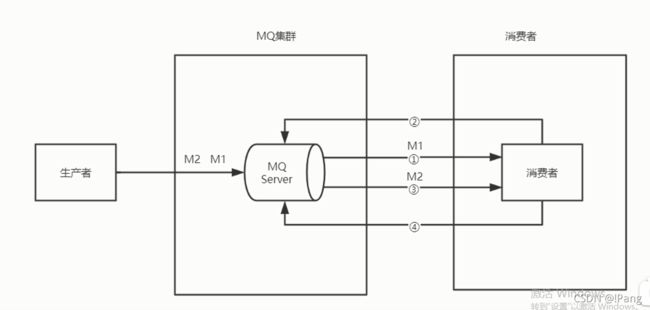
1.可以保证消息顺序到达MQ.
2.可以保证消息顺序消费.
全局的顺序霞飞,并不常见!
1.吞吐量下降,没有了集群.
2.容错率降低.
pass
模型5 : 局部顺序消费(常用)
1.生产者根据消息id将一组消息发送到一个队列中.
2.多个消费者同时获取队列中的消息进行消费.
3.MQ使用分段锁保证单个队列中的有序消费.
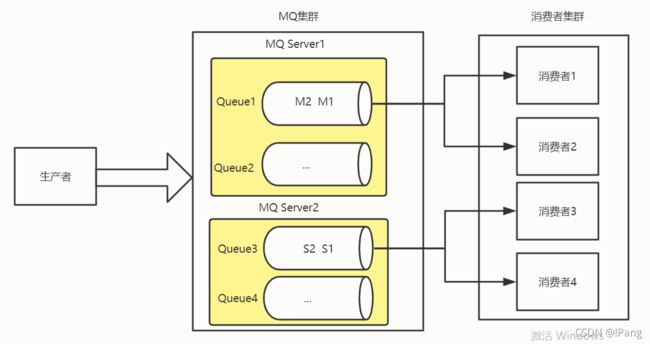 我们现在只要保证,张三和李四各自产生的三条消息的顺序一致就可以了.
我们现在只要保证,张三和李四各自产生的三条消息的顺序一致就可以了.
张三李四可以同时消费,M系和S系的消息不追求顺序性,这种场景被称为局部性的顺序消费.
局部性的顺序消费如何处理?
让张三产生订单之后的数据根据id放到一个队列里面,李四的订单数据放到另一个队列,由于队列本身就是天然的先进先出特性,就保证了顺序性.
消费者去消费的时候,让多个消费者并发消费,提高了消息费的效率和吞吐量.两个消费者都可以去队列1进行消费.这样无法保证消费者之间的顺序,所以MQ提供了解决方案,分段锁.它会把队列锁住,当消费者1拿了M1之后没有处理完,就不对MQ进行ACK确认,如果没有去人Q1就被锁住可,M2就不能被获取,直到M1成功消费并提交了ACK确认了才会释放锁.消费者2蔡能拿到M2进行消费,这样就可以保证了顺序性,还保证了消息消费的吞吐量.
精髓在分段锁,分段锁只锁住了Q1,给Q2发消息不受影响.所以分段锁就保证了队列同步性顺序性还不会影响性能.
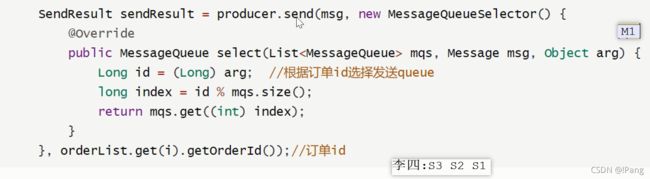
根据订单id可以去选择的队列,如果订单一样队列也是一个队列.
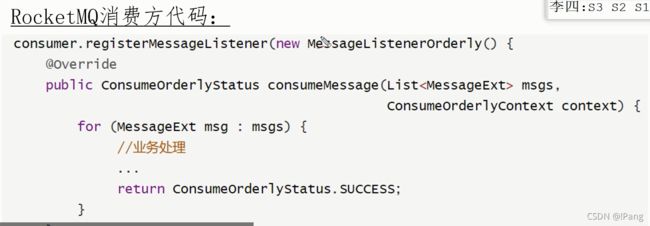
消费者消费通常根据监听机制.
匿名内部类中内置了分段锁,用了MessageListenerOrderly内部类就会自动去加锁保证顺序性.
总结 : 如何保证顺序消费?
1.全局顺序消息,生产者:MQ:消费者=1:1:1(不常用)
2.局部顺序消费(常用)
1.生产者将一组消息发送到1个队列中.
2.多个消费者并行对消息进行消费.
3.队列通过分段锁保证消息的消费顺序性.
8.大量消息堆积怎么处理?
消息堆积的原因?
消费方出现了故障导致消息没有被正常消费.
1.网路故障.
2.消费方消费消息后没有给MQServer正常应答.

1.网络断了没人消费,消息源源不断堆积在MQ.
2.消费方消费了,忘记ACK确认消息,所以MQ没有删除消费过消息,造成消息堆积.
消息堆积的处理方案
1.检查并修复消费方的正常消费速度.
2.将堆积消息转存到容量更大的MQ集群中.
3.增加多个消费者节点并行消费堆积消息.
4.消费完毕后,恢复原始架构.
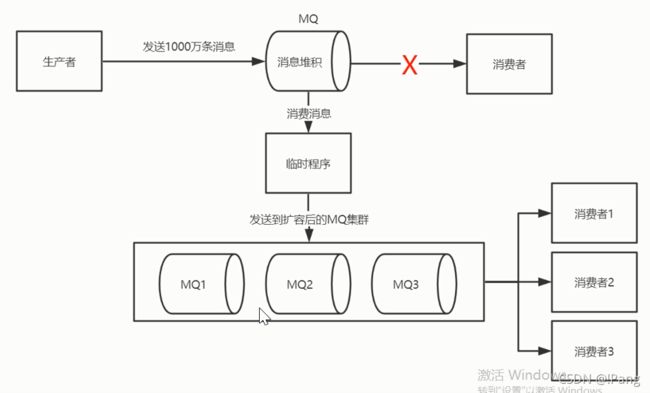
先检查消费方看什么原因导致的一致没有进行消费,恢复网络之后消息堆积还是有的.为了快速的把堆积消息处理完,把消息转存到更多的队列中去,提高消息处理的吞吐量.怎么做呢?可以写一个临时的程序作为消费方,取出堆积在MQ中的消息,再把消息发送给更多的MQ集群当中.让消息吞吐量提高,增加更多的消费节点并发处理,这样可以快速的把堆积的消息处理完,处理完之后就可以回复到原始架构.
9.消息过期怎么处理?
消息过期的原因?
消息设置了过期时间,如果超时还没被消费,则视为过期消息.
过期消息可以转存到死信队列.
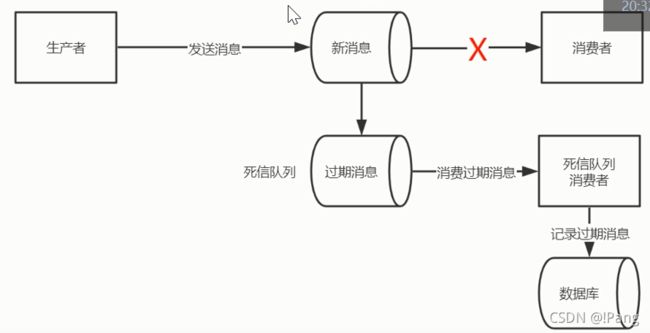 没配置死信队列,消息会被直接删除.
没配置死信队列,消息会被直接删除.
这么做的目的是保证MQ消息不积压.
消息被直接删除并不好,因为业务没有正常的处理,通常会启动一个死信队列,死信队列会去接收没有被正常消费的消息.
流程:
1.过期消息进入到死信队列.
2.启动专门的消费者消费死信队里中中的消息,并写入到数据库并记录日志.
3.查询数据库消息日志,重新发送消息到MQ.
开启死信队列的消费节点,去把死信队列的消息进行消费,存到数据库之后,再重复查询出来扔到正常队列里等待消费即可.