Hadoop and Sort Benchmark
Sort Benchmark是一个专门从事排序基准评估的非盈利机构,该机构每年都会举办一次排序基准评估比赛,很多公司和学术机构都会带着他们最新的研究成果来参加这个比赛,以评估他们的研究成果。在2007之前,该机构的排序基准评估比赛的主办和管理主要都是由Jim Gray来负责,他是数据库界的超级牛人、1998年图灵奖获得者。但不幸的是,JimGray在
- ChrisNyberg of Ordinal Technology
- MehulShah of Hewlett-Packard
- NagaGovindaraju of Microsoft
Sort Benchmark有很多种形式,到目前为止,总共有6种:GraySort、PennySort、MinuteSort、JouleSort、TeraByte Sort、Datamation Sort。随着机器配置和排序程序的性能提升,TeraByte Sort、Datamation Sort目前已经弃用了。不管是哪一种Sort Benchmark形式,都必须遵守下面的几条公共规则:
- 排序的输入和输出文件必须放在辅助存储设备(如硬盘)上。
- 不能使用裸磁盘(Raw disk,未经格式化的磁盘),因为IO子系统也要被测试。
- 鼓励使用分散连结(striping)的文件或设备(RAID 0)以获得带宽,如果使用了分散连结的文件,那这些连结文件必须来自一个已排序的文件。
- 排序必须要生成输出文件。
- 总耗时包括运行排序程序的时间。
- 排序输入记录长度必须是100字节,并且前10个字节是一个随机的Key。
- 使用gensort记录生成器来生成输入记录。
- 排序输出文件必须要通过Key顺序和校验码的验证。
对于每一种排序测试基准方式,都有两种类别可供选择,分别是:Indy和Daytona。Indy很像印第赛车那样,它可以自定义排序评测标准,如固定的key和记录大小,以及随机的、高密度的和均匀分布的输入keys。简单点说就是,定制不通用的排序基准。Daytona要的则是通用目的的排序,而且还有更多的评测要求:
- 除了长度是100字节,并且前10个字节是一个随机的Key的记录外,还能排序其它类型的记录和key。
- 当排序其它类型的key和记录时,性能不能有大的下降。
- 不能过度依赖排序输入数据中key值的均匀和随机分布状况。如果排序数据被分成了多个文件(比如在集群排序中),排序不能依赖任何先前确定的分区边界。分区边界必须是通过对输入数据进行抽样而得知或在排序中得知。如果使用了抽样方法,报告中要解释它是如何工作的并注上耗费时间。相似的,keys的非均匀分布不能过度增加集群排序中的网络通信量。
- 不能覆盖或损坏输入文件。
- 系统要能持续运行1个小时不出错,这个要求针对于GraySort和MinuteSort。
- 对于输入文件和输出文件要使用相同的副本数,这在GraySort中很重要。举个例子,如果输入文件在集群文件系统中并且副本数为3,那参赛者可以利用副本来提升性能。但是,输出文件的副本数也必须是3。
这里,我主要讲一下Yahoo利用Hadoop参加过的GraySort、MinuteSort和TeraByte Sort,其它的各位看官就要到官方主页去细看咯。首先是TeraByte Sort,它的评测标准就是看你排序1TB的数据要花多少时间。在2008年5月,Yahoo利用Hadoop赢得了TeraByte Sort的第一名,耗时209秒(3.48分),比上一年的的纪录保持者保持的297秒快了将近90秒。当时Hadoop的集群配置为910 个节点 x (4 dual-core processors, 4 disks,8 GB memory) ,版本为打上HADOOP-3443和HADOOP-3446补丁的pre-0.18。注意,下图只是配图,是09年的数据,非比赛数据,其它图同样。

图1 TeraByte Sort
由于实质上TeraByte Sort跟MinuteSort方式差不多,于是09年开始官方就把TeraByteSort给弃用了。MinuteSort,顾名思义,就是看你在一分钟内能排序多大的数据。Hadoop以500GB/min的成绩拿下了2009年MinuteSort的冠军,用了1406个节点 x (2 Quadcore Xeons, 8 GBmemory, 4 SATA)。

图2 MinuteSort
GraySort,这个咋一看,不像前两个能直接看出点名堂来。其实这是为纪念SortBenchmark的发起者Jim Gray而起的名字,它的目标就是评测大规模排序的性能。GraySort的评测单位是TB/min,这个来源得追溯到1994年MinuteSort评测基准第一次被构想出来的时候,当时Jim's的评测目标就是一分钟内能排序1TB。GraySort没有最大数据约束,但是有最小数据约束,最小必须是100TB。这样做的目的是为了确保数据集不能全被放在内存上,随着时间的推移,这个最小值会逐渐提升。Hadoop的超大规模计算能力在GraySort中得以充分体现,以0.578TB/min的成绩一举拿下2009年的GraySort冠军,用了3452个节点 x (2 Quadcore Xeons, 8 GBmemory, 4 SATA)。
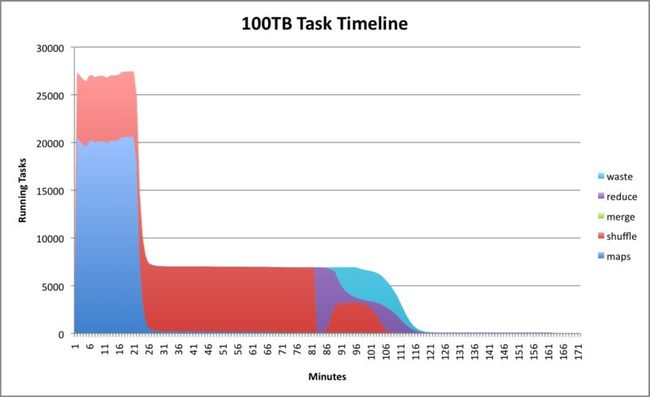
图3 GraySort(1)
由于GraySort对最大数据没有约束,Yahoo还测试了1PB的数据,平均速度为1.03TB/min!
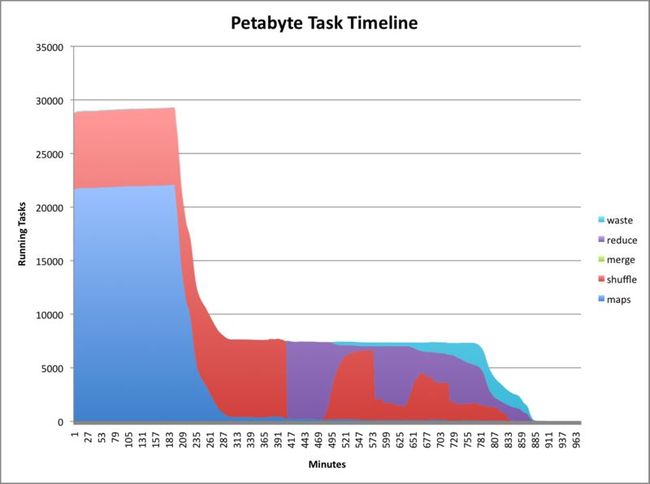
图4 GraySort(2)
到此,各位对Sort Benchmark以及Hadoop的超大规模计算能力应该已经有一个较清晰的了解了。下去,有时间会把Yahoo最新的GraySort程序分析下(其实早期的已经看得差不多了,复杂的不多,主要就是分区那里用到了一个Trie树。不过目前最新的用新MRapi写的相比以前变化了不少,有时间再把它罗列一下)。
