tensorflow2.0 基于LSTM模型的文本生成
春水碧于天,画船听雨眠
基于LSTM模型的唐诗文本生成
-
- 实验基本要求
- 实验背景
- 实验数据下载
- LSTM模型分析
- 实验过程
-
- 文本预处理
- 编解码模型
- LSTM模型设置
- 实验代码
- 实验结果
- 总结
- 致谢
实验基本要求
tensorflow2.0及以上版本
实验背景
在自然语言处理(NLP)领域,大多对话机器人的对话形成都会采用基于语料库和深度神经网络生成模型进行回答和交流。很多企业成功落地了许多产品,例如,微软小冰、Siri、谷歌翻译、淘宝智能客服系统等。文本生成的商业价值不断提升,用户的要求也不断提高,因此文本生成的研究意义重大。此外,在一些自动文本摘要和文本简化的地方,也会采用神经网络生成一段可读性强而且易于常人理解的文本。目前主流的文本生成的神经网络大多是基于循环神经网络的编码器-解码器框架,通过循环神经网络学习到序列的前后关系,能够生成一些较为通顺的文本。
本实验采用长短期记忆单元(LSTM)模型,对唐诗语句序列进行学习,得到一个简单的唐诗文本模型。整体的过程如下框图2.1所示,首先对原始数据的获取,可以提供本项目的爬虫或者自行下载的办法,获取得到想要的原始数据集。其次,想要对数据集的句子进行分词,得到词语字典。然后,数据总存在着不需要的其他字符,想要对其进行标准化,对于对英文的处理时,还需要将单词的格式统一,例如单复数形式的统一。由于计算机不能处理文字信息,在得到标准化数据之后,想要对数据进行特征提取,转换成向量的形式。比较经典的转换方式有独热(one_hot),词向量(word2vec)等方式。然后,搭建神经网络模型并且对其进行训练和测试。

实验数据下载
https://download.csdn.net/download/MARSHCW/13104886
LSTM模型分析
长短记忆单元模型 (LSTM模型)是一种改进型的RNN模型。由于RNN在计算前后变量想要累乘之前变量的梯度,所以在时序上梯度不断相乘,如果梯度值小于1,那么在累乘之后会导致梯度消失和梯度爆炸等问题。鉴于此,引入选择性记忆机制,它能够有选择性的记忆和忘却一些数据信息,学习到上下文的前后关系,二者的对比图如下2.2。

LSTM能够完成选择性记忆,是因为其引入了三个重要的门,分别是输入门、遗忘门、输出门。LSTM的一些重要的参数如下:
(1) 输入门it ,wi是待训练的参数矩阵,σ表示sigmoid函数,使门限的范围在0到1之间。
(2) 遗忘门ft ,记忆门是把上次的状态ht-1和这一次的输入xt进行比较,通过gate输出0到1的数值,其中1表示记住,0表示遗忘。
(3) 短期记忆ht ,其中ot表示需要记忆的比例,表示输出门。
(4) 长期记忆Ct,它是由两部分组成的,一部分是t时刻前的需要记忆信息和当前需要记忆的信息。
(5) 当前新知识 , 表示系统归纳出的新知识。
(6) 输出门ot,控制输出的比率。
LSTM在对序列进行记忆时,其机理比较复杂,整体的过程可以描述为以下几步:首先模型归纳出当前的新知识,其中一部分来自于之前神经网络中的短期记忆和现在输入的数据,通过二者则可以得到当前的新知识。第二步,计算遗忘门和输入门,是对数据进行有选择的记忆的关键。第三步,由遗忘门和输入门计算长期记忆Ct,并且根据输出门和长期记忆计算当前时刻的短期记忆,用于下一步的新知识计算。将这几步进行迭代,则可以得到整体的LSTM模型。
实验过程
文本预处理
在对词语编码之前,需要对原始数据集进行预处理,除去影响编码和低频的词汇。首先,需要把每一首诗歌提取出来,把其标题和不合标准的特殊字符去掉,比如书名号等。其次,分割每一首古诗,存放入列表中,方便在编码阶段进行编码。然后,将每一首古诗进行分词,将得到的词语存入列表。再对列表中的数据排序和统计每个词出现的次数,剔除出现频率较小的词语,按照出现次数由高到低排序。因为在古诗生成需要设置起始字符和停止字符,以及应对不能够识别的字符等情况,所以,需要在词表中加入特殊词。然后,因为所处理的古诗由有三万多首,所以需要将列表转换成能够高效索引的词典。最后,需要将每个词语进行编码,将文字转换成计算机可以处理的向量。这里采用了独热(one-hot)的编码方式,具体的流程如下图2.3所示。
图 2.3 数据预处理流程

编解码模型
编码器主要任务是对词语集合机型编码表示,将文字转换成向量的形式,先对文本数值化,用文本中词的字典序号来初步表示每一个词,然后经过嵌入层对文本进行编码表示。
解码器主要功能是将已经生成的数字序列转换成文本,模型起始时是起始字符[‘CLS’],在进行解码时需要去除。文本起始字符实在数据预处理时指定的,随着文本的不断生成,新生此不断连接到已生成的序列中,形成需要的文本格式的数字序列。这时,需要一个结束标志,本项目中设置的结束标志是[‘SEP’],在译码时,该标志位不会被显示。
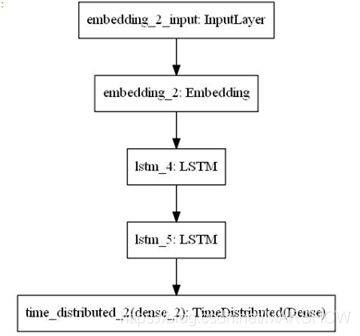
LSTM模型设置
唐诗的格式大都比较统一,能够采用LSTM学习到比较好的参数,进而生成较为通顺的唐诗文本。
文本生成模型如下图所示
实验代码
#-*- coding:utf-8 -*-
#desc:唐诗生成
import collections
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
import matplotlib.image as mpimg # mpimg 用于读取图片
import os
#分词器,完成编码译码转换
class Tokenizer:
"""
分词器
"""
def __init__(self, token_dict):
# 词->编号的映射
self.token_dict = token_dict
# 编号->词的映射
self.token_dict_rev = {value: key for key, value in self.token_dict.items()}
# 词汇表大小
self.vocab_size = len(self.token_dict)
def id_to_token(self, token_id):
"""
给定一个编号,查找词汇表中对应的词
:param token_id: 带查找词的编号
:return: 编号对应的词
"""
return self.token_dict_rev[token_id]
def token_to_id(self, token):
"""
给定一个词,查找它在词汇表中的编号
未找到则返回低频词[UNK]的编号
:param token: 带查找编号的词
:return: 词的编号
"""
return self.token_dict.get(token, self.token_dict['[UNK]'])
def encode(self, tokens):
"""
给定一个字符串s,在头尾分别加上标记开始和结束的特殊字符,并将它转成对应的编号序列
:param tokens: 待编码字符串
:return: 编号序列
"""
# 加上开始标记
token_ids = [self.token_to_id('[CLS]'), ]
# 加入字符串编号序列
for token in tokens:
token_ids.append(self.token_to_id(token))
# 加上结束标记
token_ids.append(self.token_to_id('[SEP]'))
return token_ids
def decode(self, token_ids):
"""
给定一个编号序列,将它解码成字符串
:param token_ids: 待解码的编号序列
:return: 解码出的字符串
"""
# 起止标记字符特殊处理
spec_tokens = {'[CLS]', '[SEP]'}
# 保存解码出的字符的list
tokens = []
for token_id in token_ids:
token = self.id_to_token(token_id)
if token in spec_tokens:
continue
tokens.append(token)
# 拼接字符串
return ''.join(tokens)
#-------------------------------数据预处理---------------------------#
def process_text(file_name='poetry.txt'):
poetry_file ='poetry.txt' #诗集导入
# 禁用词,包含如下字符的唐诗将被忽略
disallow_words = ['(', ')', '(', ')', '__', '《', '》', '【', '】', '[', ']']
# 诗集
poetrys = []
with open(poetry_file, "r", encoding='utf-8',) as f:
for line in f.readlines():
try:
#line = [li.replace(':',':')for li in line]
title, content = line.strip().split(':')#把诗词的标题和诗词的内容提取出来
content = content.replace(' ','')
ignore_flag = False
for dis_word in disallow_words:
if dis_word in content:
ignore_flag = True
break
#print(ignore_flag)
if ignore_flag:
continue
if len(content) < 5 or len(content) > 80:
continue
#指定起始标志位,指定终止标志位
#content = '[' + content + ']'
#print(content)
poetrys.append(content)
except Exception as e:
pass
# 按诗的字数排序
poetrys = sorted(poetrys,key=lambda line: len(line))
print('唐诗总数: ', len(poetrys))
#----------- 统计每个字出现次数--------------
all_words = []
for poetry in poetrys:
all_words += [word for word in poetry]
counter = collections.Counter(all_words)
#最小频度:8
min_word_frequency = 8
words = [(token, count) for token, count in counter.items() if count >= min_word_frequency]
#排序
count_pairs = sorted(words, key=lambda x: -x[1])
#words, _ = zip(*count_pairs)
#words.append(' ')
words = [token for token,count in words]
# 取前多少个常用字
#words = words[:len(words)] + (' ',)
# 将特殊词和数据集中的词拼接起来
words = ['[PAD]', '[UNK]', '[CLS]', '[SEP]'] + words
# print(words)
# 每个字映射为一个数字ID:可以换成word2vec
word_num_map = dict(zip(words, range(len(words))))
#print(word_num_map)
# 使用新词典重新建立分词器
tokenizer = Tokenizer(word_num_map)
#print(tokenizer.vocab_size)
#数据混洗
np.random.shuffle(poetrys)
#print(word_num_map)
return poetrys,tokenizer,word_num_map
# 把诗转换为向量形式
#poem_to_num = lambda word: word_num_map.get(word, len(words))poetrys_vector = [ list(map(to_num, poetry)) for poetry in poetrys]
#poem2num = [list(map(lambda word:word_num_map.get(word,len(words)),p))for p in poetrys]
#[[314, 3199, 367, 1556, 26, 179, 680, 0, 3199, 41, 506, 40, 151, 4, 98, 1],
#[339, 3, 133, 31, 302, 653, 512, 0, 37, 148, 294, 25, 54, 833, 3, 1, 965, 1315, 377, 1700, 562, 21, 37, 0, 2, 1253, 21, 36, 264, 877, 809, 1]#....]
#print(poem2num)
#return poem2num,word_num_map,words
#poetrys,tokenizer,word_num_map = process_text()
#--------批量处理------------
#这里批量获取训练样本,并且把训练样本转换成特征值和目标值,并且清洗数据
def poetry_gen(tokenizer,poetrys,batch_size=64,rand=False):
#数据填充
def sequence_padding(poetrys, length=None, padding=None):
"""
将给定数据填充到相同长度
:param poetrys: 待填充数据
:param length: 填充后的长度,不传递此参数则使用data中的最大长度
:param padding: 用于填充的数据,不传递此参数则使用[PAD]的对应编号
:return: 填充后的数据
"""
# 计算填充长度
if length is None:
length = max(map(len, poetrys))
# 计算填充数据
if padding is None:
padding = tokenizer.token_to_id('[PAD]')
# 开始填充
outputs = []
for line in poetrys:
padding_length = length - len(line)
# 不足就进行填充
if padding_length > 0:
outputs.append(np.concatenate([line, [padding] * padding_length]))
# 超过就进行截断
else:
outputs.append(line[:length])
return np.array(outputs)
n_chunk = len(poetrys) // batch_size #迭代步长
def genrt(poetrys,rand=False):
n_len = len(poetrys)
# 是否随机混洗
if rand:
np.random.shuffle(poetrys)
# 迭代一个epoch,每次yield一个batch
for i in range(0,n_len,batch_size):
end = min(i + batch_size, n_len)
batch_data = []
# 逐一对古诗进行编码
for single_data in poetrys[i:end]:
batch_data.append(tokenizer.encode(single_data))
# 填充为相同长度
batch_data = sequence_padding(batch_data)
# yield x,y
yield batch_data[:, :-1], tf.one_hot(batch_data[:, 1:], tokenizer.vocab_size)
del batch_data
def for_fit(poetrys,rand=False):
"""
创建一个生成器,用于训练
"""
# 死循环,当数据训练一个epoch之后,重新迭代数据
while True:
# 利用生成器产生数据
yield from genrt(poetrys,rand)
return n_chunk,for_fit
# n_chunk,for_fit = poetry_gen(tokenizer,poetrys)
# for_fit(poetrys,True)
# 构建模型
def model_gen(word_num_map):
model = tf.keras.Sequential([
# 不定长度的输入
tf.keras.layers.Input((None,)),
# 词嵌入层
tf.keras.layers.Embedding(input_dim=tokenizer.vocab_size, output_dim=128),
# 第一个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 第二个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 对每一个时间点的输出都做softmax,预测下一个词的概率
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.vocab_size, activation='softmax')),
])
# 查看模型结构
model.summary()
# 配置优化器和损失函数
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.categorical_crossentropy)
return model
#model = model_gen(tokenizer)
def generate_random_poetry(tokenizer, model, s=''):
"""
随机生成一首诗
:param tokenizer: 分词器
:param model: 用于生成古诗的模型
:param s: 用于生成古诗的起始字符串,默认为空串
:return: 一个字符串,表示一首古诗
"""
# 将初始字符串转成token
token_ids = tokenizer.encode(s)
# 去掉结束标记[SEP]
token_ids = token_ids[:-1]
while len(token_ids) < 64:
# 进行预测,只保留第一个样例(我们输入的样例数只有1)的、最后一个token的预测的、不包含[PAD][UNK][CLS]的概率分布
output = model(np.array([token_ids, ], dtype=np.int32))
_probas = output.numpy()[0, -1, 3:]
del output
# print(_probas)
# 按照出现概率,对所有token倒序排列
p_args = _probas.argsort()[::-1][:100]
# 排列后的概率顺序
p = _probas[p_args]
# 先对概率归一
p = p / sum(p)
# 再按照预测出的概率,随机选择一个词作为预测结果
target_index = np.random.choice(len(p), p=p)
target = p_args[target_index] + 3
# 保存
token_ids.append(target)
if target == 3:
break
return tokenizer.decode(token_ids)
# model = load_model('best_model.h5')
# generate_random_poetry(tokenizer,model,'海')
#模型显示
def model_img(model):
'''
显示模型,以jpg格式显示
'''
path ='D:\WeChat\biancheng\exercise\py\tydpy\2-数据分析处理库pandas\nlp\tangshi\model.jpg'
if not os.path.isfile(path): #文件不存在
plot_model(model, to_file='model.jpg', show_shapes=True)
else:
plt.subplots(figsize=[12,8])
path ='./model.jpg'
img = mpimg.imread(path)
plt.imshow(img)
#模型评估
class Evaluate(tf.keras.callbacks.Callback):
"""
在每个epoch训练完成后,保留最优权重,并随机生成5首古诗展示
"""
def __init__(self):
super().__init__()
# 给loss赋一个较大的初始值
self.lowest = 1e10
def on_epoch_end(self, epoch, logs=None):
# 在每个epoch训练完成后调用
# 如果当前loss更低,就保存当前模型参数
if logs['loss'] <= self.lowest:
self.lowest = logs['loss']
path = './best_model.h5'
model.save(path)
# 随机生成几首古体诗测试,查看训练效果
print()#换行
for i in range(5):
print(generate_random_poetry(tokenizer, model))
def poetry_test():
poetrys,tokenizer,word_num_map = process_text()
# step1:创建数据集
#n_chunk,for_fit = poetry_gen(tokenizer,poetrys)
#step2:设置迭代次数
#TRAIN_EPOCHS = 3
#step3:开始训练
#model.fit_generator(for_fit(poetrys,True), steps_per_epoch=n_chunk, epochs=TRAIN_EPOCHS,callbacks=[Evaluate()])
#step4:test step模型读取
model = load_model('best_model.h5')
model_img(model)
#last step:预测展示
generate_random_poetry(tokenizer,model,'海')
if __name__=="__main__":
poetry_test()
实验结果
模型训练
由于项目采用的是CPU版本的tesnsorflow2.2来搭建LSTM框架,所以对运行环境的要求较高,设置的模型迭代训练4次。在训练的过程中,采用边训练边预测输出的方式。可以看到,损失函数在不断的下降,模型能够学到古诗的基本句式。在完成第二次训练之后,模型能够输出具有基本唐诗结构的文本。在最后还能够生成五言绝句和七言绝句,但是,在句意上还不够通顺,想要进一步的训练。具体的输出如下图所示。

模型测试
将训练好的模型保存在文件夹中,在想要生成唐诗的时候引入load_model()函数即可调用模型,可以使用该模型对输入的起始数据进行预测输出,即文本的生成。分组多次训练之后,调用模型,输入初始的字符[‘海’],模型的输出如下输出示例所示。可以看出:模型能够输出比较通顺的唐诗,而且在整体的诗歌格式完全拟合。
输入[‘海’]输出示例:
(1) 海叶何闲落,西山秋北赊。何人若寂上,山水上明年。
(2) 海柳红金里宿楼,不怜青下断魂人。还将马上书人是,千后东华二月山。
(3) 海景临城草,黄衣入气红。行来离草叶,不作远枝声。
总结
(1)对语义的理解不足,可以在后期增加网络层数或者采用语料库结合的方法;
(2)网络收敛慢,可以采用其他一些方法,提取特征向量加速收敛。
致谢
感谢诸君观看,如果感觉有用的话,点个赞吧!