《机器学习算法竞赛实战》整理 | 六、模型融合
目录
前言
6.1 构建多样性
6.1.1 特征多样性
6.1.2 样本多样性
6.1.3 模型多样性
6.2 训练过程融合
6.2.1 Bagging
6.2.2 Boosting
6.3 训练结果融合
6.3.1 加权法
(1)分类问题
(2)回归问题
(3)排序问题
6.3.2 Stacking 融合
6.3.3 Blending 融合
6.4 实战案例
6.5 思考练习
前言
本章将向大家介绍在算法竞赛中提分的关键步骤,这也是最后阶段的惯用方法,即模型融合(或者集成学习),通过结合不同子模型的长处进行模型融合,当然这是在理想状态下。
本章主要分为构建多样性、训练过程融合和训练结果融合三部分。
模型融合常常是竞赛取得胜利的关键,相比之下具有差异性的模型融合往往能给结果带来很大提升。了解的模型融合方法越多,最后取胜的概率就会越高。
本章从这三个部分介绍不同模型融合方法的应用场景,同时给出使用技巧和应用代码。
6.1 构建多样性
介绍三种模型融合中构建多样性的方式,分别是特征多样性、样本多样性和模型多样性。其中多样性是指子模型之间存在着差异,可以通过降低子模型融合的同质性来构建多样性,好的多样性有助于模型融合效果的提升。
6.1.1 特征多样性
构建多个有差异的特征集并分别建立模型,可使特征存在于不同的超空间(hyperspace),从而建立的多个模型有不同的泛化误差,最终模型融合时可以起到互补的效果。在竞赛中,队友之间的特征集往往是不一样的,在分数差异不大的情况下,直接进行模型融合基本会获得不错的收益。
另外,像随机森林中的max_features,XGBoost中的colsample_bytree 和LightGBM中的feature_fraction都是用来对训练集中的特征进行采样的,其实本质上就是构建特征的多样性。
6.1.2 样本多样性
样本多样性也是竞赛中常见的一种模型融合方式,这里的多样性主要来自不同的样本集。
具体做法是将数据集切分成多份,然后分别建立模型。我们知道很多树模型在训练的时候会进行采样(sampling),主要目的是防止过拟合,从而提升预测的准确性。
有时候将数据集切分成多份并不是随机进行的,而是根据具体的赛题数据进行切分,需要考虑如何切分可以构建最大限度的数据差异性,并用切分后的数据分别训练模型。
例如,在天池“全球城市计算AI挑战赛”中,竞赛训练集包含从2019年1月1日到1月25日共25天的地铁刷卡数据记录,要求预测1月26日每个地铁站点每十分钟的平均出入客流量(2019年1月26日是周六)。显然,工作日和周末的客流量分布具有很大差异,这时会面临一个问题,若只保留周末的数据进行训练,则会浪费掉很多数据;若一周的数据全部保留,则会对工作日的数据产生一定影响。这时候就可以尝试构建两组有差异性的样本分别训练模型,即整体数据保留为一组,周末数据为一组。当然,模型融合后的分数会有很大提升。
6.1.3 模型多样性
不同模型对数据的表达能力是不同的,比如FM能够学习到特征之间的交叉信息,并且记忆性较强;树模型可以很好地处理连续特征和离散特征(如LightGBM 和CatBoost),并且对异常值也具有很好的健壮性。把这两类在数据假设、表征能力方面有差异的模型融合起来肯定会达到一定的效果。
对于竞赛而言,传统的树模型(XGBoost,LightGBM、CatBoost)和神经网络都需要尝试一遍,然后将尝试过的模型作为具有差异性的模型融合在一起。
更多多样性的方法
还有很多其他构建多样性的方法,比如训练目标多样性、参数多样性和损失函数选择的多样性等,这些都能产生非常好的效果。
6.2 训练过程融合
模型融合的方式有两种,第一种是训练过程融合,比如我们了解到的随机森林和XGBoost,基于这两种模型在训练中构造多个决策树进行融合,这里的多个决策树可以看作多个弱学习器。其中随机森林通过Bagging的方式进行融合,XGBoost通过Boosting的方式进行融合。
6.2.1 Bagging
Bagging的思想很简单,即从训练集中有放回地取出数据(Bootstrapping),这些数据构成样本集,这也保证了训练集的规模不变,然后用样本集训练弱分类器。重复上述过程多次,取平均值或者采用投票机制得到模型融合的最终结果。上述流程的示意图如图6.1所示。

6.2.2 Boosting
Boosting的思想其实并不难理解,首先训练一个弱分类器,并把这个弱分类器分错类的样本记录下来,同时给予这个弱分类器一定的权重;然后建立一个新的弱分类器,新的弱分类器基于前面记录的错误样本进行训练,同样,我们也给予这个分类器一个权重。重复上面的过程,直到弱分类器的性能达到某一指标,例如当再建立的新弱分类器并不会使准确率显著提升时,就停止选代。最后,把这些弱分类器各自乘上相应的权重并全部加起来,就得到了最后的强分类器。其实,基于Boosting的算法是比较多的,有Adaboost、LightGBM、XGBoost和 CatBoost等。
6.3 训练结果融合
模型融合的第二种方式是训练结果融合,主要分为加权法、Stacking和Blending,这些方法都可以有效地提高模型的整体预测能力,在竞赛中也是参赛者必须要掌握的方法。
6.3.1 加权法
加权法对于一系列任务(比如分类和回归)和评价指标(如AUC,MSE 或 Logloss)都是很有效的,比如我们有10个算法模型并都预测到了结果,直接对这10个结果取平均值或者给予每个算法不同的权重,即得到了融合结果。加权法通常还能减少过拟合,因为每个模型的结果可能存在一定的噪声,加权法能够平滑噪声,提高模型的泛化性。
(1)分类问题
对于分类问题,需要注意不同分类器的输出结果范围一致,因为输出的预测结果可以是0/1值,也可以是介于0和1之间的概率。另外,投票法(Voting)也是一种特殊的加权法。
(2)回归问题
对于回归问题,使用加权法会非常简单。这里主要介绍算法平均和几何平均,那么为什么有两种选择呢,主要还是因为评价指标。
在2019腾讯广告算法大赛中,选择几何平均的效果远远好于选择算术平均,这是由于评分规则是平均绝对百分比误差(SMAPE),此时如果选择算术平均则会使模型融合的结果偏大,这不符合平均绝对百分比误差的直觉,越小的值对评分影响越大,算术平均会导致出现更大的误差,所以选择几何平均,能够使结果偏向小值。
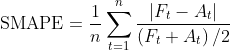
- 算术平均。基于算术平均数的集成方法在算法中是用得最多的,因为它不仅简单,而且基本每次使用该算法都有较大概率能获得很好的效果。
- 几何平均。根据很多参赛选手的分享,基于几何平均数的加权法在算法中使用得还不是很多,但在实际情况中,有时候基于几何平均数的模型融合效果要稍好于基于算术平均数的效果。?
(3)排序问题
一般推荐问题中的主要任务是对推荐结果进行排序,常见的评价指标有mAP(mean Average Precision),NDCG(Normalized Discounted Cumulative Gain),MRR(Mean Reciprocal Rank)和AUC,这里主要介绍MRR和AUC。
- MRR
给定推荐结果q,如果q在推荐序列中的位置是r,那么MRR(q)就是1/r。可以看出,如果向用户推荐的产品在推荐序列中命中,那么命中的位置越靠前,得分也就越高。显然,排序结果在前在后的重要性是不一样的,因此我们不仅要进行加权融合,还需要让结果偏向小值。这时候就要对结果进行转换,然后再用加权法进行融合,一般而言使用的转换方式是log变换。
其基本思路如下。
首先,输人三个预测结果文件,每个预测结果文件都包含M条记录,每条记录各对应N个预测结果,最终输出三个预测结果文件的整合结果。内部的具体细节可以分为以下两步。
第一步:统计三个预测结果文件中记录的所有推荐商品(共N个商品)出现的位置,例如商品A,在第一份文件中的推荐位置是1,在第二个文件的推荐位置是3,在第三个文件中未出现,此时我们计算商品A的得分为log1+log3+log(N+1),此处我们用N+1来表示未出现,即在N个推荐商品中是找不到商品A的,所以只能是N+1。
第二步:对每条记录中的商品按计算得分由小到大排序,取前N个作为这条记录的最终推荐结果。
- AUC
AUC作为排序指标,一般使用排序均值的融合思路,使用相对顺序来代替原先的概率值。很多以AUC为指标的比赛均取得了非常不错的成绩,如下两步为一种使用过程。
第一步:对每个分类器中分类的概率进行排序,然后用每个样本排序之后得到的排名值(rank)作为新的结果。
第二步:对每个分类器的排名值求算术平均值作为最终结果。
6.3.2 Stacking 融合
使用加权法进行融合虽然简单,但需要人工来确定权重,因此可以考虑更加智能的方式,通过新的模型来学习每个分类器的权重。这里我们假设有两层分类器,如果在第一层中某个特定的基分类器错误地学习了特征空间的某个区域,则这种错误的学习行为可能会被第二层分类器检测到,这与其他分类器的学习行为一样,可以纠正不恰当的训练。上述过程便是Stacking融合的基本思想。
这里需要注意两点:第一,构建的新模型一般是简单模型,比如逻辑回归这样的线性模型;第二,使用多个模型进行Stacking融合会有比较好的结果。
Stacking融合使用基模型的预测结果作为第二层模型的输人。然而,我们不能简单地使用完整的训练集数据来训练基模型,这会产生基分类器在预测时就已经“看到”测试集的风险,因此在提供预测结果时出现过度拟合问题。所以我们应该使用Out-of-Fold的方式进行预测,也就是通过K折交叉验证的方式来预测结果。这里我们将Stacking融合分为训练阶段和测试阶段两部分,将并以流程图的形式展示每部分的具体操作。如图6.2所示为训练阶段。

特征加权的线性堆叠,可参考相应论文“Feature-Weighted Linear Stacking two layer stacking",其实就是对传统的Stacking融合方法在深度上进行扩展。通过传统的Stacking融合方法得到概率值,再将此值与基础特征集进行拼接,重新组成新的特征集,进行新一轮训练。
6.3.3 Blending 融合
不同于Stacking融合使用K折交叉验证方式得到预测结果,Blending融合是建立一个Holdout集,将不相交的数据集用于不同层的训练,这样可以在很大程度上降低过拟合的风险。
假设构造两层Blending,训练集等分为两部分(train_one和train_two),测试集为test。第一层用train_one训练多个模型,将train_two和test的预测结果合并到原始特征集合中,作为第二层的特征集。第二层用train_two的特征集和标签训练新的模型,然后对test预测得到最终的融合结果。
6.4 实战案例
以stacking为例。选择ExtraTreesRegressor、RandomForestRegressor、Ridge、Lasso作为基学习器,Ridge为最终分类器。
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Ridge, Lasso
from math import sqrt
# 依然采用5折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=2020) 然后构建一个sklearn中模型的功能类,初始化参数然后训练和预测。这段代码可复用性很高,建议完善、储存。
class SklearnWrapper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def train(self, x_train, y_train):
self.clf.fit(x_train, y_train)
def predict(self, x):
return self.clf.predict(x)封装交叉验证函数。可复用性也很高。
def get_oof(clf):
oof_train = np.zeros((x_train.shape[0],))
oof_test = np.zeros((x_test.shape[0],))
oof_test_skf = np.empty((5, x_test.shape[0]))
for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)):
trn_x, trn_y, val_x, val_y = x_train.iloc[train_index], y_train[train_index],\
x_train.iloc[valid_index], y_train[valid_index]
clf.train(trn_x, trn_y)
oof_train[valid_index] = clf.predict(val_x)
oof_test_skf[i, :] = clf.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)接下来是基分类器训练和预测的部分代码,可预测四个模型的验证集结果和测试集结果。并辅助最后一步的stacking融合操作:
et_params = {
'n_estimators': 100,
'max_features': 0.5,
'max_depth': 12,
'min_samples_leaf': 2,
}
rf_params = {
'n_estimators': 100,
'max_features': 0.2,
'max_depth': 12,
'min_samples_leaf': 2,
}
rd_params={'alpha': 10}
ls_params={'alpha': 0.005}
et = SklearnWrapper(clf=ExtraTreesRegressor, seed=2020, params=et_params)
rf = SklearnWrapper(clf=RandomForestRegressor, seed=2020, params=rf_params)
rd = SklearnWrapper(clf=Ridge, seed=2020, params=rd_params)
ls = SklearnWrapper(clf=Lasso, seed=2020, params=ls_params)
et_oof_train, et_oof_test = get_oof(et)
rf_oof_train, rf_oof_test = get_oof(rf)
rd_oof_train, rd_oof_test = get_oof(rd)
ls_oof_train, ls_oof_test = get_oof(ls)最后就是tacking部分,使用ridge模型。
def stack_model(oof_1, oof_2, oof_3, oof_4, predictions_1, predictions_2, predictions_3, predictions_4, y):
train_stack = np.hstack([oof_1, oof_2, oof_3, oof_4])
test_stack = np.hstack([predictions_1, predictions_2, predictions_3, predictions_4])
oof = np.zeros((train_stack.shape[0],))
predictions = np.zeros((test_stack.shape[0],))
scores = []
for fold_, (trn_idx, val_idx) in enumerate(kf.split(train_stack, y)):
trn_data, trn_y = train_stack[trn_idx], y[trn_idx]
val_data, val_y = train_stack[val_idx], y[val_idx]
clf = Ridge(random_state=2020)
clf.fit(trn_data, trn_y)
oof[val_idx] = clf.predict(val_data)
predictions += clf.predict(test_stack) / 5
score_single = sqrt(mean_squared_error(val_y, oof[val_idx]))
scores.append(score_single)
print(f'{fold_+1}/{5}', score_single)
print('mean: ',np.mean(scores))
return oof, predictions
oof_stack , predictions_stack = stack_model(et_oof_train, rf_oof_train, rd_oof_train, ls_oof_train, \
et_oof_test, rf_oof_test, rd_oof_test, ls_oof_test, y_train)对比最终效果,stacking融合后为0.13157,基分类器最优的为0.13677,提升五个千分点,说明有一定效果。普通的加权平均效果差一些。
6.5 思考练习
1.还有很多构建多样性的方法,比如训练目标多样性、参数多样性和损失函数的选择等,都能产生非常好的效果,请对更多方法进行梳理归纳。
2.直觉上Stacking融合都能带来很好的收益,可为什么有时候Stacking融合之后的效果会变差,是基模型选择的问题,还是层数不够,请分析有哪些因素会影响最终融合结果。
3.尝试搭建Stacking融合的框架,并使其可复用,便于参赛者在竞赛中灵活调用。