【机器学习】决策树案例三:利用决策树进行泰坦尼克号事故人员存活分类预测
利用决策树进行泰坦尼克号事故人员存活分类预测
- 3 利用决策树进行泰坦尼克号事故人员存活分类预测
-
- 3.1 导入模块与加载数据
- 3.2 特征工程
- 3.3 划分数据
- 3.4 模型创建与应用
- 3.5 模型可视化
- 3.6 参数自动搜索
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/122048988(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
3 利用决策树进行泰坦尼克号事故人员存活分类预测
3.1 导入模块与加载数据
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
data= pd.read_csv('../data/data_titanic.csv',index_col=0)
data.head()
输出结果如下。
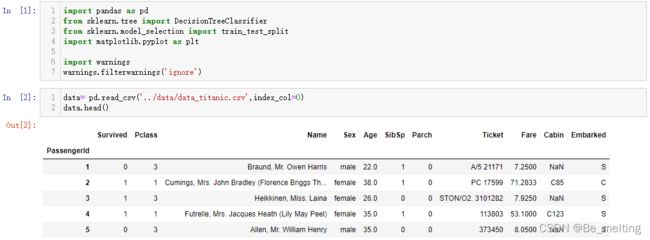
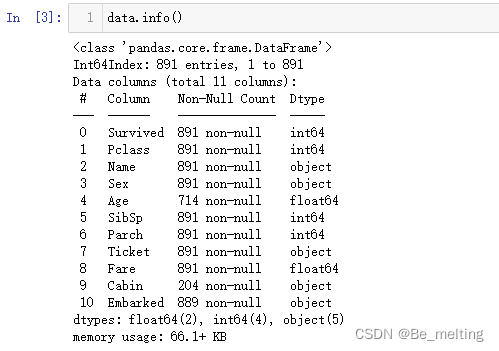
关于泰坦尼克号事故分析的案例已经在前面的数据分析实战部分有着详细地介绍,这里主要是进行决策树模型的分类预测,还是像之前案例操作一样,通过info()对所有的字段信息进行查看。
3.2 特征工程
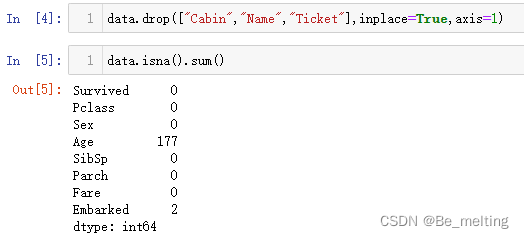
部分字段是存在着缺失,还有部分字段属于是字符串数据类型需要进行编码化处理。首先处理的是无关字段和数据缺失量较多的字段,代码如下。
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)
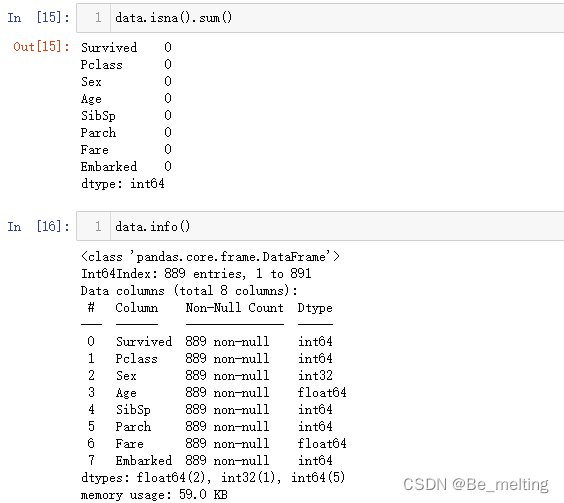
data.isna().sum()
输出结果如下。Cabin字段中是缺失值达到了一半以上;Name属于文本数据,虽然没有缺失值但是人员姓名基本上和事故结果没有联系;最后就是Ticket字段,这部分是票的单号,也是和事故结果无果的字段。
删除部分字段后,剩下字段中还是有缺失值,需要进行缺失值的处理。针对Age字段,采用均值进行填充,Embarked字段只有两个缺失值,直接进行删除即可,代码操作如下。
data["Age"] = data["Age"].fillna(data["Age"].mean())
data = data.dropna()
data.isna().sum()
输出结果如下,结果核实没有缺失值。

再次调用info()方法查看各字段的信息,输出结果如下。
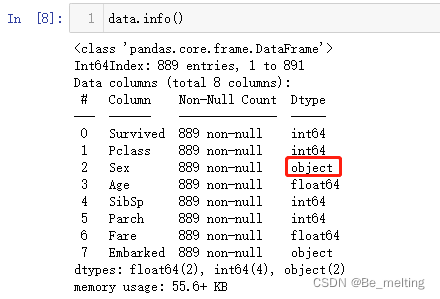
对于Sex字段还是属于字符串数据类型,需要进行编码化处理,代码如下。
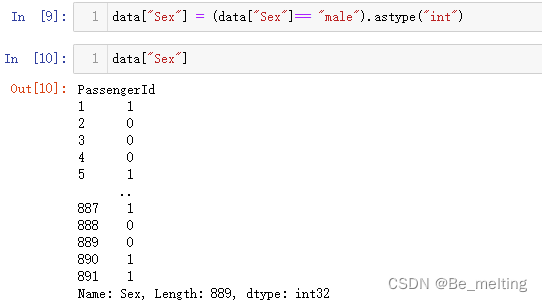
data["Sex"] = (data["Sex"]== "male").astype("int")
data["Sex"]
输出结果如下。除了上面的操作外,也可以使用apply的方式进行lambda表达式的判断,属于常用的操作。
除了Sex外,还有一个字段也是字符串数据类型,就是Embarked字段,表示上船的地点。
data["Embarked"].unique().tolist()
输出结果如下。Sex字段是二分类数据,对于多分类的字段的数据处理就是另外一种方式。

采用唯一值在列表中的坐标对多分类中的数据进行编码,代码操作如下。
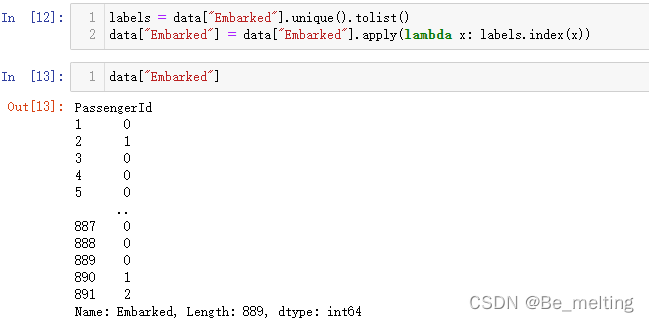
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
data["Embarked"]
输出结果如下。对于多分类数据的编码,常用的操作也就是按照唯一值进行对应索引的编号。除此之外,也可以使用之前get_dummpies()方法进行多分类编码。
数据清洗完毕后,再次查看数据,输出结果如下。

核实字段的缺失值和各字段的数据类型,代码及输出结果如下,核实数据无误。
3.3 划分数据
首先进行特征数据和标签数据的划分,代码如下。
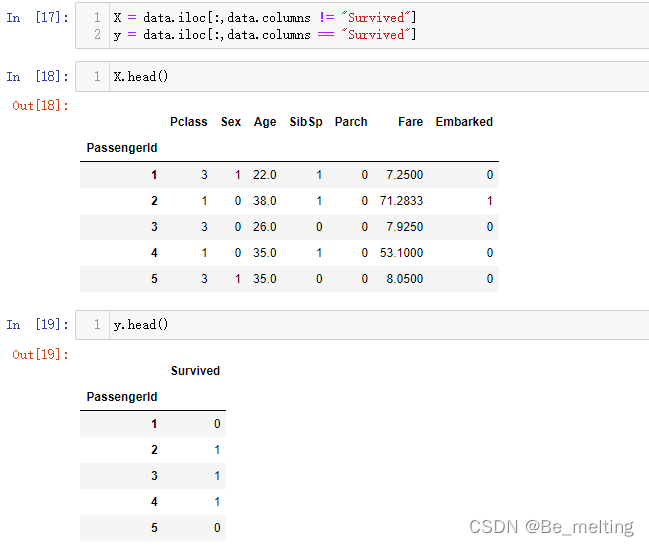
X = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
X.head()
y.head()
输出结果如下。
接着进行训练集和测试集数据划分,代码如下。
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.25)
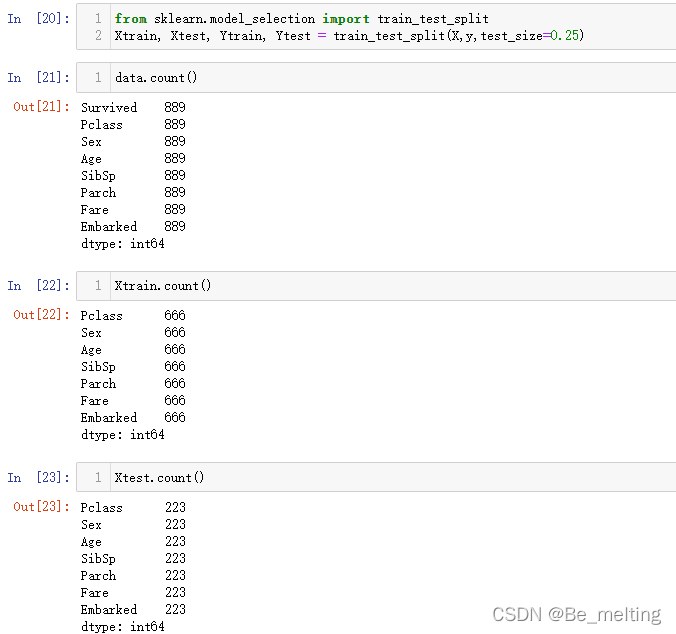
data.count()
Xtrain.count()
Xtest.count()
输出结果如下。测试数据量和训练数据量总和与原数据集数据量一致。
3.4 模型创建与应用
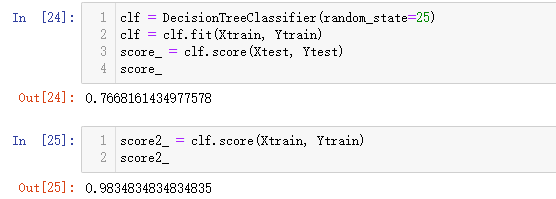
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score_ = clf.score(Xtest, Ytest)
score_
输出结果如下。模型在测试数据集上的得分为0.767,在训练数据集上的得分为0.983。
3.5 模型可视化
from sklearn import tree
data.columns
tree.export_graphviz(clf,out_file='titanic_lv6.dot',feature_names=['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare',
'Embarked'] ,label='all',rounded=True,filled=True)
输出结果如下。除了直接把对应的特征字段的名称全部放在列表中,也可以使用data.columns进行remove,去掉里面的标签字段即可,这里没有传入class_name参数,因为已经是处理好的数值字段,不用再进行设置。

用软件打开后,显示的结果如下。结果太繁杂,没有办法一下子理清头绪。

3.6 参数自动搜索
刚刚可视化的结果,把所有的可能性结果全部输出,这也是决策树模型的特点,只要是可以分,模型会把所有的分类全部分清楚。但是也就造成的决策树分支过多,因此需要指定最合适的树的分支数量。除此之外,对于批判标准,也可以进行不同类型的指定。
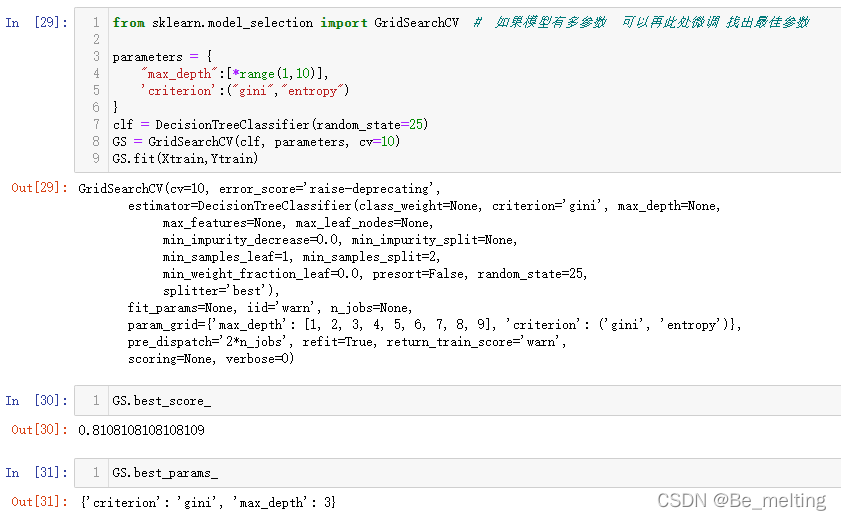
from sklearn.model_selection import GridSearchCV
parameters = {
"max_depth":[*range(1,10)],
'criterion':("gini","entropy")
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
GS.best_score_
GS.best_params_
输出结果如下。这里的经过网格搜索的方式确定参数,要比直接采用模型默认参数进行得分要高。需要注意由于之前是随机进行数据分割的,没有指定randon_state,所以模型每次跑出的结果会有差异,但是经过网格搜索后的结果要比默认的结果要得分好一些。
关于里面的cv=10这个参数,可以把说明文档调用出来,看一下详细的介绍,这里就是表示交叉验证的折数,默认不指定就是3折交叉验证。

交叉验证整个过程就可以进行下面的图例进行解答(假定100进行切分,以下只是切分的一种情况,进行4折交叉验证)。

常用的就是十折交叉验证:
- (1)英文名叫做10-fold cross-validation,用来测试算法准确性,是常用的测试方法(也就是这里的cv=10)。
- (2)将数据集分成十份,轮流 将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。
- (3)10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
那么还有一个问题:具体的划分数据的比例如何确定呢?一定是要二八开吗?这个是不确定的,需要根据数据量的大小来决定,8:2,7:3,9:1一般都是比较常见的(本案例是7.5:2.5),还有特殊的情况,比如数据量特别大的时候不需要一定要满足特定比例(假使数据有3000000条,10%就是30w了,可能由于机器的性能,这里可以指定取5w条数据进行测试就可以了)。