Kafka从入门到高级(一篇完结)
一、Kafka的概述
1.1 消息队列的简介
1.1.1 为什么要有消息队列
1. 当服务器在一次性处理大量的数据时,可能会造成服务器瘫痪,或者数据丢失这种情况
2. 如果将要处理的数据先维护在一个缓存系统中,然后再慢慢的处理,这样就可以避免上述情况。
3. 缓存系统就是用来存储消息的,该系统中至少要维护一个用来存储消息的先后顺序的队列(数据结构)
4. 为什么要使用队列(Queue,Deque,LinkedList),而不是其他的数据结构(Arraylist),因为消息要进行频繁的生产和消费(增删操作)
1.1.2 什么是消息队列
消息,就是指的网络中传输的数据,比如行为日志,文本、视频,音频、图片
队列,用来存储消息的容器,该容器是一个首尾相接的环形队列,规定的是FIFO
消息队列就是两者的结合,以及提供了各种API,和底层优化设计的应用程序(框架)
1.1.3 消息队列的分类
主要分为两大类,一类是点对点模式,一类是发布/订阅模式
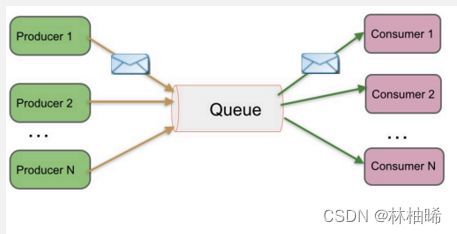
1)点对点模式
1. 可以叫 peer-to-peer ,也可以叫point-to-point
2. 角色分为:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
3. 发送者发送消息到队列中,该消息只能被一个接收者所接受,即使有多个接收者同时侦听到了这一条消息。
4. 该消息一旦被消费,则不存储在消息队列中,比如打电话
5. 支持异步/同步操作
2)发布/订阅模式
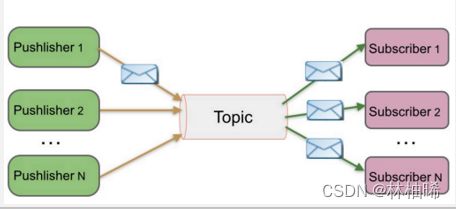
1. 叫 pub/sub模式
2. 角色分为:
-- 消息队列(Queue),
-- 发布者(Publisher、也叫producer)、
-- 订阅者(Subscriber,也叫consumer),
-- 主题(Topic) 用来将消息进行逻辑分类的
3. 一个消息可以被多个消费者消费,互不影响,比如我发布一个微博:关注我的人都能够看到。
4. 消费者在消费数据时,
--可以是push模式(消息队列主动将信息push给消费者),
--也可以使pull模式(消费者主动拉取消息对列中的消息),该模式的优点,消费者可以在自己处理消息的能力范围内,进行消费数据,
5. 支持异步/同步操作
1.1.4 消息队列的应用场景
1. 解耦: 消息系统可以作为中间件, 下游的软件和上游的软件无需了解彼此
2. 冗余: 消息可以持久化到磁盘上,或者做备份处理,避免数据丢失
3. 扩展: 消息队列提供了统计的生产者/消费者接口,
任何软件都可以调用生产者接口API,作为生产者
软件软件都可以调用消费者接口API,作为消费者
4. 销(削)峰能力:避免流量高峰期造成的系统瘫痪, 消息队列可以缓存这一时期的数据,慢慢处理
5. 可靠性: 消息队列中部分数据丢失,是有副本策略的,可以恢复数据
1.1.5 常见的消息队列系统
RabbitMQ
Redis : 本身是一个KV形式的NoSql数据,但是也有消息队列功能
ZeroMQ
ActiveMQ JMS
Kafka/Jafka : 高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理
MetaQ/RocketMQ
1.2 Kafka的简介
1.2.1 Kafka的官网介绍
apache官网:https://kafka.apache.org/documentation/#quickstart
中文官网:https://kafka.apachecn.org/
1.2.2 Kafka是什么
1. 是一个分布式、用于处理消息的发布/订阅消息系统
2. 是用scala语言编写的(scala编写另外一门比较火的框架是spark)
3. 具有以下特点:
-- 高吞吐量: 可以满足每秒百万级别消息的生产和消费——生产消费。
-- 持久化(保存在磁盘上一定时间,默认7天,区别于永久性)
-- 分布式:基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消费者转而使用其它的机器——整体
-- 健壮性:稳定,API接口的通用
4. 同时适应在线流处理和离线批处理
二、Kafka的架构与安装
2.1 Kafka的组织架构
2.1.1 架构图
2.1.2 Kafka架构中的核心概念
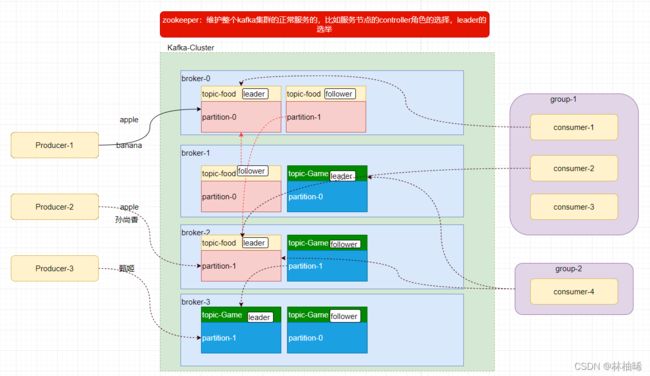
1)架构中的角色
--borker: kafka集群中各个节点的名称, 值得注意的是,每个broker都有一个唯一标识符,broker间的标识符不能重复。
--producer: 就是生产消息到Kafka集群的应用程序
--consumer: 就是从Kafka集群中消费消息的应用程序
--consumer-group:为了方便管理消费者,比如设置消费者的一些配置属性,引入了消费者组的概念,进而统一设置。
--zookeeper:作为协调Kafka集群工作的角色,比如多个broker谁是controller,broker的动态上下线。分区的副本冗余策略,leader的选举
2)工作机制中的概念
--message: 生产者产生的、消费者消费的数据,就是message,也可以称之为event。
--topic: 用于将message进行逻辑划分,即划分成不同的主题。比如有一些消息是关于美食的,一些是关于旅游的,一些是关于宠物等
--partition:是kafka集群中真正缓存数据的地方
1)本质是目录。
2)并发消费:每个主题可以有多个分区(分区多,消费者就可以并发处理消息)
3)可靠性:每个分区可以有多个副本,同一个分区的多个副本不能在同一个节点上。
--leader: 同一个分区的多个副本中,要有一个leader角色。
1)生产者向leader生产消息,
2)消费者从leader上消费消息,
3)follower从leader上同步消息
--follower: 同一个分区的多个副本中,除了leader角色,剩下的都是follower角色
作用:就是提高消息的安全可靠性,副本冗余
2.2 KAFKA的安装
2.2.1 安装步骤
步骤1)上传、解压、更名、配置环境变量
[root@qianfeng01 ~]# tar -zxvf kafka_2.11-1.1.1.tgz -C /usr/local/
[root@qianfeng01 ~]# cd /usr/local/
[root@qianfeng01 ~]# mv kafka_2.11-1.1.1/ kafka
[root@qianfeng01 ~]# vim /etc/profile
.....省略....
#kafka environment
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@qianfeng01 ~]# source /etc/profile
步骤2)修改server.properties
[root@qianfeng01 kafka]# cd config
[root@qianfeng01 config]# vim server.properties
# 每个节点的唯一标识符的配置
broker.id=0
# 设置消息的存储位置,如果有多个目录,可以用逗号隔开
log.dirs=/usr/local/kafka/data
# 设置zookeeper的集群地址,同时指定kafka在zookeeper上的各个节点的父znode
zookeeper.connect=qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka
# 下面属性可以改可不改
# 发送消息的缓存大小,100K
socket.send.buffer.bytes=102400
# 接收消息的缓存大小,100K
socket.receive.buffer.bytes=102400
# 服务端处理发送过来的数据的最大字节数 100M
socket.request.max.bytes=104857600
# 消息对应的文件保留的时间,默认使7天
log.retention.hours=168
# 消息对应的文件的最大字节数,1G
log.segment.bytes=1073741824
# 用来检查消息对应的文件是否过期或者是大于1G的时间周期,默认是300秒一检查
log.retention.check.interval.ms=300000
步骤3)同步到其他节点上
[root@qianfeng01 local]# scp -r kafka/ qianfeng02:/usr/local/
[root@qianfeng01 local]# scp -r kafka/ qianfeng03:/usr/local/
[root@qianfeng01 local]# scp /etc/profile qianfeng02:/etc/
[root@qianfeng01 local]# scp /etc/profile qianfeng03:/etc/
步骤4)修改其他节点上的brokerId
qianfeng02的broker.id 为 1
qianfeng03的broker.id 为 2
2.2.2 启动操作
步骤1)先启动zookeeper
可以使用myzkServer.sh脚本,同时启动三台机器的zookeeper
步骤2)启动三台机器的kafka
方式1: 正常启动, 注意,带上配置文件,进行后台启动
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
关闭:
kafka-server-stop.sh -daemon /usr/local/kafka/config/server.properties
方式2: 自己编写一个启动三台机器kafka的脚本
比如 mykafka.sh
2.3 查看Zookeeper维护的数据
kafka在zookeeper上维护了多个znode节点,分别用于存储不同的信息
--cluster/id : 用于存储kafka集群的唯一标识
{"version":"1","id":"mO77ods8Q-ek99Y7lTOwUg"}
--controller : 用于记录多个broker中谁是控制角色
{"version":1,"brokerid":0,"timestamp":"1644464244261"}
--controller_epoch : 记录的是第几次选举controller角色
3
--brokers/ids: 以子znode的形式记录所有的broker唯一标识符
brokers/ids/0 : 记录着自己的信息
{..."endpoints":["PLAINTEXT://qianfeng01:9092"],"host":"qianfeng01","port":9092}
brokers/ids/1 : 记录着自己的信息
{..."endpoints":["PLAINTEXT://qianfeng02:9092"],"host":"qianfeng02","port":9092}
brokers/ids/2 : 记录着自己的信息
{..."endpoints":["PLAINTEXT://qianfeng03:9092"],"host":"qianfeng03","port":9092}
--brokers/topics : 以子znode的形式记录kafka集群中的所有主题名
--consumers : 旧版本用来记录消费者消费消息的偏移量,以便下次继续消费,但是新版本不用该znode,
而是以一个主题"__consumer_offsets"来记录各个消费者的偏移量
三、Kafka的基本操作
3.1 topic的CRUD
3.1.1 帮助信息
对应的脚本是:kafka-topics.sh, 用法直接输入脚本名称回车
[root@qianfeng01 data]# kafka-topics.sh
Create, delete, describe, or change a topic.
Option Description
------ -----------
--alter 修改一个主题的分区数量,副本,以及配置等
--config <String: name=value> 修改主题的一个配置。
--create 创建一个新的主题
--delete 删除一个主题
--delete-config <String: name> 移除一个配置
--describe 列出指定的主题的详情信息
--disable-rack-aware 禁用机架感知副本分配
--force 抑制控制台提示
--help 打印帮助信息
--if-exists 如果在更改或删除主题时设置该操作,则该操作只会在主题存在时执行
--if-not-exists 如果在创建主题时设置,则只在主题不存在时执行该操作
--list 列出所有的主题名称
--partitions <number> `必需属性`,创建或者修改时的分区数量
--replica-assignment <.....> 正在创建或更改的主题的手动分区到代理分配列表。
--replication-factor <Integer> `必需属性`,创建主题时的副本因子
--topic <String: topic> 要创建,修改或者描述的主题名称
--topics-with-overrides 如果在描述主题时设置,则只显示覆盖了配置的主题
--unavailable-partitions 如果在描述主题时设置,只显示leader不可用的分区
--under-replicated-partitions 如果在描述主题时设置,则只显示除了leader的副本
--zookeeper <String: hosts> `必需属性`,用于zookeeper连接的连接字符串,格式为host:port。可以指定多个主机以允许故障转移。
3.1.2 创建主题
案例1:
[root@qianfeng01 data]# kafka-topics.sh \
--zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka \
--create \
--topic food \
--partitions 4 \
--replication-factor 2
案例2:
[root@qianfeng01 data]# kafka-topics.sh \
--zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka \
--create \
--topic pet \
--partitions 2 \
--replication-factor 3
小贴士:
1) 副本因子不能大于broker的数量, 否则报以下错误:
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException Replication factor: 4 larger than available brokers: 3
2) zookeeper的路径,必需写到server.properties里指定的kafka的根znode.
3) 创建时,必需指定分区数量,副本因子,zookeeper路径
3.1.3 列出所有的主题
[root@qianfeng01 data]# kafka-topics.sh \
--zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka \
--list
原理:
列出所有主题名称的逻辑:其实就是访问zookeeper的/kafka/brokers/topics/ 子节点的名字
3.1.4 查看指定主题
[root@qianfeng01 data]# kafka-topics.sh \
--zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka \
--describe \
--topic food
获取的描述信息如下:
Topic:food PartitionCount:4 ReplicationFactor:2
Configs:
Topic: food Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: food Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: food Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: food Partition: 3 Leader: 0 Replicas: 0,2 Isr: 0,2
可以获取四个信息:
Topic: 主题名
PartitionCount: 该主题的分区数量
ReplicationFactor: 该主题的每个分区的副本因子
Configs: 列出的是每个分区的详情信息
摘抄一条解析分区的详情信息:
Topic: food Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
^ ^ ^ ^ ^
| | | | |
主题名称 分区号码 该分区所有副本的leader的所在broker 副本所在的broker 当前可用的副本的broker位置
3.1.5 修改主题
[root@qianfeng01 ~]# kafka-topics.sh \
--zookeeper qianfeng01,qianfeng02,qianfeng03/kafka \
--alter \
--topic food \
--partitions 5
小贴士
1. 修改主题的分区时,数量只能增加,不能减少
2. 副本因子不能被修改
3.1.6 删除主题
[root@qianfeng01 ~]# kafka-topics.sh \
--zookeeper qianfeng01,qianfeng02,qianfeng03/kafka \
--delete \
--topic pet
删除的原理:
1. 将zookeeper里对应的znode删除
2. 将kafka的存储目录下的该主题的分区目录打标记,过一会,再删除.
3.2 生产和消费消息
3.2.1 生产者生产消息
1)帮助信息
使用 kafka-console-producer.sh脚本,回车,即可显示帮助信息。
[root@qianfeng01 data]# kafka-console-producer.sh
Read data from standard input and publish it to Kafka.
Option Description
------ -----------
--batch-size <Integer: size> 如果没有同步发送消息,则在单个批处理中发送的消息数。(默认:200)
--broker-list <String: broker-list> `REQUIRED`: 形式为HOST1:PORT1,HOST2:PORT2的代理列表字符串。
--compression-codec [compression-codec] 'none','gzip', 'snappy', or 'lz4'. 默认值为'gzip'
--key-serializer <className> 用于序列化key的消息编码器实现的类名。(默认:kafka.serializer.DefaultEncoder)
--line-reader <String: reader_class> 用于从标准中读取行的类的类名。默认情况下,每行读取为单独的消息。
(default: kafka.tools. ConsoleProducer$LineMessageReader)
--max-block-ms <Long> 生产者在发送请求期间阻塞的最大时间 (default: 60000)
--max-memory-bytes <Long> 生产者用来缓冲等待发送到服务器的记录的总内存。(default: 33554432)
--max-partition-memory-bytes <Long> 分配给分区的缓冲区大小。当接收到小于这个大小的记录时,
生产者将尝试乐观地将它们组合在一起,直到达到这个大小。
(default: 16384)
--message-send-max-retries <Integer> 重试次数(default: 3)
--producer-property <String> 将用户定义的属性以key=value形式传递给生产者的机制。
--producer.config <String: config file> 引用生产者的配置文件
--property <String: prop> 自定义属性
--queue-enqueuetimeout-ms <Integer: 消息排队超时时间 (default:2147483647)
--queue-size <Integer: queue_size> 如果设置并且生产者以异步模式运行,这将给出等待足够批处理
大小的消息队列的最大数量。(default: 10000)
--request-required-acks <String: 生产者请求所需的ack (default: 1)
--request-timeout-ms <Integer: request 生产者请求的ack超时。值必须是非负且非零 (default: 1500)
--retry-backoff-ms <Integer> 在每次重试之前,生产者会刷新相关主题的元数据。由于leader选举需要一些时间,
这个属性指定生产者在刷新元数据之前等待的时间。 (default: 100)
--socket-buffer-size <Integer: size> tcp协议的缓存大小。(default: 102400)
--sync 如果设置消息,发送到代理的请求是同步的,每次一个。
--timeout <Integer: timeout_ms> 如果设置并且生产者在异步模式下运行,这将给出消息队列等待足够大的批处理的最大时间。
该值的单位是ms。(default: 1000)
--topic <String: topic> `REQUIRED`: 生产的消息去往的主题名称.
--value-serializer <String: kafka的消息对应的value的序列化实现类
(default: kafka. serializer.DefaultEncoder)
2)生产数据到food主题的分区里
该脚本的作用是读取控制台的数据,发送到kafka集群中
[root@qianfeng01 data]# kafka-console-producer.sh \
--broker-list qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food
3.2.2 消费者消费消息
1)帮助信息
使用 kafka-console-consumer.sh脚本,回车,即可显示帮助信息。
[root@qianfeng01 data]# kafka-console-consumer.sh
The console consumer is a tool that reads data from Kafka and outputs it to standard output.
Option Description
------ -----------
--blacklist <String: blacklist> 将主题排除在消费之外的黑名单。
--bootstrap-server <String> `REQUIRED` (unless old consumer isused): 要连接的kafka服务器.
--consumer-property <String> 将用户定义的属性以key=value形式传递给消费者的机制。
--consumer.config <String: config file> 引用消费者的配置文件
--csv-reporter-enabled 如果设置,将启用CSV指标报表器
--delete-consumer-offsets 如果指定了,则启动时删除zookeeper中的consumer路径
--enable-systest-events 除了记录所使用的消息之外,还要记录使用者的生命周期事件。(这是特定于系统测试的。)
--formatter <String: class> 用于格式化显示kafka消息的类名。
(default: kafka.tools.DefaultMessageFormatter)
--from-beginning 从日志中出现的最早的消息开始消费。而不是消费最新的消息。
普通情况下:消费者消费的数据是最新的数据 也就是消费者启动后生产者新生产的数据
--group <String> 消费者所在的消费者组ID
--isolation-level <String> 设置为read_committed是为了过滤掉未提交的事务性消息。
设置为read_uncommitted以读取所有消息. (default: read_uncommitted)
--key-deserializer <String> key的反序列化要实现的类型
--max-messages <Integer: num_messages> 退出前要使用的最大消息数。如果没有设定,消费是持续的。
--metrics-dir <String> 如果设置了csv-reporter-enable,并且该参数为isset,则csv指标将在这里输出
--new-consumer 使用新的使用者实现。这是默认设置,因此该选项已被弃用,并将在未来的版本中删除。
--offset <String: consume offset> 要消费的偏移id(一个非负数),或者'earliest'表示从开始,或者'latest'表示从最新
(default: latest)
--partition <Integer: partition> 指定要消费的具体分区号。除非指定了'——offset',否则消费将从该分区的末尾开始。
--property <String: prop> 自定义属性
--skip-message-on-error 如果在处理消息时出现错误,跳过它而不是停止。
--timeout-ms <Integer: timeout_ms> 如果指定了,如果在指定的时间间隔内没有可用的消息,则退出。
--topic <String: topic> 要消费的主题
--value-deserializer <String> key的反序列化要实现的类型
--whitelist <String: whitelist> 要包含用于消费的主题白名单。
--zookeeper <String: urls> `REQUIRED` (针对于老版本的消费者是必须的):
用于zookeeper连接的连接字符串,格式为host:port。可以提供多个url来允许故障转移。
2)消费者消费food主题的数据
- 默认情况,消费最新消息 (最新消息指的是消费者启动后生产者新生产的消息)
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food
- 从头消费信息,一个主题的所有分区的消息
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--from-beginning
- 指定分区,指定偏移量消费消息--------> 指定非负数形式
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--partition 0 \
--offset 0
注意: 0 表示从该分区的第一个消息开始消费
- 指定分区,指定偏移量消费消息--------> 指定从头消费
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--partition 0 \
--offset earliest
- 指定分区,指定偏移量消费消息--------> 从最新的消息开始消费
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--partition 0 \
--offset latest
经过测试: 消息默认使用轮询的方式进入到不同的分区里
3.2.3 消费者组的引入
1) 说明
1. kafka这个消息队列系统,消息是可以共享的
2. 消息的主题可以分多个分区,想要并行计算。
3. 方便设置消费者的属性。对多个消费者进行设置,归为一组,只需要最该组进行设置即可。
基于上述的设计需求,提供了消费者组的概念:
一个消费者组里可以有多个消费者,如果想要并行计算分区的数据,则可以让每一个消费者去尽量均分主题里的分区
不同的消费者组,可以共享数据,也就是可以重复处理同一个分区的数据
小贴士:
如果一个消费者不指定消费者组,则默认为一个消费者组。 简而言之,Kafka消费数据时,是基于消费者组进行消费的。
2)参数
在consumer.properteis配置文件中,有一个属性,group.id用来指定消费者所属的组id。但是如果想要使用该配置文件,必须在命令行指定。格式如下:
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--consumer.config /usr/local/kafka/config/consumer.properties
3)使用命令行上的参数临时指定:–group
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--group g2
4)消费者组的总结
#1. kafka是基于消费者组来消费数据的,组的成员可以并行处理消息,加快处理速度
#2. 不同的消费者组可以消费同一个主题
#3. 消费者组的消费者数量与主题的分区数量的对比
- 消费者数量=分区数量时,该状态是最优的,一个消费者处理一个分区的数据
- 消费者数量>分区数量时, 一个消费者处理一个分区的数据,剩下的消费者闲置。
- 消费者数量<分区数量时, 消费者处理的分区数个数尽量均分。 比如有5个分区,三个消费者,出现的情况是2,2,1. 不可能出现3,1,1情况
四、Kafka的工作机制
4.1 Kafka的工作流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mHPlbXyN-1648390712499)(ClassNotes.assets/image-20220211093810188.png)]
工作流程的文字整理。
1. 集群上要维护一个主题,并维护好这个主题的分区数量,副本数量,以及对应的leader和follower角色。
2. 生产者生产一条记录,写入到主题的某一个分区的leader副本中。
3. 这个分区的follower副本开始从leader上同步数据。
4. 如果有消费者消费某一个分区的数据,那么是从该分区的leader副本上pull数据,并记录offset到__consumer_offsets主题里。
工作流程中的复杂问题?
1. 集群在维护一个主题的所有分区时,是如何分配分区到各个broker上
2. 每个分区的多个副本又是如何分配到各个broker上的
3. 生产者生产的消息是如何进入某一个分区的
4. 生产者是如何确定了leader收到消息的,leader和follower是如何保证数据的安全性,以及一致性的。
5. 消息进入分区后,是如何存储的
6. 消费者在消费数据时,是如何分配分区的
7. 消费者消费的消息的offset是如何维护的。
整个工作流程可以概括为三个部分:
第一部分:生产者生产消息到leader副本中
第二部分:leader收到消息后进行持久化
第三部分:消费者从leader中消费数据。
4.2 Kafka的文件存储机制
4.2.1 为什么引入分区概念
kafka的存储指的就是消息的持久化操作,而消息是进行逻辑划分成不同的主题。每个主题下的所有的消息是被物理划分成不同的分区进行存储的。
1. 可以并发处理某一个分区的所有的消息
2. 分区也可以方便kafka的分布式的高可靠性,高容错性,高扩展性。
小贴士:
主题的分区的本质,就是目录。 一个目录下的数据被消费者组中的一个消费者处理。
4.2.2 segment的物理结构
思考问题: 消息是存储在分区(目录)下的文件中的,消息不是永久存储的。那么如果所有的消息都存储在分区目录下的一个文件中有哪些缺点。
1. 随着时间,文件会越来越大。写入操作的性能会变的越来越低
2. 消息是要删除的,当文件越来越大是,删除旧消息的性能开销很大。
3. 消费者在消费消息时,也要读取这个文件,文件大不利于查找和读取。
基于上述的问题。分区里的文件是按照segment(片段,段)进行划分的,一个segment的大小默认是1G, 不过可以通过配置参数log.segment.bytes进行修改。
即就是当日志文件存储的字节数达到1G时,就会产生一个新的文件来存储新的消息
segment的构成图解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EbHTpn1K-1648390712499)(ClassNotes.assets/image-20220211110959245.png)]
1)查看log文件的内容
[root@qianfeng01 ~]# kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log
offset: 0 position: 0 CreateTime: 1644478520275 isvalid: true keysize: -1 valuesize: 1 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: 4
log文件的物理结构如下:
| 属性 | 解析 |
|---|---|
| offset | 针对于当前分区的记录的偏移量, 是一个从0开始的连续的自然数, 即当前分区的第几条记录 |
| position | 针对于当前segment文件的字节偏移量。 |
| CreateTime | 当前消息的产生时间戳 |
| isvalid | 是否有效 |
| keysize | 消息的key的长度,-1表示key是null。 注意:kafka的消息指的是value。 |
| valuesize | 消息的value的长度 |
| magic | 表示本次kafka发布消息的协议版本号 |
| compresscodec | 压缩类型 |
| producerId | 生产者的ID, 幂等机制会用到 -1表示没有使用 |
| producerEpoch | 生产者的逻辑时钟,幂等机制会用到 -1表示没有使用 |
| sequence | 消息的序列号,幂等机制会用到 -1表示没有使用 |
| isTransactional | 是否开启了事务 |
| headerKeys | 消息的消息头 |
| payload | 是kafka的具体消息 |
segment的log文件的命名:
1. 是由20个数字字符组成.log为扩展的文件。比如xxxxxxxxxxxxxxxxxxxx.log
2. xxxxxxxxxxxxxxxxxxx6.log 表示该segment文件中存储的消息是从该分区的第7条存储的。
也表示之前的segment文件存储的总记录数是6条。
2)查看index文件的内容
问题:为什么要为log文件设计一个index文件。
假如没有index文件,那么消费者消费log文件时,从某一个offset开始查询,那么要从头开始遍历查找对应的offset,文件里的消息数量过多时,那么耗时就长。
因此如果有一个文件用来维护log文件中的消息的索引信息,那么就可以提高查询效率。
查看index文件的命令:
[root@qianfeng01 ~]# kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000021.index --print-data-log
offset: 21 position: 0
offset: 23 position: 200
offset: 40 position: 1900
offset: 57 position: 3600
通过上述的内容查看,可以看到,index文件存储的是log文件中的消息的offset和position,而且是稀疏存储的
为什么要稀疏存储?
因为索引文件的作用是给消费者来消费数据时使用的,消费者在使用索引文件时,会将索引文件加载到内存,又因为kafka消息系统是高吞吐量,数据量非常大,如果每条消息的索引都存储,那么索引文件也会很大,加载到内存,就是占用过多的内存资源。
index文件的命名与之对应的log的文件名一致,后缀是index而已。
4.2.3 Kafka的消息查找流程
指的是消费者在消费消息时的查找流程,假如某一个消费者从某一个offset开始消费某一个分区的消息,如下操作:
[root@qianfeng01 data]# kafka-console-consumer.sh \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--topic food \
--partition 0 \
--offset 30
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q2luqEoD-1648390712500)(ClassNotes.assets/image-20220211122924761.png)]
1. 先根据锁定的offset 30 来确定是哪一个索引文件。如何定位索引文件,使用二分查找法
即,定位到00000000000000000021.index
2. 将该索引文件加载到内存中,遍历里面的offset,如果有具体的30这个offset,就获取position的值。如果没有,就定位offset的范围28~34,然后获取小于30的28这个offset的position的值。
3. 然后在查找与该index同名的log文件。
4. 然后根据offse=28以及position=700这个数据开始向下遍历,查找offset=30的,然后获取对应的postition以及valuesize,开始读取真正的payload数据
4.3 Kafka的分区分配策略
1)说明
每一个主题都有多个分区(先不考虑副本),那么各个分区是如何分配到各个broker上的呢?应该对应着一个算法,也就是分区分区策略。
2)策略如下:
1. 将所有broker(n个)和partition排序
2. 将第i个Partition分配到第(i mode n)个broker上
假设主题phone,有4个分区,副本因子为1。 broker有三个。
phone-0
phone-1
phone-2
broker-0 broker-1 broker-2
假设第一个分区是i=0的分区, 计算公式:0%3 = 0 假设0为第一个broker, 位置位于第一个broker
第二个分区是i=1的分区, 计算公式:1%3 = 1 位置位于第二个broker
第三个分区是i=2的分区 计算公式:2%3 = 2 位置位于第三个broker
第四个分区是i=3的分区 计算公式:3%3 = 0 位置位于第一个broker
经过大量的测试:
1. 上面的公式不是特别的准确
2. 但是,一旦主题的第一个分区确定了broker的位置。那么该主题的其他分区就是按照顺序依次循环存储到各个broker(broker是排序的)上。
4.4 Kafka的副本分配策略
1)说明
一个分区至少有一个副本,也可以有多个副本,如果是多个副本,副本的所在位置是如何分配的呢? 也应该有一个分配策略。假设没有分配策略,比如随机,那么会造成broker维护的副本数量不一致,从而造成负载不均衡,以及网络IO不均衡。
2)策略如下
1. 一个分区的副本是一个leader和N个follower构成的。每个borker都有均等分配leader的机会。
2. 同一个分区的副本不应该在同一台机器上,否则没有意义( 10个副本都存在同一台机器上,该机器宕机了,10个副本都没有用了)
3. broker也可以设置多个机架。副本在分配的时候,是尽量散布在不同的机架上的。
4. 副本的数量不能大于所有机架的broker总数。
案例演示:
#创建一个主题,具有7个分区,3个副本
kafka-topics.sh --zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka --create --topic b1 --partitions 7 --replication-factor 3
#查看该主题的详情
kafka-topics.sh --zookeeper qianfeng01:2181,qianfeng02:2181,qianfeng03:2181/kafka --topic t6 --describe
#详情如下:
Topic:t6 PartitionCount:7 ReplicationFactor:3 Configs:
Topic: t6 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: t6 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: t6 Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: t6 Partition: 3 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: t6 Partition: 4 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: t6 Partition: 5 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: t6 Partition: 6 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
从上述的详情中可知:
1. 一旦第一个分区的多个副本中的leader的位置确定,那么其他分区的leader副本的位置就确定了。
即:其他分区的leader的位置,是按照borker的顺序循环的。
2. 同一个分区的其他副本是存在其他的broker上的。
4.5 Kafka的生产者相关
4.5.1 Kafka的消息分配策略
1) 说明
当生产者向kafka集群push消息时,到底该条消息进入哪一个分区,是有消息分配策略的。
2)策略如下:
1. 如果指定了partition,消息就会进入该partition
2. 如果没有指定该partition,但是指定key,通过key的hashcode值和partition数求模确定partition号码
3. 如果都没有指定,通过轮询方式进入对应的partition。
4.5.2 Kafka的数据保障机制
问题:当生产者向某一个分区的leader写数据时,如果leader发生了宕机,或者网络阻塞,或者是follower在同步数据时出现了问题,那么如何保证数据的一致性,完整性,安全性
所以:kafka提供了一个ack应答机制,来解决上述问题。
4.5.2.1 Kafka的ack应答机制
在生产者与leader进行交互时,kafka提供了一个应答机制,作为保障数据的完整性,一致性等特征。供开发人员有一个可选择的策略,比如数据必须完整,不能重复,或者说数据丢失的内容在可控范围内。 kafka开发人员提供了以下三种情况,其实就是一个参数acks, 该参数是在生产者的配置文件中。
acks = 0:
表示leader在收到producer生产的消息后,不需要向producer进行应答。 producer可以一直写新消息。
我们要考虑的问题是 数据是否会丢失,是否会重复?
数据可能会丢失,不会重复: 当leader收到消息后,还没有持久化到磁盘中,然后就宕机了,剩下的follower会选举出一个新的leader,而这个leader无法从原有的宕机的leader上同步数据,因此其他所有的副本都会丢失这一部分数据。
acks = 1
表示leader在将收到的消息持久化到磁盘后,向producer进行应答。(特点:producer如果没有收到应答,就会重发该条消息)
出现的情况有:
-- 数据可能会丢失: leader应答了,但是follower在从leader上同步数据时,leader宕机了。
-- 数据可能会重复: leader应答了,但是由于网络震荡,producer迟迟没有收到应答信息,然后producer就会将该条消息重新发送一次。
acks = -1(all)
表示leader在收到信息后,持久化到磁盘,并且所有的follower都已经同步完成,leader再向producer进行应答。
数据不可能丢失,但是可能重复,原因就是leader在进行应答时,出现了网络震荡,producer没有收到应答,会再次发送该条消息。
结账系统:
当买家使用微信,或者是银行app付款时,网络出现了延迟, 银行应该选择一种 即不能丢失数据,也不能重复结账的应答机制。 即仅仅一次的语义。
4.5.2.2 ExActly Once语义
对于某些应用程序,或者是接受者来说,有的时候消息最好是精确的接受一次,即不能丢失,也不能重复,这种情况我们称之为ExActly Once。
而kafka在进行ack机制时,其实对应着三种语义,分别是:
at least once(至少一次):
当acks = 1|-1时,kafka可能会出现 at least once这种情况
at most once(至多一次)
当acks = 0 时,kafka一定会出现 at most once这种情况
exactly once(精准一次):
如银行交易系统,数据不应该丢失,也不应该重复,所以说应该具有exactly once这种语义。
kafka是如何保证exactly once语义
kafka使用 at least once (acks=-1) + 幂等机制 来维护exactly once语义。
什么是幂等机制
步骤1:当启用了幂等机制时,生产者就会在本地维护一个producerId(生产ID)以及为每条消息维护一个sequence(序列号),序列号是递增的自然数。
步骤2:当向leader发送消息时,会带上这两个属性的值,leader也会保存这两个属性的值。
步骤3:当生产者没有收到应答时,会重新发送该条消息,依然会带上这两个属性。
步骤4:leader再次收到消息时,会判断producerId和sequence是否出现过。如果出现过,则不再保存。这样就避免了数据重复。
如何启动幂等机制
只需要在producer.properties里配置以下属性即可
enable.idempotence = true
注意:
--重试次数对应的那个属性的值要大于0
--还要使用acks机制,即acks=-1
4.5.2.3 ISR的概念
isr是in-sync replica set (ISR)的简写,表示可以同步leader数据的所有副本(包括leader)。当ack机制选择的配置是-1时,则表示所有的follow都必须同步完数据后(也就是ISR中的所有的副本),leader才会向producer做应答
如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
扩展:follower从leader同步数据时,有两种方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
针对于上述两种方案,Kafka选择的是第二种方案。根据优缺点来决定的,第一种方案需要至少2n+1个broker,或者是2n+1个副本,更浪费磁盘空间。相较于第二个方案的延迟高,磁盘的浪费缺点更明显,因此选择了第二种方案。
4.5.2.4 故障处理细节
在kafka接受生产者的数据时,引入了一个叫HW的概念。
HW: 是High watermark的简写。即高水位线。
作用:就是记录每次持久化后的消息的偏移量。 HW之前的数据,所有的消费者都可见。 HW后的数据是正在同步的数据,消费者不可见。 这样的优势是保证了所有的消费者可以消费的数据都是一致的,即保证了数据的一致性。
LEO:指的是一个副本中的最后一个消息的偏移量。 注意:每个副本的LEO的值可能不相同,原因时,follower的同步速度不一样,leader的leo一定是最大的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5BK01PCt-1648390712500)(ClassNotes.assets/1577975301062.png)]
1)follower发生故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等follower追上leader之后,就可以重新加入ISR了。
2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。具体看acks配置的是0,1,-1
4.6 Kafka的消费者相关
4.6.1.消费者组的架构
kafka消费消息时,是以消费者组为单位的。如果这个消费者不指定组,则默认为一个独立的组。
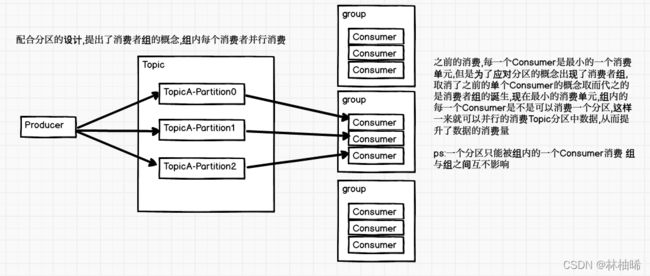
1. 消费者组里可以有多个消费者, 消费者可以是进程,也可以是线程。
2. 消费者组有一个唯一标识符:groupid 组内的消费者共享此ID
3. 消费者组订阅的主题的所有分区的分配情况: 一个分区只能被一个消费者进行消费。
但是,不同的消费者组可以订阅同一个主题。
4.6.2 消费者的pull模式
1. kafka的producer采用的push模式,即 producer主动向broker节点push数据。
--因为kafka的高吞吐量的特点,因此生产者不需要考虑消息的生产速度
2. kafka的consumer采用的pull模式,即 consumer主动从broker节点pull数据
--pull的优点:
消费者可以根据自己的处理能力来pull消息的数量
--pull的缺点:
如果生产者一直没有生产新数据,那么消费者也会一直pull,pull到的都是空数据。
kafka设置了一个等待时间,如果这一次没有pull到数据,则等待这个时间后,再pull目的,减少pull空数据的次数。
4.6.3 消费者的分区分配策略
消费者在消费主题的分区里的数据时,消费者是如何分配一个主题下的所有分区呢?这是有消费者的分区分配策略。版本不同,分配策略不同。比如1.1.1版本有两个分配策略(轮询分配策略和范围分配策略),
最新版本3.1有四个分配策略
--RoundRobinAssignor轮询分配策略
--RangeAssignor范围分配策略,
--StickyAssignor
--CooperativeStickyAssignor
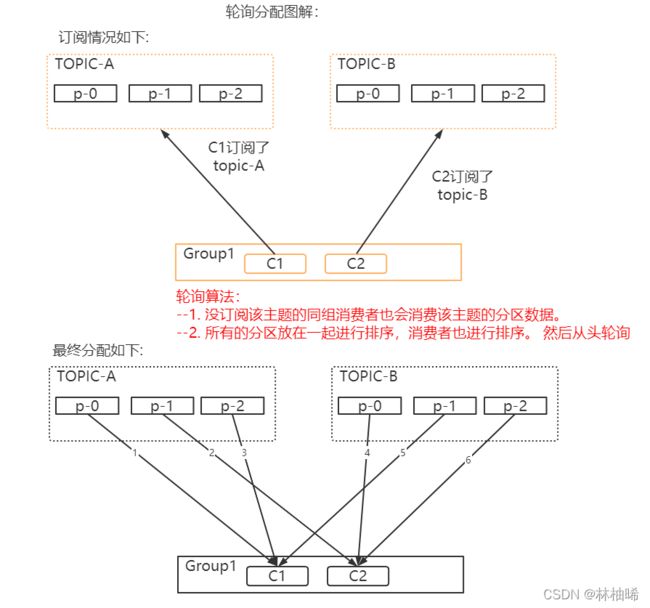
1)RoundRobin
该算法的特点如下:
如果这个消费者组的某一个成员订阅了一个主题,那么其他成员也会消费该主题的信息
特点也是缺点:我没有订阅,为什么还让我处理分区
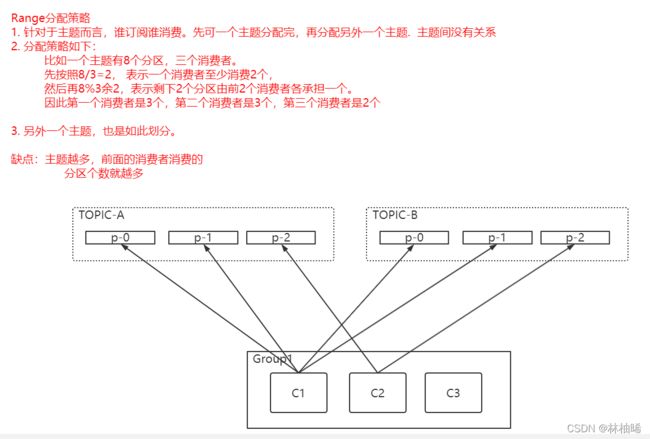
2)Range分配策略
该分配策略的特点:针对主题来说,谁订阅谁消费
4.6.4 消费者offset的维护
当消费者在消费某一个主题分区的数据时,如果宕机了,然后重启后,所要消费的数据是从头开始,还是接着宕机前的数据继续消费呢?
这两个需求都可以实现
1. 如果从头消费,那简单,只需要指定offset的偏移量的值为0即可
2. 如果从宕机前消费到的那个位置开始消费,则需要对消费过的offset进行保存,方便下次从该处继续消费。
kafka对消费者消费的offset也有相关维护策略。如下:
1. kafka在版本0.11以前,这个offset是在zookeeper上维护的。
2. 在0.11版本以后,在kafka集群上维护了一个特殊主题__consumer_offsets. 默认的分区数是50个。
因为zookeeper本身不适合存储数据。
那么,该主题是怎么维护每个消费者的消费过的offset呢?,可以使用以下指令查看,前提是消费者需要在consumer.properties下配置一个属性:exclude.internal.topics=false。 当然消费者读取该主题,要带上这个配置文件,否则不生效
[root@qianfeng01 ~]# kafka-console-consumer.sh \
--topic __consumer_offsets \
--bootstrap-server qianfeng01:9092,qianfeng02:9092,qianfeng03:9092 \
--formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" \
--consumer.config /usr/local/kafka/config/consumer.properties --from-beginning
主题里的内容如下:
[g1,MiPhone,2]::[OffsetMetadata[4,NO_METADATA],CommitTime 1644807874253,ExpirationTime 1644894274253]
格式整理如下:
[group,topic,partition]::[OffsetMetadata,CommitTime,ExpirationTime]
OffsetMetadata: 是消费者消费的主题的分区下的某一条记录的偏移
- 小贴士:任何消费者相对于__consumer_offset这个主题都是生产者,因为消费者需要保存自己消费的偏移量到该主题下。
测试:
4.7 Kafka的高效读写
kafka的消息队列存储会持久化到磁盘上,默认可以临时保存7天。虽然是基于磁盘的,但是速度依然是特别快。
写时:
普通的软件向磁盘写文件时,文件的字节序列一般情况下不是有序存储,可能是分开到不同的扇区,不同的位置进行存储,因此写时,很慢
但是kafka在存储文件时,强制开辟一块有序的扇区,进行存储消息。因此只要开辟后,就连续写。因此写速度非常快
读时:
当kafka读取文件时,只需要寻找一次地址,就可以连续读这个文件,不像其他软件读文件时,可能需要多次寻址。
所以,kafka读文件,也特别快。
还有一个原因:消费者在读数据时,是先读稀疏存储的索引文件,然后再找对应的分段文件里的相对offset,进行小范围的遍历。
kafka的旧log的删除操作
有一个检查周期参数,默认5分钟检查一次,当发现有有一个片段文件超过存储时间期,则将该分段文件以及索引文件进删除。
五、Kafka的API
pom.xml
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>1.1.1version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.11artifactId>
<version>1.1.1version>
dependency>
5.1 生产者API
5.1.1 简单案例演示
package com.qf.kafka.producer;
import org.apache.kafka.clients.KafkaClient;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 练习Kafka的生产者API
* 简单练习,使用生产者向某一个主题MiPhone里生产数据
*/
public class Kafka_01 {
public static void main(String[] args) {
/**
* kafka生产者的类型,有四个构造器可用。
* KafkaProducer(final Map configs)
* KafkaProducer(Map configs, Serializer keySerializer, Serializer valueSerializer)
* KafkaProducer(Properties properties)
* KafkaProducer(Properties properties, Serializer keySerializer, Serializer valueSerializer)
* 上述四个构造器,都是要用来指定配置参数的。
*
*/
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//获取一个具体的生产者对象
KafkaProducer kafkaProducer = new KafkaProducer(properties);
/**
* ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable headers)
* ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
* ProducerRecord(String topic, Integer partition, K key, V value, Iterable headers)
* ProducerRecord(String topic, Integer partition, K key, V value)
* ProducerRecord(String topic, K key, V value)
* ProducerRecord(String topic, V value)
*/
ProducerRecord producerRecord = new ProducerRecord("MiPhone", "you are best one");
//调用send方法发送数据, 数据是ProducerRecord类型
kafkaProducer.send(producerRecord);
//释放资源
kafkaProducer.close();
}
}
5.1.2 异步发送演示
生产者的工作流程图解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tEQeww0E-1648390712503)(ClassNotes.assets/image-20211030174354729.png)]
package com.qf.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 研究一下生产者的send方法的异步发送。
* 注意: 与一个属性linger.ms有关系. 该属性的作用
*
* 实际上,生产者在发送数据时,是如下情况:
* 生产者自己维护一个缓存,用于存储消息记录,而且还有一个时间限制,当到达该时间限制时,会将缓存记录中的所有记录一次性发送到kafka集群上。
* 这样的目的是用于减少生产者和kafka集群之间的网络IO次数。
* 缓存大小由batch.size来决定的, 时间限制是由linger.ms来决定的。
*
*
* 扩展: 参数的使用 可以使用ProducerConfig该类的静态成员变量获取相应的属性和属性文档。
*
*/
public class Kafka_02 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"10000");
KafkaProducer kafkaProducer = new KafkaProducer(properties);
ProducerRecord producerRecord = new ProducerRecord("MiPhone", "you are best one");
//调用send方法发送数据, 数据是ProducerRecord类型
kafkaProducer.send(producerRecord);
/**
* main方法睡眠了100秒。 参数设置的是10秒一发送。
*
* 该实现,验证了,send方法触发了一个独立的线程。与main线程是不同的线程。
*
* 也就是说:在main方法中,瞬间就执行到了send方法,但是kafka收到数据的时候是10秒。所以只能说send方法触发了另外一个线程。
*
*/
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//释放资源, 注意,底层会调用flush冲刷缓存,如果立马调用flush, 不能证明send方法是一个异步发送消息的方法。所以要在之前写一个main方法的睡眠代码
kafkaProducer.close();
}
}
5.1.3 指定分区发送数据
package com.qf.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 案例演示: 生产者指定分区发送数据
* 注意:生产者的命令行脚本无法指定分区进行生产数据
*/
public class Kafka_03 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG,"10000");
KafkaProducer kafkaProducer = new KafkaProducer(properties);
ProducerRecord producerRecord = new ProducerRecord("MiPhone", 0,"","进入0分区了");
//调用send方法发送数据, 数据是ProducerRecord类型
kafkaProducer.send(producerRecord);
kafkaProducer.close();
}
}
5.1.4 生产者的消息的默认分区策略代码
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
.....
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
通过上述源码可知,生产者的消息的默认分区策略如下:
1. 如果指定了分区号,则直接进入该分区
2. 如果指定了key, 则进入key.hashcode%numPartitions取模的结果对应的分区号
3. 如果没有指定分区号,也没有指定key,则使用轮询的方式进入分区。
5.1.5 自定义分区策略
package com.qf.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 自定义一个分区类型
* 1. 演示轮询分区策略
*
*/
public class MyPartitioner implements Partitioner {
//获取一个自增变量
private AtomicInteger atomicInteger = new AtomicInteger();
/**
* 模拟 轮询分区策略的演示 : 算法就是 递增的自然数对分区数据取模运算
* @param topic
* @param key
* @param keyBytes
* @param value
* @param valueBytes
* @param cluster
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
/**
* 获取自增变量的值
* incrementAndGet() :相当于++i
* GetAndIncrement() :相当于i++
*
* 每次调用时,都会递增
*/
// int num = atomicInteger.incrementAndGet();
// //获取主题的所有分区数量
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);
// return num%partitionInfos.size();
return key.hashCode()%partitionInfos.size();
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
测试:
package com.qf.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 自定义分区器
*/
public class Kafka_05_customPartition {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.qf.kafka.producer.MyPartitioner");
KafkaProducer kafkaProducer = new KafkaProducer(properties);
/**
* 测试分区的时候,值得注意的是,要使用同一个生产者生产多个消息进行测试。
* 不能重新运行多次该程序,因为每运行一次,都是一个新的生产者。
*/
int i = 0;
while(i<10){
ProducerRecord producerRecord = new ProducerRecord("pet","A","b"+i);
//调用send方法发送数据, 数据是ProducerRecord类型
kafkaProducer.send(producerRecord);
i++;
}
kafkaProducer.close();
}
}
5.2 消费者API
5.2.1 消费最新数据
package com.qf.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class Kafka_06 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//消费者在消费数据时,必须指定消费者组属性。
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"g1");
//获取一个消费者对象
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
//调用相关方法subscribe来消费主题
List<String> topics = new ArrayList<String>();
topics.add("pet");
topics.add("fruit");
kafkaConsumer.subscribe(topics);
//消费者是主动拉去集群上的消息的
while (true){
ConsumerRecords messages = kafkaConsumer.poll(5000);
Iterator<ConsumerRecord> iterator = messages.iterator();
while (iterator.hasNext()){
ConsumerRecord m = iterator.next();
System.out.println(m.topic()+"\t"+m.partition()+"\t"+m.value());
}
}
}
}
5.2.2 定位offset进行消费数据
package com.qf.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
/**
* 消费者进行指定offset消费
*/
public class Kafka_07 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//消费者在消费数据时,必须指定消费者组属性。
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"g1");
//获取一个消费者对象
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
//如果想要定位offset进行消费,必须使用方法assign
List<TopicPartition> tps = new ArrayList<>();
TopicPartition t1 = new TopicPartition("pet",0);
TopicPartition t2 = new TopicPartition("fruit",0);
tps.add(t1);
tps.add(t2);
//指定要分配的主题集合
kafkaConsumer.assign(tps);
//一定要先分配主题,然后再进行offset定位
kafkaConsumer.seek(t1,0);
kafkaConsumer.seek(t2,0);
//消费者是主动拉去集群上的消息的
while (true){
ConsumerRecords messages = kafkaConsumer.poll(5000);
Iterator<ConsumerRecord> iterator = messages.iterator();
while (iterator.hasNext()){
ConsumerRecord m = iterator.next();
System.out.println(m.topic()+"\t"+m.partition()+"\t"+m.value());
}
}
}
}
六、Kafka与Flume的整合
kafka是一个消费队列系统,在与flume进行整合时,kafka可以作为source源,也可以作为channel通道,也可以作为sink使用。
1. kafka作为source源时,flume相当于kafka的消费者角色
2. kafka作为sink源时,flume相当于kafka的生产者角色
3. kafka作为channel时,就是起到一个临时缓存的作用
6.1 Kafka Source的方案编写
测试流程应该如下:
1. kafka的生产者向kafka集群生产数据
2. flume作为消费者从kafka集群上采集数据
3. flume将数据落地到控制台上
采集方案的编写
[root@qianfeng01 ~]# vim /root/flumeconf/kafka-mem-logger.properties
#三大核心组件的命令和关联
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = qianfeng01:9092,qianfeng02:9092,qianfeng03:9092
a1.sources.r1.kafka.consumer.group.id = g1
a1.sources.r1.kafka.topics = pet
a1.channels.c1.type = memory
# 内存存储容量 event的最大数量
a1.channels.c1.capacity=1000
# 从内存中出来时,一次性提交的event的数量
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sinks.k1.maxBytesToLog = 20
启动采集方案
[root@qianfeng01 ~]# flume-ng agent -c /usr/local/flume/conf -f /root/flumeconf/kafka-mem-logger.properties -n a1 -Dflume.root.logger=INFO,console
测试:
1. 开启一个生产者,使用生产者发送消息
方式1:使用api
方式2:使用shell
6.2 Kafka Sink的方案编写
测试流程如下:
[root@qianfeng01 flumeconf]# vim syslog-mem-kafka.properties
#定义agent和三大核心组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = s1
#关联
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
#定义source源
a1.sources.r1.type = syslogtcp
a1.sources.r1.host = qianfeng01
a1.sources.r1.port = 10086
#定义channel源
a1.channels.c1.type = memory
a1.channels.c1.capacity= 1000
a1.channels.c1.transactionCapacity=100
#定义sink源
a1.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.s1.kafka.bootstrap.servers = qianfeng01:9092,qianfeng02:9092,qianfeng03:9092
#主题必须提前存在
a1.sinks.s1.kafka.topic = pet
a1.sinks.s1.kafka.producer.acks = 1
#缓冲区flush到磁盘的时间阈值
a1.sinks.s1.kafka.producer.linger.ms = 1
#a1.sinks.k1.kafka.producer.compression.type = snappy
启动采集方案
[root@qianfeng01 ~]# flume-ng agent -c /usr/local/flume/conf -f /root/flumeconf/syslog-mem-kafka.properties -n a1 -Dflume.root.logger=INFO,console
测试如下:
1. 使用syslogtcp进行测试
2. 消息会进入kafka集群,
3. 如果想要看到结果,需要开启一个kafka的消费者角色
[root@qianfeng01 flumeconf]# echo "aaaaa" | nc qianfeng01 10086
id = g1
a1.sources.r1.kafka.topics = pet
a1.channels.c1.type = memory
内存存储容量 event的最大数量
a1.channels.c1.capacity=1000
从内存中出来时,一次性提交的event的数量
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sinks.k1.maxBytesToLog = 20
启动采集方案
```shell
[root@qianfeng01 ~]# flume-ng agent -c /usr/local/flume/conf -f /root/flumeconf/kafka-mem-logger.properties -n a1 -Dflume.root.logger=INFO,console
测试:
1. 开启一个生产者,使用生产者发送消息
方式1:使用api
方式2:使用shell
6.2 Kafka Sink的方案编写
测试流程如下:
[root@qianfeng01 flumeconf]# vim syslog-mem-kafka.properties
#定义agent和三大核心组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = s1
#关联
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
#定义source源
a1.sources.r1.type = syslogtcp
a1.sources.r1.host = qianfeng01
a1.sources.r1.port = 10086
#定义channel源
a1.channels.c1.type = memory
a1.channels.c1.capacity= 1000
a1.channels.c1.transactionCapacity=100
#定义sink源
a1.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.s1.kafka.bootstrap.servers = qianfeng01:9092,qianfeng02:9092,qianfeng03:9092
#主题必须提前存在
a1.sinks.s1.kafka.topic = pet
a1.sinks.s1.kafka.producer.acks = 1
#缓冲区flush到磁盘的时间阈值
a1.sinks.s1.kafka.producer.linger.ms = 1
#a1.sinks.k1.kafka.producer.compression.type = snappy
启动采集方案
[root@qianfeng01 ~]# flume-ng agent -c /usr/local/flume/conf -f /root/flumeconf/syslog-mem-kafka.properties -n a1 -Dflume.root.logger=INFO,console
测试如下:
1. 使用syslogtcp进行测试
2. 消息会进入kafka集群,
3. 如果想要看到结果,需要开启一个kafka的消费者角色
[root@qianfeng01 flumeconf]# echo "aaaaa" | nc qianfeng01 10086