(转)大数据面试题130道及答案整理 1-15
大数据面试题130道及答案整理 1-15
转载自:https://www.cnblogs.com/yuluoxingkong/p/13475235.html
1、HashMap 和 Hashtable 区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
2、Java 垃圾回收机制和生命周期
C语言:

Java语言:

c的垃圾回收是人工的,工作量大,但是可控性高。
java是自动化的,但是可控性很差,甚至有时会出现内存溢出的情况,
内存溢出也就是jvm分配的内存中对象过多,超出了最大可分配内存的大小。
提到java的垃圾回收机制就不得不提一个方法:
System.gc()用于调用垃圾收集器,在调用时,垃圾收集器将运行以回收未使用的内存空间。它将尝试释放被丢弃对象占用的内存。
然而System.gc()调用附带一个免责声明,无法保证对垃圾收集器的调用。
所以System.gc()并不能说是完美主动进行了垃圾回收。
作为java程序员还是很有必要了解一下gc,这也是面试过程中经常出现的一道题目。
我们从三个角度来理解gc。
1jvm怎么确定哪些对象应该进行回收
2jvm会在什么时候进行垃圾回收的动作
3jvm到底是怎么清楚垃圾对象的
jvm怎么确定哪些对象应该进行回收
对象是否会被回收的两个经典算法:引用计数法,和可达性分析算法。
1.引用计数法
简单的来说就是判断对象的引用数量。实现方式:给对象共添加一个引用计数器,每当有引用对他进行引用时,计数器的值就加1,当引用失效,也就是不在执行此对象是,他的计数器的值就减1,若某一个对象的计数器的值为0,那么表示这个对象没有人对他进行引用,也就是意味着是一个失效的垃圾对象,就会被gc进行回收。
但是这种简单的算法在当前的jvm中并没有采用,原因是他并不能解决对象之间循环引用的问题。
假设有A和B两个对象之间互相引用,也就是说A对象中的一个属性是B,B中的一个属性时A,这种情况下由于他们的相互引用,从而是垃圾回收机制无法识别。

因为引用计数法的缺点有引入了可达性分析算法,通过判断对象的引用链是否可达来决定对象是否可以被回收。可达性分析算法是从离散数学中的图论引入的,程序把所有的引用关系看作一张图,通过一系列的名为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连(就是从 GC Roots 到这个对象不可达)时,则证明此对象是不可用的。
如图:
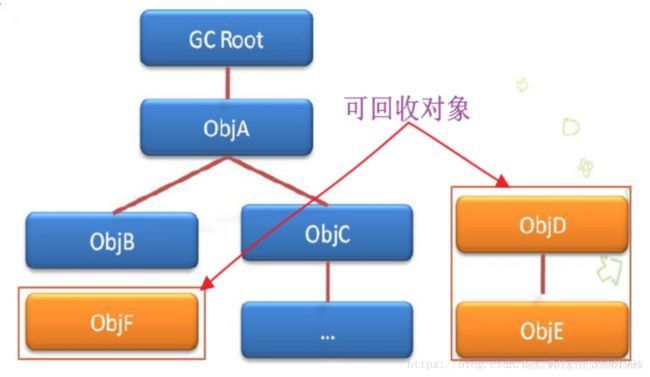
二在确定了哪些对象可以被回收之后,jvm会在什么时候进行回收
1会在cpu空闲的时候自动进行回收
2在堆内存存储满了之后
3主动调用System.gc()后尝试进行回收
三如何回收
如何回收说的也就是垃圾收集的算法。
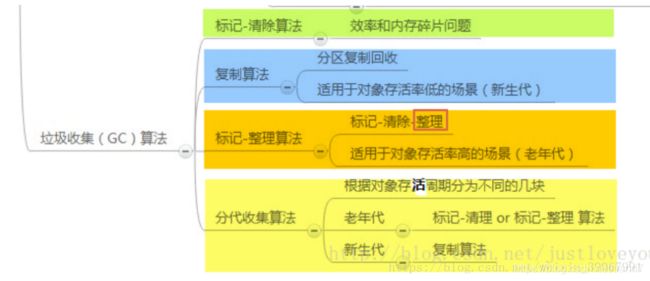
算法又有四个:标记-清除算法,复制算法,标记-整理算法,分代收集算法.
1 标记-清除算法。
这是最基础的一种算法,分为两个步骤,第一个步骤就是标记,也就是标记处所有需要回收的对象,标记完成后就进行统一的回收掉哪些带有标记的对象。这种算法优点是简单,缺点是效率问题,还有一个最大的缺点是空间问题,标记清除之后会产生大量不连续的内存碎片,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而造成内存空间浪费。
执行如图:

2复制算法。
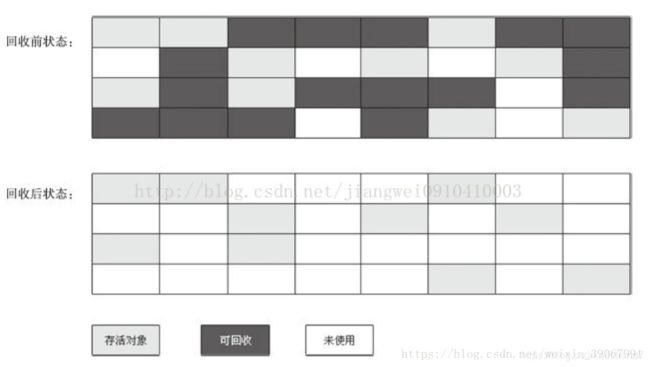
复制将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况。只是这种算法的代价是将内存缩小为原来的一半。
复制算法的执行过程如图:

复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,浪费了一半的空间。
标记-整理算法:
标记整理算法与标记清除算法很相似,但最显著的区别是:标记清除算法仅对不存活的对象进行处理,剩余存活对象不做任何处理,造成内存碎片;而标记整理算法不仅对不存活对象进行处理清除,还对剩余的存活对象进行整理,重新整理,因此其不会产生内存碎片。

分代收集算法:
分代收集算法是一种比较智能的算法,也是现在jvm使用最多的一种算法,他本身其实不是一个新的算法,而是他会在具体的场景自动选择以上三种算法进行垃圾对象回收。
那么现在的重点就是分代收集算法中说的自动根据具体场景进行选择。这个具体场景到底是什么场景。
场景其实指的是针对jvm的哪一个区域,1.7之前jvm把内存分为三个区域:新生代,老年代,永久代。

了解过场景之后再结合分代收集算法得出结论: 1、在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法。只需要付出少量存活对象的复制成本就可以完成收集。 2、老年代中因为对象存活率高、没有额外空间对他进行分配担保,就必须用标记-清除或者标记-整理。
注意:
在jdk8的时候java废弃了永久代,但是并不意味着我们以上的结论失效,因为java提供了与永久代类似的叫做“元空间”的技术。
废弃永久代的原因:由于永久代内存经常不够用或发生内存泄露,爆出异常java.lang.OutOfMemoryErroy。元空间的本质和永久代类似。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。也就是不局限与jvm可以使用系统的内存。理论上取决于32位/64位系统可虚拟的内存大小。
GC垃圾回收:
jvm按照对象的生命周期,将内存按“代”划分(将堆划分为多个地址池):新生代、老年代和持久代(jdk1.8后移除持久代);
在JVM中程序(PC)计数器、JAVA栈、本地方法栈3个区域随线程而生、随线程而灭,因此这几个区域的内存分配和回收都具备确定性,就不需要过多考虑回收的问题,因为方法结束或者线程结束时,内存自然就跟随着回收了。而堆和方法区则不一样,这部分内存的分配和回收是动态的,正是垃圾收集器所需关注的部分。
java中新创建的对象会先被放在新生代区域,该区域对象使用频繁,jvm会在该区域使用不同算法回收一定的短期对象,如果某些对象使用次数达到一定限制后,那么该对象就会被放入老年代区域,老年代区域要比新生代区域更大一些(堆内存大部分分配给了老年代区域),而持久代保存的是类的元数据、常量、类静态变量等。
方法区和永久代的区别:
对于方法区和永久代的区别的话,人们一直将它们看作一个部件,其实永久代实现了方法区,比作java中类的话,永久代就是接口实现类,方法区就是接口。
finalize()和System.gc()方法介绍:
提到GC就要提到finalize()方法,该方法是在jvm确定了一个对象符合GC的条件下执行的,用于对一些外部资源的释放等操作,但是何时对这个对象回收我们就不知道了;需要注意的是在jvm调用了该方法后,这个符合GC的对象也不一定最后就被回收了,因为在执行了finalize()方法后由于在方法体给对该方法进行了一些操作,使得该对象不符合GC的条件,例如将一个引用指向这个对象,最终导致该对象不会被GC,但这也只能求这个对象依次。
同样还有System.gc()方法,这个方法的调用,jvm也不会立即执行对对象的回收,gc()仅仅是提醒jvm可以回收该方法了,但实际上要根据jvm内存需求来确定何实回收这个可以回收的对象。
那么gc()和finalize()的区别是什么呢?
首先finalize()方法是jvm调用的,但是在回收期间不一定每个对象都会调用这个方法进行收尾工作,这也是这个方法不被提倡使用的原因。而System.gc()方法可以人为调用进行标记一个对象可以被回收。
最后我们从何时回收对象比较,finalize()标记的对象是在被标记后的第二次回收时进行回收,而System.gc()方法没有这种规定,它只是被标记,何时回收由jvm决定。
代码示例:
public class Test {
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println(“调用”);
}
public static void main(String[] args){
Test test = new Test();
test=null;
System.gc();
}
}
分析:
我们这里创建了Test类并重写了finalize()方法,然后我在主方法里创建了一个Test对象,并使其引用为空(此时符合回收条件)我们先调用System.gc()
结果:
调用
我们发现执行了finalize()方法,OK,我们现在将System.gc()注释掉,我们会发现并没有输出“调用”,也就是没有调用finalize()方法,这就是不一定每个垃圾对象jvm都会自动调用finalize()方法。
3、怎么解决 Kafka 数据丢失的问题
1)消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况,就是说,你那个消费到了这个消息,然后消费者那边自动提交了offset,让kafka以为你已经消费好了这个消息,其实你刚准备处理这个消息,你还没处理,你自己就挂了,此时这条消息就丢咯。
这不是一样么,大家都知道kafka会自动提交offset,那么只要关闭自动提交offset,在处理完之后自己手动提交offset,就可以保证数据不会丢。但是此时确实还是会重复消费,比如你刚处理完,还没提交offset,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
生产环境碰到的一个问题,就是说我们的kafka消费者消费到了数据之后是写到一个内存的queue里先缓冲一下,结果有的时候,你刚把消息写入内存queue,然后消费者会自动提交offset。
然后此时我们重启了系统,就会导致内存queue里还没来得及处理的数据就丢失了
2)kafka弄丢了数据
这块比较常见的一个场景,就是kafka某个broker宕机,然后重新选举partiton的leader时。大家想想,要是此时其他的follower刚好还有些数据没有同步,结果此时leader挂了,然后选举某个follower成leader之后,他不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前kafka的leader机器宕机了,将follower切换为leader之后,就会发现说这个数据就丢了
所以此时一般是要求起码设置如下4个参数:
给这个topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本
在kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧
在producer端设置acks=all:这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了
在producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了
我们生产环境就是按照上述要求配置的,这样配置之后,至少在kafka broker端就可以保证在leader所在broker发生故障,进行leader切换时,数据不会丢失
3)生产者会不会弄丢数据
如果按照上述的思路设置了ack=all,一定不会丢,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
4、zookeeper 是如何保证数据一致性的
ZooKeeper是个集群,内部有多个server,每个server都可以连接多个client,每个client都可以修改server中的数据
ZooKeeper可以保证每个server内的数据完全一致,是如何实现的呢?
答:数据一致性是靠Paxos算法保证的,Paxos可以说是分布式一致性算法的鼻祖,是ZooKeeper的基础
Paxos的基本思路:(深入解读zookeeper一致性原理)
假设有一个社团,其中有团员、议员(决议小组成员)两个角色
团员可以向议员申请提案来修改社团制度
议员坐在一起,拿出自己收到的提案,对每个提案进行投票表决,超过半数通过即可生效
为了秩序,规定每个提案都有编号ID,按顺序自增
每个议员都有一个社团制度笔记本,上面记着所有社团制度,和最近处理的提案编号,初始为0
投票通过的规则:
新提案ID 是否大于 议员本中的ID,是议员举手赞同
如果举手人数大于议员人数的半数,即让新提案生效
例如:
刚开始,每个议员本子上的ID都为0,现在有一个议员拿出一个提案:团费降为100元,这个提案的ID自增为1
每个议员都和自己ID对比,一看 1>0,举手赞同,同时修改自己本中的ID为1
发出提案的议员一看超过半数同意,就宣布:1号提案生效
然后所有议员都修改自己笔记本中的团费为100元
以后任何一个团员咨询任何一个议员:“团费是多少?”,议员可以直接打开笔记本查看,并回答:团费为100元
可能会有极端的情况,就是多个议员一起发出了提案,就是并发的情况
例如
刚开始,每个议员本子上的编号都为0,现在有两个议员(A和B)同时发出了提案,那么根据自增规则,这两个提案的编号都为1,但只会有一个被先处理
假设A的提案在B的上面,议员们先处理A提案并通过了,这时,议员们的本子上的ID已经变为了1,接下来处理B的提案,由于它的ID是1,不大于议员本子上的ID,B提案就被拒绝了,B议员需要重新发起提案
上面就是Paxos的基本思路,对照ZooKeeper,对应关系就是:
团员 -client
议员 -server
议员的笔记本 -server中的数据
提案 -变更数据的请求
提案编号 -zxid(ZooKeeper Transaction Id)
提案生效 -执行变更数据的操作
ZooKeeper中还有一个leader的概念,就是把发起提案的权利收紧了,以前是每个议员都可以发起提案,现在有了leader,大家就不要七嘴八舌了,先把提案都交给leader,由leader一个个发起提案
Paxos算法就是通过投票、全局编号机制,使同一时刻只有一个写操作被批准,同时并发的写操作要去争取选票,只有获得过半数选票的写操作才会被批准,所以永远只会有一个写操作得到批准,其他的写操作竞争失败只好再发起一轮投票
1)一致性保证
Zookeeper是一种高性能、可扩展的服务。Zookeeper的读写速度非常快,并且读的速度要比写的速度更快。另外,在进行读操作的时候,ZooKeeper依然能够为旧的数据提供服务。这些都是由于ZooKeepe所提供的一致性保证,它具有如下特点:
顺序一致性
客户端的更新顺序与它们被发送的顺序相一致。
原子性
更新操作要么成功要么失败,没有第三种结果。
单系统镜像
无论客户端连接到哪一个服务器,客户端将看到相同的ZooKeeper视图。
可靠性
一旦一个更新操作被应用,那么在客户端再次更新它之前,它的值将不会改变。。这个保证将会产生下面两种结果:
1.如果客户端成功地获得了正确的返回代码,那么说明更新已经成果。如果不能够获得返回代码(由于通信错误、超时等等),那么客户端将不知道更新操作是否生效。
2.当从故障恢复的时候,任何客户端能够看到的执行成功的更新操作将不会被回滚。
实时性
在特定的一段时间内,客户端看到的系统需要被保证是实时的(在十几秒的时间里)。在此时间段内,任何系统的改变将被客户端看到,或者被客户端侦测到。
给予这些一致性保证,ZooKeeper更高级功能的设计与实现将会变得非常容易,例如:leader选举、队列以及可撤销锁等机制的实现。
2)Leader选举
ZooKeeper需要在所有的服务(可以理解为服务器)中选举出一个Leader,然后让这个Leader来负责管理集群。此时,集群中的其它服务器则成为此Leader的Follower。并且,当Leader故障的时候,需要ZooKeeper能够快速地在Follower中选举出下一个Leader。这就是ZooKeeper的Leader机制,下面我们将简单介绍在ZooKeeper中,Leader选举(Leader Election)是如何实现的。
此操作实现的核心思想是:首先创建一个EPHEMERAL目录节点,例如“/election”。然后。每一个ZooKeeper服务器在此目录下创建一个SEQUENCE|EPHEMERAL 类型的节点,例如“/election/n_”。在SEQUENCE标志下,ZooKeeper将自动地为每一个ZooKeeper服务器分配一个比前一个分配的序号要大的序号。此时创建节点的ZooKeeper服务器中拥有最小序号编号的服务器将成为Leader。
在实际的操作中,还需要保障:当Leader服务器发生故障的时候,系统能够快速地选出下一个ZooKeeper服务器作为Leader。一个简单的解决方案是,让所有的follower监视leader所对应的节点。当Leader发生故障时,Leader所对应的临时节点将会自动地被删除,此操作将会触发所有监视Leader的服务器的watch。这样这些服务器将会收到Leader故障的消息,并进而进行下一次的Leader选举操作。但是,这种操作将会导致“从众效应”的发生,尤其当集群中服务器众多并且带宽延迟比较大的时候,此种情况更为明显。
在Zookeeper中,为了避免从众效应的发生,它是这样来实现的:每一个follower对follower集群中对应的比自己节点序号小一号的节点(也就是所有序号比自己小的节点中的序号最大的节点)设置一个watch。只有当follower所设置的watch被触发的时候,它才进行Leader选举操作,一般情况下它将成为集群中的下一个Leader。很明显,此Leader选举操作的速度是很快的。因为,每一次Leader选举几乎只涉及单个follower的操作。
5、hadoop 和 spark 在处理数据时,处理出现内存溢出的方法有哪些?
- map过程产生大量对象导致内存溢出
这种溢出的原因是在单个map中产生了大量的对象导致的。
例如:rdd.map(x=>for(i <- 1 to 10000) yield i.toString),这个操作在rdd中,每个对象都产生了10000个对象,这肯定很容易产生内存溢出的问题。针对这种问题,在不增加内存的情况下,可以通过减少每个Task的大小,以便达到每个Task即使产生大量的对象Executor的内存也能够装得下。具体做法可以在会产生大量对象的map操作之前调用repartition方法,分区成更小的块传入map。例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。
面对这种问题注意,不能使用rdd.coalesce方法,这个方法只能减少分区,不能增加分区,不会有shuffle的过程。
2.数据不平衡导致内存溢出
数据不平衡除了有可能导致内存溢出外,也有可能导致性能的问题,解决方法和上面说的类似,就是调用repartition重新分区。这里就不再累赘了。
3.coalesce调用导致内存溢出
这是我最近才遇到的一个问题,因为hdfs中不适合存小问题,所以Spark计算后如果产生的文件太小,我们会调用coalesce合并文件再存入hdfs中。但是这会导致一个问题,例如在coalesce之前有100个文件,这也意味着能够有100个Task,现在调用coalesce(10),最后只产生10个文件,因为coalesce并不是shuffle操作,这意味着coalesce并不是按照我原本想的那样先执行100个Task,再将Task的执行结果合并成10个,而是从头到位只有10个Task在执行,原本100个文件是分开执行的,现在每个Task同时一次读取10个文件,使用的内存是原来的10倍,这导致了OOM。解决这个问题的方法是令程序按照我们想的先执行100个Task再将结果合并成10个文件,这个问题同样可以通过repartition解决,调用repartition(10),因为这就有一个shuffle的过程,shuffle前后是两个Stage,一个100个分区,一个是10个分区,就能按照我们的想法执行。
4.shuffle后内存溢出
shuffle内存溢出的情况可以说都是shuffle后,单个文件过大导致的。在Spark中,join,reduceByKey这一类型的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism参数只对HashPartitioner有效,所以如果是别的Partitioner或者自己实现的Partitioner就不能使用spark.default.parallelism这个参数来控制shuffle的并发量了。如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
- standalone模式下资源分配不均匀导致内存溢出
在standalone的模式下如果配置了–total-executor-cores 和 –executor-memory 这两个参数,但是没有配置–executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
6.在RDD中,共用对象能够减少OOM的情况
这个比较特殊,这里说记录一下,遇到过一种情况,类似这样rdd.flatMap(x=>for(i <- 1 to 1000) yield (“key”,”value”))导致OOM,但是在同样的情况下,使用rdd.flatMap(x=>for(i <- 1 to 1000) yield “key”+”value”)就不会有OOM的问题,这是因为每次(“key”,”value”)都产生一个Tuple对象,而”key”+”value”,不管多少个,都只有一个对象,指向常量池。具体测试如下:

这个例子说明(“key”,”value”)和(“key”,”value”)在内存中是存在不同位置的,也就是存了两份,但是”key”+”value”虽然出现了两次,但是只存了一份,在同一个地址,这用到了JVM常量池的知识.于是乎,如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用.
6、java 实现快速排序
高快省的排序算法
有没有既不浪费空间又可以快一点的排序算法呢?那就是“快速排序”啦!光听这个名字是不是就觉得很高端呢。
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这个10个数进行排序。首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,就是一个用来参照的数,待会你就知道它用来做啥的了)。为了方便,就让第一个数6作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在6的右边,比基准数小的数放在6的左边,类似下面这种排列:
3 1 2 5 4 6 9 7 10 8
在初始状态下,数字6在序列的第1位。我们的目标是将6挪到序列中间的某个位置,假设这个位置是k。现在就需要寻找这个k,并且以第k位为分界点,左边的数都小于等于6,右边的数都大于等于6。想一想,你有办法可以做到这点吗?
排序算法显神威
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
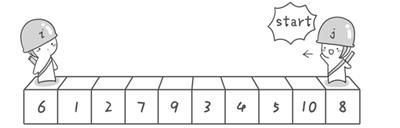
首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j–),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。

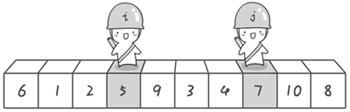
现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下:
6 1 2 5 9 3 4 7 10 8
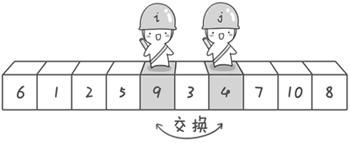

到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
6 1 2 5 4 3 9 7 10 8
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下:
3 1 2 5 4 6 9 7 10 8
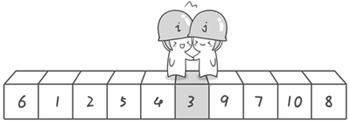
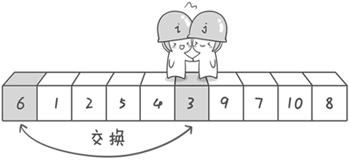
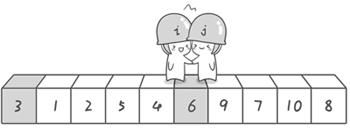
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
OK,解释完毕。现在基准数6已经归位,它正好处在序列的第6位。此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列。因为6左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。现在先来处理6左边的序列现吧。
左边的序列是“3 1 2 5 4”。请将这个序列以3为基准数进行调整,使得3左边的数都小于等于3,3右边的数都大于等于3。好了开始动笔吧
如果你模拟的没有错,调整完毕之后的序列的顺序应该是:
2 1 3 5 4
OK,现在3已经归位。接下来需要处理3左边的序列“2 1”和右边的序列“5 4”。对序列“2 1”以2为基准数进行调整,处理完毕之后的序列为“1 2”,到此2已经归位。序列“1”只有一个数,也不需要进行任何处理。至此我们对序列“2 1”已全部处理完毕,得到序列是“1 2”。序列“5 4”的处理也仿照此方法,最后得到的序列如下:
1 2 3 4 5 6 9 7 10 8
对于序列“9 7 10 8”也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列,如下
1 2 3 4 5 6 7 8 9 10
到此,排序完全结束。细心的同学可能已经发现,快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。下面上个霸气的图来描述下整个算法的处理过程。

这是为什么呢?
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。其实快速排序是基于一种叫做“二分”的思想。我们后面还会遇到“二分”思想,到时候再聊。先上代码,如下
代码实现:
public class QuickSort {
public static void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位
temp = arr[low];
while (i=arr[i]&&i }
public static void main(String[] args){
int[] arr = {10,7,2,4,7,62,3,4,2,1,8,9,19};
quickSort(arr, 0, arr.length-1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
输出为
1
2
2
3
4
4
7
7
8
9
10
19
62
7、设计微信群发红包数据库表结构(包含表名称、字段名称、类型)
举例:
drop table if exists wc_groupsend_rp;
create external table wc_groupsend_rp (
imid string, --设备ID
wcid string, --微信号
wcname string, --微信名
wcgroupName string, --群名称
rpamount double, --红包金额
rpid string, --红包标识
rpcount int, --红包数量
rptype int, --红包类型 比如1拼手气红包,2为普通红包,3为指定人领取红包
giverpdt string, --发红包时间
setuprpdt string, --创建红包时间 点击红包按钮的时间 paydt string, --支付时间
) COMMENT ‘群发红包表’
PARTITIONED BY (giverpdt string)
row format delimited fields terminated by ‘\t’;
drop table if exists wc_groupcash_rp;
create external table wc_groupcash_rp (
rpid string, --红包标识
imid string, --设备ID
wcid string, --微信号
wcname string, --微信名
wcgroupName string, --群名称
cashdt stirng, --红包领取时间 每领取一次更新一条数据
cashcount int, --领取人数
cashamount double, --领取金额
cashwcid string, --领取人的微信
cashwcname string, --领取人微信昵称
cashsum double, --已领取总金额
) COMMENT ‘红包领取表’
PARTITIONED BY (rpid string)
row format delimited fields terminated by ‘\t’;
8、如何选型:业务场景、性能要求、维护和扩展性、成本、开源活跃度
9、Spark如何调优
1)使用foreachPartitions替代foreach。
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可以提升30%以上。
2)设置num-executors参数
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:该参数设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。针对数据交换的业务场景,建议该参数设置1-5。
3)设置executor-memory参数
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常也有直接的关联。
参数调优建议:针对数据交换的业务场景,建议本参数设置在512M及以下。
4) executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。建议,如果是跟他人共享一个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,避免影响其他人的作业运行。
5) driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置512M以下就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
6) spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:如果不设置这个参数, Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,此时可以充分地利用Spark集群的资源。针对数据交换的场景,建议此参数设置为1-10。
7) spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。针对数据交换的场景,建议降低此参数值到0.2-0.4。
8) spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。针对数据交换的场景,建议此值设置为0.1或以下。
资源参数参考示例
以下是一份spark-submit命令的示例,可以参考一下,并根据自己的实际情况进行调节:
./bin/spark-submit \
–master yarn-cluster \
–num-executors 1 \
–executor-memory 512M \
–executor-cores 2 \
–driver-memory 512M \
–conf spark.default.parallelism=2 \
–conf spark.storage.memoryFraction=0.2 \
–conf spark.shuffle.memoryFraction=0.1 \
10、Flink和spark的通信框架有什么异同
首先它们有哪些共同点?flink和spark都是apache 软件基金会(ASF)旗下顶级项目,都是通用数据处理平台。它们可以应用在很多的大数据应用和处理环境。并且有如下扩展:
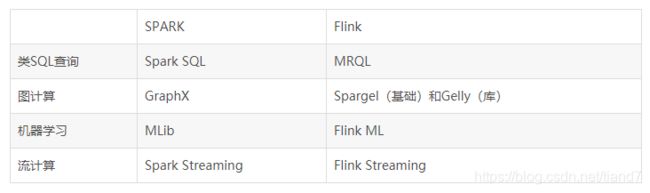
并且两者均可在不依赖于其他环境的情况下运行于standalone模式,或是运行在基于hadoop(YARN,HDFS)之上,由于它们均是运行于内存,所以他们表现的都比hadoop要好很多。
然而它们在实现上还是有很多不同点:
在spark 1.5.x之前的版本,数据集的大小不能大于机器的内存数。
Flink在进行集合的迭代转换时可以是循环或是迭代计算处理。这使得Join算法、对分区的链接和重用以及排序可以选择最优算法。当然flink也是一个很强大的批处理工具。flink的流式处理的是真正的流处理。流式数据一但进入就实时进行处理,这就允许流数据灵活地在操作窗口。它甚至可以在使用水印的流数中处理数据(It is even capable of handling late data in streams by the use of watermarks)。此外,flink的代码执行引擎还对现有使用storm,mapreduce等有很强的兼容性。
Spark 在另一方面是基于 弹性分布式数据集(RDD),这(主要的)给于spark基于内存内数据结构的函数式编程。它可以通过固定的内存给于大批量的计算。spark streaming 把流式数据封装成小的批处理,也就是它收集在一段时间内到达的所有数据,并在收集的数据上运行一个常规批处理程序。同时一边收集下一个小的批处理数据。
11、Java的代理
代理模式是什么
代理模式是一种设计模式,简单说即是在不改变源码的情况下,实现对目标对象的功能扩展。
比如有个歌手对象叫Singer,这个对象有一个唱歌方法叫sing()。
public class Singer{
public void sing(){
System.out.println(“唱一首歌”);
}
}
假如你希望,通过你的某种方式生产出来的歌手对象,在唱歌前后还要想观众问好和答谢,也即对目标对象Singer的sing方法进行功能扩展。
public void sing(){
System.out.println(“向观众问好”);
System.out.println(“唱一首歌”);
System.out.println(“谢谢大家”);
}
但是往往你又不能直接对源代码进行修改,可能是你希望原来的对象还保持原来的样子,又或许你提供的只是一个可插拔的插件,甚至你有可能都不知道你要对哪个目标对象进行扩展。这时就需要用到java的代理模式了。网上好多用生活中的经理人的例子来解释“代理”,看似通俗易懂,但我觉得不适合程序员去理解。程序员应该从代码的本质入手。
Java的三种代理模式
想要实现以上的需求有三种方式,这一部分我们只看三种模式的代码怎么写,先不涉及实现原理的部分。
1.静态代理
public interface ISinger {
voidsing();
}
/**
- 目标对象实现了某一接口
/
public class Singer implements ISinger{
public void sing(){
System.out.println(“唱一首歌”);
}
}
/* - 代理对象和目标对象实现相同的接口
*/
public class SingerProxy implementsI Singer{
//接收目标对象,以便调用sing方法
private ISinger target;
public UserDaoProxy(ISinger target){
this.target=target;
}
//对目标对象的sing方法进行功能扩展
public void sing() {
System.out.println(“向观众问好”);
target.sing();
System.out.println(“谢谢大家”);
}
}
测试
/**
- 测试类
*/
public classTest {
public static void main(String[] args) {
//目标对象
ISinger target =newSinger();
//代理对象
ISinger proxy =newSingerProxy(target);
//执行的是代理的方法
proxy.sing();
}
}
总结:其实这里做的事情无非就是,创建一个代理类SingerProxy,继承了ISinger接口并实现了其中的方法。只不过这种实现特意包含了目标对象的方法,正是这种特征使得看起来像是“扩展”了目标对象的方法。假使代理对象中只是简单地对sing方法做了另一种实现而没有包含目标对象的方法,也就不能算作代理模式了。所以这里的包含是关键。
缺点:这种实现方式很直观也很简单,但其缺点是代理对象必须提前写出,如果接口层发生了变化,代理对象的代码也要进行维护。如果能在运行时动态地写出代理对象,不但减少了一大批代理类的代码,也少了不断维护的烦恼,不过运行时的效率必定受到影响。这种方式就是接下来的动态代理。
2.动态代理(也叫JDK代理)
跟静态代理的前提一样,依然是对Singer对象进行扩展
public interface ISinger {
void sing();
}
/**
- 目标对象实现了某一接口
*/
public class Singer implements ISinger{
public void sing(){
System.out.println(“唱一首歌”);
}
}
这回直接上测试,由于java底层封装了实现细节(之后会详细讲),所以代码非常简单,格式也基本上固定。
调用Proxy类的静态方法newProxyInstance即可,该方法会返回代理类对象
static Object newProxyInstance(ClassLoader loader, Class[] interfaces,InvocationHandler h )
接收的三个参数依次为:
·ClassLoader loader:指定当前目标对象使用类加载器,写法固定
·Class[] interfaces:目标对象实现的接口的类型,写法固定
·InvocationHandler h:事件处理接口,需传入一个实现类,一般直接使用匿名内部类
测试代码
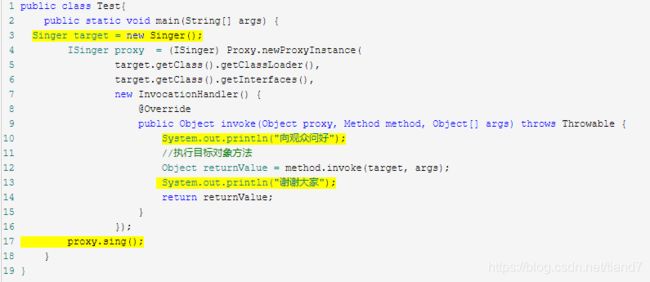
总结:以上代码只有标黄的部分是需要自己写出,其余部分全都是固定代码。由于java封装了newProxyInstance这个方法的实现细节,所以使用起来才能这么方便,具体的底层原理将会在下一小节说明。
缺点:可以看出静态代理和JDK代理有一个共同的缺点,就是目标对象必须实现一个或多个接口,加入没有,则可以使用Cglib代理。
3.Cglib代理
前提条件:
需要引入cglib的jar文件,由于Spring的核心包中已经包括了Cglib功能,所以也可以直接引入spring-core-3.2.5.jar
目标类不能为final
目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法


这里的代码也非常固定,只有标黄部分是需要自己写出
测试

总结:三种代理模式各有优缺点和相应的适用范围,主要看目标对象是否实现了接口。以Spring框架所选择的代理模式举例
在Spring的AOP编程中:
如果加入容器的目标对象有实现接口,用JDK代理
如果目标对象没有实现接口,用Cglib代理
12、Java的内存溢出和内存泄漏
1.内存溢出和内存泄漏是啥
。内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
。内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间。
是不是觉得上文中的内存泄漏的定义比较难理解?
其实,内存泄漏用粗俗一点的话来说就是“占着茅坑不拉粑粑”。
什么意思呢?就是说,你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),而你自己出于某些原因不能再访问到那块内存(也许你把它的地址给弄丢了),这时候系统也不能再次将它分配给需要的程序。
这里需要注意一点,即一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
危害到底有多重呢?举个例子,上文我们说到“占着茅坑不拉粑粑”,假设这个厕所有五个蹲位,那么一个人占用了一个且不离开,别人又拿它没有办法,那这个蹲位就用不了了,现在就只剩下四个。这样似乎还可以接受,那么当三个蹲位被占用且无法被释放的时候,剩下的两个蹲位的压力就很大了。当五个蹲位都被占用且无法释放的时候,就没有蹲位了,那些排队等待拉粑粑的人就没有地方宣泄自己的粑粑,这麻烦就大了。万一人家拉裤子了咋办呢?对吧。内存泄漏也是这样。
而对于溢出来说,一个盘子用尽各种方法只能装4个果子,你装了5个,结果掉倒地上不能吃了。这就是溢出!又比方说栈,栈满时再做进栈必定产生空间溢出,叫上溢,栈空时再做退栈也产生空间溢出,称为下溢。分配的内存不足以放下数据项序列,称为内存溢出.
注:memory leak会最终会导致out of memory!

2.内存泄漏的分类
发生的方式来分类的话,内存泄漏可以分为4类:
常发性内存泄漏:发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
偶发性内存泄漏:发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
一次性内存泄漏:发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
隐式内存泄漏:程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。上文也有说到,真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到。所以我等程序员们在写代码的时候要养成好的习惯哦(在这一点上,Java的回收机制就做的很好)。
3.内存溢出的原因
内存溢出常见的原因有以下几种:
。内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
。集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
。代码中存在死循环或循环产生过多重复的对象实体;
。使用的第三方软件中的BUG;
。启动参数内存值设定的过小
会出现问题,自然也就有解决办法了。
4.内存溢出的解决方案:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
第四步,使用内存查看工具动态查看内存使用情况。
其中,第三步重点排查以下几点:
。检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
。检查代码中是否有死循环或递归调用。
。检查是否有大循环重复产生新对象实体。
。检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询。
。检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。
好啦,这次关于内存泄漏和内存溢出的探秘就算总结完啦,当然,内存绝对不止是这些知识点,如果大家有什么别的发现,或者发现了我文中表述不对的地方,欢迎和我们一起讨论学习。
13、hadoop 的组件有哪些?Yarn的调度器有哪些?
Hadoop常用组件介绍
1、Hive
Hive是将Hadoop包装成使用简单的软件,用户可以用比较熟悉的SQL语言来调取数据,也就是说,Hive其实就是将Hadoop包装成MySQL。Hive适合使用在对实时性要求不高的结构化数据处理。像是每天、每周用户的登录次数、登录时间统计;每周用户增长比例之类的BI应用。
2、HBase
HBase是用来储存和查询非结构化和半结构化数据的工具,利用row key的方式来访问数据。HBase适合处理大量的非结构化数据,例如图片、音频、视频等,在训练机器学习时,可以快速的透过标签将相对应的数据全部调出。
3、Storm
前面两个都是用来处理非实时的数据,对于某些讲求高实时性(毫秒级)的应用,就需要使用Storm。Storm也是具有容错和分布式计算的特性,架构为master-slave,可横向扩充多节点进行处理,每个节点每秒可以处理上百万条记录。可用在金融领域的风控上。
4、Impala
Impala和Hive的相似度很高,最大的不同是Impala使用了基于MPP的SQL查询,实时性比MapReduce好很多,但是无法像Hive一样可以处理大量的数据。Impala提供了快速轻量查询的功能,方便开发人员快速的查询新产生的数据。
YRAN提供了三种调度策略
一、FIFO-先进先出调度器
YRAN默认情况下使用的是该调度器,即所有的应用程序都是按照提交的顺序来执行的,这些应用程序都放在一个队列中,只有在前面的一个任务执行完成之后,才可以执行后面的任务,依次执行
缺点:如果有某个任务执行时间较长的话,后面的任务都要处于等待状态,这样的话会造成资源的使用率不高;如果是多人共享集群资源的话,缺点更是明显
二、capacity-scheduler-容量调度器
针对多用户的调度,容量调度器采用的方法稍有不同。集群由很多的队列组成(类似于任务池),这些队列可能是层次结构的(因此,一个队列可能是另一个队列的子队列),每个队列被分配有一定的容量。这一点于公平调度器类似,只不过在每个队列的内部,作业根据FIFO的方式(考虑优先级)调度。本质上,容量调度器允许用户或组织(使用队列自行定义)为每个用户或组织模拟出一个使用FIFO调度策略的独立MapReduce集群。相比之下,公平调度器(实际上也支持作业池内的FIFO调度,使其类似于容量调度器)强制池内公平共享,使运行的作业共享池内的资源。
总结:容量调度器具有以下几个特点
1、集群按照队列为单位划分资源,这些队列可能是层次结构的
2、可以控制每个队列的最低保障资源和最高使用限制,最高使用限制是为了防止该队列占用过多的空闲资源导致其他的队列资源紧张
3、可以针对用户设置每个用户的资源最高使用限制,防止该用户滥用资源
4、在每个队列内部的作业调度是按照FIFO的方式调度的
5、如果某个队列的资源使用紧张,但是另一个队列的资源比较空闲,此时可以将空闲的资源暂时借用,但是一旦被借用资源的队列有新的任务提交之后,此时被借用出去的资源将会被释放还回给原队列
6、每一个队列都有严格的访问控制,只有那些被授权了的用户才可以查看任务的运行状态。
配置文件的说明(capacity-scheduler.xml):



三、Fair-scheduler-公平调度器
所谓的公平调度器指的是,旨在让每个用户公平的共享集群的能力。如果是只有一个作业在运行的话,就会得到集群中所有的资源。随着提交的作业越来越多,限制的任务槽会以“让每个用户公平共享集群”这种方式进行分配。某个用户的好事短的作业将在合理的时间内完成,即便另一个用户的长时间作业正在运行而且还在运行过程中。
作业都是放在作业池中的,默认情况下,每个用户都有自己的作业池。提交作业数较多的用户,不会因此而获得更多的集群资源。可以用map和reduce的任务槽数来定制作业池的最小容量,也可以设置每个池的权重。
公平调度器支持抢占机制。所以,如果一个池在特定的一段时间内未能公平的共享资源,就会终止运行池中得到过多的资源的任务,把空出来的任务槽让给运行资源不足的作业池。
主要特点:
1、也是将集群的资源以队列为单位进行划分,称为队列池
2、每个用户都有自己的队列池,如果该队列池中只有一个任务的话,则该任务会使用该池中的所有资源
3、每个用户提交作业都是提交到自己的队列池中,所以,提交作业数较多的用户,并不会因此而获得更多的集群资源
4、支持抢占机制。也就是说如果一个吃在特定的时间内未能公平的共享资源,就会终止池中占用过多资源的任务,将空出来的任务槽让给运行资源不足的作业池。
5、负载均衡:提供一个基于任务数目的负载均衡机制。该机制尽可能的将任务均匀的分配到集群的所有的节点上。
14、hadoop 的 shuffle 过程
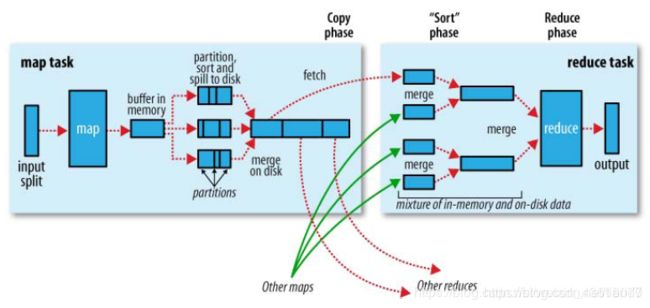
流程解释:
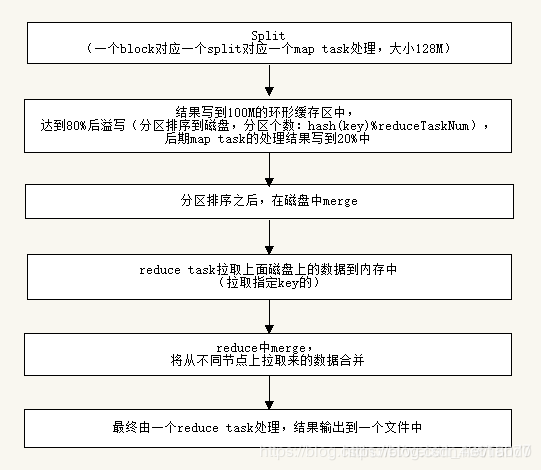
以wordcount为例,假设有5个map和3个reduce:
map阶段
1、在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。
2、在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“hello”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。这个job有3个reduce task,到底当前的“hello”应该交由哪个reduce去做呢,是需要现在决定的。
分区(partition)
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
一个split被分成了3个partition。
排序sort
在spill写入之前,会先进行二次排序,**首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。**partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。
溢写(spill)
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中, 缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。 当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8。
将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,MapReduce任务结束后就会被删除)。
合并(merge)
每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。这个操作就叫merge(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。一个map最终会溢写一个文件。
至此,Map的shuffle过程就结束了。
Reduce阶段
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
copy
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),**所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。**每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
merge
Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
这里需要强调的是:
merge阶段,也称为sort阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。
merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。
当copy到内存中的数据量到达一定阈值,就启动内存到磁盘的merge,即第二种merge方式,与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。这种merge方式一直在运行,直到没有map端的数据时才结束。
然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
reduce
不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,参见性能优化篇。
然后就是Reducer执行,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
15、简述Spark集群运行的几种模式
a.local本地模式
b.Spark内置standalone集群模式
c.Yarn集群模式
16、RDD 中的 reducebyKey 与 groupByKey 哪个性能高?
17、简述 HBase 的读写过程
18、在 2.5亿个整数中,找出不重复的整数,注意:内存不足以容纳 2.5亿个整数。
19、CDH 和 HDP 的区别
20、Java原子操作
21、Java封装、继承和多态
22、JVM 模型
23、Flume taildirSorce 重复读取数据解决方法
24、Flume 如何保证数据不丢
25、Java 类加载过程
26、Spark Task 运行原理
27、手写一个线程安全的单例
28、设计模式
29、impala 和 kudu 的适用场景,读写性能如何
30、Kafka ack原理
31、phoenix 创建索引的方式及区别
32、Flink TaskManager 和 Job Manager 通信
33、Flink 双流 join方式
34、Flink state 管理和 checkpoint 的流程
35、Flink 分层架构
36、Flink 窗口
37、Flink watermark 如何处理乱序数据
38、Flink time
39、Flink支持exactly-once 的 sink 和 source
40、Flink 提交作业的流程
41、Flink connect 和 join 区别
42、重启 task 的策略
43、hive 的锁
44、hive sql 优化方式
45、hadoop shuffle 过程和架构
46、如何优化 shuffle过程
47、冒泡排序和快速排序
48、讲讲Spark的stage
49、spark mkrdd和Parrallilaze函数区别
50、Spark checkpoint 过程
51、二次排序
52、如何注册 hive udf
53、SQL去重方法
54、Hive分析和窗口函数
55、Hadoop 容错,一个节点挂掉然后又上线
56、掌握 JVM 原理
57、Java 并发原理
58、多线程的实现方法
59、RocksDBStatebackend实现(源码级别)
60、HashMap、ConcurrentMap和 Hashtable 区别
61、Flink Checkpoint 是怎么做的,作用到算子还是chain
62、Checkpoint失败了的监控
63、String、StringBuffer和 StringBuilder的区别
64、Kafka存储流程,为什么高吞吐?
65、Spark优化方法举例
66、keyby的最大并行度
67、Flink 优化方法
68、Kafka ISR 机制
69、Kafka partition的4个状态
70、Kafka 副本的7个状态
71、Flink taskmanager的数量
72、if 和 switch 的性能及 switch 支持的参数
73、kafka 零拷贝
74、hadoop 节点容错机制
75、HDFS 的副本分布策略
76、Hadoop面试题汇总,大概都在这里(https://www.cnblogs.com/gala1021/p/8552850.html)
77、Kudu 和Impala 权限控制
78、Time_wait状态?当server处理完client的请求后立刻closesocket此时会出现time_wait状态
79、三次握手交换了什么?(SYN,ACK,SEQ,窗口大小) 3次握手建立链接,4次握手断开链接。
80、hashmap 1.7和1.8 的区别
81、concurrenthashmap 1.7和1.8?
82、Kafka 的ack
83、sql 去重方法(group by 、distinct、窗口函数)
84、哪些 Hive sql 不能在 Spark sql 上运行,看这里:https://spark.apache.org/docs/2.2.0/sql-programming-guide.html#unsupported-hive-functionality
85、什么情况下发生死锁
86、事务隔离级别?可重复读、不可重复读、读未提交、串行化
87、Spark shuffle 和 Hadoop shuffle的异同
88、Spark静态内存和动态内存
89、mysql btree 和 hash tree 的区别。btree 需要唯一主键,hash tree 适合>= 等,精确匹配,不适合范围检索
90、udf、udtf和 udaf 的区别
91、hive sql 的执行过程
92、spark sql 的执行过程
93、找出数组中最长的top10字符串
94、Flink 数据处理流程
95、Flink 与 Spark streaming 对比
96、Flink watermark 使用
97、窗口与流的结合
98、Flink 实时告警设计
99、Java:面向对象、容器、多线程、单例
100、Flink:部署、API、状态、checkpoint、savepoint、watermark、重启策略、datastream 算子和优化、job和task状态
101、Spark:原理、部署、优化
102、Kafka:读写原理、使用、优化
103、hive的外部表
104、spark的函数式编程
105、线性数据结构和数据结构
106、Spark映射,RDD
107、java的内存溢出和内存泄漏
108、多线程的实现方法
109、HashMap、ConcurrentMap和 Hashtable 区别
110、Flink Checkpoint 是怎么做的,作用到算子还是chain
111、Checkpoint失败了的监控
112、String、StringBuffer和 StringBuilder的区别
113、Kafka存储流程,为什么高吞吐
114、Spark 优化方法举例
115、keyby 的最大并行度
116、Flink 优化方法
117、Kafka ISR 机制
118、kafka partition 的状态
119、kafka 副本的状态
120、taskmanager 的数量
121、if 和switch的性能区别
122、Hdfs读写流程(结合cap理论讲)
123、技术选型原则
124、Kafka组件介绍
125、g1和cms的区别
126、讲讲最熟悉的数据结构
127、spark oom处理方法
128、看了哪些源码
129、Spark task原理
130、解决过的最有挑战的问题
131、Hbase读写流程