深度学习基础宝典---激活函数、Batch Size、归一化
博客首页:knighthood2001
欢迎点赞评论️
❤️ 热爱python,期待与大家一同进步成长!!❤️
给大家推荐一款很火爆的刷题、面试求职网站
目录
激活函数
常见的激活函数及图像
1.sigmoid 激活函数
2.tanh激活函数
3.Relu激活函数
4.Leak Relu 激活函数
5.SoftPlus 激活函数
6.softmax 函数
激活函数有哪些性质?
如何选择激活函数?
Batch Size
Batch Size 值的选择
在合理范围内,增大Batch_Size有何好处?
调节 Batch_Size 对训练效果影响到底如何?
归一化
归一化含义
为什么要归一化?
为什么归一化能提高求解最优解速度?
学习率
学习率的作用
学习率衰减常用参数有哪些
常见的学习率衰减方法
分段常数衰减
指数衰减
自然指数衰减
多项式衰减
余弦衰减
深度学习中常用的数据增强方法
结尾
激活函数
激活函数(Activation Function),是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
为什么需要激活函数?
- 激活函数对模型学习、理解非常复杂和非线性的函数具有重要作用。
- 激活函数可以引入非线性因素。如果不使用激活函数,则输出信号仅是一个简单的线性函数。线性函数一个一级多项式,线性方程的复杂度有限,从数据中学习复杂函数映射的能力很小。没有激活函数,神经网络将无法学习和模拟其他复杂类型的数据,例如图像、视频、音频、语音等。
- 激活函数可以把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
为什么激活函数需要非线性函数?
- 假若网络中全部是线性部件,那么线性的组合还是线性,与单独一个线性分类器无异。这样就做不到用非线性来逼近任意函数。
- 使用非线性激活函数 ,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物,复杂的表单数据,以及表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
常见的激活函数及图像
1.sigmoid 激活函数
函数的定义为:![]() ,其值域为 (0,1) 。
,其值域为 (0,1) 。

2.tanh激活函数
函数的定义为:![]() 值域为 (-1,1) 。
值域为 (-1,1) 。

3.Relu激活函数
函数的定义为:![]() ,值域为 [0,+∞) ;
,值域为 [0,+∞) ;

4.Leak Relu 激活函数
函数定义为: 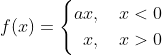 ,值域为 (-∞,+∞) 。
,值域为 (-∞,+∞) 。
图像如下( a = 0.5 ):
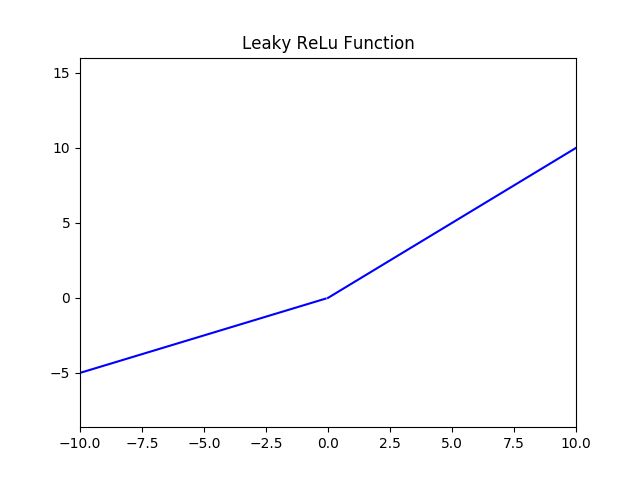
5.SoftPlus 激活函数
定义为:![]() ,值域为 (0,+∞) 。
,值域为 (0,+∞) 。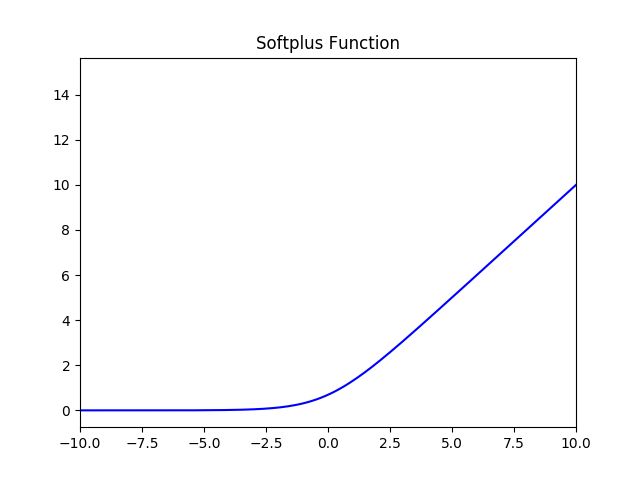
6.softmax 函数
函数定义为: ![]() 。
。
Softmax 多用于多分类神经网络输出。
激活函数有哪些性质?
- 非线性: 当激活函数是非线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即
 ,就不满足这个性质,而且如果多层感知机使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
,就不满足这个性质,而且如果多层感知机使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的; - 可微性: 当优化方法是基于梯度的时候,就体现了该性质;
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数;
- f'(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
- 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况下,一般需要更小的 Learning Rate。
如何选择激活函数?
选择一个适合的激活函数并不容易,需要考虑很多因素,通常的做法是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者测试集上进行评价。然后看哪一种表现的更好,就去使用它。
以下是常见的选择情况:
- 如果输出是 0、1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 Relu 函数。
- 如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当是负值的时候,导数等于 0。
- sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
- tanh 激活函数:tanh 是非常优秀的,几乎适合所有场合。
- ReLu 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu,再去尝试其他的激活函数。
- 如果遇到了一些死的神经元,我们可以使用 Leaky ReLU 函数。
Batch Size
Batch Size指的是一次训练所选取的样本数。Batch Size的大小影响模型的优化程度和速度。在理解这个之前,我们先区分一下Epoch、Batch和Iteration这3个概念的差别。
1、Epoch使用训练集的全部数据对模型进行一次完整训练,被称为一代训练;
2、Batch使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为一批数据;
3、Iteration是使用一个Batch数据集对模型进行一次参数更新的过程,被称为一次训练。
Batch Size 值的选择
假如每次只训练一个样本,即 Batch Size = 1。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。此时,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
既然 Batch Size 为全数据集或者Batch Size = 1都有各自缺点,可不可以选择一个适中的Batch Size值呢?此时,可采用批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
在合理范围内,增大Batch_Size有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch Size 越大,其确定的下降方向越准,引起训练震荡越小。
调节 Batch_Size 对训练效果影响到底如何?
- Batch Size 太小,模型表现效果极其糟糕(error飙升)。
- 随着 Batch Size 增大,处理相同数据量的速度越快。
- 随着 Batch Size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
归一化
归一化含义
-
归纳统一样本的统计分布性。归一化在 0-1之间是统计的概率分布,归一化在-1 - +1 之间是统计的坐标分布。
-
无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。
-
归一化是统一在 0-1 之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。
-
另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0 或与其均方差相比很小。
为什么要归一化?
- 为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
- 为了程序运行时收敛加快。
- 同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
- 避免神经元饱和。就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
- 保证输出数据中数值小的不被吞食。
为什么归一化能提高求解最优解速度?
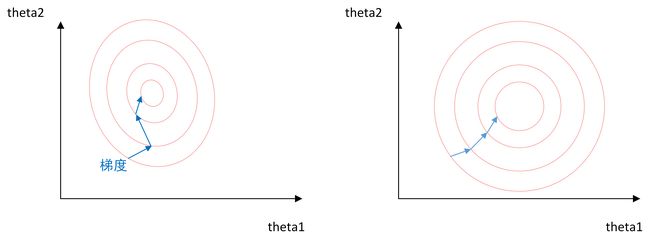
上图是代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
学习率
学习率的作用
在机器学习中,监督式学习通过定义一个模型,并根据训练集上的数据估计最优参数。梯度下降法是一个广泛被用来最小化模型误差的参数优化算法。梯度下降法通过多次迭代,并在每一步中最小化成本函数(cost 来估计模型的参数。学习率 (learning rate),在迭代过程中会控制模型的学习进度。
在梯度下降法中,都是给定的统一的学习率,整个优化过程中都以确定的步长进行更新, 在迭代优化的前期中,学习率较大,则前进的步长就会较长,这时便能以较快的速度进行梯度下降,而在迭代优化的后期,逐步减小学习率的值,减小步长,这样将有助于算法的收敛,更容易接近最优解。故而如何对学习率的更新成为了研究者的关注点。 在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、多项式衰减、指数衰减、自然指数衰减、余弦衰减、线性余弦衰减、噪声线性余弦衰减
学习率衰减常用参数有哪些
| 参数名称 | 参数说明 |
|---|---|
| learning_rate | 初始学习率 |
| global_step | 用于衰减计算的全局步数,非负,用于逐步计算衰减指数 |
| decay_steps | 衰减步数,必须是正值,决定衰减周期 |
| decay_rate | 衰减率 |
| end_learning_rate | 最低的最终学习率 |
| cycle | 学习率下降后是否重新上升 |
| alpha | 最小学习率 |
| num_periods | 衰减余弦部分的周期数 |
| initial_variance | 噪声的初始方差 |
| variance_decay | 衰减噪声的方差 |
常见的学习率衰减方法
分段常数衰减
分段常数衰减需要事先定义好的训练次数区间,在对应区间置不同的学习率的常数值,一般情况刚开始的学习率要大一些,之后要越来越小,要根据样本量的大小设置区间的间隔大小,样本量越大,区间间隔要小一点。下图即为分段常数衰减的学习率变化图,横坐标代表训练次数,纵坐标代表学习率。

指数衰减
以指数衰减方式进行学习率的更新,学习率的大小和训练次数指数相关,其衰减方式简单直接,收敛速度快,是最常用的学习率衰减方式,如下图所示,绿色的为学习率随 训练次数的指数衰减方式,红色的即为分段常数衰减,它在一定的训练区间内保持学习率不变。

自然指数衰减
它与指数衰减方式相似,不同的在于它的衰减底数是$e$,故而其收敛的速度更快,一般用于相对比较 容易训练的网络,便于较快的收敛,其更新规则如下
![]()
下图为为分段常数衰减、指数衰减、自然指数衰减三种方式的对比图,红色的即为分段常数衰减图,阶梯型曲线。蓝色线为指数衰减图,绿色即为自然指数衰减图,很明可以看到自然指数衰减方式下的学习率衰减程度要大于一般指数衰减方式,有助于更快的收敛。

多项式衰减
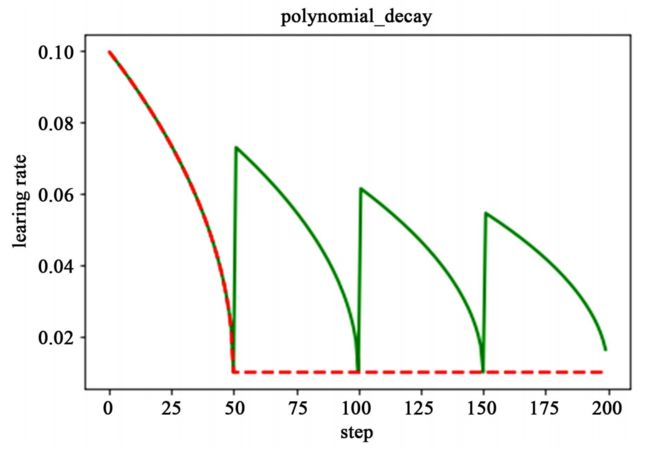
应用多项式衰减的方式进行更新学习率,这里会给定初始学习率和最低学习率取值,然后将会按照 给定的衰减方式将学习率从初始值衰减到最低值。
需要注意的是,有两个机制,降到最低学习率后,到训练结束可以一直使用最低学习率进行更新,另一个是再次将学习率调高,使用 decay_steps 的倍数,取第一个大于 global_steps 的结果,如下式所示.它是用来防止神经网络在训练的后期由于学习率过小而导致的网络一直在某个局部最小值附近震荡,这样可以通过在后期增大学习率跳出局部极小值。
如下图所示,红色线代表学习率降低至最低后,一直保持学习率不变进行更新,绿色线代表学习率衰减到最低后,又会再次循环往复的升高降低。
余弦衰减
余弦衰减就是采用余弦的相关方式进行学习率的衰减,衰减图和余弦函数相似。
如下图所示,红色即为标准的余弦衰减曲线,学习率从初始值下降到最低学习率后保持不变。蓝色的线是线性余弦衰减方式曲线,它是学习率从初始学习率以线性的方式下降到最低学习率值。绿色噪声线性余弦衰减方式。

深度学习中常用的数据增强方法
-
Color Jittering:对颜色的数据增强:图像亮度、饱和度、对比度变化(此处对色彩抖动的理解不知是否得当);
-
PCA Jittering:首先按照RGB三个颜色通道计算均值和标准差,再在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值,用来做PCA Jittering;
-
Random Scale:尺度变换;
-
Random Crop:采用随机图像差值方式,对图像进行裁剪、缩放;包括Scale Jittering方法(VGG及ResNet模型使用)或者尺度和长宽比增强变换;
-
Horizontal/Vertical Flip:水平/垂直翻转;
-
Shift:平移变换;
-
Rotation/Reflection:旋转/仿射变换;
-
Noise:高斯噪声、模糊处理;
-
Label Shuffle:类别不平衡数据的增广。
结尾
以上内容全部来自github上的,作者:scutan90 如果觉得有帮助的可以给作者点个star。
和我一起学习python和深度学习!!