前言
这两天把 html2canvas 这玩意抽丝剥茧了一下,搞了个勉强能跑的小 demo,麻雀虽小五脏俱全,来看看实现的效果吧(跟基金一样的绿,离离原上谱):
现在我们就来实现它。这里是项目地址。
感性认识
目前我们已知的是 html,然后要画到 canvas 上,具体该怎么操作呢?这里可以短暂思考几秒中。。。。ok,没思绪的同学可以瞅瞅下面这张图找找灵感:  上图就是把 html 转成 canvas 的三个小例子(背景、图片和文字),由此我们可以知道要想把 html 变成 canvas,只要把 html 转换成对应的 canvas 语言即可,也就是把上图中左边的代码变成右边的代码。有了这个感性认识,就可以动手开撸啦!
上图就是把 html 转成 canvas 的三个小例子(背景、图片和文字),由此我们可以知道要想把 html 变成 canvas,只要把 html 转换成对应的 canvas 语言即可,也就是把上图中左边的代码变成右边的代码。有了这个感性认识,就可以动手开撸啦!
第一步:解析 dom 树
要想把一个元素画到画布上,就得知道在哪里画(位置),画什么(类型),画成什么样(样式)。显然位置的话可以用 getBoundingClientRect 来获取,样式用 getComputedStyle 来获取,类型我们用 tagName 来区分是文本还是图片等等,不同类型处理方式不同。那要想获取上述所有信息,我们肯定要对 dom 进行解析啦,先来看看解析前后的对比图,有个直观印象: 
 显然,要保持原来的树形结构,遍历 dom 节点是必不可少的啦!大家不要觉得这个很难,遍历 dom 是件很简单的事情,看下面的代码就能够理解,注释也是应有尽有:
显然,要保持原来的树形结构,遍历 dom 节点是必不可少的啦!大家不要觉得这个很难,遍历 dom 是件很简单的事情,看下面的代码就能够理解,注释也是应有尽有:
// 按照原有的树结构遍历整个 dom,变成我们自己需要的新对象 ElContainer
// ElContainer 主要包括坐标位置和大小、样式、子元素等
class ElContainer {
constructor(global, el) { // global 就是存储一些全局变量,目前只存储全局的偏移量,因为计算位置的时候需要减去它
this.bounds = new Bounds(global, el); // 获取位置和大小
this.styles = window.getComputedStyle(el); // 这里为了方便直接把所有的样式拿过来,其实可以按需过滤一下
this.elements = []; // 子元素
this.textNodes = []; // 文本节点比较特殊,单独处理
this.flags = 0; // falgs 标志是否要创建层叠上下文
this.el = el; // 元素的引用
}
}
// 计算元素的位置和大小信息
class Bounds {
constructor(global, el) {
const { x = 0, y = 0 } = global.offset;
const { top, left, width, height } = el.getBoundingClientRect();
this.top = top - y;
this.left = left - x;
this.width = width;
this.height = height;
}
}
parseTree(global, el) {
const container = this.createContainer(global, el);
this.parseNodeTree(global, el, container);
return container;
}
parseNodeTree(global, el, parent) {
[...el.childNodes].map((child) => {
if (child.nodeType === 3) {
// 如果是文本节点
if (child.textContent.trim().length > 0) {
// 文本节点不为空
const textElContainer = new TextElContainer(child.textContent, parent);
parent.textNodes.push(textElContainer);
}
} else {
// 如果是普通节点
const container = this.createContainer(global, child);
const { position, zIndex, opacity, transform } = container.styles;
if ((position !== 'static' && !isNaN(zIndex)) || opacity < 1 || transform !== 'none') { // 需不需要创建层叠上下文的标志,不理解可以先跳过,下面会讲解
container.flags = 1;
}
parent.elements.push(container);
this.parseNodeTree(global, child, container);
}
});
}
复制代码
上述代码中要注意的就是:
- 我们计算
bounds时需要考虑最外层容器#app的偏移量,否则当你页面一滚动,bounds.top值就会变成负数,就会画到画布上方,于是就会出现空白。 - 文本节点比较特殊,因为文本不是容器,它的样式和位置受父节点影响,所以我们用一个单独的变量
textNodes来保存。 其实遍历的结果和生成虚拟 dom 是一个挺像的过程。
第二步:按层叠规则分组(重点)
我们知道正常情况下页面是流式布局的,元素从上往下、从左往右进行顺序排列,彼此之间互不重叠。不过有时候这种规则会被打破,比如使用了浮动和定位。所以在一个层叠上下文中元素会根据下面的层叠顺序表来展示(大家应该看过类似的图):  上图中,background/border 为装饰属性,float 和 block 一般用作布局,inline 则用来展示内容。因为页面中内容最重要,所以 inline 的层叠等级会较高。这个层叠顺序也是我们后面用 canvas 绘制的顺序。前端是障眼法的技术,所以先画哪个再画哪个是很有讲究的。现在我们来简单补充下层叠上下文的概念,大家最有印象的应该就是
上图中,background/border 为装饰属性,float 和 block 一般用作布局,inline 则用来展示内容。因为页面中内容最重要,所以 inline 的层叠等级会较高。这个层叠顺序也是我们后面用 canvas 绘制的顺序。前端是障眼法的技术,所以先画哪个再画哪个是很有讲究的。现在我们来简单补充下层叠上下文的概念,大家最有印象的应该就是 z-index 了,其实形成层叠上下文的方法大致有三种:
- 页面的根元素 html 本身就是层叠上下文,称为根层叠上下文
- position 为非 static 并且 z-index 为数值
- css3 中的一些新属性 层叠上下文其实就是 photoshop 中图层的概念,不理解的可以想象成一张透明的纸,页面是由很多张纸叠起来的,每张纸上面又有自己的内容。这里我们以
z-index为例子,通过下面两张图来加深一下印象,假设页面的 html 结构长下面这个样子: 那么我们可以划分出几个层叠上下文,并且他们是可以嵌套的,就像下面这样:
那么我们可以划分出几个层叠上下文,并且他们是可以嵌套的,就像下面这样: 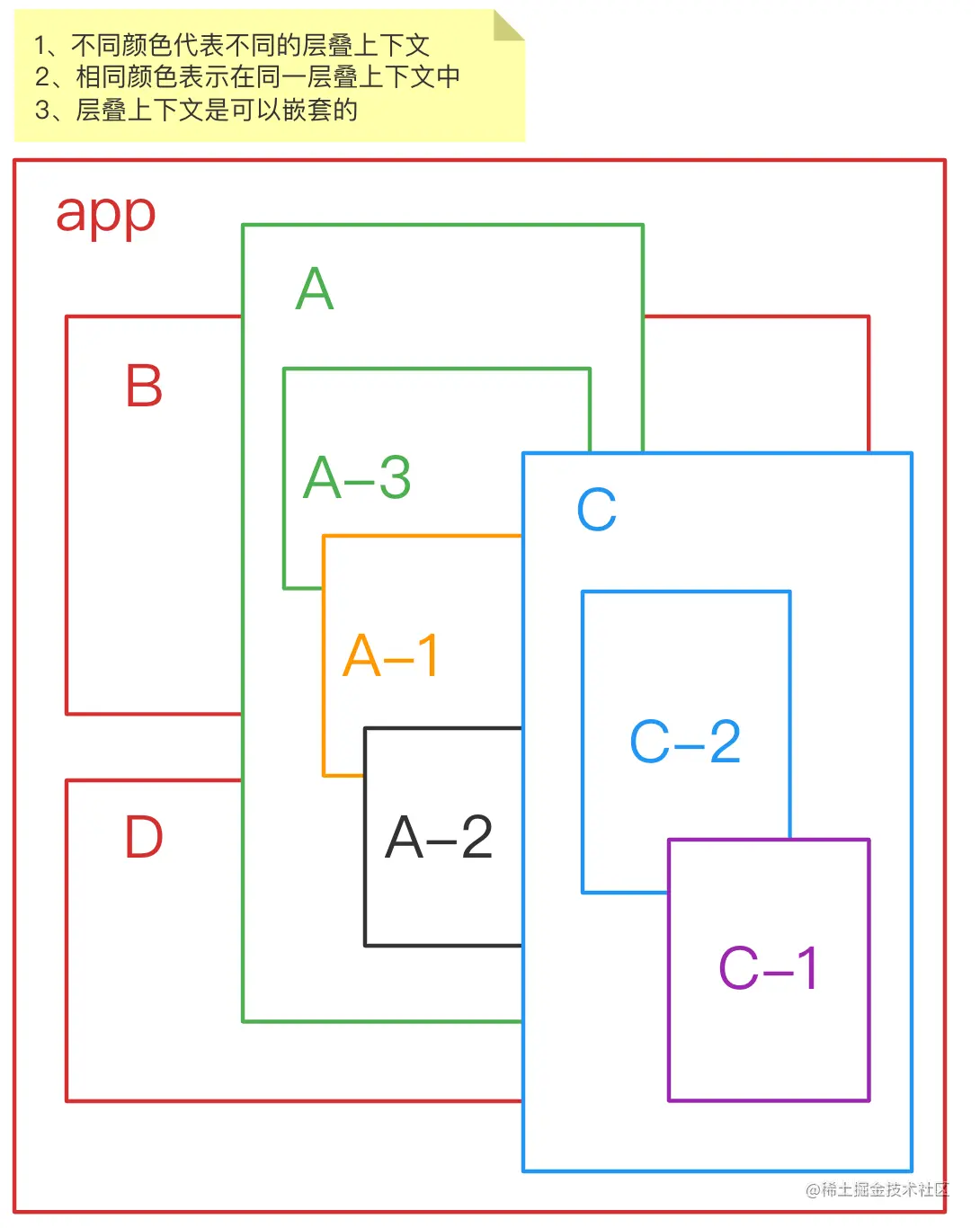 从上图中可以看出 A-2 的
从上图中可以看出 A-2 的 z-index为 99,但是它却被 C 盖住了,这是因为他们两个元素不在同一层叠上下文(同一张纸)中,所以不能相互比较,这也是我们经常在开发中遇到的一个问题,把某个元素的z-index设置成 9999 了,却没有效果,就是这个原因。事实上一个好的页面应该是很少用z-index的,除了全局遮罩会用上。
额。。。讲了这么多废话,还没说下这步要做什么,因为。。。这个东西不好描述,所以我们也是先看看这步处理之后的样子吧: 接下来要做的其实就是根据层叠规则再次遍历上一步中返回的对象,生成上图的样子。思路很简单,就是如果遇到满足新建层叠上下文的条件(如
接下来要做的其实就是根据层叠规则再次遍历上一步中返回的对象,生成上图的样子。思路很简单,就是如果遇到满足新建层叠上下文的条件(如z-index)就新建一个层叠上下文,否则就在当前层叠上下文中将子元素按层叠规则分组,这里需要自己花点时间品一品,建议配合下面代码食用:
class StackingContext { // 这就是层叠上下文
constructor(container) {
this.container = container;
this.negativeZIndex = []; // zIndex为负的元素
this.nonInlineLevel = []; // 块级元素
this.nonPositionedFloats = []; // 浮动元素
this.inlineLevel = []; // 内联元素
this.positiveZIndex = []; // z-index大于等于1的元素
this.zeroOrAutoZIndexOrTransformedOrOpacity = []; // 具有 transform、opacity、zIndex 为 auto 或 0 的元素
}
}
// 开始按层叠规则划分
parseStackingContext(container) {
const root = new StackingContext(container);
this.parseStackTree(container, root);
return root;
}
parseStackTree(parent, stackingContext) { // 这里简化了一些东西,stackingContext 是当前层叠上下文
parent.elements.map((child) => { // 开始分组
if (child.flags) { // 创建新的层叠上下文的标识,上文中有提到(比如在遇到 z-index 的时候会置为 1)
const stack = new StackingContext(child);
const zIndex = child.styles.zIndex;
if (zIndex > 0) { // zIndex 可能是 1、10、100,所以其实不是直接 push,而是要比较之后插入
stackingContext.positiveZIndex.push(stack);
} else if (zIndex < 0) {
stackingContext.negativeZIndex.push(stack);
} else {
stackingContext.zeroOrAutoZIndexOrTransformedOrOpacity.push(stack);
}
this.parseStackTree(child, stack);
} else {
if (child.styles.display.indexOf('inline') >= 0) {
stackingContext.inlineLevel.push(child);
} else {
stackingContext.nonInlineLevel.push(child);
}
this.parseStackTree(child, stackingContext);
}
});
}
复制代码
第三步:创建画布
这个就比较简单了,但是要考虑到 dpr(设备像素比)的影响,这样画布才不会模糊,具体原因可以阅读我的另一篇文章: 关于 canvas 模糊的问题(高清图解),专门讲为什么要这么写,事实上一般也是这么创建画布(把 canvas 放大 dpr 倍):
createCanvas(el) {
const { width, height } = el.getBoundingClientRect();
const dpr = window.devicePixelRatio || 1;
const canvas = document.createElement('canvas');
const ctx2d = canvas.getContext('2d');
canvas.width = Math.round(width * dpr);
canvas.height = Math.round(height * dpr);
canvas.style.width = width + 'px';
canvas.style.height = height + 'px';
ctx2d.scale(dpr, dpr);
this.canvas = canvas;
this.ctx2d = ctx2d;
return canvas;
}
复制代码
第四步:渲染
现在我们已经有了各种数据,接下来只要再遍历一次第二步所返回的层级结果,按顺序依次绘制就可以了。这步难的就是针对不同情况如何转成与之对应的 canvas 语言,需要考虑很多东西的,当然我们这里都是些简单的元素,哈哈哈嗝。
// 根据划分的层级数组,一层一层从下往上绘制,并且转换成相对应的 canvas 绘图语句
render(stack) {
const { negativeZIndex = [], nonInlineLevel = [], inlineLevel = [], positiveZIndex = [], zeroOrAutoZIndexOrTransformedOrOpacity = [] } = stack;
this.ctx2d.save();
// 1、先设置会影响全局的属性,比如 transform 和 opacity
this.setTransformAndOpacity(stack.container);
// 2、绘制背景和边框
this.renderNodeBackgroundAndBorders(stack.container);
// 3、绘制 zIndex < 0 的元素
negativeZIndex.map((el) => this.render(el));
// 4、绘制自身内容
this.renderNodeContent(stack.container);
// 5、绘制块状元素
nonInlineLevel.map((el) => this.renderNode(el));
// 6、绘制行内元素
inlineLevel.map((el) => this.renderNode(el));
// 7、绘制 z-index: auto || 0、transform: none、opacity小于1 的元素
zeroOrAutoZIndexOrTransformedOrOpacity.map((el) => this.render(el));
// 8、绘制 zIndex > 0 的元素
positiveZIndex.map((el) => this.render(el));
this.ctx2d.restore();
}
// 针对不同元素有不同的渲染方式,也就是开篇提到的方式
renderNodeContent(container) {
if (container.textNodes.length) {
container.textNodes.map((text) => this.renderText(text, container.styles));
} else if (container instanceof ImageElContainer) {
this.renderImg(container);
} else if (container instanceof InputElContainer) {
this.renderInput(container);
}
}
renderNode(container) {
this.renderNodeBackgroundAndBorders(container);
this.renderNodeContent(container);
}
renderText(text, styles) { // 这里只考虑影响字体的几个因素,并不全面
const { ctx2d } = this;
ctx2d.save();
ctx2d.font = `${styles.fontWeight} ${styles.fontSize} ${styles.fontFamily}`;
ctx2d.fillStyle = styles.color;
ctx2d.fillText(text.text, text.bounds.left, text.bounds.top);
ctx2d.restore();
}
renderImg(container) { // 这里直接用页面中的 img 元素进行绘制,所以得等到图片加载完成,不然就看不见图片。正常写法应该是在 img.onload 的回调中进行绘制
const { ctx2d } = this;
const { el, bounds, styles } = container;
ctx2d.drawImage(el, 0, 0, parseInt(styles.width), parseInt(styles.height), bounds.left, bounds.top, bounds.width, bounds.height);
}
复制代码
同样说几个注意点:
- 类似 transform 和 opacity 这样的样式会影响自身及其子元素,所以我们需要在渲染一开始的时候就设置画布的全局属性(比如
setTransformAndOpacity中透明度的设置ctx2d.globalAlpha = opacity;) - 对于有 transform 属性的元素,画出来的图形应该是错误的。因为我们一开始获取的位置信息 bounds 就是错误的,我们获取的是元素经过 transform 变换后的位置信息,事实上我们需要的是变换前的位置,所以在一开始遍历的时候需要简单处理下数据,就像下面这样:
class ElContainer {
constructor(global, el) {
// 获取位置和大小,如果元素用了 transform,我们需要将其先还原,再获取样式,因为我们没有克隆整个 html,所以这里就这样处理
const transform = this.styles.transform;
if (transform !== 'none') el.style.transform = 'none';
this.bounds = new Bounds(global, el);
if (transform !== 'none') el.style.transform = transform;
// ...
}
}
复制代码
- 关于背景和边框的绘制,其实就是算出四个点(点是有顺序的,要么顺时针要么逆时针)画四条线然后进行填充或描边;如果有圆角的话,我们就要画四条线和四段圆弧;另外边框的宽度也可能会影响其内部元素的位置,否则会产生一些偏差,不过我们没有处理,哈哈。
- 关于文本的绘制,细心的同学会发现在一开始的效果图中 canvas 上的文字和 html 的有些出入,比如位置会偏移一点,这是因为文字渲染也是件麻烦事,什么字体、怎么对齐、基线在哪、字间距、行高等各种属性五花八门,所以我们也只是简单处理,也不支持换行。
- 关于图片因为加载需要时间,所以渲染应该是异步的,不然可能就绘制不上(还可能受到跨域、图片过大等影响),这里只是简单的把加载好的 img 拿过来绘制。
那如果我们需要一些其他功能怎么办?经过前面的学习你应该有所了解,比如:
- 有些元素不需要绘制怎么办?加个属性或者加个类(
data-html2canvas-ignore),遍历的时候过滤掉就好了。 - 文本有省略号怎么办?这里我们得利用
ctx2d.measureText这个 api 算出文本宽度再自己拼接上...,另外这个 api 只能算宽度,不能算高度,高度需要自己(根据字号、行高等)繁琐的计算下。 - 遇到 canvas 元素咋处理?直接把这个 canvas 绘制过来即可,其他元素呢,有 api 就直接用(比如 svg),没 api 就手写(比如复选框);属性也是一样的,没有对应的 canvas 实现方式就慢慢手写实现。由此可见从 html 到 canvas 基本上都是要一个个转换到对应写法的,想想就头大,所以会有各种各样的问题是很正常的,即便是像本文这么简单的实现版本。此外还很容易产生一些不可描述的bug,然后你一查又会知道几个生僻的属性,最后就剩无奈了♀️(我摊牌了,我不会,搞不动,也不想搞)。 知识看了容易忘,这里我们简单看张流程图回顾一下:
 ps:其实我觉得最难的是获取位置和样式,不过好在浏览器已经帮我们解决了。
ps:其实我觉得最难的是获取位置和样式,不过好在浏览器已经帮我们解决了。
另一种方法(html->svg->canvas)
没兴趣的同学可以跳过这一趴。这种方法相对比较简单,就是把 html 装进 svg 里面,再将 svg 搞到 canvas,因为浏览器有提供相应的 api,所以可以这样搞,当然也有它的局限性,这里只是简单带过下:
- 遍历 dom,把所有外联样式写到内联样式中(因为 svg 需要这样,否则样式无效的)
- 把 html 序列化后拼接到 svg 中,然后导出成图片,就像下面这样:
const svg = `<svg xmlns="http://www.w3.org/2000/svg" width="${width}" height="${height}">
<foreignObject height="100%" width="100%">${htmlString}</foreignObject>
</svg>`;
const img = new Image();
img.src = `data:image/svg+xml,${svg}`;
复制代码
- 最后把 img 画到画布上即可。
ctx2d.drawImage(img, 0, 0); 复制代码
看着简单,实际应用也是问题百出。
结语
好了,上面就是 html2canvas 的两种思路,当然在实际开发中,我们肯定是直接使用 html2canvas。不过这回如果在使用中出了问题,你心里就有底了,你就能估摸个大概为什么有的地方会转不成功,这种情况大概率就是不兼容、不支持、没有对应的转换,所以最好的方案就是把 html 和 css 换种写法,少用一些花里胡哨的样式尤为重要。最后,如果你看过 html2canvas 的 README.md,你会发现这样一句话: ![]() 这里是项目地址传送门。顺便附上我 canvas 专栏的另外两篇实战文章:
这里是项目地址传送门。顺便附上我 canvas 专栏的另外两篇实战文章:
- 用 canvas 搞一个手势识别?醍醐灌顶
- 用 canvas 来画个函数曲线吧!纵享丝滑
以上就是JS前端html2canvas手写示例问题剖析的详细内容,更多关于JS前端html2canvas的资料请关注脚本之家其它相关文章!