定义内容的结构。
使用代码定义内容模型是设计使然。它使版本控制变得更容易,并使开发人员能够控制数据结构的布局方式。我们让在界面中添加、更改和删除字段变得毫不费力。
观看Schema 工作原理的视频,或滚动阅读它的工作原理。
你的第一个 Schema
当 Sanity 启动时,默认在项目 schemas 文件夹中查找 schema.js。让我们来构建一个简单的 Schema 开始:
// 首先,必须引入 schema-creator
import createSchema from "part:@sanity/base/schema-creator";
// 然后引入插件可能暴露的 Schema 类型expose them
import schemaTypes from "all:part:@sanity/base/schema-type";
// 接着创建 Schema
export default createSchema({
// 名称
name: "mySchema",
// 连接文档类型,目前只需要一个
types: schemaTypes.concat([
{
// 类型显示名称
title: "Person",
//API 标识符
name: "person",
// 文档类型为 `document `
type: "document",
// 字段声明
fields: [
// 该文档类型仅有一个字段
{
// 显示名称
title: "Name",
// API 标识符
name: "name",
// 字段类型
type: "string",
},
],
},
]),
});这个 Schema 配置创建了一个 person 的文档类型,它包含一个 name 字段。

稍后通过 API 获取这样的文档时,我们会得到这样的文档:
{
"_id": "45681087-46e7-42e7-80a4-65b776e19f91",
"_type": "person",
"name": "Ken Kesey"
}一个文档引用另一个文档
现在来设计一个描述一本书的简单文档。类型数组中,我们添加这样一个对象:
{
title: 'Book',
name: 'book',
type: 'document',
fields: [
{
title: 'Title',
name: 'title',
type: 'string'
},
{
title: 'Cover',
name: 'cover',
type: 'image'
},
{
title: 'Author',
name: 'author',
// `reference` 类型来指向另一个文档
type: 'reference',
// 这个引用只允许指向 `person` 类型的文档
// 虽然可以列举更多类型,但尽量保持精简:
to: [{type: 'person'}]
}
]
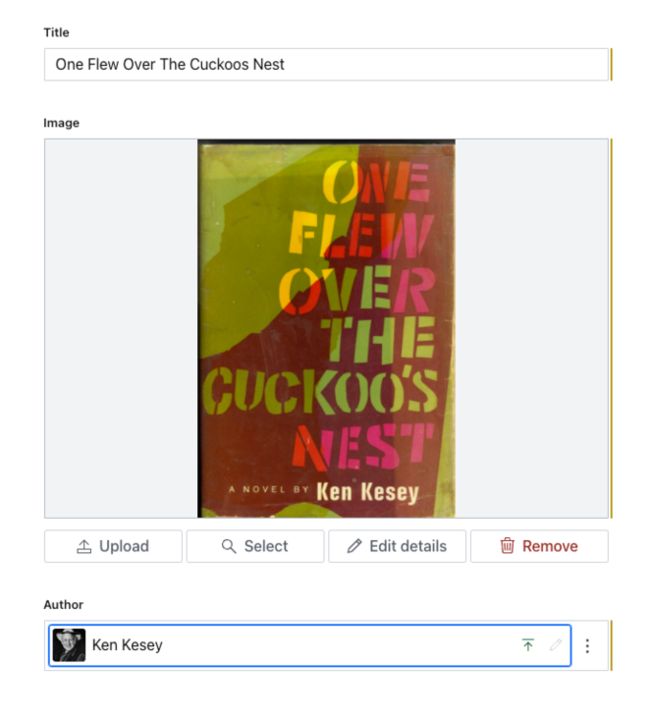
}这个 Schema 创建了一个叫做 book 的文档类型,它包含三个字段:
- 标题
- 封面图片
- 作者(该字段引用了另一个文档,在
to字段里描述引用的文档类型。列出了一条规则为,类型可以是person)
表单看起来是这个样子:
当通过 API 获取这个文档时,我们会得到:
{
_id: "d1760c53-428c-4324-9297-ac8313276c45",
_type: "book",
title: "One Flew Over the Cuckoos Nest",
cover: {
_type: "image",
asset: {
_ref: "image-Su3NWQ712Yg0ACas3JN9VpcS-322x450-jpg",
_type: "reference"
}
},
author: {
_ref: "45681087-46e7-42e7-80a4-65b776e19f91",
_type: "reference"
}
}如您所见,作者字段没有提及 Ken Kesey,但字段 _ref 中包含了 Ken Kesey 文档的 id。当获取引用的文档时,可以轻松的通过指示 API 去体会为目标文档的实际内容。您可以在 Query 教程 中阅读更多相关信息。
数组的一种使用
让我们谈谈数组:有些书有不止一位作者。我们应该通过将作者字段设置为引用数组来改进 Book 文档类型:
{
title: 'Authors',
name: 'authors',
type: 'array',
of: [{
type: 'reference',
to: [{type: 'person'}]
}]
}从 API 返回的文档将如下所示:
{
_id: "drafts.e7f370d0-f86f-4a09-96ea-12f1d9b236c4",
_type: "book",
title: "The Illuminatus! Trilogy",
cover: {
_type: "image",
asset: {
_ref: "image-Ov3HwbkOYkNrM2yabmBr2M8T-318x473-jpg",
_type: "reference"
}
},
authors: [
{
_ref: "9a8eb52c-bf37-4d6e-9321-8c4674673198",
_type: "reference"
},
{
_ref: "ee58f2ff-33ed-4273-8031-b74b5664ff5e",
_type: "reference"
}
]
}组织架构
最后的注意点是组织你的文件(们)。在这个示例中,我们将两种类型文档的定义都堆积到了同一个 JS 文件中。不推荐这么做;这会很快让代码失控。推荐的做法是在每个单独的文件中描述每种文档类型:
// 文件: schemas/schema.js
import createSchema from 'part:@sanity/base/schema-creator'
import schemaTypes from 'all:part:@sanity/base/schema-type'
import person from './person'
export default createSchema({
name: 'mySchema',
types: schemaTypes.concat([
person
])
})
// 文件: schemas/person.js
export default {
title: "Person",
name: "person",
type: "document",
fields: [
{
title: "Name",
name: "name",
type: "string",
}
]
}这涵盖了非常基础的内容,但还有更多内容!现在,让我们深入探讨使用 Sanity 对内容进行建模时的最佳实践。