Kubernetes 调度使用介绍(亲和、反亲和、污点、容忍)
Kubernetes 调度使用介绍
- 一、基本介绍
-
- 1.Scheduler 调度过程
- 2.K8s 调度策略
- 二、使用介绍
-
- 1.亲和
- 2.反亲和
- 3.污点
- 4.容忍
一、基本介绍
在 Kubernetes 中 Pod 的调度都是由 Scheduler 组件来完成的,整个调度过程都是自动完成的,也就是说我们并不能确定 Pod 最终被调度到了哪个节点上。而在实际环境中,可能需要将 Pod 调度到指定的节点上。官方文档
这时,我们便可以通过 K8s 提供的节点选择器、亲和、反亲和等配置来实现 Pod 到节点的定向调度。
1.Scheduler 调度过程
- 预选(Predicates):遍历集群中的所有节点,并通过预选策略筛选出符合条件的节点列表。
- 优选(Priorities):在预选结果的基础上,通过优选策略对每个节点进行打分和排序,最后将 Pod 优先分配到分数较高的节点上。
2.K8s 调度策略
| 调度策略 | 作用 |
|---|---|
nodeSelector |
节点选择器,通过匹配节点标签的方式,调度到存在该标签的节点上。 |
nodeAffinity |
节点亲和,通过匹配节点标签的方式,调度到存在该标签的节点上。 |
podAffinity |
Pod 亲和,通过匹配 Pod 标签的方式,使 Pod 和 Pod 调度在同一台节点上。 |
podAntiAffinity |
Pod 反亲和,通过匹配 Pod 标签的方式,使 Pod 和 Pod 调度在不同的节点上。 |
Taint & Toleration |
污点和容忍,污点可以将节点和 Pod 达到互斥的效果,而容忍则可以让 Pod 调度到带有污点的节点上。 |
二、使用介绍
1.亲和
1)nodeAffinity:
[root@k8s-master01 ~]# cat <<END > test-nodeAffinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
containers:
- name: busybox
image: busybox:1.28.4
imagePullPolicy: IfNotPresent
command: ['/bin/sh','-c','sleep 3600']
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master01
- k8s-master02
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1 # 权重 (1-100),优先匹配权重较高的
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master02
END
[root@k8s-master01 ~]# kubectl create -f test-nodeAffinity.yaml
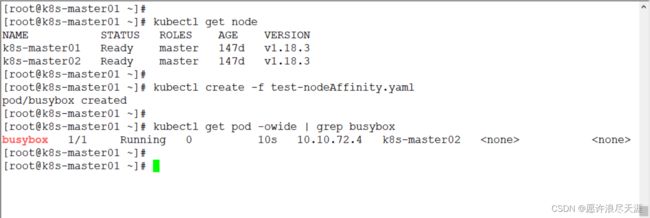
注意:
- 当同时指定
nodeSelector和nodeAffinity时,需要将两者条件都满足,才能正常的对 Pod 进行调度。 - 当在同一个
nodeSelectorTerms下配置多个matchExpressions时,需要满足所有条件后,才能正常的对 Pod 进行调度。
requiredDuringScheduling...:硬策略(强制性的,当集群内的节点没有满足硬策略的要求时,Pod 将不会被调度)
preferredDuringScheduling...:软策略(满足条件最好,不满足也不会影响正常调度)(匹配顺序为:先硬后软)
operator 匹配条件:
In:标签值存在某个列表中;NotIn:标签值不存在某个列表中;Gt:标签值大于某个值;Lt:标签值小于某个值;Exists:某个标签存在;DoesNotExist:某个标签不存在;
2)podAffinity:
[root@k8s-master01 ~]# cat <<END > test-podAffinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:1.21.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: mariadb
labels:
app: db
spec:
containers:
- name: mariadb
image: mariadb:10.7.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
env:
- name: MARIADB_ROOT_PASSWORD
value: '123123'
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web
topologyKey: kubernetes.io/hostname
END
[root@k8s-master01 ~]# kubectl create -f test-podAffinity.yaml

topologyKey:指定节点标签,通过该标签可以确定哪些节点上的 Pod 有指定标签,以此来做区分。
2.反亲和
[root@k8s-master01 ~]# cat <<END > test-podAntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
END
[root@k8s-master01 ~]# kubectl create -f test-podAntiAffinity.yaml
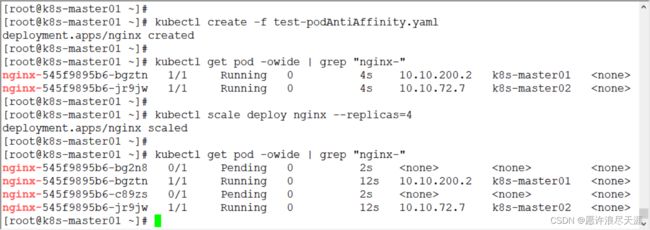
- 后面增加的 Pod 处于 Pending 的原因是因为我的集群内就两个节点,所以导致 Pod 由于反亲和而调度不到其它节点。
3.污点
格式:
kubectl taint node [node] key=value[effect]
effect 可选配置:
NoSchedule:表示 Pod 将不会被调度到具有该污点的节点上。PreferNoSchedule:表示 Pod 将尽量避免调度到具有该污点的节点上(类似于软策略)NoExecute:表示 Pod 将不会被调度到具有该污点的节点上,同时将节点上预警存在的 Pod 进行驱逐。
1)配置污点
[root@k8s-master01 ~]# kubectl taint nodes k8s-master01 node-role.kubernetes.io/master=k8s-master01:NoSchedule
2)验证
[root@k8s-master01 ~]# cat <<END > test-taints.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: test-taints
spec:
selector:
matchLabels:
test: taints
template:
metadata:
labels:
test: taints
spec:
containers:
- name: test-taints
image: busybox:1.28.4
imagePullPolicy: IfNotPresent
command: ['/bin/sh','-c','sleep 3600']
END
[root@k8s-master01 ~]# kubectl describe node k8s-master01 | grep Taints
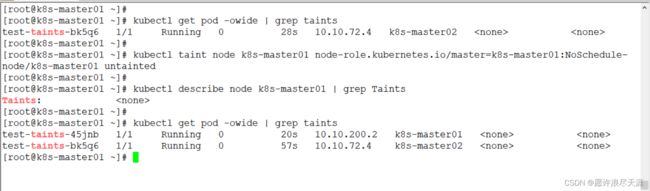
[root@k8s-master01 ~]# kubectl create -f test-taints.yaml
[root@k8s-master01 ~]# kubectl get pod -owide | grep taints

- 可以看到,即便是 DaemonSet 类型的控制器也不能在带有污点(不包括
PreferNoSchedule)的节点上运行 Pod。
3)取消污点
[root@k8s-master01 ~]# kubectl taint node k8s-master01 node-role.kubernetes.io/master=k8s-master01:NoScheduler-
4.容忍
当给节点配置上污点后,便可以使节点和 Pod 间处于一种互斥的状态,使 Pod 不能够调度到带有污点的节点上。不过,如果想要将 Pod 调度到带有污点的节点时,便可以通过在 Pod 上配置容忍(可以包容带有污点的节点)
[root@k8s-master01 ~]# cat <<END > test-toleration.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: test-toleration
spec:
selector:
matchLabels:
test: toleration
template:
metadata:
labels:
test: toleration
spec:
containers:
- name: test-toleration
image: busybox:1.28.4
imagePullPolicy: IfNotPresent
command: ['/bin/sh','-c','sleep 3600']
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: "k8s-master01"
effect: "NoSchedule"
END
[root@k8s-master01 ~]# kubectl create -f test-toleration.yaml
[root@k8s-master01 ~]# kubectl get pod -owide | grep toleration

容忍多种配置:
1)可以被调度到带有 key/value:NoExecute 污点的节点上。
tolerations:
- key: ""
operator: "Equal"
value: ""
effect: "NoExecute"
tolerationSeconds: 3600
tolerationSeconds:表示当 Pod 被驱逐时,还可以在节点上继续运行的时间(仅可以和NoExecute配合使用)
2)可以被调度到带有指定 key 污点的节点上。
tolerations:
- key: ""
operator: "Exists"
3)可以被调度到带有任何污点的节点上。
tolerations:
- operator: "Exists"