【机器学习】数据科学基础——神经网络基础实验
【机器学习】数据科学基础——神经网络基础实验

活动地址:[CSDN21天学习挑战赛](https://marketing.csdn.net/p/bdabfb52c5d56532133df2adc1a728fd)
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:机器学习
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【机器学习】数据科学基础——神经网络基础实验
- 前言
-
-
- 什么是神经网络?
-
- 一、基于全连接神经网络实型房价预测
-
- (一)、数据加载及预处理
- (二)、模型配置
- (三)、模型训练
- (四)、模型评估
- 小结
- 二、基于全连接神经网络实现宝石分类
-
- (一)、数据加载及预处理
- (二)、模型配置
- (三)、模型训练
- (四)、模型评估
- (五)、模型预测
- 三、基于高层API实现宝石分类
-
- (一)、准备数据
- (二)、配置网络
- (三)、训练网络
- (四)、模型评估
- (五)、模型预测:
- 总结
前言
什么是神经网络?
神经网络是一门重要的机器学习技术,它是目前人工智能领域内最为火热的研究方向——深度学习技术的基础。神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型,也是我们后续学习自然语言处理和视觉图像处理的基础
一、基于全连接神经网络实型房价预测
(一)、数据加载及预处理
- 导入相关包:
# import paddle.fluid as fluid
import paddle
import numpy as np
import os
import matplotlib.pyplot as plt
- 设置paddle默认的全局数据类型为float64
#设置默认的全局dtype为float64
paddle.set_default_dtype("float64")
#下载数据
print('下载并加载训练数据')
train_dataset = paddle.text.datasets.UCIHousing(mode='train')
eval_dataset = paddle.text.datasets.UCIHousing(mode='test')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=32, shuffle=True)
eval_loader = paddle.io.DataLoader(eval_dataset, batch_size = 8, shuffle=False)
(二)、模型配置
线性回归本质上是一层不带激活函数的全连接层,因此本实验使用
paddle.nn.Linear(in_features,out_features,weight_attr=None,nias_attr=None,name=None)
来实现线性变换,其中,in_features为输入特征的维度,out_features为输出特征的维度,weight_attr指定权重参数的属性,表示使用默认的权值参数属性,将权重参数初始化为0,bias_attr指定偏置参数的属性,设置为False时,表示不会为该层添加偏置,name用于网络层输出的前缀标识,在自定义网络模型时,应当继承paddle.nn.Layer类,该类属于基于OOD实现的动态图,实现了训练模式与验证模式,训练模型会执行反向传播,而验证模式不包含反向传播,同时也为dropout等训练,验证时不同的操作提供了支持。在神经网络中,从输入到输出的过程称为网络的前向计算,在飞浆中,可用forward关键字标识,forward()函数定义函数从前到后的完整计算过程,是实现网络框架最重要的环节。
定义全连接网络:
# 定义全连接网络
class Regressor(paddle.nn.Layer):
def __init__(self):
super(Regressor, self).__init__()
# 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数
self.linear = paddle.nn.Linear(13, 1, None)
# 网络的前向计算函数
def forward(self, inputs):
x = self.linear(inputs)
return x
(三)、模型训练
本实验中使用
paddle.optimizer.SGD(learning_rate=0.001,parameters=None,weight_decay=None,grad_clip=None,name=None)
进行优化,其中learning_rate为学习率,也就是参数梯度的更新步长,parameters指定优化器需要优化的参数,weight_decay为权重衰减系数,grad_clip为梯度裁减的策略,支持三种裁剪策略:paddle.nn.ClipGradByGlobalNorm、paddle.nn.ClipGradByNorm、paddle.nn.ClipGradByValue,梯度裁剪将梯度值阶段约束在一个范围内,防止使用深度网络时出现梯度爆炸的情况,默认值为None,此时将不进行梯度裁剪。定义好模型、损失函数和优化器之后,将数据分批送入模型中,并执行梯度反向传播更新参数(loss.backward()),达到训练目的,模型训练结束后,调用paddle.save()保存模型,后续进行预测时,只需要将训练好的模型参数加载到模型中,便可利用训练数据提取到的规律对测试数据进行预测。
代码如下:
Batch=0
Batchs=[]
all_train_accs=[]
def draw_train_acc(Batchs, train_accs):
title="training accs"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("acc", fontsize=14)
plt.plot(Batchs, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss=[]
def draw_train_loss(Batchs, train_loss):
title="training loss"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Batchs, train_loss, color='red', label='training loss')
plt.legend()
plt.grid()
plt.show()
model=Regressor() # 模型实例化
model.train() # 训练模式
mse_loss = paddle.nn.MSELoss()
opt=paddle.optimizer.SGD(learning_rate=0.0005, parameters=model.parameters())
epochs_num=200 #迭代次数
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_loader()):
image = data[0]
label = data[1]
predict=model(image) #数据传入model
# print(predict)
# print(np.argmax(predict,axis=1))
loss=mse_loss(predict,label)
# acc=paddle.metric.accuracy(predict,label.reshape([-1,1]))#计算精度
# acc = np.mean(label==np.argmax(predict,axis=1))
if batch_id!=0 and batch_id%10==0:
Batch = Batch+10
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
# all_train_accs.append(acc.numpy()[0])
print("epoch:{},step:{},train_loss:{}".format(pass_num,batch_id,loss.numpy()[0]) )
loss.backward()
opt.step()
opt.clear_grad() #opt.clear_grad()来重置梯度
paddle.save(model.state_dict(),'Regressor')#保存模型
draw_train_loss(Batchs,all_train_loss)
模型训练过程中部分输出如下图1-1所示:

(四)、模型评估
- 模型训练结束后,根据保存的损失值的中间结果,绘制损失值随模型迭代次数的变化过程:
def draw_train_acc(Batchs,train_accs):
title="training accs"
plt.title(title,fontsize=24)
plt.xlabel("batch",fontsize=14)
plt.ylabel("acc",fontsize=14)
plt.plot(Batchs,train_accs,color='green',label='training accs')
plt.legend()
plt.grid()
plt.show()
draw_train_loss(Batchs,all_train_loss)
模型损失值随迭代次数变化趋势如下图1-2所示:
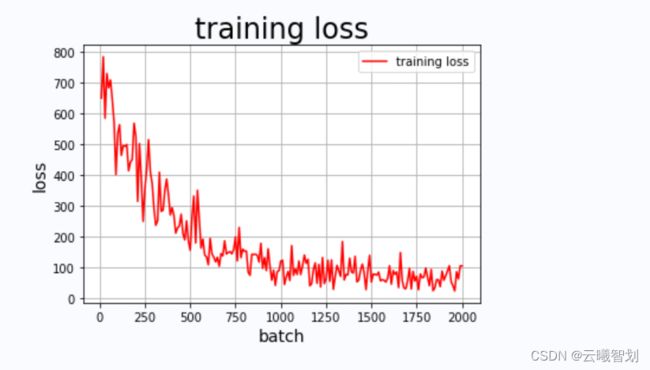
- 为了判断上述模型的性能,可在验证集上进行验证。首先将前面步骤保存的训练好的参数加载到新实例化的模型中,然后启动验证模型,将验证数据批量输入到网络中进行损失值计算,并输出模型在验证集上的损失值:
#模型评估
para_state_dict = paddle.load("Regressor")
model = Regressor()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #验证模式
losses = []
infer_results=[]
groud_truths=[]
for batch_id,data in enumerate(eval_loader()):#测试集
image=data[0]
label=data[1]
groud_truths.extend(label.numpy())
predict=model(image)
infer_results.extend(predict.numpy())
loss=mse_loss(predict,label)
losses.append(loss.numpy()[0])
avg_loss = np.mean(losses)
print("当前模型在验证集上的损失值为:",avg_loss)
输出结果如下图1-3所示:

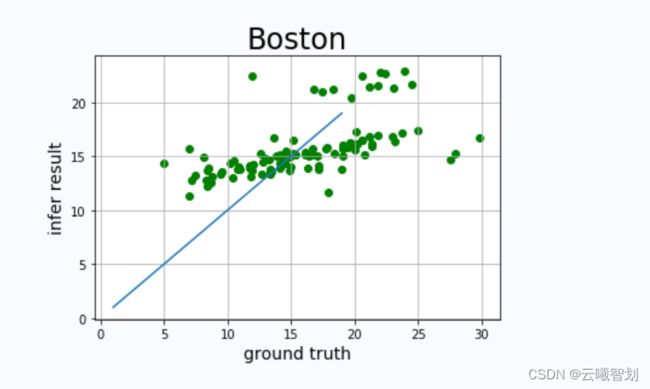
- 绘制模型预测结果与真实值之间的差异,当模型的预测值等于真实值时,模型的预测效果是最优的,但是这种情况几乎不可能出现,因此作为对照,可以观察预测值与真实值构成的坐标点位于y=x直线的位置,判断模型性能的好坏,代码实现及图示如下:
#绘制真实值和预测值对比图
def draw_infer_result(groud_truths,infer_results):
title='Boston'
plt.title(title, fontsize=24)
x = np.arange(1,20)
y = x
plt.plot(x, y)
plt.xlabel('ground truth', fontsize=14)
plt.ylabel('infer result', fontsize=14)
plt.scatter(groud_truths, infer_results,color='green',label='training cost')
plt.grid()
plt.show()
draw_infer_result(groud_truths,infer_results)
真实值和预测值对比图如下图1-4所示:
小结
上述方法获得模型的拟合能力并没有达到最优,仍然具有很大的优化空间。线性回归算法只能处理线性可分的数据,对于线性不可分数据,在传统机器学习算法中,需要使用对数线性回归、广义线性回归或者其它回归算法,但是在神经网络中,可以通过添加激活函数、加深网络深度,实现任意函数的拟合。
二、基于全连接神经网络实现宝石分类
(一)、数据加载及预处理
- 加载必要的包:
import os
import zipfile
import random
import json
import cv2
import numpy as np
from PIL import Image
import paddle
import matplotlib.pyplot as plt
from paddle.io import Dataset
- 参数配置:
'''
参数配置
'''
train_parameters = {
"input_size": [3, 224, 224], #输入图片的shape
"class_dim": 25, #分类数
"src_path":"data/data55032/archive_train.zip", #原始数据集路径
"target_path":"/home/aistudio/data/dataset", #要解压的路径
"train_list_path": "./train.txt", #train_data.txt路径
"eval_list_path": "./eval.txt", #eval_data.txt路径
"label_dict":{}, #标签字典
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"num_epochs": 40, #训练轮数
"train_batch_size": 32, #批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.0001 #超参数学习率
}
}
- 定义解压函数,解压数据集:
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data/dataset目录下
'''
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
else:
print("文件已解压")
- 生成数据列表:读取每个文件夹下的图片,将绝对路径统一保存于文件中:
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path
class_dirs = os.listdir(data_list_path)
if '__MACOSX' in class_dirs:
class_dirs.remove('__MACOSX')
# #总的图像数量
all_class_images = 0
# #存放类别标签
class_label=0
# #存放类别数目
class_dim = 0
# #存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = os.path.join(data_list_path,class_dir)
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
if img_path =='.DS_Store':
continue
name_path = os.path.join(path,img_path) # 每张图片的路径
if class_sum % 15 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # eval_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
print(train_parameters)
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
#乱序
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')
- 调用前面的功能函数,生成数据列表,用于后面的训练与验证:
'''
参数初始化
'''
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
-
为训练模型,需要定义一个数据集类将数据进行封装,该类需要继承paddle.io.Dataset抽象类,Dataset抽象了数据集的方法和行为,须实现以下方法:
__ getitem__:根据给定索引获取数据集中指定样本,在paddle.io.DataLoader中需要使用此函数通过下标获取样本;
__ len__:返回数据集样本个数,paddle.io.BatchSampler中需要样本个数生成下标序列。
本实验中自定义Reader(命名可自定义)类继承Dataset,然后再使用paddle.io.DataLoader进行批量数据处理,获取可批量迭代的数据加载器:
class Reader(Dataset):
def __init__(self, data_path, mode='train'):
"""
数据读取器
:param data_path: 数据集所在路径
:param mode: train or eval
"""
super().__init__()
self.data_path = data_path
self.img_paths = []
self.labels = []
if mode == 'train':
with open(os.path.join(self.data_path, "train.txt"), "r", encoding="utf-8") as f:
self.info = f.readlines()
for img_info in self.info:
img_path, label = img_info.strip().split('\t')
self.img_paths.append(img_path)
self.labels.append(int(label))
else:
with open(os.path.join(self.data_path, "eval.txt"), "r", encoding="utf-8") as f:
self.info = f.readlines()
for img_info in self.info:
img_path, label = img_info.strip().split('\t')
self.img_paths.append(img_path)
self.labels.append(int(label))
def __getitem__(self, index):
"""
获取一组数据
:param index: 文件索引号
:return:
"""
# 第一步打开图像文件并获取label值
img_path = self.img_paths[index]
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) / 255
label = self.labels[index]
label = np.array([label], dtype="int64")
return img, label
def print_sample(self, index: int = 0):
print("文件名", self.img_paths[index], "\t标签值", self.labels[index])
def __len__(self):
return len(self.img_paths)
train_dataset = Reader('/home/aistudio/',mode='train')
eval_dataset = Reader('/home/aistudio/',mode='eval')
#训练数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=16, shuffle=True)
#测试数据加载
eval_loader = paddle.io.DataLoader(eval_dataset, batch_size = 8, shuffle=False)
- 打印观察数据集的组成情况,构造的数据集中,训练集包含730条样本,测试集包含81条样本:
train_dataset.print_sample(200)
print(train_dataset.__len__())
eval_dataset.print_sample(0)
print(eval_dataset.__len__())
print(eval_dataset.__getitem__(10)[0].shape)
print(eval_dataset.__getitem__(10)[1].shape)
输出结果如图2-1所示:

(二)、模型配置
数据处理完毕后,需要设计模型实现宝石分类,本实验使用简单的深度全连接网络来实现宝石分类,在定义神经网络模型时,需要继承paddle.nn.Layer,然后实现继承类的初始化函数__init__(self, args)。在该初始化函数中,通常会定义网络中的子模块操作,全连接神经网络包含线性模块与激活模块,本实验使用paddle.nn.Linear与paddle.nn.ReLU实现网络的构建,paddle.nn.ReLU的激活方式为f(x)=max(x,0),也就是若单元值为负数时,其激活值为0,否则激活值仍为本身:
#定义DNN网络
class MyDNN(paddle.nn.Layer):
def __init__(self):
super(MyDNN,self).__init__()
self.linear1 = paddle.nn.Linear(in_features=3*224*224, out_features=1024)
self.relu1 = paddle.nn.ReLU()
self.linear2 = paddle.nn.Linear(in_features=1024, out_features=512)
self.relu2 = paddle.nn.ReLU()
self.linear3 = paddle.nn.Linear(in_features=512, out_features=128)
self.relu3 = paddle.nn.ReLU()
self.linear4 = paddle.nn.Linear(in_features=128, out_features=25)
def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑
# input.shape (16, 3, 224, 224)
x = paddle.reshape(input, shape=[-1,3*224*224]) #-1 表示这个维度的值是从x的元素总数和剩余维度推断出来的,有且只能有一个维度设置为-1
# print(x.shape)
x = self.linear1(x)
x = self.relu1(x)
# print('1', x.shape)
x = self.linear2(x)
x = self.relu2(x)
# print('2',x.shape)
x = self.linear3(x)
x = self.relu3(x)
# print('3',x.shape)
y = self.linear4(x)
# print('4',y.shape)
return y
(三)、模型训练
- 创建好模型之后,下一步就是模型的训练。在训练模型之前,先定义两个函数draw_train_acc(Batchs,train_accs)与draw_train_loss(Batchs,train_loss),用来可视化训练过程中损失函数值与训练集准确率随迭代步数的变化趋势:
Batch=0
Batchs=[]
all_train_accs=[]
def draw_train_acc(Batchs, train_accs):
title="training accs"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("acc", fontsize=14)
plt.plot(Batchs, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss=[]
def draw_train_loss(Batchs, train_loss):
title="training loss"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Batchs, train_loss, color='red', label='training loss')
plt.legend()
plt.grid()
plt.show()
- 模型的训练包括模型实例化、开启训练模式、定义损失函数、定义优化器、循环前向迭代与反向参数更新等过程,本实验使用paddle.metric.accuracy(input,label,k=1,correct=None,total=None,name=None)直接计算分类的准确率,如果正确的标签在top k个预测值里,则计算结果加1,其中,input为预测分类的概率分布,shape为[sample_number,class_dim],label为数据集的标签,shape为[sample_number,1],k代表取每个类别中k个预测值用于计算,默认值为1,correct为正确预测值的个数,默认值为None,total为总共的预测值,默认值为None:
model=MyDNN() #模型实例化
model.train() #训练模式
cross_entropy = paddle.nn.CrossEntropyLoss()
opt=paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
epochs_num=train_parameters['num_epochs'] #迭代次数
for pass_num in range(train_parameters['num_epochs']):
for batch_id,data in enumerate(train_loader()):
image = data[0]
label = data[1]
predict=model(image) #数据传入model
loss=cross_entropy(predict,label)
acc=paddle.metric.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%5==0:
Batch = Batch+5
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,loss.numpy(),acc.numpy()))
loss.backward()
opt.step()
opt.clear_grad() #opt.clear_grad()来重置梯度
paddle.save(model.state_dict(),'MyDNN')#保存模型
draw_train_acc(Batchs,all_train_accs)
draw_train_loss(Batchs,all_train_loss)
模型训练过程中部分输出及变化曲线如下图2-2所示:

绘制迭代次数-准确率/损失函数值曲线如图2-3和2-4所示


(四)、模型评估
模型训练完成后,需要对模型的泛化性能进行评估,在前面步骤划分数据集时预留的测试集上进行模型性能的评估,并输出其准确率,首先加载保存的模型参数,然后将参数值赋值给实例化的模型,调用model.eval()函数开启模型的验证模式,分批将测试数据输入到网络中进行预测:
#模型评估
para_state_dict = paddle.load("MyDNN")
model = MyDNN()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #验证模式
accs = []
for batch_id,data in enumerate(eval_loader()):#测试集
image=data[0]
label=data[1]
predict=model(image)
acc=paddle.metric.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print("当前模型在验证集上的准确率为:",avg_acc)
输出结果如图2-5所示:

(五)、模型预测
对于训练好的模型,可将其应用于实际场景的图像类型进行推理,因此,对于给定条或多条预测样本,需要首先定义基本的图像处理函数,对输入图像进行预处理,然后加载训练好的模型,在验证模式下进行预测:
import os
import zipfile
def unzip_infer_data(src_path,target_path):
'''
解压预测数据集
'''
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
return img
infer_src_path = '/home/aistudio/data/data55032/archive_test.zip'
infer_dst_path = '/home/aistudio/data/archive_test'
unzip_infer_data(infer_src_path,infer_dst_path)
'''
模型预测
'''
para_state_dict = paddle.load("MyDNN")
model = MyDNN()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #训练模式
#展示预测图片
infer_path='data/archive_test/alexandrite_3.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(infer_path))
infer_imgs = np.array(infer_imgs)
label_dic = train_parameters['label_dict']
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor (dy_x_data)
out = model(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print("第{}个样本,被预测为:{},真实标签为:{}".format(i+1,label_dic[str(lab)],infer_path.split('/')[-1].split("_")[0]))
print("结束")
输出结果如图2-6所示:

三、基于高层API实现宝石分类
飞桨高层API面向从深度学习小白到资深开发者的所有人群,对于AI初学者来说,使用高层API可以简单快速地构建深度学习项目,对于资深开发者来说,可以快速完成算法迭代。
- 飞桨高层API具有以下特点:
(1)易学易用:高层API是对普通动态图API的进一步封装和优化,同时保持与普通API的兼容性,高层API使用更加易学易用,同样的实现使用高层API可以节省大量的代码;
(2)低代码开发:使用飞桨高层API的一个明显特点时编程代码量大大缩减;
(3)动静转换:高层API支持动静转换,只需要改一行代码即可实现动态图代码在静态图模式下训练,既方便使用动态图调整模型,又提高了训练效率。
- 在功能增强与使用方式上,高层API有以下升级:
(1)模型训练方式升级:高层API中封装了Model类,继承了Model类的神经网络可以仅用几行代码完成模型的训练;
(2)新增图像处理模块transform:飞桨新增了图像预处理模块,其中包含数十种数据处理函数,基本涵盖了常用的数据处理、数据增强方法;
(3)提供常用的神经网络模型可供调用:高层API中集成了计算机视觉领域和自然语言处理领域常用模型,包括但不限于mobilenet、resnet、yolov3、cyclegan、bert、transformer、seq2seq等。同时发布了对应模型的预训练模型,可以直接使用这些模型或者在此基础上完成二次开发。
(一)、准备数据
- 导入所需的包
#导入所需的包
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.nn as nn
- 生成图像列表
# 生成图像列表
data_path = './data/data54865/train'
test_path = './data/data54865/test'
character_folder = os.listdir(data_path)
img_size = 225
print(character_folder,len(character_folder))
if(os.path.exists('./train_data.txt')):
os.remove('./train_data.txt')
if(os.path.exists('./test_data.txt')):
os.remove('./test_data.txt')
label2id = {label:i for i,label in enumerate(character_folder)}
labels_number=len(list(label2id))
for character_folder in label2id.keys():
with open('./train_data.txt', 'a') as f_train:
with open('./test_data.txt', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path,character_folder))
count = 0
for img in character_imgs:
if img == '.DS_Store':
continue
if count%10 == 0:
f_test.write(os.path.join(data_path,character_folder,img) + '\t' + str(label2id[character_folder]) + '\n')
else:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + str(label2id[character_folder]) + '\n')
count +=1
print('--- 列表已生成')
- 通过继承paddle.io.Dataset 对数据集进行定义
import paddle
import paddle.vision.transforms as T
import numpy as np
from PIL import Image
class FoodDataset(paddle.io.Dataset):
"""
数据集类的定义
"""
def __init__(self, mode='train_data'):
"""
初始化函数
"""
self.data = []
with open(f'{mode}.txt') as f:
lines = f.readlines()
np.random.shuffle(lines)
for line in lines:
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
img = Image.open(image_file)
img = img.resize((img_size, img_size), Image.ANTIALIAS)
img = np.array(img).astype('float32')
# img = img[:,:,:]
img = img.transpose((2, 0, 1))[:3,:,:] #读出来的图像是rgb,rgb,rbg..., 转置为 rrr...,ggg...,bbb...
# print(img.shape)
img = img[:,:,:]/255.0
# if img.size!=img_size*img_size*3:
# print('error-----------------------',img.size,img.shape)
return img, np.array(label, dtype='int64')
def __len__(self):
"""
获取样本总数
"""
return len(self.data)
# 训练的数据提供器
train_dataset = FoodDataset(mode='train_data')
# 测试的数据提供器
eval_dataset = FoodDataset(mode='test_data')
# 查看训练和测试数据的大小
print('train大小:', train_dataset.__len__())
print('eval大小:', eval_dataset.__len__())
# 查看图片数据、大小及标签
# for data, label in train_dataset:
# print(data)
# print(np.array(data).shape)
# print(label)
# break
(二)、配置网络
代码如下:
from paddle.nn import Linear
import paddle.nn.functional as F
import paddle
#定义DNN网络
class MyDNN(paddle.nn.Layer):
def __init__(self):
super(MyDNN,self).__init__()
self.hidden1 = Linear(img_size,512)
self.hidden2 = Linear(512,256)
self.hidden3 = Linear(256,128)
self.hidden4 = Linear(3*img_size*128,labels_number)
def forward(self,input):
x = self.hidden1(input)
x =F.relu(x)
x = self.hidden2(x)
x = F.relu(x)
x = self.hidden3(x)
x = F.relu(x)
x = paddle.reshape(x, shape=[-1,3*img_size*128])
x = self.hidden4(x)
y = F.softmax(x)
return y
network = MyDNN()
model = paddle.Model(network) # 模型封装
# 配置优化器、损失函数、评估指标
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 可视化模型结构
# paddle.summary(network, (3,225,225))
(三)、训练网络
代码如下:
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=20, # 训练的总轮次
batch_size=64, # 训练使用的批大小
verbose=1, # 日志展示形式
callbacks=[visualdl]) # 设置可视化
训练部分过程如下图3-1所示:
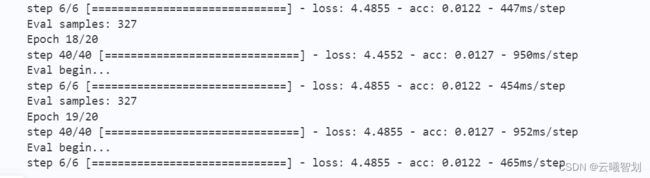
(四)、模型评估
代码如下:
# 模型评估,根据prepare接口配置的loss和metric进行返回
result = model.evaluate(eval_dataset, verbose=1)
print(result)
# 保存模型
model.save('finetuning/model')
结果如下图3-2所示:
(参数有误,导致了准确率过低,不过大体方法和思路是没有问题的)

(五)、模型预测:
代码如下(模型准确率太低,此处不再进行预测图展示):
# 读取图片
def load_image(path):
img = Image.open(path)
img = img.resize((img_size, img_size), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
print(img.shape)
return img
# 读取模型准备预测
model_state_dict = paddle.load('finetuning/model.pdparams')
model = MyDNN()
model.set_state_dict(model_state_dict)
model.eval()
# 读取图片并预测
data = load_image('data/data55032/test/Alexandrite/alexandrite_18.jpg')
ceshi = model(paddle.to_tensor(data))
id2label = {v:k for k,v in label2id.items()}
print('预测的结果为:',id2label[np.argmax(ceshi.numpy())])
总结
本系列文章内容为根据清华社初版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞浆开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
