数据科学与机器学习管道中预处理的重要性(一):中心化,缩放和K近邻
原文链接:The importance of preprocessing in data science and the machine learning pipeline I: centering, scaling and k-Nearest Neighbours
作者:Hugo Bowne-Anderson
译者:刘翔宇 审校:刘帝伟
责编:周建丁([email protected])
未经许可,谢绝转载!
数据预处理是一个概括性术语,它包括一系列的操作,数据科学家使用这些方法来将原始数据处理成更方便他们进行分析的形式。例如,在对推特数据进行情感分析之前,你可能想去掉所有的HTML标签,空格,展开缩写词,将推文分割成词汇列表。在分析空间数据的时候,你可能要对其进行缩放,使其与单位无关,也就是说算法不关心原始的度量是英里还是厘米。然后,数据预处理并不是凭空产生的。预处理只是一种达到目的的手段,并没有硬性、简便的规则:我们将会看到这有标准的做法,你也会了解到哪些可以起作用,但最终,预处理一般是面向结果管道的一部分,它的性能需要根据上下文来判断。
在这篇文章中,我将通过缩放数值数据(数值数据:包含数字的数据,而不是包含类别/字符串;缩放:使用基本的算术方法来改变数据的范围;下面会详细描述)来向你展示将预处理作为机器学习管道结构一部分的重要性。为此,我们将会使用一个实际的例子,在此例子中缩放数据可以提升模型的性能。在文章的最后,我也会列出一些重要的术语。
首先,我将介绍机器学习中的分类问题以及K近邻,它是解决这类问题时使用到的最简单的算法之一。在这种情形下要体会缩放数值数据的重要性,我会介绍模型性能度量方法和训练测试集的概念。在接下来的试验中你将会见识到这些所有的概念和实践,我将使用一个数据集来分类红酒的质量。我同样会确保我把预处理使用在了刀刃上——在一次数据科学管道迭代开始的附近。这里所有的样例代码都由Python编写。如果你不熟悉Python,你可以看看我们的DataCamp课程。我将使用pandas库来处理数据以及scikit-learn 来进行机器学习。
机器学习中分类问题简介
给现象世界中的事物进行分类和标记是一门古老的艺术。在公元前4世纪,亚里士多德使用了一套系统来分类生物,这套系统使用了2000年。在现代社会中,分类通常作为一种机器学习任务,具体来说是一种监督式学习任务。监督式学习的基本原理很简单:我们有一堆有预测变量和目标变量组成的数据。监督式学习的目标是构建一个“擅长”通过预测变量来预测目标变量的模型。如果目标变量包含类别(例如“点击”或“不是”,“恶性”或“良性”肿瘤),我们称这种学习任务为分类。如果目标是一个连续变化的变量(例如房屋价格),那么这是一个回归任务。
以一个例子进行说明:考虑心脏病数据集,其中有75个预测变量,例如“年龄”,“性别”和“是否吸烟”,目标变量为心脏病出现的可能性,范围从0(没有心脏病)到4。此数据集的许多工作都集中于区分会出现心脏病的数据和不会出现心脏病的数据。这是一个分类任务。如果你是要预测出目标变量具体的值,这就是一个回归问题了(因为目标变量是有序的)。我将会在下一篇文章中讨论回归。在这里我将集中于讲述分类任务中最简单的算法之一,也就是K近邻算法。
机器学习中K近邻分类
假如我们有一些标记了的数据,比如包含红酒特性的数据(比如酒精含量,密度,柠檬酸含量,pH值等;这些是预测变量)和目标变量“质量”和标签“好”和“坏”。然后给出一条新的未标记的红酒特性数据,分类任务就是预测这条数据的“质量”。当所有的预测变量都是数值类型时(处理分类数据还有其他的方法),我们可以将每一行/红酒看作是n维空间中的一点,在这种情形下,不管在理论上还是计算上,K近邻(k-NN)都是一种简单的分类方法:对于每条新的未标记的红酒数据,计算一个整数k,是在n维预测变量空间中距离最近的k个质心。然后我们观察这k个质心的标签(即“好”或“坏”),然后将最符合的标签分配给这条新的红酒数据(例如,如果k=5,3的质心给出的是“好”,k=2的质心给出的是“坏”,那么模型将新红酒数据标记为“好”)。需要注意的是,在这里,训练模型完全由存储数据构成:没有参数需要调整!
K近邻可视化描述
下图是2维k-NN算法的样例:你怎么分类中间那个数据点?如果k=3,那么它是红色,如果k=5,那么它是绿色。
from IPython.display import Image
Image(url= 'http://36.media.tumblr.com/d100eff8983aae7c5654adec4e4bb452/tumblr_inline_nlhyibOF971rnd3q0_500.png')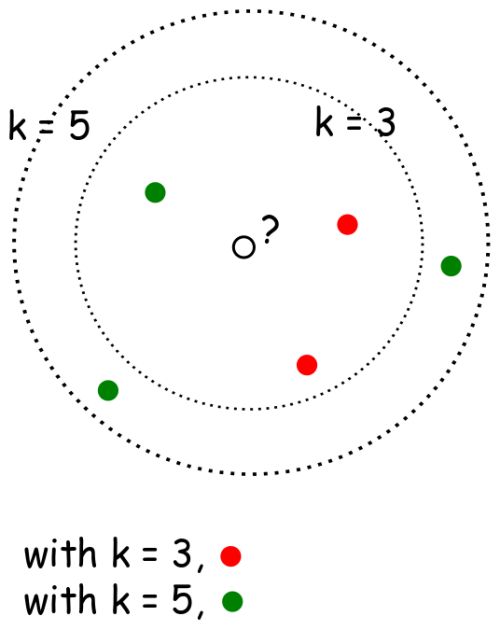
Python(scikit-learn)实现k-NN
现在我们来看一个k-NN实战例子。首先我们要导入红酒质量数据:我们把它导入到pandas的dataframe中,然后用直方图绘制预测变量来感受下这些数据。
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ' , sep = ';')
X = df.drop('quality' , 1).values # drop target variable
y1 = df['quality'].values
pd.DataFrame.hist(df, figsize = [15,15]);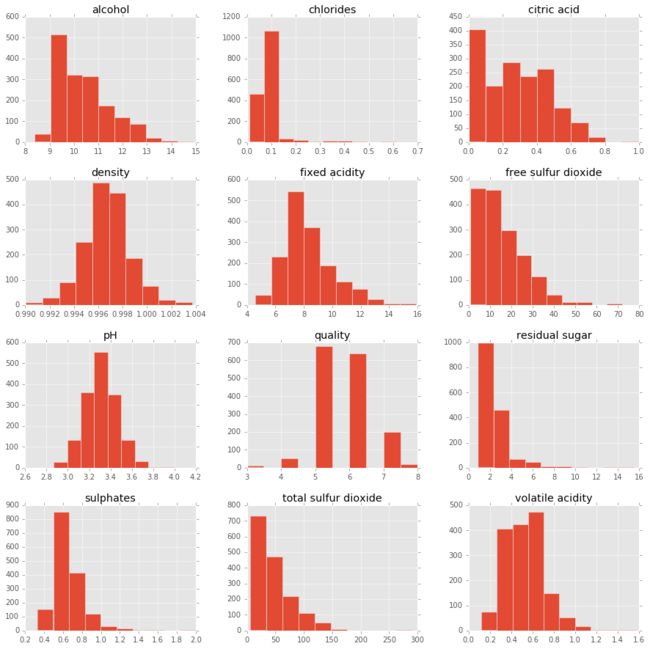
首先看看预测变量的范围:“游离二氧化硫(free sulfur dioxide)”从0到70,“挥发性酸(volatile acidity)”大约从0到1.2。具体而言,前者比后者大两个数量级。任何关心数据点之间距离的算法,如k-NN,都会直接不公平的处理这些更大范围的变量,如“游离二氧化硫”,它可能包含噪声。这促使我们缩放数据,我们很快会讲到。
现在目标变量是“质量”,等级(rating)范围从3到8。为便于解释,我们把它分为两类,包含“好”的变量(rating>5)和“坏”的变量(rating<=5)。同样我们使用直方图来绘制这两种目标变量来获得直观体验。
y = y1 <= 5 # is the rating <= 5?
# plot histograms of original target variable
# and aggregated target variable
plt.figure(figsize=(20,5));
plt.subplot(1, 2, 1 );
plt.hist(y1);
plt.xlabel('original target value')
plt.ylabel('count')
plt.subplot(1, 2, 2);
plt.hist(y)
plt.xlabel('aggregated target value')
plt.show()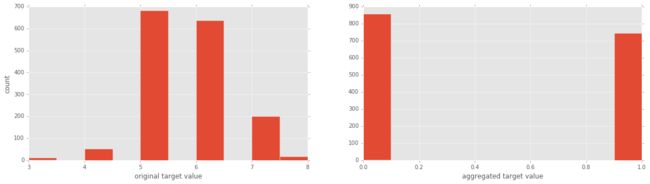
现在我们可以进行K近邻操作了。首先,如果我们要比较经预处理和没经预处理得到的模型的性能,我们需要知道如何衡量一个模型的“好坏”:
K近邻:它执行效果如何?
对于分类任务有许多性能度量措施。需要注意的是,性能度量的选择很大程度上取决于具体的领域和问题。在类别分布平衡的数据集上(所有的目标值都同样表示),数据科学家通常将准确率作为性能度量。事实上,我们将会看到在scikit-learn中准确率是k-NN和逻辑回归默认的性能度量方法。那么什么是准确率呢?它就是由正确预测的数目除以总预测数得来。

注意:准确率同样可以用混淆矩阵来定义,而且通常为二元分类中的真阳性和假阴性定义;从混淆矩阵衍生出的其他一些常见的模型性能度量方法有精度(precision),用真阳性样例数目除以真和假阳性样例数目,召回率(recall),用真阳性样例数目除以真阳性和假阴性样例数目;还有另外一个度量方式,F1-score,是精度和召回率的调和平均数。参见machine learning mastery 来了解这些度量方式;同样可以在Wikipedia上了解关于混淆矩阵和F1 score的相关信息。
k-NN:实际性能和训练测试拆分
使用诸如精度的性能度量的确不错,但是如果用所有的数据来拟合模型,我们用哪些数据来生成精度报告呢?请记住,我们需要一个对新数据具有良好泛化的模型。因此,如果我们在数据集D上训练模型,使用同样的数据集D来生成此模型的精度,这样可能会比实际情况下的产生的精度要高。这被称为过度拟合。为了解决这个问题,数据科学家通常用数据集的子集来训练模型,这个子集叫做训练集,然后使用剩下的数据来评估性能,被称为测试集。这正是我们要在这里做的!一般的经验法则是使用大约80%的数据作为训练数据,20%的数据作为测试数据。现在我们来拆分红酒质量数据集:
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)我们现在建立k-NN模型,在测试集上进行预测,然后将这些预测与实际结果进行对比来度量模型的性能。
from sklearn import neighbors, linear_model
knn = neighbors.KNeighborsClassifier(n_neighbors = 5)
knn_model_1 = knn.fit(X_train, y_train)
print('k-NN accuracy for test set: %f' % knn_model_1.score(X_test, y_test))k-NN accuracy for test set: 0.612500值得重申的是scikit-learn中k-NN默认的计分方法是精度。61%的精度不算太好,但是没有经过预处理而生成的模型可以达到这个精度还算不错。要查看其它各种指标,我们可以使用scikit-learn中的分类报告:
from sklearn.metrics import classification_report
y_true, y_pred = y_test, knn_model_1.predict(X_test)
print(classification_report(y_true, y_pred)) precision recall f1-score support
False 0.66 0.64 0.65 179
True 0.56 0.57 0.57 141
avg / total 0.61 0.61 0.61 320现在我们来介绍缩放和中心化,它们是预处理数值型数据最基本的方法,看看它们如何影响模型的性能。
预处理机制:缩放和中心化
在运行模型前,比如回归(预测连续变量)或分类(预测离散变量),你几乎总想要对数据做一些预处理工作。对于数值型变量,通常会对数据进行标准化或规范化。这些术语是什么意思?
所有的标准化操作就是将数据集缩放,使其最小值为0,最大值为1。为实现这一目标,我们将数据点x变换成 
规范化略有不同;它将数据向0集中,使用标准差进行缩放: 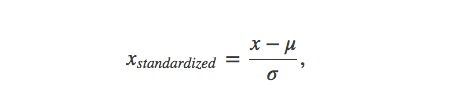
其中μ和σ分别表示数据集的平均值和标准差。首先要注意的是,这些变换仅仅改变数据的范围而没有改变其分布。之后你可能会使用其他的变换,比如log变换或者Box-Cox变换,让数据更像高斯分布(如钟形曲线)。在进一步讲述之前,我们首先弄清楚这么一个问题:我们为什么缩放数据?有没有在某个情形下更适合缩放数据呢?比如,在分类问题中使用缩放数据比在回归中更重要?
首先我们来看看在分类问题中缩放数据对k-NN性能的影响:
预处理:缩放实战
在这里,我首先(i)缩放数据,(ii)使用k-NN,(iii)检查模型的性能。我将使用scikit-learn的scale函数,它对输入的数组中所有的特征(列)进行缩放。
from sklearn.preprocessing import scale
Xs = scale(X)
from sklearn.cross_validation import train_test_split
Xs_train, Xs_test, y_train, y_test = train_test_split(Xs, y, test_size=0.2, random_state=42)
knn_model_2 = knn.fit(Xs_train, y_train)
print('k-NN score for test set: %f' % knn_model_2.score(Xs_test, y_test))
print('k-NN score for training set: %f' % knn_model_2.score(Xs_train, y_train))
y_true, y_pred = y_test, knn_model_2.predict(Xs_test)
print(classification_report(y_true, y_pred))k-NN score for test set: 0.712500
k-NN score for training set: 0.814699
precision recall f1-score support
False 0.72 0.79 0.75 179
True 0.70 0.62 0.65 141
avg / total 0.71 0.71 0.71 320所有的这些度量值都提升了0.1,提高了16%,太显著了!从上面可以看出,在缩放数据之前,有许多不同量级范围的预测变量,意味着它们其中的一或两个在算法中占主导地位,比如k-NN。缩放数据的两个主要原因是:
- 预测变量可能包含非常不同的范围,并且在某些情况下,比如使用k-NN时,这些变量值需要进行削减以免某些特征在算法中占主导地位;
- 你希望你的特征是单位独立的,也就是说,不涉及单位度量:例如,你可能有一些以米为单位的特征,我可能有用厘米表示的同样的特征。如果我们各自缩放数据,这些特征对我们来说都会是一样的。
我们已经通过缩放和中心化预处理形式知道了数据科学管道中的关键部分,并且我们通过这些方法改进了机器学习问题时使用到的方法。在以后的文章中,我希望将此话题延伸到其他类型的预处理,比如数值数据的变换和分类数据的预处理,它们都是数据科学家工具箱中不可或缺的方式。在此之前,下一篇文章我将介绍缩放在用于分类的回归模型中的作用。我将分析逻辑回归,你将会发现这个结果与刚才在k-NN中看到的结果截然不同。
在下面的交互式窗口中,你可以玩转你的数据。首先改变变量n_neig的值,它表示的是k-NN算法中质心的个数。同样如果你愿意的话,你可以通过设定sc=True来缩放数据。然后运行整个脚本来得到模型的准确率报告和分类报告。
# Set the the number of neighbors for k-NN
n_neig = 5
# Set sc = True if you want to scale your features
sc = False
# Load data
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv ' , sep = ';')
X = df.drop('quality' , 1).values # drop target variable
# Here we scale, if desired
if sc == True:
X = scale(X)
# Target value
y1 = df['quality'].values # original target variable
y = y1 <= 5 # new target variable: is the rating <= 5?
# Split the data into a test set and a training set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train k-NN model and print performance on the test set
knn = neighbors.KNeighborsClassifier(n_neighbors = n_neig)
knn_model = knn.fit(X_train, y_train)
y_true, y_pred = y_test, knn_model.predict(X_test)
print('k-NN accuracy for test set: %f' % knn_model.score(X_test, y_test))
print(classification_report(y_true, y_pred))<script.py> output:
k-NN accuracy for test set: 0.612500
precision recall f1-score support
False 0.66 0.64 0.65 179
True 0.56 0.57 0.57 141
avg / total 0.61 0.61 0.61 320术语表
监督式学习(Supervised learning):从预测变量中推断目标变量。比如从“年龄”,“性别”和“是否吸烟”这样的预测变量中推断目标变量“患心脏病”。
分类任务(Classfication task):如果目标变量包含类别(比如“点击”或“不是”,“恶性”或“良性”肿瘤),那么这种监督式学习任务就是一个分类任务。
回归任务(Regression task):如果目标变量包含连续变化变量(比如房屋价格)或是有序的分类变量,比如“红酒质量级别”,那么这种监督式学习任务就是一个回归任务。
K近邻(k-Nearest Neighbors):分类任务的一种算法,一个数据点的标签由离它最近的k个质心投票决定。
预处理:数据科学家会使用的任何操作,将原始数据转换成更适合他们工作的形式。例如,在对推特数据进行情感分析之前,你可能想去掉所有的HTML标签,空格,展开缩写词,将推文分割成词汇列表。
中心化和缩放:这都是数值数据预处理方式,这些数据包含数字,而不是类别或字符;对一个变量进行中心化就是减去所有数据点的平均值,让新变量的平均值为0;缩放变量就是对每个数据点乘以一个常数来改变数据的范围。想知道这些操作的重要性,参见全文以及案例。