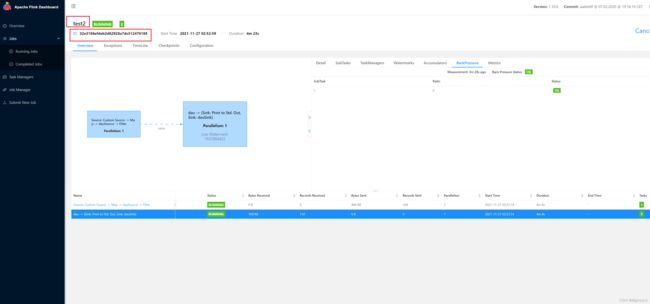
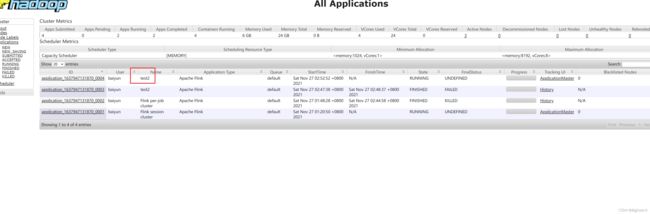
flink yarn-per-job模式 后台执行 定义 yarn名称 定义 flinkjob名称 jdbcSink动态传参 消费aws kinesis配置aliyun scala编译
flink run -d -m yarn-cluster -ynm test2 -c xx.xx /home/baiyun/xxxx/target/xxxx.jar \ --xxx xx --xx xxx --xx xxx --tableName xx --jobName test2
注意scala版本与集群flink匹配,hadoop版本不要带到jar包中,以免与集群冲突,另外的依赖需要放到flink lib目录下面

<properties>
<java.version>1.8java.version>
<scala.binary.version>2.11scala.binary.version>
<kda.version>2.0.0kda.version>
<kda.runtime.version>1.2.0kda.runtime.version>
<flink.version>1.10.1flink.version>
<hadoop.version>2.7.1hadoop.version>
properties>
<repositories>
<repository>
<id>maven-aliid>
<url>http://maven.aliyun.com/nexus/content/groups/public//url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>trueenabled>
<updatePolicy>alwaysupdatePolicy>
<checksumPolicy>failchecksumPolicy>
snapshots>
repository>
repositories>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.amazonawsgroupId>
<artifactId>aws-java-sdk-bomartifactId>
<version>1.11.903version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
<scope>providedscope>
<exclusions>
<exclusion>
<groupId>xml-apisgroupId>
<artifactId>xml-apisartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.44version>
dependency>
<dependency>
<groupId>software.amazon.awssdkgroupId>
<artifactId>kinesisartifactId>
<version>2.0.0version>
dependency>
<dependency>
<groupId>com.amazonawsgroupId>
<artifactId>aws-kinesisanalytics-runtimeartifactId>
<version>${kda.runtime.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kinesis_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>com.amazonawsgroupId>
<artifactId>aws-kinesisanalytics-flinkartifactId>
<version>${kda.version}version>
dependency>
<dependency>
<groupId>org.json4sgroupId>
<artifactId>json4s-native_2.10artifactId>
<version>3.2.11version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
<scope>providedscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.3.0version>
<configuration>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
descriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<version>2.4version>
<configuration>
<archive>
<manifest>
<addClasspath>trueaddClasspath>
<classpathPrefix>lib/classpathPrefix>
<mainClass>com.example.MainClassmainClass>
manifest>
archive>
configuration>
plugin>
plugins>
build>
class MyJdbcSink(tableName:String) extends RichSinkFunction[(String, String, String, Long, String, Long)] {
// 定义一些变量:JDBC连接、sql预编译器()
var conn: Connection = _
var updateStmt: PreparedStatement = _
var insertStmt: PreparedStatement = _
// open函数用于初始化富函数运行时的上下文等环境,如JDBC连接
override def open(parameters: Configuration): Unit = {
println("----------------------------open函数初始化JDBC连接及预编译sql-------------------------")
super.open(parameters)
conn = DriverManager.getConnection(URL, USER, PASSWORD)
insertStmt = conn.prepareStatement(s"INSERT INTO xx.$tableName (prt_dt, project, uv, pv,update_date) VALUES (?, ?, ?, ?,?)")
updateStmt = conn.prepareStatement(s"UPDATE xx.$tableName set uv = ?, pv = ? ,update_date=? where prt_dt = ? and project = ?")
}
// 调JDBC连接,执行SQL
// 关闭时做清理工作
override def close(): Unit = {
println("-----------------------关闭连接,并释放资源-----------------------")
updateStmt.close()
insertStmt.close()
conn.close()
}
override def invoke(in: (String, String, String, Long, String, Long)): Unit = {
val update_date = fmS.format(System.currentTimeMillis())
val value = DauSs(in._1, in._2, in._4.toInt, in._6.toInt,update_date)
println("-------------------------执行sql---------------------------")
// 执行更新语句
updateStmt.setInt(1, value.uv)
updateStmt.setInt(2, value.pv)
updateStmt.setString(3, value.update_date)
updateStmt.setString(4, value.prt_dt)
updateStmt.setString(5, value.project)
updateStmt.execute()
// 如果update没有查到数据,那么执行insert语句
if (updateStmt.getUpdateCount == 0) {
insertStmt.setString(1, value.prt_dt)
insertStmt.setString(2, value.project)
insertStmt.setInt(3, value.uv)
insertStmt.setInt(4, value.pv)
insertStmt.setString(5, value.update_date)
insertStmt.execute()
}
}
}
