Flink on Yarn 部署Session-Cluster和Per-Job-Cluster
文章目录
- 原理介绍
- Flink on Yarn模式
-
- Session-Cluster模式
- Per-Job-Cluster模式
Flink on Yarn 模式的原理是依靠 YARN 来调度 Flink 任务,目前在企业中使用较多。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要 1 套 Hadoop集群,就可以执行 MapReduce 、Spark和Flink 任务,操作非常方便,运维方面也很轻松。Flink on Yarn 模式需要依赖 Hadoop 集群,并且Hadoop 的版本需要是 2.2 及以上。
原理介绍
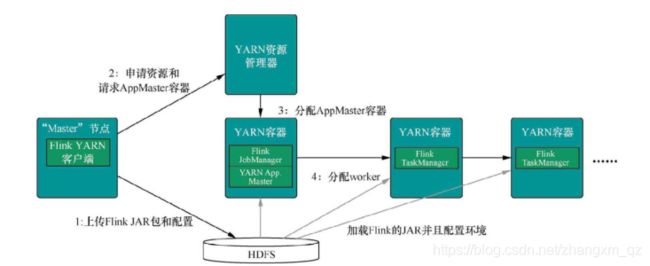
1)当启动一个新的 Flink YARN Client 会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传 Flink 配置和 JAR 文件到 HDFS。
2)客 户 端 请 求 一个 YARN 容 器 启动 ApplicationMaster 。 JobManager 和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM 就能够知道JobManager 的地址,它会为 TaskManager 生成一个新的 Flink 配置文件(这样它才能连上 JobManager),该文件也同样会被上传到 HDFS。另外,AM 容器还提供了 Flink 的Web 界面服务。Flink 用来提供服务的端口是由用户和应用程序 ID 作为偏移配置的,这使得用户能够并行执行多个 YARN 会话。
3)之后,AM 开始为 Flink 的 TaskManager 分配容器(Container),从 HDFS 下载 JAR 文件和修改过的配置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了
Flink n on n Yarn 模式在使用的时候又可以分为两Session-Cluster和Per-Job-Cluster
Session-Cluster
这种模式是在 YARN 中提前初始化一个 Flink 集群(称为 Flinkyarn-session),开辟指定的资源,以后的 Flink 任务都提交到这里。这个 Flink 集群会常驻在 YARN 集群中,除非手工停止。这种方式创建的 Flink 集群会独占资源,不管有没有 Flink 任务在执行,YARN 上面的其他任务都无法使用这些资源

Per-Job-Cluster
这种模式,每次提交 Flink 任务都会创建一个新的 Flink 集群,每个 Flink 任务之间相互独立、互不影响,管理方便。任务执行完成之后创建的 Flink集群也会消失,不会额外占用资源,按需使用,这使资源利用率达到最大,在工作中推荐使用这种模式。
Flink on Yarn模式
link on Yarn 模式需要如下条件:
1)安装配置好 hadoop集群 ,参见:https://blog.csdn.net/zhangxm_qz/article/details/106695347
2)配置好 HADOOP_HOME 环境变量
3)下载 Flink 提交到 Hadoop 的连接器(jar 包),并把 jar 拷贝到 Flink 的 lib 目录下
我这里hadoop版本是2.6.2 jar包下载地址:https://download.csdn.net/download/zhangxm_qz/12737715
Session-Cluster模式
启动hadoop集群
[root@server01 hadoop]# sbin/start-all.sh
通过flink命令启动flink集群
[root@server01 flink]# bin/yarn-session.sh -n 3 -s 3 -nm bjsxt1
yarn-session.sh 参数说明如下:
-n,--container <arg> 表示分配容器的数量(也就是 TaskManager 的数量)。
-D <arg> 动态属性。
-d,--detached 在后台独立运行。
-jm,--jobManagerMemory <arg>:设置 JobManager 的内存,单位是 MB。
-nm,--name:在 YARN 上为一个自定义的应用设置一个名字。
-q,--query:显示 YARN 中可用的资源(内存、cpu 核数)。
-qu,--queue <arg>:指定 YARN 队列。
-s,--slots <arg>:每个 TaskManager 使用的 Slot 数量。
-tm,--taskManagerMemory <arg>:每个 TaskManager 的内存,单位是 MB。
-z,--zookeeperNamespace <arg>:针对 HA 模式在 ZooKeeper 上创建 NameSpace。
-id,--applicationId <yarnAppId>:指定 YARN 集群上的任务 ID,附着到一个后台独立运行的 yarn session 中
问题
我这里启动过程中一直报一个错误:
Container [] is running beyond virtual memory limits. Current Usage: 200MB of 1GB physical memory used; 2.6GB of 2.1GB virtual memory used. Killing container.
提示虚拟内存使用超出范围
网上查找资料 找到原因:
yarn分配的物理内存为1GB,默认的虚拟内存与物理内存的比例为2.1。因此虚拟内存不够,增大虚拟内存与物理内存的比例即可。
修改hadoop 中yarn-site.xml 配置文件 ,增加如下内容,并重启hadoop集群和flink(我这里重启了好几次都不行,但是后来可以了,可以通过http://server01:8088/conf 查看 修改的配置是否生效)
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
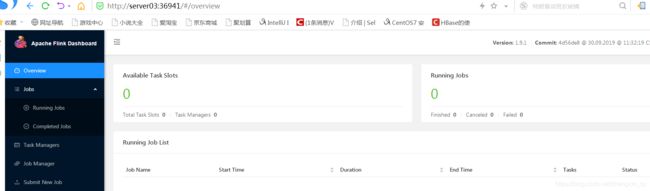
访问FlinkwebUI
执行上述命令启动Flink集群,后日志中会显示 webUI地址,通过该地址可访问 flink webUI
JobManager Web Interface: http://server03:36941
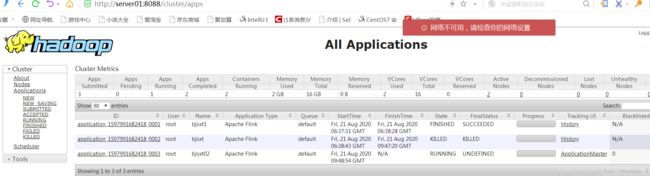
yarn界面中可以看到我们提交的application
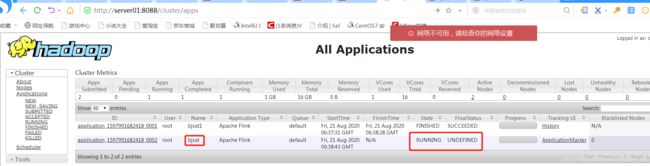
提交任务
flink成功启动后,可以看到本地文件系统中有一个临时文件。有了这个文件可以提交 job 到 Yarn
[root@server01 hadoop]# cat /tmp/.yarn-properties-root
#Generated YARN properties file
#Fri Aug 21 02:39:00 EDT 2020
parallelism=9
dynamicPropertiesString=
applicationID=application_1597991682418_0002
命令提交任务
[root@server01 flink]# bin/flink run -d -c com.test.flink.wc.StreamWordCount ./appjars/test-1.0-SNAPSHOT.jar
2020-08-21 05:40:25,763 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root.
2020-08-21 05:40:25,763 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root.
2020-08-21 05:40:27,148 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 9
2020-08-21 05:40:27,148 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 9
YARN properties set default parallelism to 9
2020-08-21 05:40:27,217 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at server01/192.168.204.10:8032
2020-08-21 05:40:27,445 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-08-21 05:40:27,445 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-08-21 05:40:27,454 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-08-21 05:40:27,560 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'server03' and port '36941' from supplied application id 'application_1597991682418_0002'
Starting execution of program
Job has been submitted with JobID 714f6e03bf0dd2dba7d23db45a5961ab
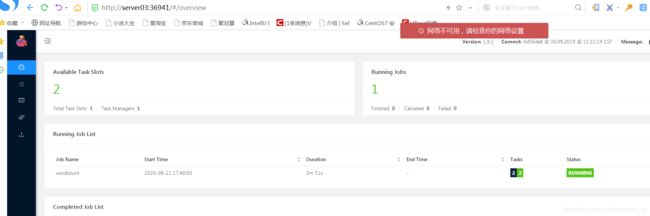
通过webUI 可以看到任务正常执行
Per-Job-Cluster模式
通过命令停止Flink Session-Cluster
[root@server01 flink]# yarn application -kill application_1597991682418_0002
20/08/21 05:47:19 INFO client.RMProxy: Connecting to ResourceManager at server01/192.168.204.10:8032
Killing application application_1597991682418_0002
20/08/21 05:47:20 INFO impl.YarnClientImpl: Killed application application_1597991682418_0002
提交任务
bin/flink run -m yarn-cluster -yn 3 -ys 3 -ynm bjsxt02 -c com.test.flink.wc.StreamWordCount ./appjars/test-1.0-SNAPSHOT.jar
任务提交参数说明:相对于 Yarn-Session 参数而言,只是前面加了 y,详情如下:
-yn,--container <arg> 表示分配容器的数量,也就是 TaskManager 的数量。
-d,--detached:设置在后台运行。
-yjm,--jobManagerMemory<arg>:设置 JobManager 的内存,单位是 MB。
-ytm,--taskManagerMemory<arg>:设置每个 TaskManager 的内存,单位是 MB。
-ynm,--name:给当前 Flink application 在 Yarn 上指定名称。
-yq,--query:显示 yarn 中可用的资源(内存、cpu 核数)
-yqu,--queue<arg> :指定 yarn 资源队列
-ys,--slots<arg> :每个 TaskManager 使用的 Slot 数量。
-yz,--zookeeperNamespace<arg>:针对 HA 模式在 Zookeeper 上创建 NameSpace
-yid,--applicationID<yarnAppId> : 指定 Yarn 集群上的任务 ID,附着到一个后台独立运行的 Yarn Session 中。
上传任务后可以看到application