基于深度学习的图像分割综述
综述:基于深度学习的图像分割
-
- 1 传统的图像分割算法
- 2 基于深度学习的图像分割算法
- 2.1 深度神经网络概述
-
- 2.1.1 卷积神经网络
- 2.1.2 循环神经网络
- 2.1.3 编码器-解码器模型和自动编码器模型
- 2.1.4 生成对抗网络(GAN)
- 2.1.5 迁移学习
- 2.2 基于深度学习的图像分割模型
-
- 2.2.1 Fully Convolutional Networks
- 2.2.2 Convolutional Models With Graphical Models
- 2.2.3 Encoder-Decoder Based Models
- 2.2.4 Multi-Scale and Pyramid Network Based Models
- 2.2.5 R-CNN Based Models
- 2.2.6 Dilated Convolutional Models and DeepLab Family
- 2.2.7 Recurrent Neural Network Based Models
- 2.2.8 Attention-Based Models
- 2.2.9 Generative Models and Adversarial Training
- 2.2.10 CNN Models With Active Contour Models
图像分割是计算机视觉中的一个关键性课题,具有场景理解、医学图像分析、机器人感知、视频监控、增强现实和图像压缩等方面的应用。
1 传统的图像分割算法
在深度学习出现之前已经发展了许多图像分割算法,从最早的阈值分割方法、基于直方图的分割方法、区域生长算法、K-Means 聚类、分水岭算法到更加先进的主动轮廓分割、图割法、条件随机场、马尔可夫随机场、基于稀疏性的方法等。
2 基于深度学习的图像分割算法
基于深度学习的图像分割算法可以分为以下几类:
1) Fully convolutional networks 全卷积神经网络
2) Convolutional models with graphical models 基于图模型的卷积模型
3) Encoder-decoder based models 编码-解码模型
4) Multi-scale and pyramid network based models 基于多尺度和金字塔的网络模型
5) R-CNN based models 基于R-CNN的模型
6) Dilated convolutional models and DeepLab family 空洞卷积模型和DeepLab族
7) Recurrent neural network based models 循环神经网络的模型
8) Attention-based models 基于注意力机制的模型
9) Generative models and adversarial training 生成对抗网络
10) Convolutional models with active contour models 基于主动轮廓模型的卷积网络
11) Other models 其他模型
2.1 深度神经网络概述
此处介绍一些计算机视觉领域使用的一些杰出的深度学习体系结构,目前随着深度学习的普及一些更加前沿的深度神经结构如胶囊网络模型、变压器网络模型等将不在这里进行讨论
2.1.1 卷积神经网络
通俗易懂的卷积神经网络
卷积神经网络中部分数据的传输过程
部分卷积神经网络框架解读
卷积神经网络最著名的一些CNN架构包括:
AlexNet
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
VGGNet
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprin tarXiv:1409.1556, 2014.
ResNet
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
GoogleLeNet
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
MobileNet
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017.
DenseNet
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp.4700–4708.
2.1.2 循环神经网络
卷积神经网络只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。这时,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络①、循环神经网络②、长短时记忆网络
2.1.3 编码器-解码器模型和自动编码器模型
Enncoder-Decoder模型的主要作用是利用一个两级网络将数据点从输入域映射到输出域。编码器通过某个关系将输入映射到‘隐空间表示’,然后通过某种映射关系将‘隐表示’解码至输出域,这里的‘隐表示’实际上就是特征表示(特征图),能够捕捉输入中的底层语义信息。该模型尤其在图像到图像的映射(增强、分割)和NLP问题中的序列模型中应用广泛。
2.1.4 生成对抗网络(GAN)
GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。以下图为例,生成器从先验分布的噪声中随机抽取样本,通过生成器获取对应的生成样本,通过判别器将真实样本和生成样本尽最大可能区分两种样本。循环k次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误。多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自于生成器的输出还是真实的输出。亦即最终样本判别概率均为0.5。
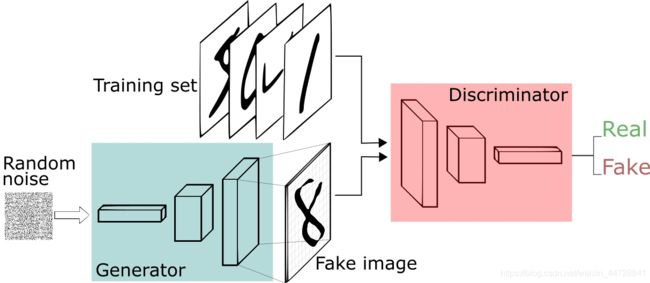
图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。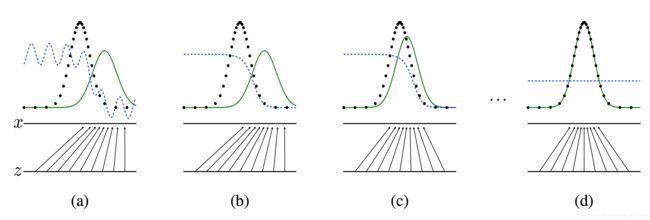
2.1.5 迁移学习
一般情况下,深度学习模型能够在一个新的数据集下进行训练,但是当没有足够的标记数据进行模型训练时,往往可以使用迁移学习的方法解决问题。在迁移学习中,在一个模型中训练得到的参数被应用到另一个相关的模型,通常是通过对新任务的某种适应过程。迁移学习
2.2 基于深度学习的图像分割模型
2.2.1 Fully Convolutional Networks
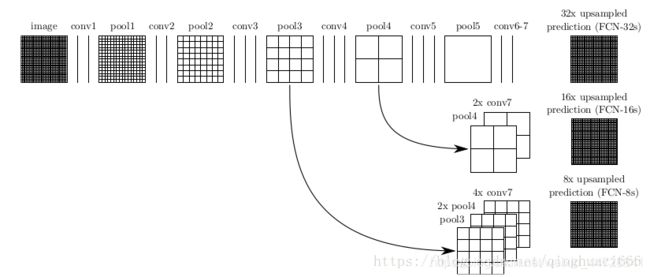
与普通的卷积神经网络不同,全卷积神经网络只由卷积层构成,其允许输入图像为任意尺寸,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。能够实现图像端到端的分割。传统的FCN模型虽然具有普遍性和有效性,但也存在一定的局限性,它不能快速地进行实时推理,不能有效地考虑全局上下文信息,也不容易转换为3D图像。有几项努力试图克服FCN的一些局限性。例如,Liu等人提出了一个名为ParseNet的模型,以解决FCN忽略全局context information的问题. ParseNet通过使用层的平均特征来增加每个位置的特征,将全局context information添加到FCN。
2.2.2 Convolutional Models With Graphical Models
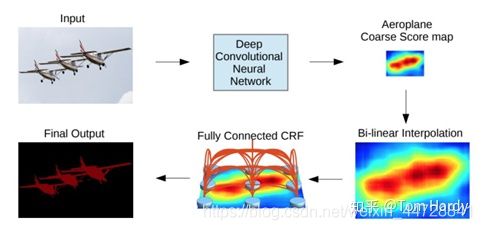
Chen等人提出了一种基于CNN和全连接CRF组合的语义分割算法。他们表明,对于精确的目标分割来说,来自深层CNN最终层的响应并没有得到足够的定位(因为CNN的不变性使得它适合于高层次的任务,比如分类)。为了克服深CNN定位性能差的问题,他们将最终CNN层的响应与全连接的CRF相结合,论文表明,模型能够以比以前的方法更高的准确率定位。
Schwing和Urtasun提出了一种用于图像分割的全连通深结构网络。他们提出了一种联合训练CNNs和全连接CRF进行语义图像分割的方法,并在PASCAL VOC 2012数据集上取得了令人鼓舞的结果。Zheng等人提出了一种结合CRF和CNN的相似语义分割方法。在另一项相关工作中,Lin等人提出了一种基于上下文深度CRF的高效语义分割算法。Liuatal提出了一种将丰富的信息集成到MRF中的语义分类算法,包括高阶关系和混合标签文本。与以往使用迭代算法优化MRF的工作不同,他们提出了一种CNN模型,即一个解析网络,它可以在一次转发过程中实现确定性的端到端计算。
2.2.3 Encoder-Decoder Based Models
另一个流行的用于图像分割的深度模型家族是基于卷积编码器-解码器体系结构的。大多数基于DL的分割工作都使用某种编码-解码模型。论文将这些工作分为两类,用于一般分割的编码器-解码器模型和用于医学图像分割的编码器-解码器模型。
Badrinarayanan等人提出了一种用于图像分割的卷积编码器架构,SegNet的核心由一个编码器网络(在拓扑上与VGG16网络中的13个卷积层相同)和一个对应的解码器网络以及一个像素级分类层组成。SegNet的主要新颖之处在于解码器对其低分辨率输入特征映射进行上采样;具体来说,它使用在相应编码器的最大池步骤中计算的池索引来执行非线性上采样。这消除了学习向上采样的必要性。然后(稀疏的)上采样地图与可训练滤波器卷积以产生密集的特征图。SegNet在可训练参数的数量上也比其他结构小得多。同一作者还提出了SegNet的Bayesian版本,用于建模场景分割的卷积编码器-解码器网络固有的不确定性。这一类中另一个流行的模型是最近的一些分割网络,高分辨率网络(HRNet)。除了像在DeConvNet、SegNet、U-Net和V-Net中那样恢复高分辨率表示之外,HRNet通过并行连接高分辨率和低分辨率卷积流并在多个分辨率之间重复交换信息来通过编码过程保持高分辨率表示。
近年来,许多关于语义分割的研究都是以HRNet为骨干,利用上下文模型,如self-attention及其扩展等。其他一些工作采用转置卷积或编码器-解码器进行图像分割,如堆叠反卷积网络(SDN)、Linknet、W-Net和局部敏感反卷积网络进行RGBD分割。

U-Net 网络是一种非常典型的解码器-编码器模型,这里附上一个能实现的U-Net网络连接,下图中的U-Net网络输入和输出图像的图片尺寸不同,这是由于卷积时无填充造成的。可以看出来,就是一个全卷积神经网络,输入和输出都是图像,没有全连接层。较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。
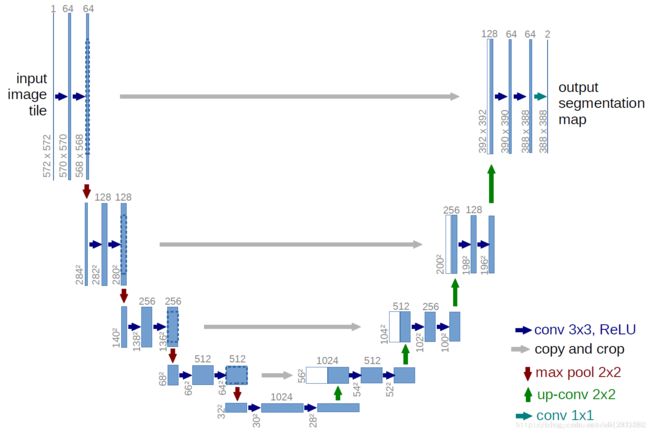
V-Net是一个全卷积的体数据分割神经网络。它采用端到端的训练方式,包含一个新式的目标函数用于训练时进行优化使用。同时能很好的处理背景和非背景之间的强烈不平衡问题。为了解决数据量有限的问题,使用了非线性变换和直方图匹配的方式来进行数据增强。
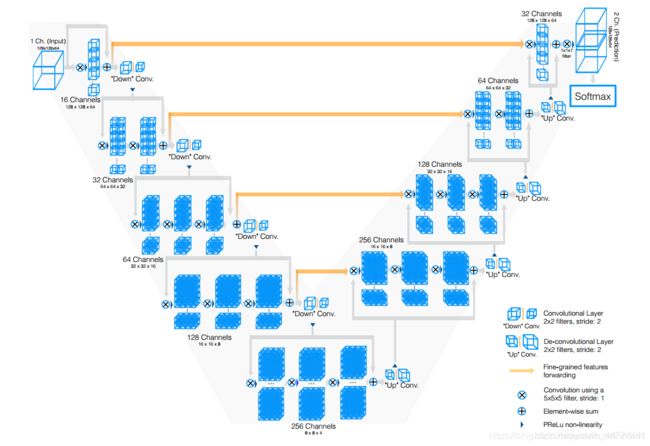
2.2.4 Multi-Scale and Pyramid Network Based Models
多尺度分析的主要思想是,通过自适应输入图片的尺度,产生一系列不同尺寸的特征图,然后将这些特征图进行并行计算。最经典的多尺度分析算法,是由 Lin等人在2017年 IEEE上提出的Feature Pyramid Network (FPN),算法最初被应用于目标检测( object detection),不过之后也被用作图像分割。FPN的工作原理和传统的Encoder-Decoder Based Models类似,都是通过一个bottom-up 过程,一个 top-down 过程,同时经过lateral connections,最终产生分割结果。
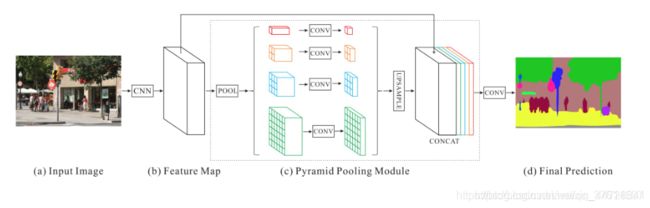
首先PSPN在第一步,使用ResNet和空洞卷积提取feature map。之后,这些特征图会被输入一个pyramid pooling module中,pooling成4个不同size的特征图,其中第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。在pyramid pooling module的过程中,对每一个不同size的特征图,引入了一个1 x 1的卷积,目的是将其维度降低。在这之后,我们得到了4个不同size的、低维度的特征图。我们将这4个特征图up-sampled到原来的大小之后,和初始的特征图进行合并,由此,我们新的特征图包含了local context information(初始特征图提供)和global context information(pyramid pooling特征图提供)。最后,再通过一个卷积层,获得像素级分割。
2.2.5 R-CNN Based Models
何凯明提出了一个用于对象实例分割的Mask R-CNN,它在许多COCO挑战上超过了所有先前的基准。该模型在为每个实例生成高质量分段掩码的同时,有效地检测图像中的对象。详解
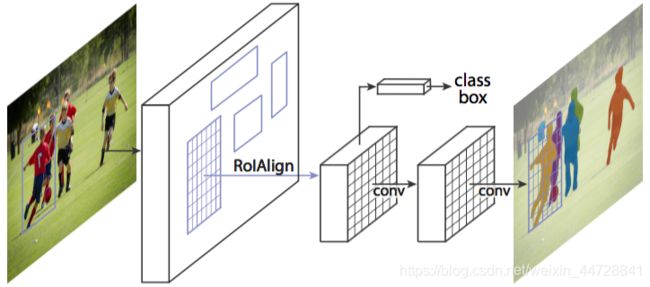
Hu等人提出了一种新的部分监督训练范式和一种新的权值转移函数,该范式使约束状态分类模型成为一个大类别集,所有类别都有框注释,但只有一小部分类别有掩码注释。Chen等人开发了一个实例分割模型MaskLab,该模型基于更快的R-CNN,具有语义和方向特征。另一个有趣的模型是Tensormask,由Chen等人提出,基于密集滑动窗口实例分割。他们将密集实例分割作为4D张量上的预测任务,并提出了一个通用框架,使4D张量上的新算子成为可能。他们证明了张量视图比基线有更大的增益,产生的结果与掩模R-CNN相当。TensorMask在密集对象分割方面取得了很有希望的结果(许多其他的实例分割模型是基于R-CNN开发的,例如那些为掩码建议开发的模型,包括R-FCN、DeepMask、SharpMask、PolarMask和边界感知实例分割。值得注意的是,还有一个很有前途的研究方向是尝试通过学习用于自底向上分割的分组线索来解决实例分割问题,例如深分水岭变换和通过深度量学习进行语义实例分割。
2.2.6 Dilated Convolutional Models and DeepLab Family
在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测,之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。Dilated convolution的主要贡献就是,在去掉池化下采样操作的同时,而不降低网络的感受野。从下面两张图可以很容易的看出,相同size的featuer map使用空洞卷积可以拥有更大的感受野,从而避免了pooling时图片信息损失。
使用空洞卷积进行图像分割
空洞卷积的深度理解
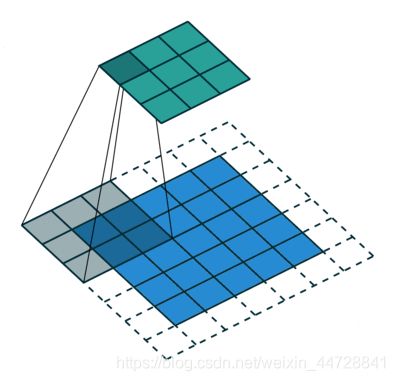
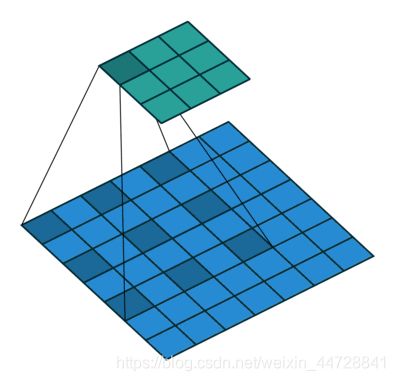
膨胀卷积在实际时间段中已被广泛应用,其中一些最重要的包括DeepLab家族、多尺度Context Aggregation、密集上采样卷积和混合扩张卷积(DUC-HDC)、Densespp和ENet。
DeepLabv1和DeepLabv2是Chenetal开发的最流行的图像分割方法之一,后者有三个关键特性:第一,使用扩展卷积来解决网络中分辨率降低的问题(由max pooling和striding引起)。第二种是atrus空间金字塔池(ASPP),它在多个采样率下使用滤波器探测传入的卷积特征层,从而在多个尺度上捕获对象和图像上下文,以在多个尺度上可靠地分割对象。第三种是结合深CNNs和概率图形模型的方法改进目标边界的定位。最佳的DeepLab(使用ResNet-101作为主干)在2012年pascal VOC挑战赛中达到79.7%的mIoU分数,在cityscape挑战赛中达到70.4%的mIoU分数。
随后,Chen等人提出了DeepLabv3,它结合了级联和并行的扩展卷积模块。并行卷积模块分组在ASPP中。在ASPP中加入了1×1卷积和批量正态化。2018年,Chen等人发布的Deeplabv3+,它使用编码器-解码器架构,包括Atrus separable convolution、每个输入通道的空间卷积和点卷积。他们使用DeepLabv3框架作为编码器。在COCO和JFT数据集上预训练的最佳DeepLabv3+在2012年pascal VOC挑战赛中获得89.0%的mIoU分数。
2.2.7 Recurrent Neural Network Based Models
虽然CNN是解决计算机视觉问题的一种天然手段,但它并不是唯一的可能性。RNNs在建立像素间的短期/长期依赖关系模型以(潜在地)改善分割图的估计方面非常有用。使用RNNs,像素可以被连接在一起并按顺序处理,以建模全局信息进行语义分割。
2.2.8 Attention-Based Models
多年来,注意机制一直在计算机视觉中被不断探索,因此,发现将这种机制应用于语义分割的出版物也就不足为奇了。Chen等人提出了一种attention机制,学习在每个像素位置对多尺度特征进行软加权。它们采用了一个强大的语义分割模型,并与多尺度图像和attention模型联合训练。attention机制的性能优于平均值和最大值池,使模型能够在不同的位置和尺度上评估特征的重要性。
RAN是一个同时执行直接和反向attention学习过程的三分支网络。Li等人开发了一个用于语义分割的金字塔attention网络。该模型充分利用了全局上下文信息对语义分割的影响。他们将注意力机制和空间金字塔结合起来,提取精确的密集特征用于像素标记,而不是复杂的扩展卷积和精心设计的解码网络。最近,Fu等人提出了一种用于场景分割的双attention网络,该网络能够基于自注意机制捕获丰富的上下文依赖关系。
2.2.9 Generative Models and Adversarial Training
GANs自提出以来,已被广泛应用于计算机视觉领域,并被用于图像分割。Luc等人提出了一种对抗性的语义分割训练方法。他们训练了一个卷积式语义分割网络,以及一个对抗性网络,该网络将地面真值分割图与分割网络生成的真值分割图区分开来。他们展示了这种差异训练方法提高了在PASCAL VOC 2012数据集上的准确性。
2.2.10 CNN Models With Active Contour Models
FCNs和活动轮廓模型(ACMs)之间协同作用的探索最近引起了研究兴趣。一种方法是根据ACM原理建立新的损失函数。例如Chen等人提出了一个有监督的丢失层,该层在FCN训练过程中包含了预测掩模的面积和大小信息,解决了心脏MRI中心室分割的问题。同样,Gur等人提出了一种基于无边缘形态学活动轮廓的无监督损失函数,用于微血管图像分割。一种不同的方法最初试图将ACM仅仅用作FCN输出的后处理程序,一些努力试图通过对FCN进行预训练来实现适度的共同学习。Le等人的工作是一个用于自然图像语义分割的ACM后处理器的例子。Hatamizadeh等人提出了一个集成的深部活动损伤(DALS)模型,用于训练背根骨预测新的局部参数化水平集能函数的参数函数。在其他相关工作中,Marcos等人提出了深结构活动轮廓(DSAC),它将ACMs和预先训练的FCNs结合在一个结构化的预测框架中,用于在航空图像中建立实例分割(尽管需要手动初始化)。对于相同的应用程序,Cheng等人提出了与DSAC相似的深度主动射线网络(DarNet),但采用了基于极坐标的不同显式ACM公式来防止轮廓自相交。Hatamizadeh等人最近推出了一种真正的端到端反向传播可训练、完全集成的FCN-ACM组合被称为深卷积活动轮廓(DCAC)。