win11+AMD的cpu+3060GPU电脑安装 tensorflow-GPU+cuda11+cudnn
win11电脑安装 tensorflow-GPU+cuda11
前言
我新买的电脑是AMD的cpu+NVIDIA的3050GPU想试一试这个电脑跑深度学习,就安装一下tensorflow记录一下
安装Anconda
这个往上下载默认安装即可,不做描述
使用命令行新建一个tensorflow的环境
conda create --name tf python=3.7
安装时候有一个需要确认输入 y即可
创建完成切换到创建的环境中
conda activate tf
然后使用豆瓣源pip下载tensorflow2.7相关的依赖包,tensorflow1.15版本以上就不需要区分普通版和Gpu版本的了,可以直接安装,并且keras在安装时也会一并安装下来。
pip install tensorflow==2.7.0 -i https://pypi.douban.com/simple/
安装cuda
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 和中央处理器(Central Processing Unit, CPU)相对,图形处理器(Graphics Processing Unit, GPU)是显卡的核心芯片。而cuda正是暴露了英伟达开发的GPU的编程接口。
这里是cuda的历史版本,选择自己需要的版本号安装
cuda历史版本
我选择的是11.52版本


之后我是win11版本的本地安装不要选错了,如果想跟我一样可以点卡以下链接即可
https://developer.nvidia.com/cuda-11-5-2-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local
然后默认c盘路径安装,选择自定义安装

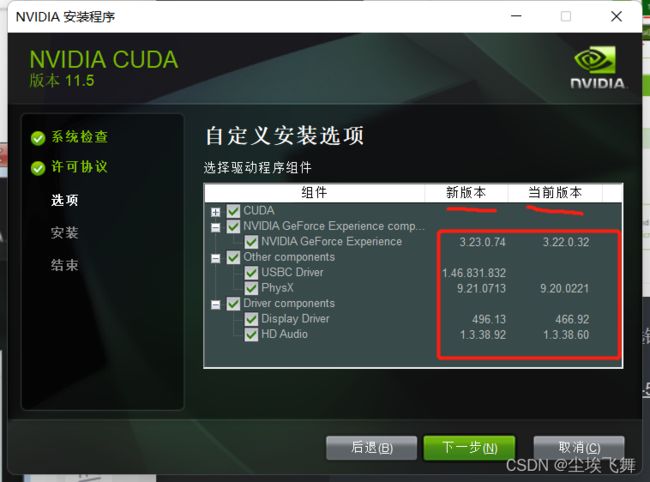
看看自己电脑的当前版本跟新版本的版本号,如果自己电脑比较新可以不用更新取消勾选,我这里比较旧就更新了一下,之后一路下一步安装
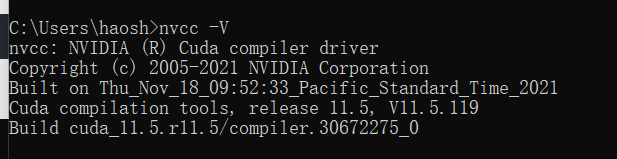
之后输入如下
nvcc -V
即可看到版本号就代表安装成功了
Cudnn的安装
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
进入Cudnn的官网去下载对应版本的cudnn版本:这里需要注册账号,自己注册一下很快
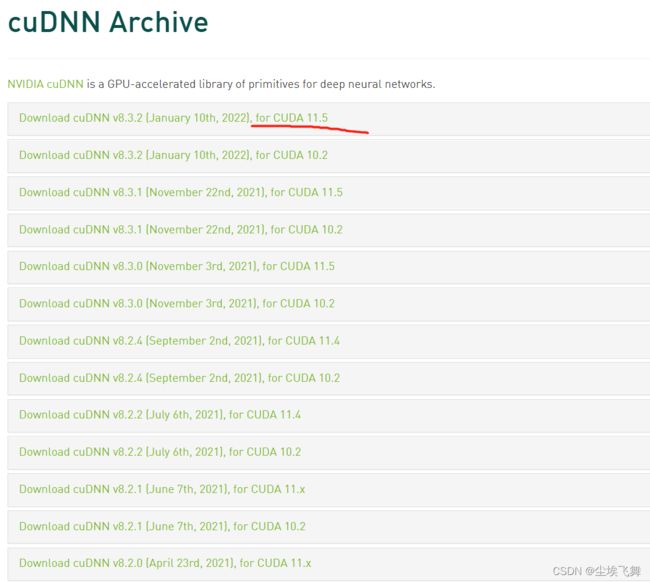
cuDNN所有版本
我选择对应的for cuda11.5的版本下载
选择第zip文件

如果想跟我一样可以点开下面链接,选择第一个
https://developer.nvidia.com/rdp/cudnn-download

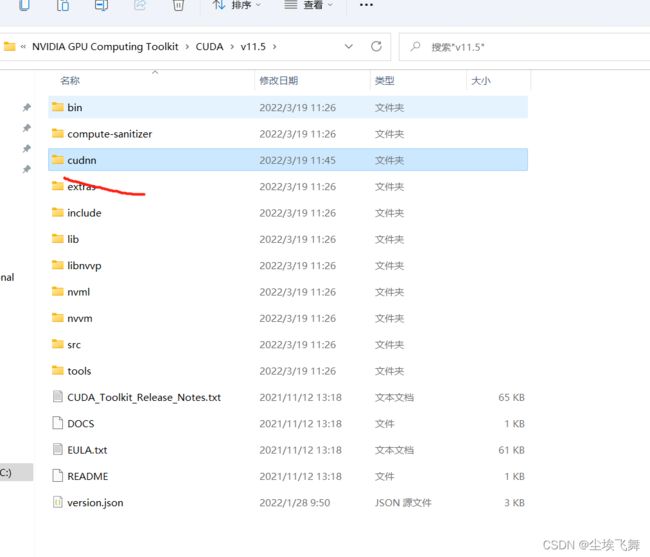
将该压缩包解压后得到一个名为“cuda”的文件夹,将其重命名为“cudnn”。
如果刚刚默认安装的可以在这个路径下找到如下文件
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5

将cudnn整体复制进去
之后编辑环境变量,将以下四个变量编辑到Path中
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\extras\CUPTI\lib64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\cudnn\bin

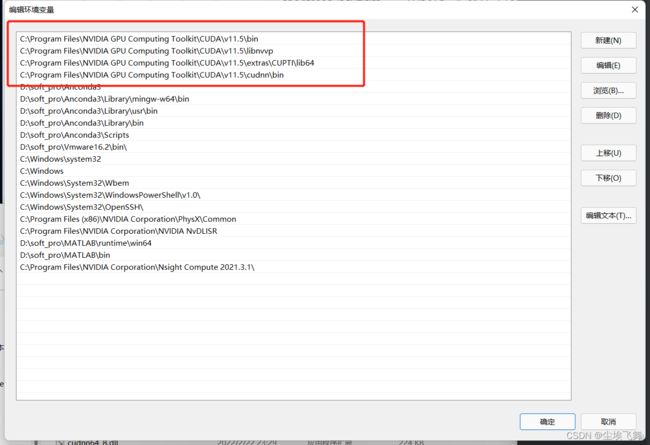
注意上移到最上面
测试

import tensorflow as tf
import timeit
with tf.device('/cpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
print(cpu_a.device, cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
print(gpu_a.device, gpu_b.device)
def cpu_run():
with tf.device('/cpu:0'):
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'):
c = tf.matmul(gpu_a, gpu_b)
return c
# warm up
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('warmup:', cpu_time, gpu_time)
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('run time:', cpu_time, gpu_time)
结果如下运行成功
/job:localhost/replica:0/task:0/device:CPU:0 /job:localhost/replica:0/task:0/device:CPU:0
/job:localhost/replica:0/task:0/device:CPU:0 /job:localhost/replica:0/task:0/device:CPU:0
warmup: 0.6677898000000013 0.6471977999999972
run time: 0.6454234999999997 0.6467144000000005