DETR项目--github--facebookresearch/detr
项目链接:https://github.com/facebookresearch/detr
该项目使用transformer对图像进行集合预测,直接将目标检测中的框的坐标和类别进行输出,与ground truth进行比较优化模型,整个过程不需要进行NMS等后处理操作,实现真正的端到端模型。在此对项目中的主要结构和代码进行记录
DETR结构及前向过程
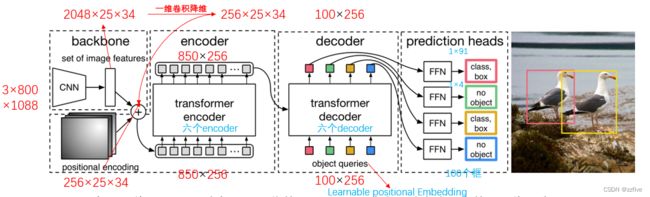
项目结构
- models
- position_encoding.py–存放使用三角函数实现的位置的位置编码和绝对位置可学习的二维空间位置编码
- transformer.py–区别与原版transformer,主要是在encoder和decedr中的q、k、v的设置方式
- matcher.py–使用匈牙利算法从输出的100个集合中给每个ground truth匹配合适的目标框
- backbone.py–使用torch内置的resnet作为backbone抽取图像的feature map
- detr.py–
- segmentation.py–
位置编码–position_encoding.py
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
Various positional encodings for the transformer.
"""
import math
import torch
from torch import nn
from util.misc import NestedTensor
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
类似于transformer中标准的用三角函数实现的位置嵌入层,将每个位置的各个维度映射到角度上,即scale参数,默认为0~2Π
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi # 角度范围为0~2Π
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors # 获取图像中的图像张量,(batch_size,c,h,w)
mask = tensor_list.mask # mask为True表示该部分对应的像素值是通过padding构造的,(batch_size,h,w)
assert mask is not None
not_mask = ~mask # 此处取反,即not_mask为True对应的像素值就是实际图像的像素值
y_embed = not_mask.cumsum(1, dtype=torch.float32) # not_mask在列(垂直)方向累加,数据由布尔型转为浮点型,(batch_size,h,w)
x_embed = not_mask.cumsum(2, dtype=torch.float32) # not_mask在行(水平)方向累加,数据由布尔型转为浮点型,(batch_size,h,w)
# 根据上面的行列累加操作,每行每列的值映射为不同的值
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale # 列方向做归一化
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale # 行方向做归一化
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) # 构造计算公式三角函数中数值的坟墓
pos_x = x_embed[:, :, :, None] / dim_t # (batch_size,h,w,num_pos_feats)
pos_y = y_embed[:, :, :, None] / dim_t # (batch_size,h,w,num_pos_feats)
# 在最后一维中,偶数维上使用正弦函数,奇数维上使用余弦函数
# (batch_size,h,w,num_pos_feats//2)+(batch_size,h,w,num_pos_feats//2)->(batch_size,h,w,num_pos_feats//2,2)->(batch_size,h,w,2*(num_pos_feats//2))
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
# (batch_size,h,w,num_pos_feats//2)+(batch_size,h,w,num_pos_feats//2)->(batch_size,h,w,num_pos_feats//2,2)->(batch_size,h,w,2*(num_pos_feats//2))
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
# (batch_size,h,w,2 *(num_pos_feats // 2))+(batch_size,h,w,2 *(num_pos_feats // 2))->(batch_size,h,w,2*num_pos_feats)->(batch_size,2*num_pos_feats,h,w)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
class PositionEmbeddingLearned(nn.Module):
"""
Absolute pos embedding, learned.可以学习的绝对位置嵌入层
"""
def __init__(self, num_pos_feats=256):
super().__init__()
# 行列编码的第一个维度都是50表示默认backbone采集的图像feature map不大于50X50
self.row_embed = nn.Embedding(50, num_pos_feats)
self.col_embed = nn.Embedding(50, num_pos_feats)
self.reset_parameters()
def reset_parameters(self): # 设置嵌入层参数权重
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
h, w = x.shape[-2:]
# 一行中的每个位置
i = torch.arange(w, device=x.device) # 因为是对行进行编码,就是对该行上所有的列值进行编码
# 一列中的每个位置
j = torch.arange(h, device=x.device) # 因为是对列进行编码,就是对该列上所有的行值进行编码
x_emb = self.col_embed(i) # 将一行中的每个列位置进行编码,(w, num_pos_feats)
y_emb = self.row_embed(j) # 将一列中的每个行位置进行编码,(h, num_pos_feats)
pos = torch.cat([
# (w, num_pos_feats)-> (1, w, num_pos_feats)-> (h, w, num_pos_feats);即将x_emb按行(垂直)方向重复h此,所有行同一列的编码结果一样
x_emb.unsqueeze(0).repeat(h, 1, 1),
# (h, num_pos_feats)-> (h, 1, num_pos_feats)-> (h, w, num_pos_feats);即将y_emb按列(水平)方向重复h此,所有列同一行的编码结果一样
y_emb.unsqueeze(1).repeat(1, w, 1), ],
dim=-1 # 将上面两个向量在最后一维上concat,即(h, w, num_pos_feats)+(h, w, num_pos_feats)->(h, w, 2*num_pos_feats)
).permute(2, 0, 1).unsqueeze(0).repeat(x.shape[0], 1, 1, 1) # (h, w, 2*num_pos_feats)->(2*num_pos_feats,h, w)->(1,2*num_pos_feats,h, w)->(batch_size,2*num_pos_feats,h, w)
return pos
def build_position_encoding(args):
N_steps = args.hidden_dim // 2 # 因为对行、列分类编码,所以维度是隐状态维度的一半
if args.position_embedding in ('v2', 'sine'): # 构建三角函数实现的路径位置编码
# TODO find a better way of exposing other arguments
position_embedding = PositionEmbeddingSine(N_steps, normalize=True)
elif args.position_embedding in ('v3', 'learned'): # 构建可学习的绝对路径二维空间位置编码
position_embedding = PositionEmbeddingLearned(N_steps)
else:
raise ValueError(f"not supported {args.position_embedding}")
return position_embedding
其中三角函数位置编码的计算公式如下图所示
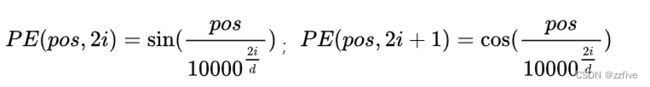
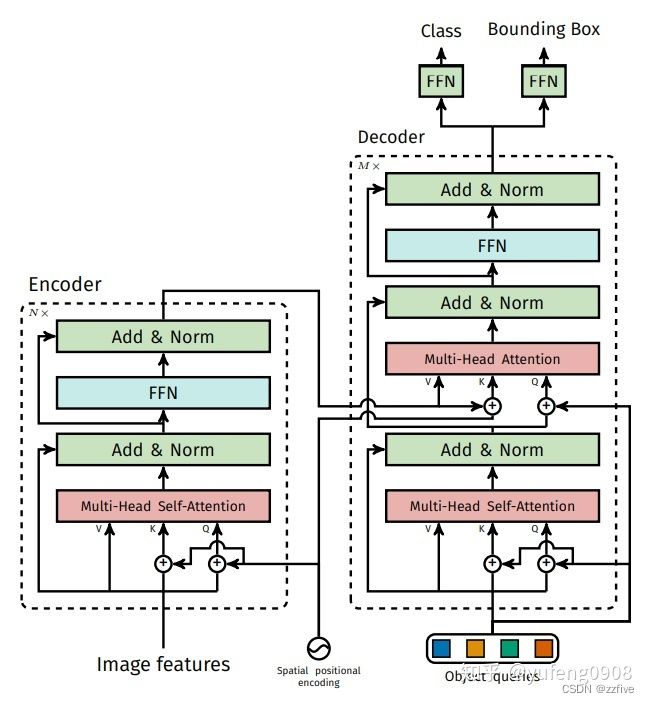
Transformer–DETR使用的Transformer与原始本本不同
DETR的encoder和decoder结构如下图所示;其中spatial positional encoding是二维空间位置编码方法,该编码分别被加入到encoder的self attention和decoder的cross attention,同时object queires也被加入到decoder的两个attention中
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
DETR Transformer class.
Copy-paste from torch.nn.Transformer with modifications:
* positional encodings are passed in MHattention
* extra LN at the end of encoder is removed
* decoder returns a stack of activations from all decoding layers
"""
import copy
from typing import Optional, List
import torch
import torch.nn.functional as F
from torch import nn, Tensor
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
"""
初始化transformer
@param d_model:每个token转为向量后的维度
@param nhead:注意力头数
@param num_encoder_layers:encoder层数
@param num_decoder_layers:decoder层数
@param dim_feedforward:
@param dropout:
@param activation:激活函数
@param normalize_before:如果设置为True,layerNorm是在编码/解码之前进行
@param return_intermediate_dec:
"""
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before) # 一个encoder层
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None # encoder中的LayerNorm层
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm) # 整个的encoder
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before) # 一个decoder层
decoder_norm = nn.LayerNorm(d_model) # decoder中的LayerNorm层
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec) # 整个的decoder
self._reset_parameters() # 对模型的所有参数进行Xavier初始化
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape # 分别是batch_size, channels,height, weight
# NxCxHxW -> NxCxHW -> HWxNxC,相当于从从图片中抽取的特征图的长宽之积转换为序列的长度,N还是batch_size,通道数C变为嵌入层输出大小或隐向量大小
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) # encoder中src是k、v、q
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
"""
TransformerEncoder初始化
@param encoder_layer:nn.Module,即单个的encoder_layer
@param num_layers:int, encoder_layer的层数
@param norm:
"""
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers) # 生成num_layers个参数不共享的encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers) # 生成num_layer个参数不共享的decoder_layer层
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = [] # 每个decoder_layer的输出值
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate: # 如果需要输出中间值,就把每个decoder_layer的输出值记录
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output) # 对最后一层decoer_layer的输出进行layerNorm
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) # endoer中的self attention层
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]): # 在tensor上添加位置编码
return tensor if pos is None else tensor + pos
# layerNorm在最后进行
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos) # q、k是在src的基础上加上位置编码
# self_attention中的v是无位置编码的src
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0] # 经过self_attention层后的输出
src = src + self.dropout1(src2) # residual
src = self.norm1(src) # 正则化
src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # 经过两个全连接层的FFN的输出
src = src + self.dropout2(src2)
src = self.norm2(src)
return src # encoder的输出,尺寸没有改变
# layerNorm在最前进行
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src) # 先进行LayerNorm
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) # self_attention层
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) # cross_attention层
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
# layerNorm在最后进行
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos) # q、k是在tgt的基础上加上查询位置编码
# self_attention中的v是无位置编码的tgt
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0] # 此处的tgt2是self_attention层的输出
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt) # 此处的tgt通过了add+norm操作
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), # q是tgt的基础上加上最早的查询位置编码
key=self.with_pos_embed(memory, pos), # k是encoder的输出加上空间位置编码
value=memory, attn_mask=memory_mask, # v就是单纯的encoder的输出
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt)))) # FFN计算
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
# layerNorm在最前进行
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)]) # 生成N个参数不共享的module存放在ModuleList中
def build_transformer(args):
return Transformer(
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True, # 输出decoder中每个decoder_layer的输出
)
def _get_activation_fn(activation): # 返回对应函数
"""Return an activation function given a string"""
if activation == "relu":
return F.relu
if activation == "gelu":
return F.gelu
if activation == "glu":
return F.glu
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
matcher.py
decoder的输出分别经过两个FFN对num_queries个框的类别和坐标进行预测,输出的两个张量尺寸分别为[batch_size, num_queries, num_classes]和[batch_size, num_queries, 4],其为对一个batch的预测,再结合该batch中每个图片ground truth的类别和坐标计算匹配损失,最后使用匈牙利算法(即调用scipy.optimize.linear_sum_assignment()函数)给batch中每个图片的真实框匹配一对一的预测框,为后续计算损失做准备。HungarianMatcher的用法以及其要求的输入和对应的尺寸在下面代码中有详细注释
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
Modules to compute the matching cost and solve the corresponding LSAP.
"""
import torch
from scipy.optimize import linear_sum_assignment
from torch import nn
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
For efficiency reasons, the targets don't include the no_object. Because of this, in general,
there are more predictions than targets. In this case, we do a 1-to-1 matching of the best predictions,
while the others are un-matched (and thus treated as non-objects).
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost,匹配成本中分类错误的相对权重
cost_bbox: This is the relative weight of the L1 error of the bounding box coordinates in the matching cost,边界框坐标的L1误差在匹配本分中的相对权重
cost_giou: This is the relative weight of the giou loss of the bounding box in the matching cost,bounding box的giou loss在匹配成本中的相对权重
"""
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs can't be 0"
@torch.no_grad()
def forward(self, outputs, targets):
""" Performs the matching
Params:
outputs: This is a dict that contains at least these entries:
"pred_logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits
"pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates
targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i is the indices of the selected predictions (in order)
- index_j is the indices of the corresponding selected targets (in order)
For each batch element, it holds:
len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets]) # 记录一个batch中所有真实框的实际类别对应的标号
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids] # 类别的标号是和索引一致的
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
# Compute the giou cost betwen boxes,先将box格式从[center_x, center_y, h, w]转为[x0, y0, x1, y1],再计算out_boxx和tgt__bbox两两之间的iou
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
# Final cost matrix,使用分别的权重将三种代价叠加
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu() # 在将batch_size维度还原
sizes = [len(v["boxes"]) for v in targets] # 一个batch中每张图含有的ground truth的数量
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))] # linear_sum_assignment即为匈牙利算法进行预测框和真实框匹配
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
def build_matcher(args):
return HungarianMatcher(cost_class=args.set_cost_class, cost_bbox=args.set_cost_bbox, cost_giou=args.set_cost_giou)
def generalized_box_iou(boxes1, boxes2): # 计算boxes1中每个box和boxes2中每个box两两之间的iou
"""
Generalized IoU from https://giou.stanford.edu/
The boxes should be in [x0, y0, x1, y1] format
Returns a [N, M] pairwise matrix, where N = len(boxes1)
and M = len(boxes2)
"""
# degenerate boxes gives inf / nan results
# so do an early check
assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
iou, union = box_iou(boxes1, boxes2)
lt = torch.min(boxes1[:, None, :2], boxes2[:, :2])
rb = torch.max(boxes1[:, None, 2:], boxes2[:, 2:])
wh = (rb - lt).clamp(min=0) # [N,M,2]
area = wh[:, :, 0] * wh[:, :, 1]
return iou - (area - union) / area
def box_cxcywh_to_xyxy(x): # 将box格式从[center_x, center_y, h, w]转为[x0, y0, x1, y1]
x_c, y_c, w, h = x.unbind(-1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=-1)
backbone.py
使用torch内置的resnet作为backbone抽取图像feature map
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
Backbone modules.
"""
from collections import OrderedDict
import torch
import torch.nn.functional as F
import torchvision
from torch import nn
from torchvision.models._utils import IntermediateLayerGetter
from typing import Dict, List
from util.misc import NestedTensor, is_main_process
from .position_encoding import build_position_encoding
class FrozenBatchNorm2d(torch.nn.Module):
"""
BatchNorm2d where the batch statistics and the affine parameters are fixed.
与nn.Module中的BatchNorm2d原理一样,但是其中的统计量(均值和方差)以及可学习的放射参数固定
Copy-paste from torchvision.misc.ops with added eps before rqsrt,
without which any other models than torchvision.models.resnet[18,34,50,101]
produce nans.
"""
def __init__(self, n):
super(FrozenBatchNorm2d, self).__init__()
# 将下面变量注册到buffer中,梯度方向传播时就不会被更新,同时能够记录在模型的state_dict中
self.register_buffer("weight", torch.ones(n))
self.register_buffer("bias", torch.zeros(n))
self.register_buffer("running_mean", torch.zeros(n))
self.register_buffer("running_var", torch.ones(n))
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
num_batches_tracked_key = prefix + 'num_batches_tracked'
if num_batches_tracked_key in state_dict:
del state_dict[num_batches_tracked_key]
super(FrozenBatchNorm2d, self)._load_from_state_dict(
state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
def forward(self, x):
# move reshapes to the beginning
# to make it fuser-friendly
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
rv = self.running_var.reshape(1, -1, 1, 1)
rm = self.running_mean.reshape(1, -1, 1, 1)
eps = 1e-5
scale = w * (rv + eps).rsqrt()
bias = b - rm * scale
return x * scale + bias
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers: # 如果为True,输出中间层
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"} # 否则只输出最后一层
# IntermediateLayerGetter能抽取输入网络(backbone)中指定的中间层(return_layers)的输出
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors) # body就是通过IntermediateLayerGetter获取的,可以用来获取模型不同层输出的多尺寸信息
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
# 将mask插值到与输出的feature map相同的尺寸
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d) # pretrained=is_main_process()表示仅在主进程中使用预训练权重
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
# Joiner是nn.Sequential的子类,通过初始化,使得self[0]是backbone,self[1]是position encoding
class Joiner(nn.Sequential): # 将backbone和spositional embedding集成在一起,在backbone输出feature map就进行位置编码
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
xs = self[0](tensor_list) # 此处的sefl[0]就是backbone,xs中就是backbone的输出
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x) # 记录backbone中每层的原本的输出
# position encoding
pos.append(self[1](x).to(x.tensors.dtype)) # 此处的sefl[1]就是position_embdeeding,记录经过编码后的输出
return out, pos
def build_backbone(args):
# 构建位置编码
position_embedding = build_position_encoding(args)
train_backbone = args.lr_backbone > 0
# 是否记录backbone中每层的输出
return_interm_layers = args.masks
backbone = Backbone(args.backbone, train_backbone, return_interm_layers, args.dilation)
model = Joiner(backbone, position_embedding)
model.num_channels = backbone.num_channels
return model
detr.py
最后的完整的detr就是就上述的各个模块整合在一起
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
DETR model and criterion classes.
"""
import torch
import torch.nn.functional as F
from torch import nn
from util import box_ops
from util.misc import (NestedTensor, nested_tensor_from_tensor_list,
accuracy, get_world_size, interpolate,
is_dist_avail_and_initialized)
from .backbone import build_backbone
from .matcher import build_matcher
from .segmentation import (DETRsegm, PostProcessPanoptic, PostProcessSegm,
dice_loss, sigmoid_focal_loss)
from .transformer import build_transformer
class DETR(nn.Module):
""" This is the DETR module that performs object detection ;用于目标检测的DETR模块"""
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes + 1) # 将decoder_layer的输出映射到类别
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) # 将decoder_layer的输出映射到预测框的坐标
self.query_embed = nn.Embedding(num_queries, hidden_dim) # 论文中的object queries
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1) # 用一维卷积将backbone输出的feature_map的维度降为隐状态维度
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels;1表示padding的像素
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x (num_classes + 1)]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, height, width). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.只有当aux_loss设置为True
时才被激活,是一个字典,包括每个decoder_layer输出的上面两项的值,即pred_logits和pred_boxes
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples) # 将samples转为NestedTensor类
features, pos = self.backbone(samples) # pos是已经在features的基础上进行了位置编码
src, mask = features[-1].decompose()
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
outputs_class = self.class_embed(hs) # 类别预测
outputs_coord = self.bbox_embed(hs).sigmoid() # box预测
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
class SetCriterion(nn.Module):
""" This class computes the loss for DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, eos_coef, losses):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
eos_coef: relative classification weight applied to the no-object category
losses: list of all the losses to be applied. See get_loss for list of available losses.
"""
super().__init__()
self.num_classes = num_classes # 类别数,不包含背景
self.matcher = matcher # 对预测框和真实框进行撇皮的算法
self.weight_dict = weight_dict # 各种loss对应的权重
self.eos_coef = eos_coef # 针对背景分类的loss权重
self.losses = losses # 指定需要计算loss的类型
# 设置在分类loss中,前景的权重为1,背景权重由传递进来的参数指定
empty_weight = torch.ones(self.num_classes + 1)
empty_weight[-1] = self.eos_coef
self.register_buffer('empty_weight', empty_weight) # 将这部分注册到buffer,能够被state_dict记录同时不会有梯度传播此处
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits'] # 形状为[batch_size, num_queries=100, num_classes+1 ]
# 返回一个tuple,表示所匹配的预测结果的batch index(在当前batch中属于第一张)和query index(图像中的第一个query对象)
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)]) # 当前batch中所有ground truth所属的类别
# (batch_size, num_query),初始化为背景
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
# 匹配的预测索引对应的值置为匹配的ground truth
target_classes[idx] = target_classes_o
# 虽然doc string中写的使用NLL loss,但实际用的还是CE loss;因为pytorch中CE loss就是将Log-softmax操作和NLL loss封装在一起了
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
# 计算top-1精度,结果是百分数
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
@torch.no_grad() # 计算预测为前景的数量与grounf truth数量的L1的误差,仅作展示并不是真正的loss,不涉及反向传播
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
pred_logits = outputs['pred_logits']
device = pred_logits.device
tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device)
# Count the number of predictions that are NOT "no-object" (which is the last class)
card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1)
card_err = F.l1_loss(card_pred.float(), tgt_lengths.float())
losses = {'cardinality_error': card_err}
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
# outputs['pred_boxes']的shape是[batch_size, num_queries=100, 4]
src_boxes = outputs['pred_boxes'][idx] # src_boxes的尺寸(num_matched_queries1+num_matched_queries2+..., 4)
# target_boxes的尺寸也是(num_matched_objs1+num_matched_objs2+..., 4),num_matched_queries1+num_matched_queries2+...=num_matched_objs1+num_matched_objs2+...
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none') # 计算boxes中中心左边和高、宽的L1损失
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes # 平均L1损失
# generalized_box_iou返回的是每个预测结果与每个ground truth的giou,因此取对角线代表获取的是相互匹配的预测结果与ground truth的giou
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes # 平均giou损失
return losses
def loss_masks(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
assert "pred_masks" in outputs
src_idx = self._get_src_permutation_idx(indices)
tgt_idx = self._get_tgt_permutation_idx(indices)
src_masks = outputs["pred_masks"]
src_masks = src_masks[src_idx]
masks = [t["masks"] for t in targets]
# TODO use valid to mask invalid areas due to padding in loss
target_masks, valid = nested_tensor_from_tensor_list(masks).decompose()
target_masks = target_masks.to(src_masks)
target_masks = target_masks[tgt_idx]
# upsample predictions to the target size
src_masks = interpolate(src_masks[:, None], size=target_masks.shape[-2:],
mode="bilinear", align_corners=False)
src_masks = src_masks[:, 0].flatten(1)
target_masks = target_masks.flatten(1)
target_masks = target_masks.view(src_masks.shape)
losses = {
"loss_mask": sigmoid_focal_loss(src_masks, target_masks, num_boxes),
"loss_dice": dice_loss(src_masks, target_masks, num_boxes),
}
return losses
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
src_idx = torch.cat([src for (src, _) in indices])
return batch_idx, src_idx
def _get_tgt_permutation_idx(self, indices):
# permute targets following indices
batch_idx = torch.cat([torch.full_like(tgt, i) for i, (_, tgt) in enumerate(indices)])
tgt_idx = torch.cat([tgt for (_, tgt) in indices])
return batch_idx, tgt_idx
def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
loss_map = {
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
'masks': self.loss_masks
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
def forward(self, outputs, targets):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
"""
# outputs是detr模型的输出,是一个dict,形式如下:
# {'pred_logits': (bsz, num_queries=100, num_classes),
# 'pred_boxes': (bsz, num_queries=100, 4),
# 'aux_outputs': [{'pred_logits: ......, 'pred_boxes': ......}, {......}, ......]}
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'} # 过滤掉aux_outputs的中间层的输出,只保留最后一层的预测结果
# Retrieve the matching between the outputs of the last layer and the targets
# 将预测结果与ground truth匹配,indices是一个包含多个元组的list,长度与batch_size相等,每一元组表示一张图片的匹配情况
# 每个元素(index_i, index_j),前者是匹配的预测索引,后者是匹配的ground truth索引
# 并且len(index_i) = len(index_j) = min(num_queries, num_target_boxes),index_i和index_j中也是有多个元素的,一对一的关系
indices = self.matcher(outputs_without_aux, targets)
# Compute the average number of target boxes accross all nodes, for normalization purposes
# 计算所有节点上目标框的平均数量,在所有分布式节点之间同步用于标准化
num_boxes = sum(len(t["labels"]) for t in targets) # 一个batch中所有图像中所有的ground truth框的数量之和
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses
losses = {} # 记录各类损失的dict
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes)) # 根据self.losses设置的loss类型获取对应的损失计算函数
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.如果需要,在每个decoder layer后计算损失
# 如果detr输出中包含中间层的输出,则对每一层中间层计算损失,同时更新到losses字典中
if 'aux_outputs' in outputs:
for i, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses
class PostProcess(nn.Module):
""" This module converts the model's output into the format expected by the coco api"""
@torch.no_grad()
def forward(self, outputs, target_sizes):
""" Perform the computation
Parameters:
outputs: raw outputs of the model
target_sizes: tensor of dimension [batch_size x 2] containing the size of each images of the batch
For evaluation, this must be the original image size (before any data augmentation)
For visualization, this should be the image size after data augment, but before padding
"""
out_logits, out_bbox = outputs['pred_logits'], outputs['pred_boxes']
assert len(out_logits) == len(target_sizes)
assert target_sizes.shape[1] == 2
prob = F.softmax(out_logits, -1)
scores, labels = prob[..., :-1].max(-1)
# convert to [x0, y0, x1, y1] format
boxes = box_ops.box_cxcywh_to_xyxy(out_bbox)
# and from relative [0, 1] to absolute [0, height] coordinates
img_h, img_w = target_sizes.unbind(1)
scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
boxes = boxes * scale_fct[:, None, :]
results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
return results
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
def build(args):
# the `num_classes` naming here is somewhat misleading.
# it indeed corresponds to `max_obj_id + 1`, where max_obj_id
# is the maximum id for a class in your dataset. For example,
# COCO has a max_obj_id of 90, so we pass `num_classes` to be 91.
# As another example, for a dataset that has a single class with id 1,
# you should pass `num_classes` to be 2 (max_obj_id + 1).
# For more details on this, check the following discussion
# https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223
num_classes = 20 if args.dataset_file != 'coco' else 91
if args.dataset_file == "coco_panoptic":
# for panoptic, we just add a num_classes that is large enough to hold
# max_obj_id + 1, but the exact value doesn't really matter
num_classes = 250
device = torch.device(args.device)
backbone = build_backbone(args)
transformer = build_transformer(args)
model = DETR(
backbone,
transformer,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
)
if args.masks:
model = DETRsegm(model, freeze_detr=(args.frozen_weights is not None))
matcher = build_matcher(args)
weight_dict = {'loss_ce': 1, 'loss_bbox': args.bbox_loss_coef} # 各种损失的权重
weight_dict['loss_giou'] = args.giou_loss_coef
if args.masks: # 如果由mask参数表示为分割任务,要再计算loss_mask和loss_dice
weight_dict["loss_mask"] = args.mask_loss_coef
weight_dict["loss_dice"] = args.dice_loss_coef
# TODO this is a hack
if args.aux_loss: # 如果aux_loss为True,每个decoder_layer的输出都要计算对应的loss,故也要设置对应的权重
aux_weight_dict = {}
for i in range(args.dec_layers - 1):
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items()}) # 设置各个中间层的权重,就是把上面设置的各个权重重复
weight_dict.update(aux_weight_dict)
# 指定计算loss的类型,其中cardinality是计算预测为前景的数量与grounf truth数量的L1的误差,仅作展示并不是真正的loss,不涉及反向传播
losses = ['labels', 'boxes', 'cardinality']
if args.masks:
losses += ["masks"]
# eos_coef用于计算fenleiloss中前景和背景的相对权重
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict,
eos_coef=args.eos_coef, losses=losses)
criterion.to(device)
postprocessors = {'bbox': PostProcess()}
if args.masks:
postprocessors['segm'] = PostProcessSegm()
if args.dataset_file == "coco_panoptic":
is_thing_map = {i: i <= 90 for i in range(201)}
postprocessors["panoptic"] = PostProcessPanoptic(is_thing_map, threshold=0.85)
return model, criterion, postprocessors
本记录中的代码为官方github提供,而其中的部分注释借鉴于以下链接,其中一些解释也能帮助理解
https://www.jianshu.com/p/1d93cde5581a、https://www.jianshu.com/p/15a7de5eae53