python3实用小工具--商品库存查看工具(附源码)
目录
- 一.分析网页结构
-
- 1.打开主站
- 2.分析网页
- 3.分析数据加载方式
- 4.分析productIds
- 二.撰写代码
- 三.运行结果
- 四.总结
今天看到有网友在我的贴子下留言,说让我帮他分析一个商品网站,判断商品有货或者无货。与其说是一个小工具,倒不如说是一个小爬虫。写下这篇博客,记录下我的分析思路。
一.分析网页结构
1.打开主站
这是一个卖奢侈品的网站,和其他电商网站一样,右侧展示这商品的信息。
有些尺码是没有货的,但是仍然显示有货,如图所示:
此时我切换到了没有货的尺码,但是仍然显示有货。
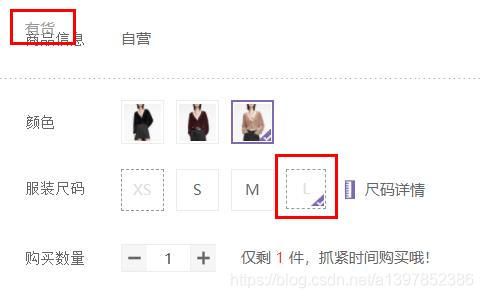
有货的时候,就显示库存数量,没有货的时候,用虚线标出。
2.分析网页
右击查看网页源代码,发现无论是有货还是没货,这里都是有货。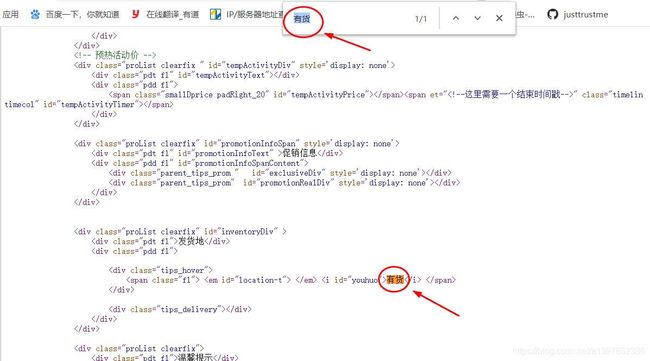
可以初步断定,库存信息数据加载方式为异步加载。
3.分析数据加载方式
此时,回到商品页面,F12打开开发者工具,切换到network刷新网页。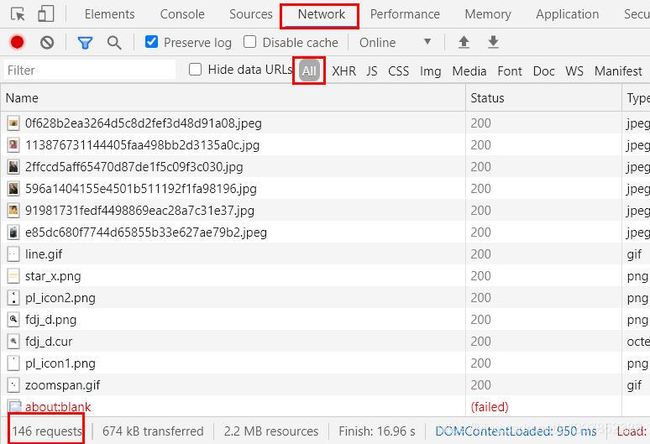
此时会产生很多请求,因为图片等数据中不会存在我们需要的数据,所以直接从XHR(XMLHttpReques)开始筛选,发现没有我们需要的库存数据,再切换到JS(JavaScript),进行手动筛选,发现这个js中存在需要的数据。
其中size为库存数量,跟网页上的数据相匹配,再来看这个js的url所需参数

其中productIds为关键参数,对应着这件商品的四个尺码。这么说我们只要找到productIds即可实现对商品库存的查询。
4.分析productIds
在网页源代码中搜索这串productids,并没有搜索到连续的字符串,遂将四个拆开。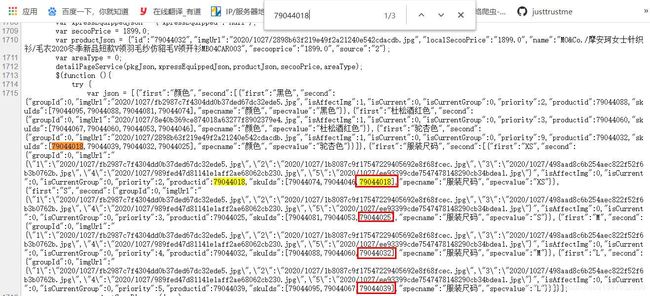
发现productIds为四个列表的最后一个值,分别对应不同尺码的skuid,我们可以获取到四个列表,按索引取值,加以判断。
二.撰写代码
import re
import requests
import json
import random
import time
class Extravgant_Judge(object):
#生成随机ua
def get_ua(self):
first_num = random.randint(55, 62)
third_num = random.randint(0, 3200)
fourth_num = random.randint(0, 140)
os_type = [
'(Windows NT 6.1; WOW64)', '(Windows NT 10.0; WOW64)', '(X11; Linux x86_64)',
'(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version = 'Chrome/{}.0.{}.{}'.format(first_num, third_num, fourth_num)
ua = ' '.join(['Mozilla/5.0', random.choice(os_type), 'AppleWebKit/537.36',
'(KHTML, like Gecko)', chrome_version, 'Safari/537.36']
)
return ua
def get_json_data(self):
base_url='http://item.secoo.com/79044032.shtml?source=list'#要判断库存商品的网址
headers = {
'Connection': 'keep-alive',
'Host': 'item.secoo.com',
'user-agent': self.get_ua()
}
count = 0#此count用于列表索引计数
r=requests.get(base_url,headers=headers)
product_title=re.findall('\s+(.*?)
',r.text)
print(product_title)
json_data=re.findall('var json = (.*);',r.text)
result=''.join(json_data)
_json=json.loads(result)
second= _json[0]
s=second.get('second')
for data in s:
item['color']=data.get('first')#商品颜色
second2 = _json[1]
s2 = second2.get('second')
for data2 in s2:
skus=data2.get('second').get('skuIds')#商品id
item['skuid']=skus[count]
item['size']=data2.get('second').get('specvalue')#尺码/规格
yield item
count += 1
if count == len(s2):
count = 0
#判断库存主函数
def judge(self,product_skuid):
headers={
"Connection": "keep-alive",
"Host":"lr.secooimg.com",
"Referer": "http://item.secoo.com/",
'user-agent': self.get_ua()
}
base_url=f'http://lr.secooimg.com/products?productIds={product_skuid}&fields=productId,status,size'
try:
r=requests.get(base_url,headers=headers)
_json=json.loads(r.text)
size=_json[0].get('size')
if size==0:
item['stock']='无货'
else:
item['stock']=f'库存量为{size}'
print(item)
except:
print('error!请稍后重新获取库存!')
if __name__ == '__main__':
item = {}
judge_product=Extravgant_Judge()
for data in judge_product.get_json_data():
judge_product.judge(data['skuid'])
time.sleep(3)#因为网站对库存判断接口有ip访问频率限制,遂加入延时。
print('程序执行结束')
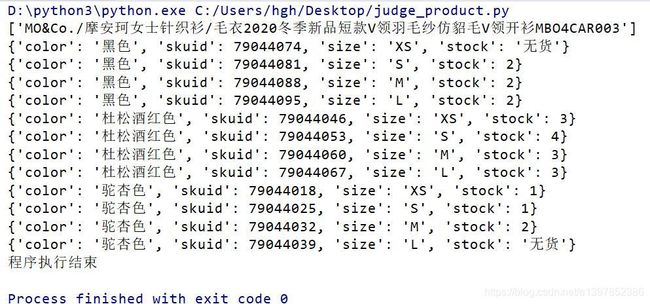
三.运行结果
四.总结
- 本次用python撰写了一个判断商品库存的小工具,此网站大多数数据能在源代码中拿到,但一些数据接口的访问加入了反爬虫,所以加入了延时,笔者认为难点在于如何去分析构造接口地址,最后和那位朋友说个抱歉,虽然问题已经解决,但是没有及时更新博客是我之误。思路、代码方面有什么不足欢迎各位大佬指正、批评!