目标追踪论文之狼吞虎咽(5):基于张量的图嵌入半监督学习及其在判别式目标追踪的应用

一、摘要
作者将一个图像(image patch)看做是一个保留了原始图像结构的二阶张量,然后设计了两个图来描绘目标和背景所在的张量样本中固有的局部几何结构,从而构建一个判别式嵌入空间。图嵌入可以在降低张量维度的同时保留着图的结构。此外,作者提出了两种思路(?)用来寻找原始张量样本到基于张量的图嵌入空间的变换矩阵。为了能够在嵌入空间编码出更多的判别信息,作者提出了基于迁移学习的的半监督策略,用以交替迭代修正嵌入空间,使得其之前获得的判别信息迁移过来。算法应用到目标追踪中能很好地捕获目标的外观特征,通过粒子滤波估计最优目标状态。最后,作者在CVPR2013基准数据库上证明了算法在追踪领域上的高效性。
注:半监督学习的基本思想是利用数据分布上的模型假设建立学习器对未标注样本进行标注。论文中使用从当前帧收集到的很多未标签图像块,来修正判别式嵌入空间。
二、相关工作
图像的向量表示
将图像patch拉伸成为向量,破坏了图像固有的二维结构。
图像的特征表示
尽管提取的特征能够很好用于判别式学习方法中,仍然会有很多有用的信息会被特征所遗漏。
图像的矩阵表示
基于张量的子空间学习可以被用到目标追踪中[11][13][24][25][26],其中一些基于张量的追踪算法[13][24][25]在k模展开矩阵中运用PCA降维,[11][26]在k模展开矩阵上运用协方差矩阵特征值分解。这些算法存在如下局限:
- 子空间学习退化问题;
- 无法完整检测到收集到的图像patch在张量形式下固有的局部几何和判别信息;
- 忽略了背景的影响,当背景和目标相似时会混淆。
注:二维线性判别分析(2DLDA)可以用来检测二阶张量样本的判别结构,然而,还是不能够检测出样本固有的局部集合结构,因为2DLDA没有考虑到同类样本的变化。
用于降维的图嵌入提供了解决上述局限的新框架。
三、文章的贡献
基于张量的图嵌入半监督学习算法框架如下图所示:
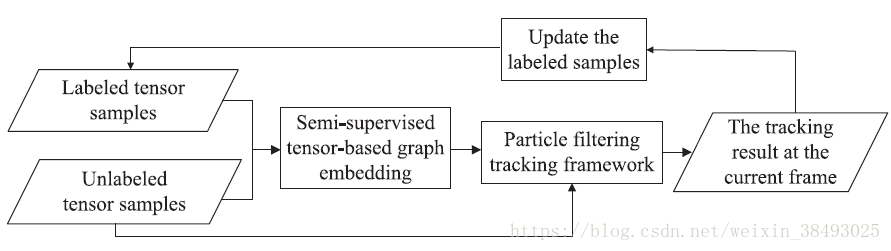
- 首先,将图像patch看做一个二阶张量。在历史帧中收集已标注的目标和背景样本,在当前帧中收集未标注样本;
- 将这些张量样本喂给作者提出的图嵌入半监督学习算法,训练出一个基于张量的图嵌入空间;
- 然后,在粒子滤波的追踪框架内实现目标追踪;
- 最后,将当前帧的追踪结果用来更新已标注的样本集合。
在该算法中,作者设计了:
- 一个固有图用来表示目标张量样本之间、背景张量样本之间的关系;
- 一个惩罚图用来分离目标张量样本和背景张量样本;
- 图嵌入降维框架用来寻找原始张量样本到基于张量的图嵌入空间的变换矩阵。
由于子空间学习退化问题的存在,该嵌入可能不能包含足够的判别信息用于追踪。为了编码出更多判别信息,作者提出,通过用半监督学习的方式,使用未标注的张量样本来修正基于张量的判别式嵌入空间。
在判别式追踪中,已有的基于矩阵的方法通过给目标函数增加约束项来修正判别式空间。这种方法很难直接在基于二阶张量的图嵌入学习(需要两个变换矩阵)中使用,因为很难定义一个合适的正则化器来处理两个相关的变换矩阵。
作者在文章中提出了在交替迭代下基于迁移学习的半监督改进方法。在每次迭代中,在前一个迭代中最可能被误判的未标记张量样本是根据它们与在早期的跟踪阶段收集的标记样本的相似程度而选择的。修正后的类标签被分配给所选的未标记的样本,并用于学习新的判别嵌入空间,在新嵌入空间中关于目标早期形变的判别信息得到迁移。从不同的迭代中学习的嵌入空间被线性组合成终极版嵌入空间。
文章的贡献有以下3点:
- 提出了一个基于二阶张量的图嵌入学习算法,使得张量样本固有的局部几何的和判别结构得到很好的表示;
- 提出了一个基于迁移学习的半监督学习方法,用来修正二阶张量图嵌入空间;
- 将提出的基于二阶张量的半监督图嵌入学习方法整合到贝叶斯推理框架中,构成了一个追踪器。
四、基于张量的图嵌入
4.1 张量操作
张量的内积:

张量的k模展开与矩阵M的积:
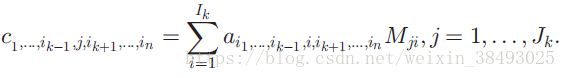 <=> C(k)=MA(k) C ( k ) = M A ( k )
<=> C(k)=MA(k) C ( k ) = M A ( k )
4.2 基于张量的图嵌入
图嵌入算法使用无向有权图来描述数据集的流行结构,在保持图的邻接关系的前提下,寻找图在低维空间中的表示,目前很多流行学习算法都可以统一到这个框架下。
令 {Xi∈RI1×I2×...×In}i=1,2,...,N { X i ∈ R I 1 × I 2 × . . . × I n } i = 1 , 2 , . . . , N 表示N个训练样本集合,每个样本是一个n阶张量。
固有图 G G 和惩罚图 Gp G p 用来描述张量样本的局部几何和判别结构。
令 W、Wp W 、 W p 分别表示 G、Gp G 、 G p 的边权重矩阵,
- Wij W i j 衡量顶点 Xi、Xj X i 、 X j 之间的相似性,固有图描述了样本的期望统计或几何性质(?);
- Wpij W i j p 衡量顶点 Xi、Xj X i 、 X j 之间的差异性,惩罚图描述了被抑制的统计或几何属性(?)。
基于张量的图嵌入的任务是寻找一个最优的低维张量表示固有图中的每个顶点。这样一个低维张量可以很好地描述顶点间的相似性特征,使得原始的固有图的特征被保留下来,同时惩罚图所识别的特征也被抑制了。
令 {Mk∈Rlk×Ik}k=1,2,...,n,lk<Ik { M k ∈ R l k × I k } k = 1 , 2 , . . . , n , l k < I k 表示从样本 {Xi}i=1,2,...,N { X i } i = 1 , 2 , . . . , N 到N个顶点 {Yi∈Rl1×l2×...×ln}i=1,2,...,N { Y i ∈ R l 1 × l 2 × . . . × l n } i = 1 , 2 , . . . , N 的n个变换矩阵集合。换句话说, Yi=Xi×1M1×2M2...×nMn Y i = X i × 1 M 1 × 2 M 2 . . . × n M n 。
【注】: Xi∈RI1×I2×...×In→Yi∈Rl1×l2×...×ln X i ∈ R I 1 × I 2 × . . . × I n → Y i ∈ R l 1 × l 2 × . . . × l n ,都是n阶张量,但是每一阶的维度降低了!
通过求解下面的优化问题可以求出一个能保留着图结构的最优变换矩阵:
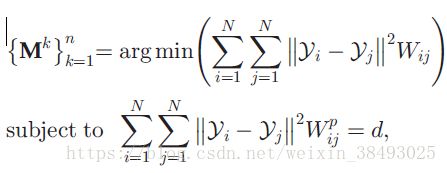
其中,d是常数。注意目标函数里是 Wij W i j ,约束条件里是 Wpij W i j p ,这样一个低维张量 Y Y 可以很好地描述顶点间的相似性特征,使得原始的固有图的特征被保留下来,同时惩罚图所识别的特征也被抑制了。
4.3 基于二阶张量的图嵌入学习
在很多实际应用中,诸如判别式追踪,样本可以用一个二阶张量形式 {Xi∈RI1×I2}i=1,2,...,N { X i ∈ R I 1 × I 2 } i = 1 , 2 , . . . , N 表示,并且样本集包含了已标注训练样本和未标注样本。未标注样本通常会被分类器误判。令“+1”表示标注的正样本,“-1”表示标注的负样本,“+2”表示伪正样本,“-2”表示伪负样本。于是,每个训练样本的类标为 Li∈{−2,−1,+1,+2} L i ∈ { − 2 , − 1 , + 1 , + 2 } ,令 nc(c∈{−2,−1,+1,+2}) n c ( c ∈ { − 2 , − 1 , + 1 , + 2 } ) 表示每一类的样本数,则有 ∑+2c=−2nc=N ∑ c = − 2 + 2 n c = N 。
在图嵌入框架中固有图描述了类内紧密性,惩罚图描述了类间可分性。样本的分布,例如跟踪时的背景样本,是无序的、不规则的和多模式的。注意到,用于定义图形结构的样本之间的全局连接,对于分布广泛的类来说可能不是有效的。因此难以用它来最大化类间散度。相反,用于定义图形结构的样本之间的局部连接更适合保存分散的样本分布(?)。文章设计了两种图,即 G、Gp G 、 G p ,对张量样本的局部几何和判别结构进行建模。
4.3.1 图结构的定义
记 Aij A i j 表示样本i和样本j之间的密切度。
- 当 Li>0,Lj>0 L i > 0 , L j > 0 时,即样本i、样本j是正样本或者伪正样本,
Aij=exp(−||Xi−Xj||2σiσj) A i j = e x p ( − | | X i − X j | | 2 σ i σ j )
其中, σi=||Xi−X(k)j|| σ i = | | X i − X j ( k ) | | , X(k)j X j ( k ) 是 Xi X i 在集合 {Xi}Nj=n−2+n−1+1 { X i } j = n − 2 + n − 1 + 1 N 中的k近邻(?)。 - 当 Li<0,Lj<0 L i < 0 , L j < 0 时,即样本i、样本j是负样本或者伪负样本,
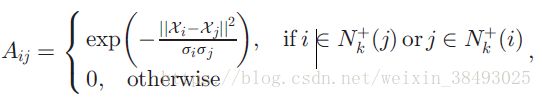
其中, N+k(i) N k + ( i ) 是 Xi X i 在集合 {Xi}n−2+n−1+1j=1 { X i } j = 1 n − 2 + n − 1 + 1 中的k近邻的下标集合。
σi=||Xi−X(k)j|| σ i = | | X i − X j ( k ) | | , X(k)j X j ( k ) 是 Xi X i 在集合 {Xi}n−2+n−1+1j=1 { X i } j = 1 n − 2 + n − 1 + 1 中的k近邻。
有了样本间密切度 Aij A i j 的定义,张量样本的局部空间关系则可以被包含在图结构中。
固有图 G G 的边权重如下定义:
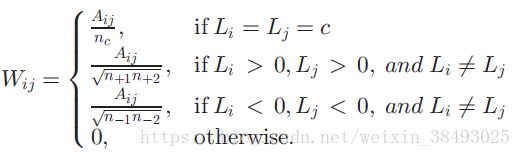
- 当 LiLj>0 L i L j > 0 时, Wij W i j 与 Aij A i j 成正比。
- 当 LiLj<0 L i L j < 0 时,他们之间不存在连接,所以权重为0。
惩罚图 Gp G p 的边权重如下定义:
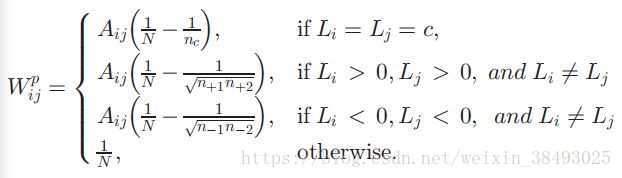
- 当 LiLj>0 L i L j > 0 时, Wij W i j 为负数。
- 当 LiLj<0 L i L j < 0 时, Wij W i j 为正数。
由于惩罚图是用来将目标从背景中分离出来,所以作者赋予不同类标的两个样本间一个正的权重,从而增加目标样本和背景样本的可分性;赋予同一类标的两个样本间一个负的权重,增加它们的不可分性。
4.3.2 解决方案
4.2节中, Yi=Xi×1M1×2M2...×nMn Y i = X i × 1 M 1 × 2 M 2 . . . × n M n ;当n=2时, Yi=Xi×1M1×2M2=UTXiV Y i = X i × 1 M 1 × 2 M 2 = U T X i V (详见下面推导),
即4.2节的优化问题在二阶张量下可以写为:

4.3.3 算法
交替迭代求解U、V

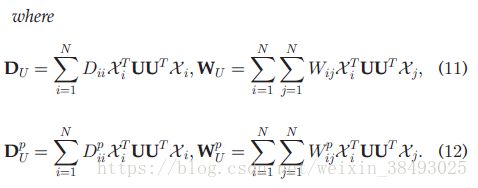
正负样本的权值中心点定义为:

最后,分类器的分类结果如下:
h(X)=sign(f(X)) h ( X ) = s i g n ( f ( X ) )
![]()
五、基于迁移学习的半监督改进方法
作者构建了一种半监督的方法,利用未标注的数据来修正学习的判别嵌入空间。
- 与其他判别追踪器一样,标记与追踪结果对应的图像patch为正样本,其他为负样本。
- 然后,在上述第4节中所描述的监督方法中,使用这些标记为正或负的样本来学习判别嵌入空间。
- 进一步,选择一些有用的未标记的样本,以半监督的方式修正嵌入空间。
作者引入迁移学习到半监督学习中。在跟踪应用程序中,
- 如果样本集经常更新,那么就可以对形变反应更快。然而在更新中,如果目标一直在发生大规模形变,就会出现跟踪漂移问题,跟踪器稳定性下降。
- 如果样本集缓慢更新,跟踪器就不会轻易受到错误追踪的影响,并且对漂移问题会更加鲁棒,但是它的适应性降低了。
为了保持跟踪的适应性和稳定性,作者构建了两个样本集:
- 一个是“目标集”,目标集中的样本称为目标数据,它只包含从最近几帧中收集的目标和背景样本。目标集更新速度很快,以确保它能够适应形变。
- 一个是“辅助集”,辅助集中的样本称为源数据,它由在早期跟踪阶段收集的样本组成。 辅助集更新速度很慢,以确保跟踪的稳定性和以及对漂移问题的鲁棒性。
环境变化会引起样本分布发生变化。所以,源数据的分布可能与目标数据的分布有很大的不同。如何将源域中的信息迁移到目标域中呢?
- 首先,我们只使用目标集中的样本来学习初始的图嵌入张量空间,它保留了最近几帧中目标形变的判别信息。
- 然后,使用辅助集选择未标记的样本,这些样本很可能被当前已学习的图嵌入空间错误地分类。它们的标签是根据它们与辅助集的样本的相似度确定的。
- 最后,使用上一步所选的样本交替迭代地修正图嵌入张量子空间。
通过这种方式,关于目标在早期形变的判别信息被迁移到图嵌入空间中。这种基于迁移学习的半监督改进方法使得模型对跟踪漂移问题更加鲁棒。
通过这种方式,相似性高的样本通常就会有相同的类标。
- 作者之所以不使用投影张量差来测量张量样本之间的相似性。这是因为在迭代的半监督的改进过程中最初的投影矩阵不够精确,无法将张量样本投影到一个低维度空间中。
- 作者之所以不使用类似 Aij A i j 的基于两阶张量距离的相似性度量,这是因为与图嵌入学习过程相比较,在这个过程中,只需要计算最近样本之间的距离。考虑到追踪近期的环境和早期的环境可能很不一样,一个简单的基于二阶张量距离的相似性度量不够有效测量目标集和辅助集中的样品距离。
- 于是,作者提出了一个更精确的基于分块的协方差矩阵描述符来测量这些样本之间的相似性。在描述符中,样本图像块中像素之间的局部关系被建模。将图像块分割成非重叠块可以将更多的局部空间信息合并到相似度度量中。协方差距离的局部信息可以补充基于张量的图嵌入的整体特性。
本节,首先描述了基于分块的相似性估计,然后是基于迁移学习的半监督改进方法。
5.1 基于分块的相似性估计
在每一个样本图像patch中,记每个像素的特征向量为:
其中,(x,y)是像素坐标, ϕ ϕ 是该像素的亮度, ϕx、ϕy ϕ x 、 ϕ y 是亮度的一阶导数。
作者将每个图像patch划分为mxn块block,对于块(p,q)可以用一个协方差矩阵表示如下:
其中, Ω Ω 是块(p,q)中的像素个数, μ μ 是特征向量 {fk}k=1,2,...,Ω { f k } k = 1 , 2 , . . . , Ω 的均值。
给定对称正定矩阵 Cpq C p q ,对矩阵进行奇异值分解(SVD)并且对数化,得
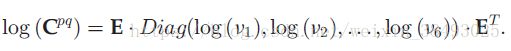
其中,E是正交矩阵, {vi}i=1,2,...,6 { v i } i = 1 , 2 , . . . , 6 是矩阵 Cpq C p q 的特征值。
由于 log(Cpq) l o g ( C p q ) 的向量空间结构,它可以展开成一个向量 opq o p q 。并且由于它是一个对称矩阵, opq o p q 只需要存储 log(Cpq) l o g ( C p q ) 的上三角矩阵即可。 log(Cpq) l o g ( C p q ) 中对角线外的元素都乘以 2–√ 2 ,以确保任意两个对称矩阵的距离等于对应的展开向量间的距离。
则第i个patch的块(p,q)和第j个patch的块(p,q)之间的相似度的计算公式为:

考虑到靠近图像patch中心的块信息量更大,而边界上的块则容易受到图像patch外部的影响。因此,作者使用空间全局高斯滤波来衡量每一块的权重。

有了不同patch块间相似度的定义以及每一块的权重,则样本 Xi X i 和样本 Xj X j 之间的相似度可以定义为:
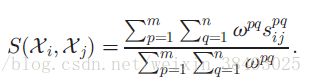
5.2 基于迁移学习的半监督改进方法
记以下三个数据集的定义:
- {(Xi,Li)}NAi=1 { ( X i , L i ) } i = 1 N A 是张量样本的辅助集, NA N A 是辅助集样本数, Li∈{−1,+1} L i ∈ { − 1 , + 1 } 是对于样本的类标
- {(Xi,Li)}NA+NTi=NA+1 { ( X i , L i ) } i = N A + 1 N A + N T 是张量样本的目标集, NT N T 是目标集样本数
- {(Xj)}NUj=1 { ( X j ) } j = 1 N U 是未标注样本集, NU N U 是未标注样本数
张量分类器 H(X):RI1×I2→R H ( X ) : R I 1 × I 2 → R 是由前 T^ T ^ 次迭代的张量分类器线性组合而成的:
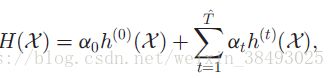
其中,
- h0(X):RI1×I2→{−1,+1} h 0 ( X ) : R I 1 × I 2 → { − 1 , + 1 } 是只用目标集中的已标注数据通过上文4.3.3的基于张量的图嵌入学习算法训练得到的张量分类器;
- ht(X):RI1×I2→{−1,+1} h t ( X ) : R I 1 × I 2 → { − 1 , + 1 } 是在第t次迭代中结合目标集中的已标注数据和错误标注的数通过基于张量的图嵌入学习算法训练得到的张量分类器;
在每一次迭代中,如何求解 h(t)(X)、αt h ( t ) ( X ) 、 α t 呢?在第 T^+1 T ^ + 1
次迭代中,优化问题如下:

其中,
- 目标函数的第一项是衡量未标注样本和辅助集中已标注样本之间的不一致性;
- 目标函数的第二项是衡量未标注样本之间的不一致性;
- η η 是连接权重,取值为 NANU N A N U
- 第一项和第二项其实形式很相似,目标函数可以改写为如下形式:

- 参考文献[16]提出,只有当max |Pj−Qj| | P j − Q j | 对应的未标注样本的分类预测结果为 h(Xj)=sign(Pj−Qj) h ( X j ) = s i g n ( P j − Q j ) 时F取得最小值。
- 对F求导,可得 α α :

基于迁移学习的半监督改进算法流程

这里解释一下step5为什么要寻找max |Pj−Qj| | P j − Q j | 对应的样本。
如果一个未标注的样本 Xj X j 和辅助集中的一个正样本高度相似,但是却被当前的图嵌入张量分类器错误预测为负样本,那么这个未标注样本对应的 Pj P j 会很大, Qj Q j 会很小。将这个样本选择出来,赋予类标为 2∗sign(Pj−Qj) 2 ∗ s i g n ( P j − Q j ) 。
并且,选择 |Pj−Qj| | P j − Q j | 的前几个较大值用来改进最终分类器 H(X) H ( X ) 。这些被选择的未标记的样本可以帮助基于张量的图嵌入空间在早期对判别信息进行编码,以补偿丢失的判别信息。
5.3 视觉追踪
作者将上述基于迁移学习的半监督基于张量的图嵌入学习算法应用到目标追踪中。算法流程如下:



追踪器的在线更新主要是更新目标集和辅助集的样本。
- 当前帧的前几帧的追踪结果作为目标集的正样本,这些样本的方差主要来自于目标不断的形变。负样本则从目标周边区域用密集采样的方法进行提取。
- 辅助集中已标注的样本则是从早期的视频帧中提取,文中是每隔几帧就提取一个正样本和几个负样本
用一个仿射参数向量 η η 表示目标的状态。在粒子滤波中,用高斯分布 G(ηt−1,∑) G ( η t − 1 , ∑ ) 来模拟与动态模型相对应的状态迁移分布。高斯分布的均值 ηt−1 η t − 1 是从前t-1帧中估计得到的,协方差矩阵 ∑ ∑ 则是经验值。当前帧t中的粒子是从状态迁移分布中抽取出来的,对应 H(X) H ( X ) ,在粒子滤波中每个粒子的权重定义如下,并且通过极大似然估计(MAP)计算当前帧的追踪结果:
