卷积神经网络(CNN)原理详解
这几年深度学习快速发展,在图像识别、语音识别、物体识别等各种场景上取得了巨大的成功,例如AlphaGo击败世界围棋冠军,iPhone X内置了人脸识别解锁功能等等,很多AI产品在世界上引起了很大的轰动。在这场深度学习革命中,卷积神经网络(Convolutional Neural Networks,简称CNN)是推动这一切爆发的主力,在目前人工智能的发展中有着非常重要的地位。
【问题来了】那什么是卷积神经网络(CNN)呢?
1、什么是神经网络?
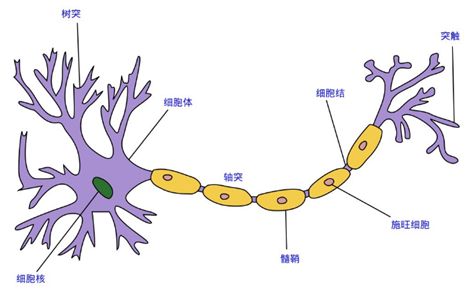
这里的神经网络,也指人工神经网络(Artificial Neural Networks,简称ANNs),是一种模仿生物神经网络行为特征的算法数学模型,由神经元、节点与节点之间的连接(突触)所构成,如下图:
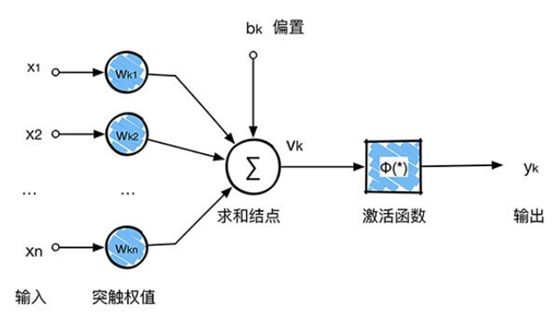
每个神经网络单元抽象出来的数学模型如下,也叫感知器,它接收多个输入(x1,x2,x3...),产生一个输出,这就好比是神经末梢感受各种外部环境的变化(外部刺激),然后产生电信号,以便于转导到神经细胞(又叫神经元)。

单个的感知器就构成了一个简单的模型,但在现实世界中,实际的决策模型则要复杂得多,往往是由多个感知器组成的多层网络,如下图所示,这也是经典的神经网络模型,由输入层、隐含层、输出层构成。
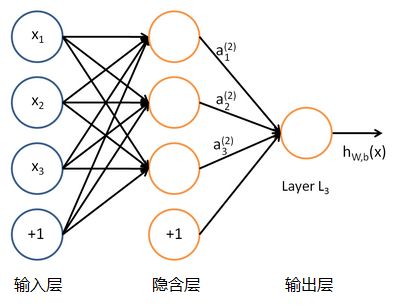
人工神经网络可以映射任意复杂的非线性关系,具有很强的鲁棒性、记忆能力、自学习等能力,在分类、预测、模式识别等方面有着广泛的应用。
2、什么是卷积神经网络?
卷积神经网络在图像识别中大放异彩,达到了前所未有的准确度,有着广泛的应用。接下来将以图像识别为例子,来介绍卷积神经网络的原理。
(1)、案例
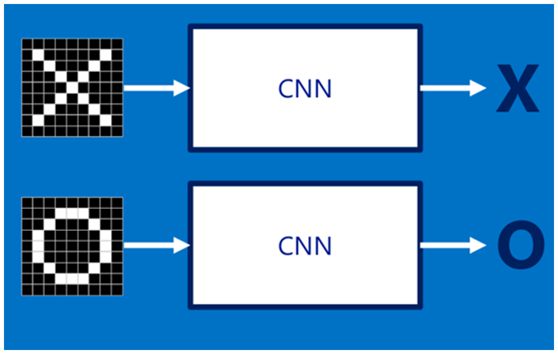
假设给定一张图(可能是字母X或者字母O),通过CNN即可识别出是X还是O,如下图所示,那怎么做到的呢
(2)、图像输入
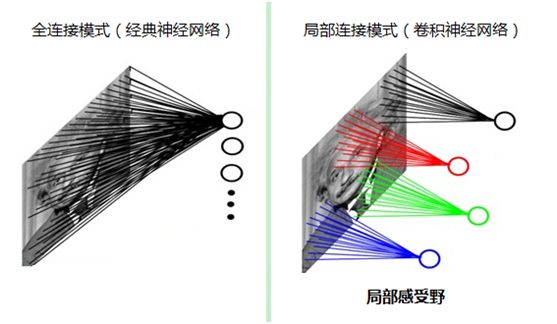
如果采用经典的神经网络模型,则需要读取整幅图像作为神经网络模型的输入(即全连接的方式),当图像的尺寸越大时,其连接的参数将变得很多,从而导致计算量非常大。
而我们人类对外界的认知一般是从局部到全局,先对局部有感知的认识,再逐步对全体有认知,这是人类的认识模式。在图像中的空间联系也是类似,局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种模式就是卷积神经网络中降低参数数目的重要神器:局部感受野。
(3)、提取特征
如果字母X、字母O是固定不变的,那么最简单的方式就是图像之间的像素一一比对就行,但在现实生活中,字体都有着各个形态上的变化(例如手写文字识别),例如平移、缩放、旋转、微变形等等,如下图所示:
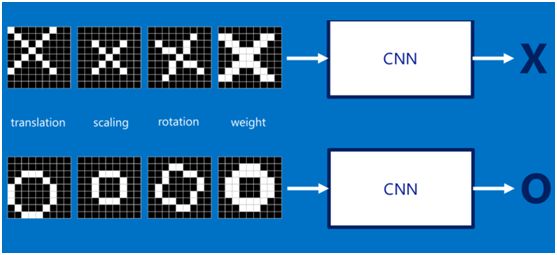
我们的目标是对于各种形态变化的X和O,都能通过CNN准确地识别出来,这就涉及到应该如何有效地提取特征,作为识别的关键因子。
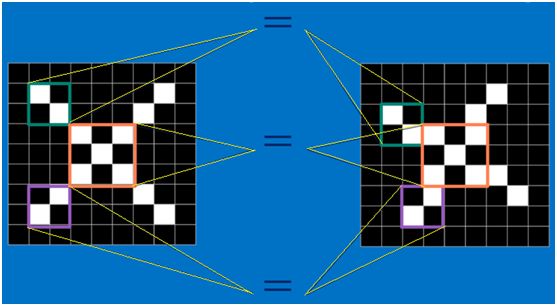
回想前面讲到的“局部感受野”模式,对于CNN来说,它是一小块一小块地来进行比对,在两幅图像中大致相同的位置找到一些粗糙的特征(小块图像)进行匹配,相比起传统的整幅图逐一比对的方式,CNN的这种小块匹配方式能够更好的比较两幅图像之间的相似性。如下图:
以字母X为例,可以提取出三个重要特征(两个交叉线、一个对角线),如下图所示:
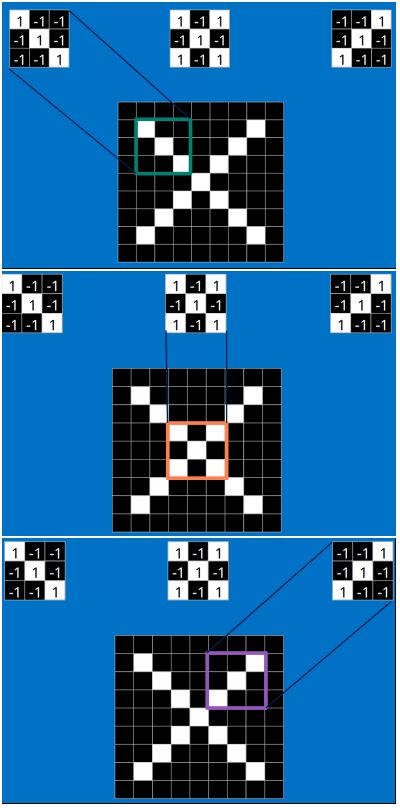
假如以像素值"1"代表白色,像素值"-1"代表黑色,则字母X的三个重要特征如下:

那么这些特征又是怎么进行匹配计算呢?(不要跟我说是像素进行一一匹配的,汗!)
(4)、卷积(Convolution)
这时就要请出今天的重要嘉宾:卷积。那什么是卷积呢,不急,下面慢慢道来。
当给定一张新图时,CNN并不能准确地知道这些特征到底要匹配原图的哪些部分,所以它会在原图中把每一个可能的位置都进行尝试,相当于把这个feature(特征)变成了一个过滤器。这个用来匹配的过程就被称为卷积操作,这也是卷积神经网络名字的由来。
卷积的操作如下图所示:
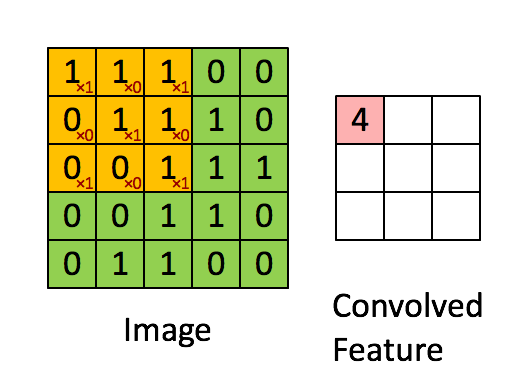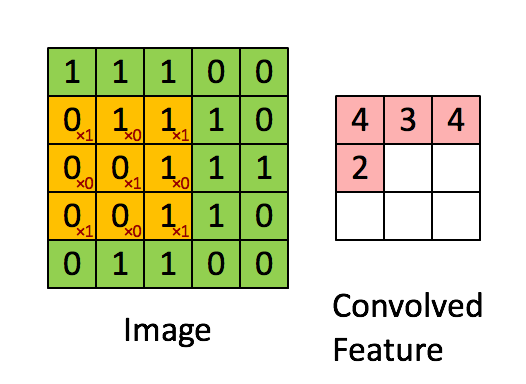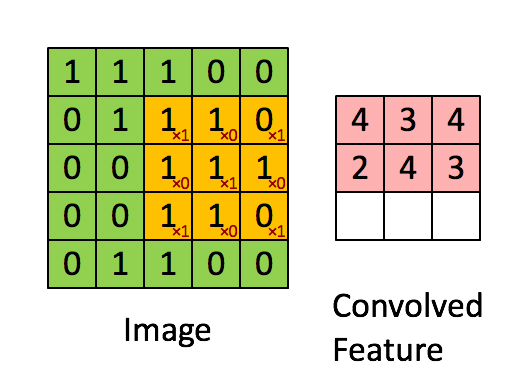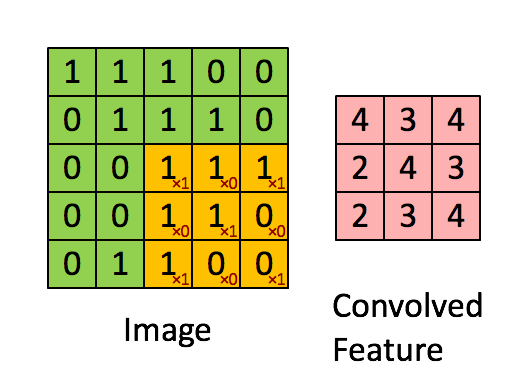
是不是很像把毛巾沿着对角卷起来,下图形象地说明了为什么叫「卷」积

在本案例中,要计算一个feature(特征)和其在原图上对应的某一小块的结果,只需将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可(注:也可不除以总个数的)。
如果两个像素点都是白色(值均为1),那么1*1 = 1,如果均为黑色,那么(-1)*(-1) = 1,也就是说,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。具体过程如下(第一个、第二个……、最后一个像素的匹配结果):
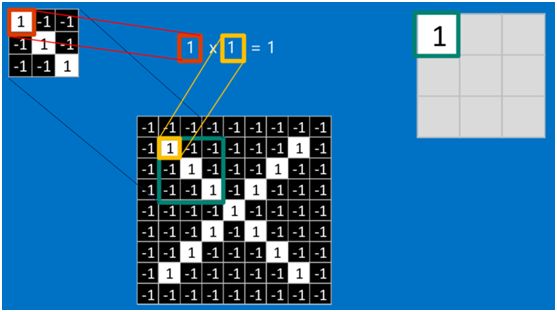
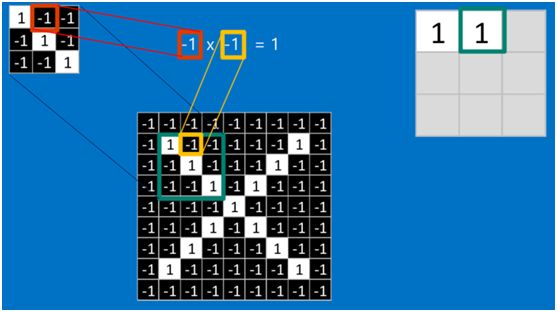
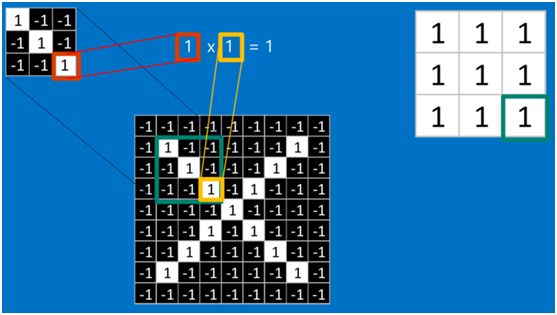
根据卷积的计算方式,第一块特征匹配后的卷积计算如下,结果为1

对于其它位置的匹配,也是类似(例如中间部分的匹配)
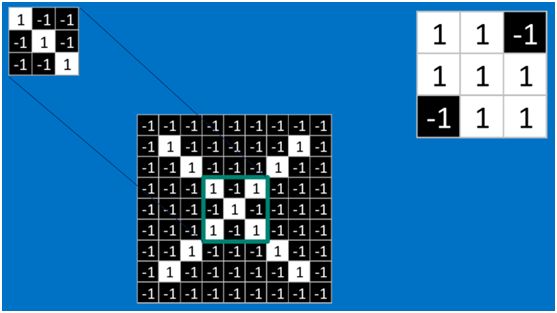
计算之后的卷积如下
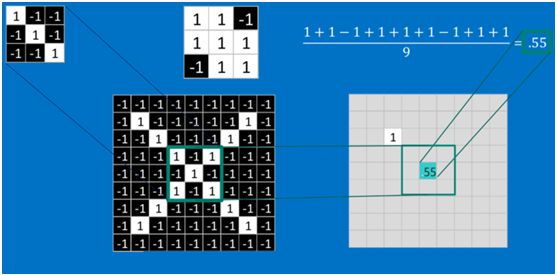
以此类推,对三个特征图像不断地重复着上述过程,通过每一个feature(特征)的卷积操作,会得到一个新的二维数组,称之为feature map。其中的值,越接近1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。如下图所示:

可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得计算量变得相当庞大。
(5)、池化(Pooling)
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
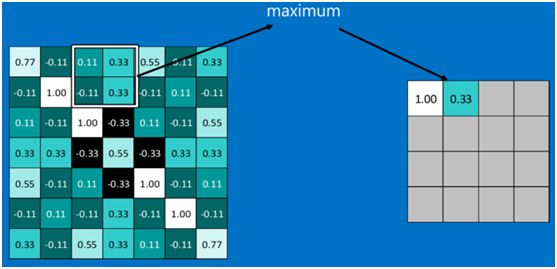
下图显示了左上角2*2池化区域的max-pooling结果,取该区域的最大 max(0.77,-0.11,-0.11,1.00) ,作为池化后的结果,如下图:

池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图:
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下:
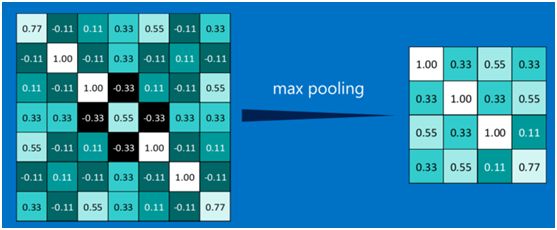
对所有的feature map执行同样的操作,结果如下:

最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
(6)、激活函数ReLU (Rectified Linear Units)
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
回顾一下前面讲的感知机,感知机在接收到各个输入,然后进行求和,再经过激活函数后输出。激活函数的作用是用来加入非线性因素,把卷积层输出结果做非线性映射。
在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。
下面看一下本案例的ReLU激活函数操作过程:
第一个值,取max(0,0.77),结果为0.77,如下图
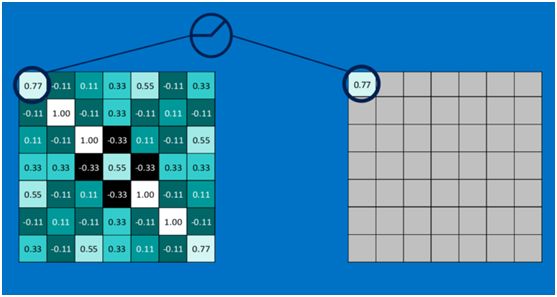
第二个值,取max(0,-0.11),结果为0,如下图

以此类推,经过ReLU激活函数后,结果如下:
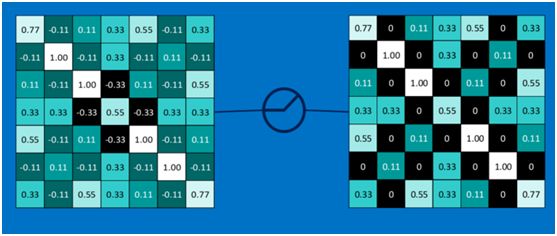
对所有的feature map执行ReLU激活函数操作,结果如下:

(7)、深度神经网络
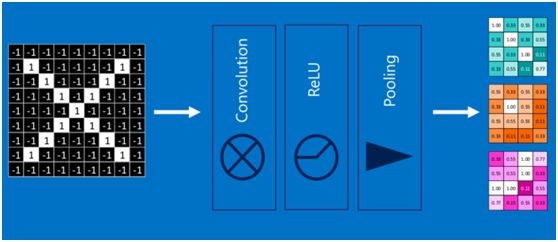
通过将上面所提到的卷积、激活函数、池化组合在一起,就变成下图:
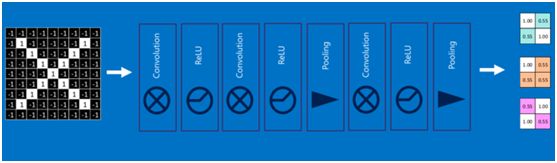
通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图:
(8)、全连接层(Fully connected layers)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示:
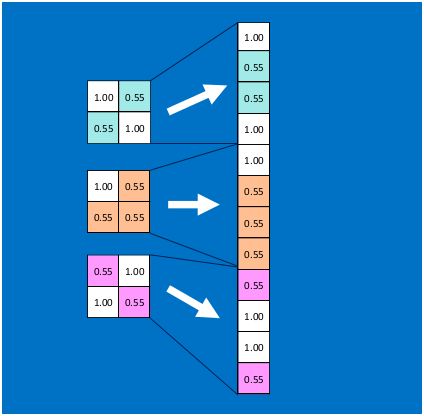
由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)

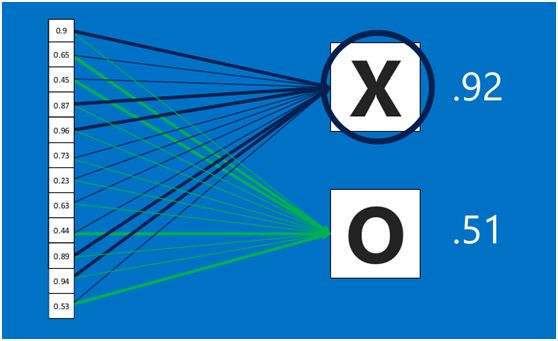
在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)
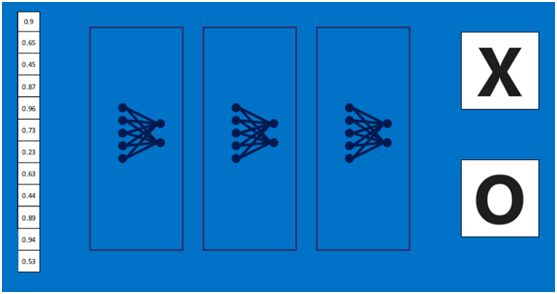
上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:
(9)、卷积神经网络(Convolutional Neural Networks)
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:

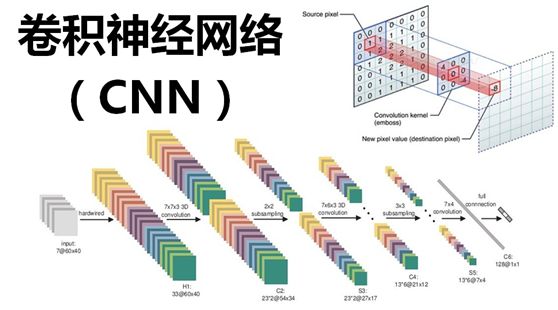
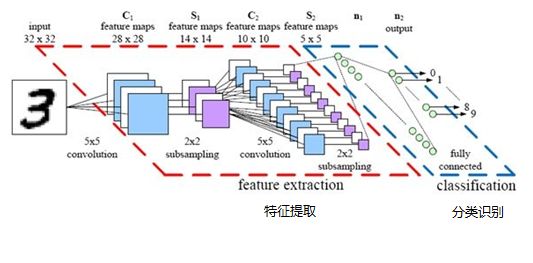
最后,再回顾总结一下,卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层),下图便是著名的手写文字识别卷积神经网络结构图:
参考文献:
大话卷积神经网络(CNN) - 雪饼的个人空间 - OSCHINA - 中文开源技术交流社区