warm up预热学习率调整策略学习记录
warm up lr scheduler
1. 使用原理
预热学习率调整策略就是在模型训练初期,将学习率调低,随着训练 epoch 的增加,lr 逐渐增大,等 lr 上升到预先设定的学习率时,再接着使用其他学习率调整策略 (如,StepLR、MultiStepLR、CosineAnnealingLR 等) 对学习率进行调整。
2. 使用优势
模型刚开始训练时,由于它的权重是随机初始化的,如果选择一个较大的学习率,可能会使损失严重震荡,但如果选择预热学习率的调整策略,就可以使得刚模型在开始训练的几个 epoch 内学习率较小,等模型相对稳定后再选择预先设定的学习率进行训练,使得模型收敛速度变得更快,效果也更好。
3. 代码实例
代码链接:https://github.com/ildoonet/pytorch-gradual-warmup-lr
参数
optimizer:损失函数优化器,如:SGD、Adam等
multiplier:tar_lr = base_lr * multiplier,base_lr 是在实例化优化器时定义的,如:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1),0.1 就是 base_lr
total_epoch:到达 tar_lr 需要的 epoch 数
after_scheduler:到达 tar_lr 之后的学习率调整策略,即预热结束后的学习率调整策略
预热学习率调整策略定义如下:
from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
class GradualWarmupScheduler(_LRScheduler):
""" Gradually warm-up(increasing) learning rate in optimizer.
Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'.
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier if multiplier > 1.0. if multiplier = 1.0, lr starts from 0 and ends up with the base_lr.
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier < 1.:
raise ValueError('multiplier should be greater thant or equal to 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super(GradualWarmupScheduler, self).__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler:
if not self.finished:
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
return self.after_scheduler.get_last_lr()
return [base_lr * self.multiplier for base_lr in self.base_lrs]
if self.multiplier == 1.0:
return [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs]
else:
return [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
def step_ReduceLROnPlateau(self, metrics, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning
if self.last_epoch <= self.total_epoch:
warmup_lr = [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
for param_group, lr in zip(self.optimizer.param_groups, warmup_lr):
param_group['lr'] = lr
else:
if epoch is None:
self.after_scheduler.step(metrics, None)
else:
self.after_scheduler.step(metrics, epoch - self.total_epoch)
def step(self, epoch=None, metrics=None):
if type(self.after_scheduler) != ReduceLROnPlateau:
if self.finished and self.after_scheduler:
if epoch is None:
self.after_scheduler.step(None)
else:
self.after_scheduler.step(epoch - self.total_epoch)
self._last_lr = self.after_scheduler.get_last_lr()
else:
return super(GradualWarmupScheduler, self).step(epoch)
else:
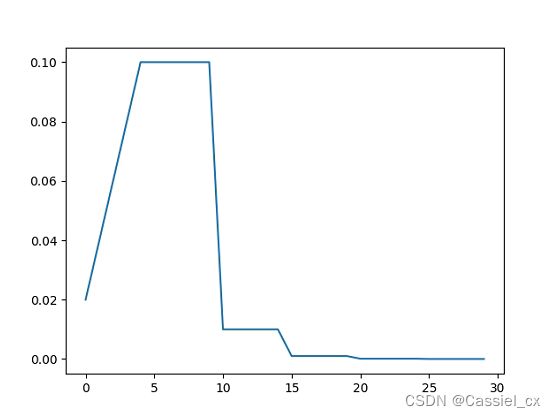
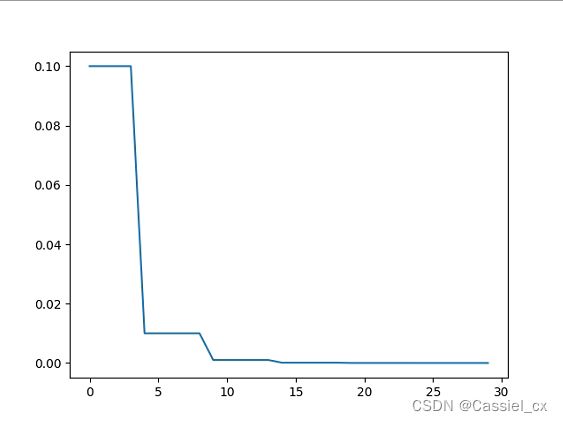
self.step_ReduceLROnPlateau(metrics, epoch)预热学习率调整策略的使用示例如下:
import torch
from torch.optim.lr_scheduler import *
import torch.nn as nn
from torchvision.models import resnet50
import matplotlib.pyplot as plt
from lr_scheduler.scheduler import GradualWarmupScheduler
model = resnet50(False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.2)
scheduler1 = LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.95 ** epoch)
scheduler2 = StepLR(optimizer, step_size=10, gamma=0.1)
scheduler3 = MultiStepLR(optimizer, milestones=[5,10,15,20,25], gamma=0.1)
scheduler4 = ExponentialLR(optimizer, gamma=0.8)
scheduler5 = CosineAnnealingLR(optimizer,T_max=5,eta_min=0.05)
scheduler6 = CyclicLR(optimizer, base_lr=0.01, max_lr=0.2, step_size_up=10, step_size_down=5)
scheduler7 = CosineAnnealingWarmRestarts(optimizer, T_0=5, T_mult=2, eta_min=0.01)
scheduler8 = GradualWarmupScheduler(optimizer, 1, 5, scheduler2)
plt.figure()
max_epoch = 30
cur_lr_list = []
for epoch in range(max_epoch):
optimizer.step()
scheduler8.step()
cur_lr = optimizer.param_groups[-1]['lr']
cur_lr_list.append(cur_lr)
print('Current lr:', cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
plt.savefig('D:/lr_scheduler_learning/gradualwarmupscheduler.png')w/o warm up
w/ warm up