利用神经网络最简单的多层感知机MLP模型在著名手写测试机Mnist上完成一次标准的深度学习流程
记东北大学理学院大三暑期实训(第三天):神经网络
数据集的导入
import numpy as np
import pandas as pd
from keras.utils import np_utils
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
from keras.datasets import mnist
(train_image,train_label),(test_image,test_label) = mnist.load_data()
# 如果网站下载太慢,就手动下载然后把文件放在C:\Users\****\.keras\datasets下加载即可
print('train data = ',len(train_image))
print('test data = ',len(test_image))
plt.imshow(train_image[0],cmap='gray')
'''
train data = 60000
test data = 10000
'''
数据集的预处理
#即每一张图片的每一点像素值作为一个特征
train_image_matric = train_image.reshape(60000,784).astype('float')
test_image_matric = test_image.reshape(10000,784).astype('float')
print(train_image_matric.shape)
print(test_image_matric.shape)
##归一化处理:去除单位的影响 去除量纲的影响 加权的前提是标准化
'''
(60000, 784)
(10000, 784)
'''
train_image_normalize = train_image_matric / 255
test_image_normalize = test_image_matric / 255
#一位有效编码来对标签进行处理 即独热编码
train_label_onehotencoding = np_utils.to_categorical(train_label)
test_label_onehotencoding = np_utils.to_categorical(test_label)
建立MLP多层感知机模型:最简单的神经网络
from keras.models import Sequential
from keras.layers import Dense
model =Sequential()
# Dense units:256隐藏层中的神经单元个数 input_dim 输入层神经单元个数 normal:正态分布产生权重和偏差
model.add(Dense(units = 256, input_dim =784 , kernel_initializer = 'normal',activation = 'relu'))
# softmax 给出具体预测的概率
model.add(Dense(units = 10, kernel_initializer = 'normal',activation = 'softmax'))
# 每一层神经单元的个数:上一层神经单元个数*本层神经单元个数+本岑神经单元个数
# 总计神经单元个数 = 各层之和
print(model.summary())
进行训练
# 配置训练模型
# 交叉熵在分类问题中常用 adam:进行优化使得预测更跨
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics = ['accuracy'])
# 从数据集中保留一部分用于验证数据 epochs:训练次数 batch_si波色1verbose =2表示显示训练过程
train_history = model.fit(train_image_normlize,train_label_onehotencoding,validation_split = 0.2,epochs = 10,batch_size = 200,verbose = 2)
训练结果
print(train_history.history['acc'])
print('-----------------------------------------------------------')
print(train_history.history['val_acc'])
print('-----------------------------------------------------------')
print(train_history.history['loss'])
print('-----------------------------------------------------------')
print(train_history.history['val_loss'])
'''
输出结果:
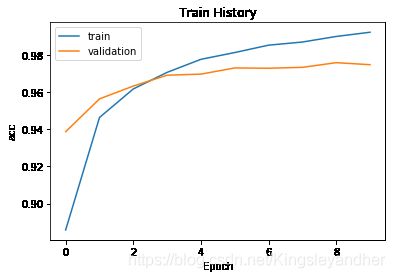
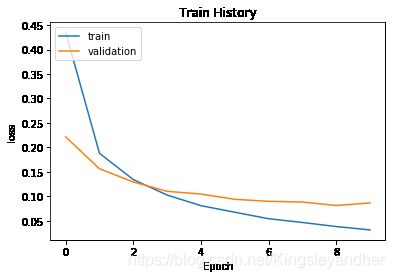
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
1s - loss: 0.4354 - acc: 0.8858 - val_loss: 0.2214 - val_acc: 0.9388
Epoch 2/10
1s - loss: 0.1878 - acc: 0.9464 - val_loss: 0.1562 - val_acc: 0.9564
Epoch 3/10
1s - loss: 0.1341 - acc: 0.9618 - val_loss: 0.1291 - val_acc: 0.9633
Epoch 4/10
1s - loss: 0.1025 - acc: 0.9707 - val_loss: 0.1101 - val_acc: 0.9692
Epoch 5/10
1s - loss: 0.0807 - acc: 0.9777 - val_loss: 0.1044 - val_acc: 0.9698
Epoch 6/10
1s - loss: 0.0673 - acc: 0.9814 - val_loss: 0.0937 - val_acc: 0.9731
Epoch 7/10
1s - loss: 0.0540 - acc: 0.9854 - val_loss: 0.0896 - val_acc: 0.9729
Epoch 8/10
1s - loss: 0.0464 - acc: 0.9870 - val_loss: 0.0881 - val_acc: 0.9734
Epoch 9/10
1s - loss: 0.0380 - acc: 0.9900 - val_loss: 0.0812 - val_acc: 0.9759
Epoch 10/10
1s - loss: 0.0311 - acc: 0.9923 - val_loss: 0.0861 - val_acc: 0.9748
'''
import matplotlib.pyplot as plt
def show_train_history(train_history , train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
show_train_history(train_history, 'acc', 'val_acc')
show_train_history(train_history, 'loss', 'val_loss')
利用10000项测试数据评估模型的准确率
scores = model.evaluate(test_image_normalize, test_label_onehotencoding)
print(scores)
# 输出 :9472/10000 [===========================>..] - ETA: 0s[0.07739098612801172, 0.9765]
预测图片
from PIL import Image
img = Image.open('2.bmp')
number_data = img.getdata()
number_data_matrix = np.matrix(number_data)
number_data_matrix = number_data_matrix.reshape(1,784).astype(float)
number_data_normalize = number_data_matrix / 255 #number_data_matrix就是最终带入到模型里面进行预测数据
#model.predict
prediction = model.predict(number_data_normalize)
print(prediction)
print(np.max(prediction))
print(np.argmax(prediction))
'''
[[2.0111328e-11 3.8465593e-08 6.9462473e-08 3.0676241e-05 8.6265492e-05
6.1589433e-04 5.9524172e-09 6.2778452e-07 3.1040592e-05 9.9923539e-01]]
0.9992354
9
'''
导出训练完毕的模型
model.save('Number_Predict.h5')
后记:这是一个关于神经网络最为简单的数据集和模型,在增加隐藏层的神经单元至1000后,模型的复杂度提升也使得训练集和验证集准确率提升了,但是提升强度不到1%,代价就是模型的过拟合现象愈发严重,在测试集上甚至效果更差。因此若想要继续增加模型的效果,需要增加Dropout功能。
# 在原模型中加入Dropout层
from keras.layers import Droupt
model.add(Dropout(0.5))
# 增加D层后测试集的准确率上升至98%