目标检测的Tricks | 【Trick5】学习率调优方法——warmup
如有错误,恳请指出。
文章目录
- 1. warmup理论概要
- 2. warmup实现代码
1. warmup理论概要
warmup定义:
在模型训练之初选用较小的学习率,训练一段时间之后(如:10epoches或10000steps)使用预设的学习率进行训练。
warmup作用:
- 因为模型的weights是随机初始化的,可以理解为训练之初模型对数据的“理解程度”为0(即:没有任何先验知识),在第一个epoches中,每个batch的数据对模型来说都是新的,模型会根据输入的数据进行快速调参,此时如果采用较大的学习率的话,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”;
- 当模型训练一段时间之后(如:10epoches或10000steps),模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛;
- 当模型使用较大的学习率训练一段时间之后,模型的分布相对比较稳定,此时不宜从数据中再学到新特点,如果仍使用较大的学习率会破坏模型的稳定性,而使用小学习率更容易获取local optima。
warmup类型:
-
Constant Warmup
学习率从非常小的数值线性增加到预设值之后保持不变,其学习率的系数如下图所示:
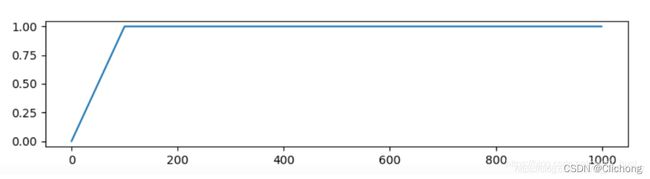
-
Linner Warmup
学习率从非常小的数值线性增加到预设值之后,然后再线性减小。其学习率的系数如下图所示:
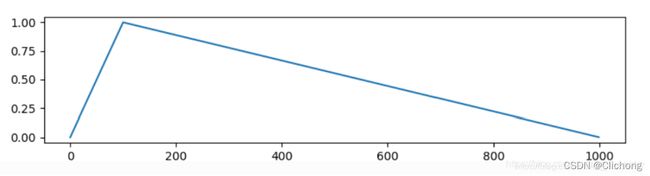
-
Cosine Warmup
学习率先从很小的数值线性增加到预设学习率,然后按照cos函数值进行衰减。其学习率系数如下图所示:
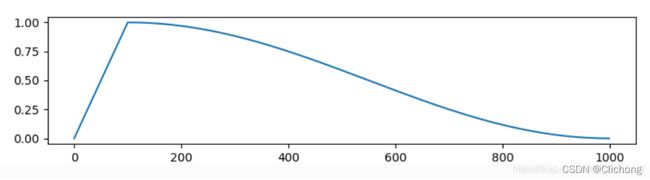
-
Gradual Warmup
constant warmup的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。
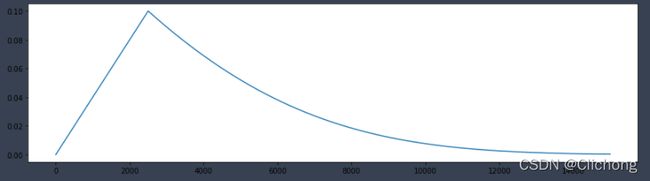
gradual warmup的实现模拟代码如下:
"""
Implements gradual warmup, if train_steps < warmup_steps, the
learning rate will be `train_steps/warmup_steps * init_lr`.
Args:
warmup_steps:warmup步长阈值,即train_steps
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
warmup_steps = 2500
init_lr = 0.1
# 模拟训练15000步
max_steps = 15000
learning_rate_lists = []
for train_steps in range(max_steps):
if warmup_steps and train_steps < warmup_steps:
warmup_percent_done = train_steps / warmup_steps
warmup_learning_rate = init_lr * warmup_percent_done #gradual warmup_lr
learning_rate = warmup_learning_rate
else:
# learning_rate = np.sin(learning_rate) #预热学习率结束后,学习率呈sin衰减
learning_rate = learning_rate**1.0001 #预热学习率结束后,学习率呈指数衰减(近似模拟指数衰减)
# if (train_steps+1) % 100 == 0:
# print("train_steps:%.3f--warmup_steps:%.3f--learning_rate:%.3f" % (
# train_steps+1,warmup_steps,learning_rate))
learning_rate_lists.append(learning_rate)
plt.figure(figsize=(15, 4))
plt.plot(range(max_steps), learning_rate_lists)
2. warmup实现代码
YOLOv3-SPP代码:
def warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor):
def f(x):
"""根据step数返回一个学习率倍率因子"""
if x >= warmup_iters: # 当迭代数大于给定的warmup_iters时,倍率因子为1
return 1
alpha = float(x) / warmup_iters
# 迭代过程中倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
# 训练一个epoch
def train_one_epoch(model, optimizer, data_loader, device, epoch,
print_freq, accumulate, img_size,
grid_min, grid_max, gs,
multi_scale=False, warmup=False, scaler=None):
...
lr_scheduler = None
if epoch == 0 and warmup is True: # 当训练第一轮(epoch=0)时,启用warmup训练方式,可理解为热身训练
warmup_factor = 1.0 / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
accumulate = 1
...
if ni % accumulate == 0 and lr_scheduler is not None: # 第一轮使用warmup训练方式
lr_scheduler.step()
# 训练过程
def train(hyp):
...
# optimizer
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=hyp["lr0"], momentum=hyp["momentum"],
weight_decay=hyp["weight_decay"], nesterov=True)
...
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp["lrf"]) + hyp["lrf"] # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
scheduler.last_epoch = start_epoch # 指定从哪个epoch开始
...
for epoch in range(start_epoch, epochs):
mloss, lr = train_util.train_one_epoch(model, optimizer, train_dataloader,
device, epoch,
accumulate=accumulate, # 迭代多少batch才训练完64张图片
img_size=imgsz_train, # 输入图像的大小
multi_scale=multi_scale,
grid_min=grid_min, # grid的最小尺寸
grid_max=grid_max, # grid的最大尺寸
gs=gs, # grid step: 32
print_freq=50, # 每训练多少个step打印一次信息
warmup=True,
scaler=scaler)
# update scheduler
scheduler.step()
ps:这里的学习率调度是呈余弦变换,这里我可视化了一下学习率曲线,其按epochs来进行变换,也就是横坐标表示epochs。
可视化代码如下所示:
# epochs: 30
# hyp["lrf"]: 0.01
# x:当前的epoch
lf = lambda x: ((1 + math.cos(x * math.pi / 30)) / 2) * (1 - 0.01) + 0.01
plt.figure(figsize=(15, 4))
max_steps = 100
# x = range(max_steps)
y = [lf(x) for x in range(max_steps)]
plt.plot(range(max_steps), y)
yolov3中的学习率变化曲线:

参考资料:
https://blog.csdn.net/qq_38253797/article/details/116451541