Pytorch中的学习率调整方法
在梯度下降更新参数的时,我们往往需要定义一个学习率来控制参数更新的步幅大小,常用的学习率有0.01、0.001以及0.0001等,学习率越大则参数更新越大。一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。因此我们常常需要动态的学习率。
⭐参考:https://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate
Pytorch中的学习率调整有两种方式:
- 手动调整optimizer中的lr参数
- 利用lr_scheduler()提供的几种衰减函数
Pytorch中的学习率调整方法
- 一. 手动调整optimizer中的lr参数
- 二. 利用lr_scheduler()提供的几种调整函数
-
- 2.1 LambdaLR(自定义函数)
- 2.2 StepLR(固定步长衰减)
- 2.3 MultiStepLR(多步长衰减)
- 2.4 ExponentialLR(指数衰减)
- 2.5 CosineAnnealingLR(余弦退火衰减)
- 2.6 ReduceLROnPlateau(动态衰减学习率)
- 2.7 其他
- 三. 注意
一. 手动调整optimizer中的lr参数
from torch.optim import SGD
import matplotlib.pyplot as plt
from torch.nn import Module, Sequential, Linear, CrossEntropyLoss
# 定义网络模型
class model(Module):
def __init__(self):
super(model, self).__init__()
self.fc = Sequential(
Linear(1,10)
)
def forward(self, input):
output = self.fc(input)
return output
# 初始化网络模型
Model = model()
# 定义损失函数
Loss = CrossEntropyLoss()
# 创建优化器
lr = 0.01
optimizer = SGD(Model.parameters(), lr=lr)
# 定义一个list保存学习率
lr_list = []
# 学习率更新频率
step = 5
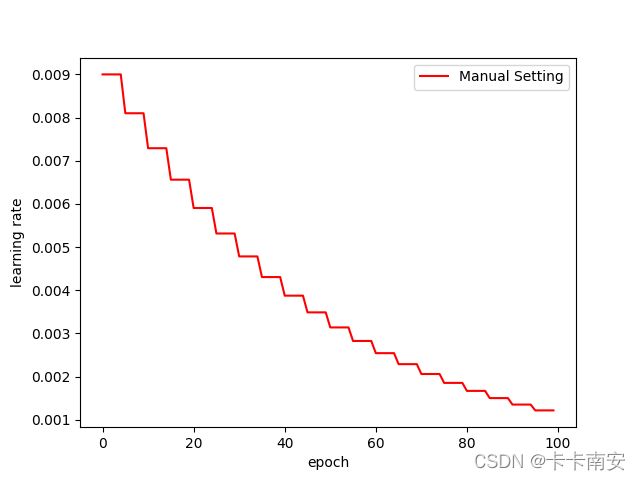
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
print("epoch from {} to {}, lr={}".format(epoch, epoch + 5, optimizer.state_dict()['param_groups'][0]['lr']))
p['lr'] *= 0.9
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r',label = 'Manual Setting')
plt.ylabel('learning rate')
plt.xlabel('epoch')
plt.legend()
plt.show()
输出:
epoch from 0 to 5, lr=0.01
epoch from 5 to 10, lr=0.009000000000000001
epoch from 10 to 15, lr=0.008100000000000001
epoch from 15 to 20, lr=0.007290000000000001
epoch from 20 to 25, lr=0.006561000000000002
epoch from 25 to 30, lr=0.005904900000000002
epoch from 30 to 35, lr=0.005314410000000002
···
二. 利用lr_scheduler()提供的几种调整函数
2.1 LambdaLR(自定义函数)
将学习率定义为与epoch相关的函数
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
- optimizer:封装好的优化器
- lr_lambda:会接收到一个int参数:epoch,然后根据epoch计算出对应的lr。如果设置多个lambda函数的话,会分别作用于Optimizer中的不同的params_group
- last_epoch:最后一个迭代epoch的索引,默认为-1
from torch.optim import SGD, lr_scheduler
import matplotlib.pyplot as plt
from torch.nn import Module, Sequential, Linear, CrossEntropyLoss
# 定义网络模型
class model(Module):
def __init__(self):
super(model, self).__init__()
self.fc = Sequential(
Linear(1,10)
)
def forward(self, input):
output = self.fc(input)
return output
# 初始化网络模型
Model = model()
# 定义损失函数
Loss = CrossEntropyLoss()
# 创建优化器
lr = 0.01
optimizer = SGD(Model.parameters(), lr=lr)
# 定义一个list保存学习率
lr_list = []
# 定义学习率与轮数关系的函数
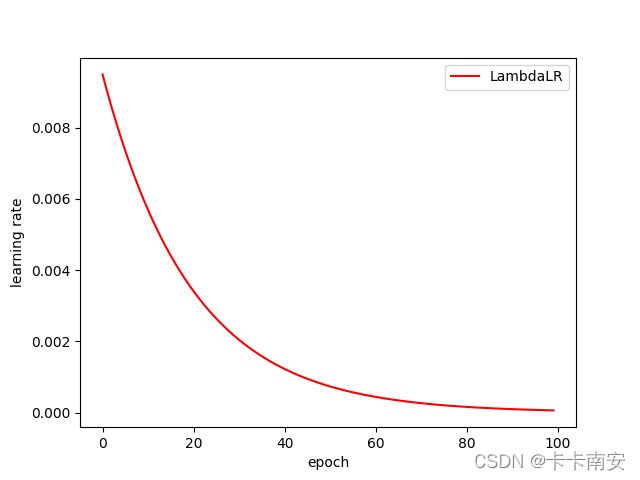
lambda1 = lambda epoch:0.95 ** epoch # 学习率 = 0.95**(轮数)
scheduler = lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1)
for epoch in range(100):
print("epoch={}, lr={}".format(epoch, optimizer.state_dict()['param_groups'][0]['lr']))
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r',label = 'LambdaLR')
plt.ylabel('learning rate')
plt.xlabel('epoch')
plt.legend()
plt.show()
输出:
epoch=0, lr=0.01
epoch=1, lr=0.0095
epoch=2, lr=0.009025
epoch=3, lr=0.00857375
epoch=4, lr=0.0081450625
epoch=5, lr=0.007737809374999998
epoch=6, lr=0.007350918906249998
···
2.2 StepLR(固定步长衰减)
每个step_size步长后使每个参数组的学习率乘上gamma
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
-
optimizer:封装的优化器
-
step_size: 学习率衰减的周期
-
gamma:学习率衰减的乘数因子,默认为0.1
-
last_epoch:最后一个迭代epoch的索引,默认为-1
# 其他代码与LambdaLR中相同
scheduler = lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8)
输出:
epoch=0, lr=0.01
epoch=1, lr=0.01
epoch=2, lr=0.01
epoch=3, lr=0.01
epoch=4, lr=0.01
epoch=5, lr=0.008
epoch=6, lr=0.008
epoch=7, lr=0.008
epoch=8, lr=0.008
epoch=9, lr=0.008
···

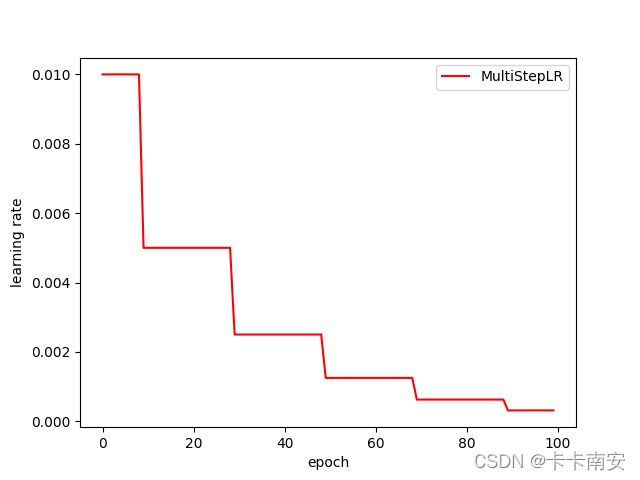
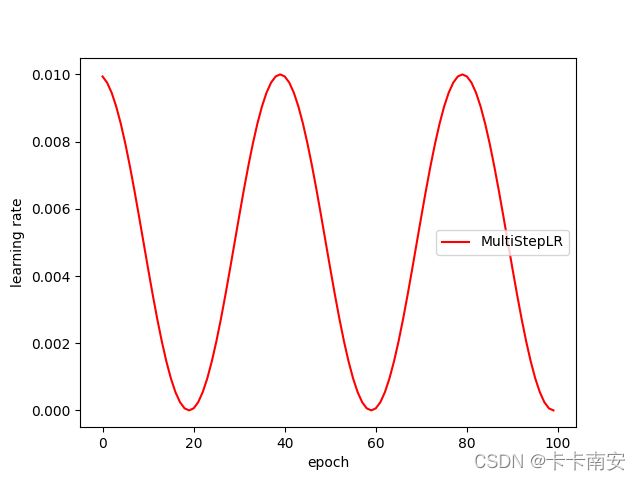
2.3 MultiStepLR(多步长衰减)
当迭代数epoch达到设定值时,每个参数组的学习率将被gamma衰减
这种衰减方式也是在学术论文中最常见的方式,一般手动调整也会采用这种方法
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
-
optimizer:封装的优化器
-
milestones: 迭代epochs指数列表. 列表中的值必须是增长的
-
gamma:学习率衰减的乘数因子,默认为0.1
-
last_epoch:最后一个迭代epoch的索引,默认为-1
# 其他代码与LambdaLR中相同
#在指定的epoch值,如[10,30,50,70,90]处对学习率进行衰减,lr = lr * gamma
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[10,30,50,70,90], gamma=0.5)
输出:
epoch=5, lr=0.01
epoch=6, lr=0.01
epoch=7, lr=0.01
epoch=8, lr=0.01
epoch=9, lr=0.01
epoch=10, lr=0.005
epoch=11, lr=0.005
epoch=12, lr=0.005
···
2.4 ExponentialLR(指数衰减)
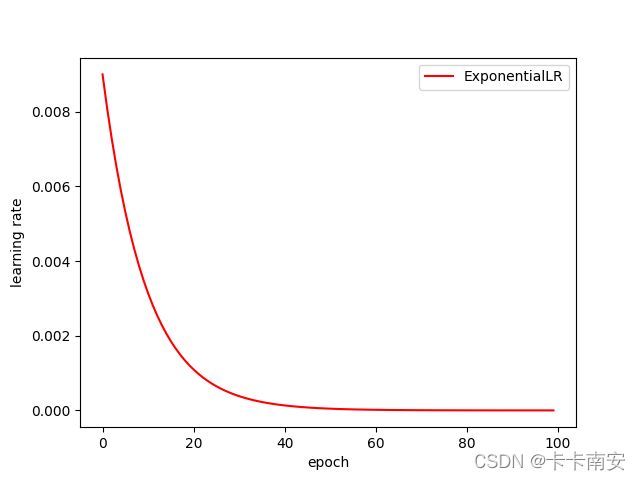
每个epoch中lr都乘以gamma
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
- optimizer:封装的优化器
- gamma :学习率衰减的乘数因子
- last_epoch:最后一个迭代epoch的索引,默认为-1
# 其他代码与LambdaLR中相同
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
输出:
epoch=0, lr=0.01
epoch=1, lr=0.009000000000000001
epoch=2, lr=0.008100000000000001
epoch=3, lr=0.007290000000000001
epoch=4, lr=0.006561000000000002
epoch=5, lr=0.005904900000000002
epoch=6, lr=0.005314410000000002
epoch=7, lr=0.004782969000000002
epoch=8, lr=0.004304672100000002
···
2.5 CosineAnnealingLR(余弦退火衰减)
使得学习率按照余弦函数周期变化
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
- optimizer:封装的优化器
- T_max:表示余弦函数周期
- eta_min:表示学习率的最小值,默认它是0表示学习率至少为正值。
- last_epoch:最后一个迭代epoch的索引,默认为-1
确定一个余弦函数需要知道最值和周期,其中周期就是T_max,最值是初始学习率。
# 其他代码与LambdaLR中相同
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max = 20)
输出:
epoch=0, lr=0.01
epoch=1, lr=0.009938441702975689
epoch=2, lr=0.009755282581475769
epoch=3, lr=0.00945503262094184
epoch=4, lr=0.009045084971874739
epoch=5, lr=0.008535533905932738
epoch=6, lr=0.007938926261462366
epoch=7, lr=0.007269952498697735
epoch=8, lr=0.006545084971874738
···
2.6 ReduceLROnPlateau(动态衰减学习率)
基于一些验证测量对学习率进行动态的下降当评价指标停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍中获益。这个调度器读取一个度量量,如果在“patience”迭代内没有看到改进,那么学习率就会降低。
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
-
optimizer (Optimizer):封装的优化器
-
mode (str):min, max两个模式中一个。在min模式下,当监测的数量停止下降时,lr会减少;在max模式下,当监视的数量停止增加时,它将减少。默认值:“分钟”。
-
factor (float):学习率衰减的乘数因子。new_lr = lr * factor. Default: 0.1.
-
patience (int):没有改善的迭代epoch数量,这之后学习率会降低。例如,如果patience = 2,那么我们将忽略前2个没有改善的epoch,如果loss仍然没有改善,那么我们只会在第3个epoch之后降低LR。Default:10。
-
verbose (bool):如果为真,则为每次更新打印一条消息到stdout. Default: False.
-
threshold (float):阈值,为衡量新的最优值,只关注显著变化. Default: 1e-4.
-
threshold_mode (str):rel, abs两个模式中一个. 在rel模式的“max”模式下的计算公式为dynamic_threshold = best * (1 + threshold),或在“min”模式下的公式为best * (1 - threshold)。在abs模式下的“max”模式下的计算公式为dynamic_threshold = best + threshold,在“min”模式下的公式为的best - threshold. Default: ‘rel’.
-
cooldown (int):触发一次条件后,等待一定epoch再进行检测,避免lr下降过速. Default: 0.
-
min_lr (float or list):标量或标量列表。所有参数组或每组的学习率的下界. Default: 0.
-
eps (float):作用于lr的最小衰减。如果新旧lr之间的差异小于eps,则忽略更新. Default: 1e-8.
import torch
import torchvision.models as models
from matplotlib import pyplot as plt
from torch import optim
import torch.nn as nn
from torch.optim import lr_scheduler
model = models.resnet34(pretrained=True)
fc_features = model.fc.in_features
model.fc = nn.Linear(fc_features, 2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(params=model.parameters(), lr=10)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
inputs = torch.randn(4, 3, 224, 224)
labels = torch.LongTensor([1, 1, 0, 1])
plt.figure()
x = list(range(60))
y = []
for epoch in range(60):
optimizer.zero_grad()
outputs = model(inputs)
# print("outputs={}".format(outputs))
loss = criterion(outputs, labels)
print("loss={:.5f}".format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step(loss)
lr = optimizer.param_groups[0]['lr']
print("epoch={}, lr={}".format(epoch, lr))
y.append(lr)
plt.plot(x, y, label = 'ReduceLROnPlateau')
plt.ylabel('learning rate')
plt.xlabel('epoch')
plt.legend()
plt.show()
输出:
loss=0.71542
epoch=0, lr=10
loss=415.35962
epoch=1, lr=10
loss=7263.38672
epoch=2, lr=10
loss=63877.69922
epoch=3, lr=10
loss=360837.37500
epoch=4, lr=10
loss=14761432.00000
epoch=5, lr=10
loss=4842640.00000
epoch=6, lr=10
loss=16175000.00000
epoch=7, lr=10
loss=876163328.00000
epoch=8, lr=10
loss=7241715.00000
epoch=9, lr=10
loss=1750400.25000
epoch=10, lr=10
loss=11120.10156
epoch=11, lr=1.0
loss=12.41332
epoch=12, lr=1.0
···
第一个loss为0.71542,一直向后的patient=10的10个epoch中都没有loss小于它,所以根据mode=‘min’,lr = lr*factor=lr * 0.1,所以lr从10变为了1.0

2.7 其他
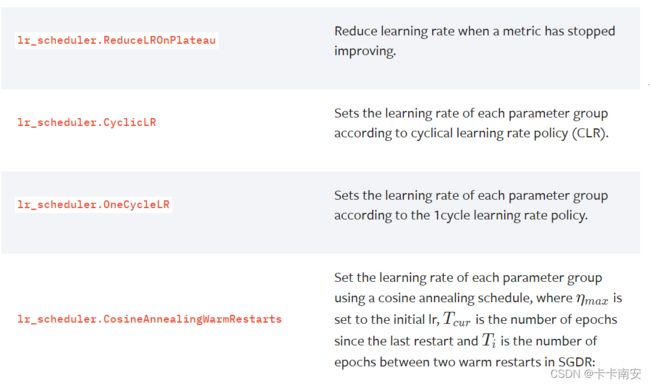
官网上还有很多其他学习率修改方法,需要用到的时候去上面找到对应的方法即可:
三. 注意
以上对学习率的更新都是在其step()函数被调用以后完成的,这个step表达的含义可以是一次迭代,当然更多情况下应该是一个epoch以后进行一次scheduler.step(),这根据具体问题来确定。此外,根据pytorch官网上给出的说明,scheduler.step()函数的调用应该在训练代码以后:
scheduler = ...
for epoch in range(100):
train(...)
validate(...)
scheduler.step()