深度学习入门 (三):神经网络的学习
- 本文为《深度学习入门 – 基于 Python 的理论与实现》的读书笔记
- 参考:知乎:Eureka 机器学习读书笔记、“西瓜书”、《统计学习方法》
目录
- 损失函数 (loss function)
-
- 为何要设定损失函数
- 均方误差 (mean squared error)
- 交叉熵误差 (cross entropy error)
- 常见的优化算法
-
- 梯度下降法 (gradient descent)
- 牛顿法 (Newton method)
-
- 求解方程
- 最优化
- 牛顿法和深度学习
- 拟牛顿法 (quasi-Newton method)
-
- DFP 算法 (Davidon-Fletcher-Powell Algorithm)
- BFGS 算法 (Broyden-Fletcher-Goldfard-Shano Algorithm)
- Broyden 类算法 (Broyden's Algorithm)
- mini-batch 学习
-
- mini-batch 学习
- 代码实现
- 学习算法的实现
-
- 数值微分
- 神经网络的梯度
- 学习算法的实现
损失函数 (loss function)
为何要设定损失函数
- 在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则识别精度对微小的参数变化基本上没有什么反应 (参数的导数在绝大多数地方都会变为 0),即便有反应,它的值也是不连续地、突然地变化
- 例如,假设某个神经网络正确识别出了100 笔训练数据中的 32 笔,此时识别精度为 32%。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在 32%,不会出现变化。也就是说,仅仅微调参数,是无法改善识别精度的。即便识别精度有所改善,它的值也不会像 32.0123 . . .% 这样连续变化,而是变为 33%、34% 这样的不连续的、离散的
- 而如果把损失函数作为指标,则当前损失函数的值可以表示为 0.92543 . . . 这样的值。并且,如果稍微改变一下参数的值,对应的损失函数也会发生连续性的变化
均方误差 (mean squared error)

- y k y_k yk 是表示神经网络的输出, t k t_k tk 表示监督数据 (one-hot 表示), k k k 表示数据的维数
交叉熵误差 (cross entropy error)
交叉熵
- 交叉熵刻画了两个概率分布之间的距离 (交叉熵越小, 两个概率分布越接近),它是分类问题中使用比较广的一种损失函数。给定两个概率分布 p p p 和 q q q, 通过 q q q 来表示 p p p 的交叉熵为:
H ( p , q ) = − ∑ x p ( x ) log q ( x ) H(p,q)=-\sum_xp(x)\log q(x) H(p,q)=−x∑p(x)logq(x)从交叉熵的公式中可以看到交叉熵函数不是对称的 ( H ( p , q ) ≠ H ( q , p ) H(p, q)\neq H(q,p) H(p,q)=H(q,p)),它刻画的是通过概率分布 q q q 来表达概率分布 p p p 的困难程度

- t k t_k tk 中只有正确解标签的索引为 1,其他均为 0(one-hot 表示)。因此,上式实际上只计算对应正确解标签的输出的自然对数,即 E = − log y i ( t i = 1 ) E = -\log y_i (t_i = 1) E=−logyi(ti=1)。该损失函数值尽量小时, y i y_i yi 在 ( 0 , 1 ) (0, 1) (0,1) 的范围内尽量大,即输出正确标签的概率尽量大
常见的优化算法
梯度下降法 (gradient descent)
- 梯度下降法是一种常用的一阶 (first-order) 优化方法,是求解无约束优化问题最简单、 最经典的方法之一;一阶方法仅使用目标函数的一阶导数,不利用其高阶导数,即使用梯度下降法寻找最优参数使得目标函数取尽可能小的值 (若目标函数为凸函数,则解为全局最优解)
梯度下降法
- 考虑无约束优化问题 min x ∈ R n f ( x ) \min_{\boldsymbol x\in\R^n}f(\boldsymbol x) minx∈Rnf(x), 其中 f ( x ) f(\boldsymbol x) f(x) 为连续可微函数. 若能构造一个序列 x 0 , x 1 , x 2 . . . \boldsymbol x^0,\boldsymbol x^1,\boldsymbol x^2... x0,x1,x2... 满足
 则不断执行该过程即可收敛到局部极小点
则不断执行该过程即可收敛到局部极小点 - 欲满足式 (B.15), 根据泰勒展式有
 于是,欲满足 f ( x + Δ x ) < f ( x ) f(\boldsymbol{x}+\Delta \boldsymbol{x})
于是,欲满足 f ( x + Δ x ) < f ( x ) f(\boldsymbol{x}+\Delta \boldsymbol{x})
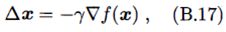 其中步长 γ ≥ 0 \gamma\geq0 γ≥0,在神经网络的学习中,称为学习率(learning rate)
其中步长 γ ≥ 0 \gamma\geq0 γ≥0,在神经网络的学习中,称为学习率(learning rate)
- 一般而言,这个值过大或过小,都无法抵达一个“好的位置”。过大会发散,过小学习速度慢
由于沿负梯度方向目标函数值下降最快,梯度下降法也成为最速下降法 (steepest descent)
全局最小与局部极小 (Global minimum vs. Local minimum)
- 梯度表示的是各点处的函数值减小最多的方向。因此,无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。实际上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处
- 例如,函数的极小值、最小值以及被称为鞍点 (saddle point) 的地方,梯度为 0。极小值是局部最小值。鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。虽然梯度法是要寻找梯度为 0 的地方,但是那个地方不一定就是最小值(也有可能是极小值或者鞍点)
- 梯度下降法的收敛速度也未必是很快的。例如,当函数很复杂且呈扁平状时,学习可能会进入一个(几乎)平坦的地区,陷入被称为“学习高原”的无法前进的停滞期

- 但当目标函数为凸函数时,局部极小点就对应着函数的全局最小点,此时梯度下降法可确保收敛到全局最优解
跳出局部最小点
- (1) 可以以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数 (这相当于从多个不同的初始点开始搜索,这样就可能陷入不同的局部极小,从中进行选择有可能获得更接近全局最小的结果)
- (2) 也可以使用 Mini-batch 梯度下降、SGD、Momentum、Adam 等加入随机特性的优化方法,这样即使陷入局部极小点,也有机会跳出局部极小继续搜索
- (3) 使用 “模拟退火" (simulated annealing) 技术: 模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于跳出 “局部极小”.在每步迭代过程中,接受 “次优解” 的概率要随着时间的推移而逐渐降低,从而保证算法稳定;但这也有可能造成 “跳出” 全局最小
除了梯度下降法,牛顿法和拟牛顿法也是求解无约束最优化问题的常用方法
牛顿法 (Newton method)
求解方程
- 并不是所有的方程都有求根公式,或者求根公式很复杂,导致求解困难。利用牛顿法,可以迭代求解
- 原理是利用泰勒公式,在 x 0 x_0 x0 处展开,且展开到一阶, 即 f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x)=f(x_0)+f'(x_0)(x-x_0) f(x)=f(x0)+f′(x0)(x−x0)。因此,求解方程 f ( x ) = 0 f(x)=0 f(x)=0 就等价于 f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) = 0 f(x_0)+f'(x_0)(x-x_0)=0 f(x0)+f′(x0)(x−x0)=0,求解 x = x 1 = x 0 − f ( x 0 ) / f ′ ( x 0 ) x=x_1=x_0-f(x_0)/f'(x_0) x=x1=x0−f(x0)/f′(x0)。因为这是利用泰勒公式的一阶展开, f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x)=f(x_0)+f'(x_0)(x-x_0) f(x)=f(x0)+f′(x0)(x−x0) 处并不是完全相等,而是近似相等,这里求得的 x 1 x_1 x1 并不能让 f ( x ) = 0 f(x)=0 f(x)=0,只能说 f ( x 1 ) f(x_1) f(x1) 的值比 f ( x 0 ) f(x_0) f(x0) 的值更接近于 0,于是迭代的想法就很自然了,可以进而推出 x n + 1 = x n − f ( x n ) / f ′ ( x n ) x_{n+1}=x_n-f(x_n)/f'(x_n) xn+1=xn−f(xn)/f′(xn)通过迭代,这个式子必然在 f ( x ∗ ) = 0 f(x^*)=0 f(x∗)=0 的时候收敛

- 原理是利用泰勒公式,在 x 0 x_0 x0 处展开,且展开到一阶, 即 f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x)=f(x_0)+f'(x_0)(x-x_0) f(x)=f(x0)+f′(x0)(x−x0)。因此,求解方程 f ( x ) = 0 f(x)=0 f(x)=0 就等价于 f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) = 0 f(x_0)+f'(x_0)(x-x_0)=0 f(x0)+f′(x0)(x−x0)=0,求解 x = x 1 = x 0 − f ( x 0 ) / f ′ ( x 0 ) x=x_1=x_0-f(x_0)/f'(x_0) x=x1=x0−f(x0)/f′(x0)。因为这是利用泰勒公式的一阶展开, f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x)=f(x_0)+f'(x_0)(x-x_0) f(x)=f(x0)+f′(x0)(x−x0) 处并不是完全相等,而是近似相等,这里求得的 x 1 x_1 x1 并不能让 f ( x ) = 0 f(x)=0 f(x)=0,只能说 f ( x 1 ) f(x_1) f(x1) 的值比 f ( x 0 ) f(x_0) f(x0) 的值更接近于 0,于是迭代的想法就很自然了,可以进而推出 x n + 1 = x n − f ( x n ) / f ′ ( x n ) x_{n+1}=x_n-f(x_n)/f'(x_n) xn+1=xn−f(xn)/f′(xn)通过迭代,这个式子必然在 f ( x ∗ ) = 0 f(x^*)=0 f(x∗)=0 的时候收敛
最优化
- 无约束最优化问题
min x ∈ R n f ( x ) \min _{x \in R^{n}} f(x) x∈Rnminf(x)
- 当目标函数 f ( x ) f(x) f(x) 二阶连续可微时,可采用牛顿法。牛顿法是典型的二阶方法,其迭代轮数远小于梯度下降法
- 设 f ( x ) f(x) f(x) 具有二阶连续偏导数,若第 k k k 次迭代值为 x ( k ) x^{(k)} x(k),则可将 f ( x ) f(x) f(x) 在 x ( k ) x^{(k)} x(k) 附近进行二阶泰勒展开
f ( x ) = f ( x ( k ) ) + g k T ( x − x ( k ) ) + 1 2 ( x − x ( k ) ) T H ( x ( k ) ) ( x − x ( x ) ) f(x)=f\left(x^{(k)}\right)+g_{k}^{T}\left(x-x^{(k)}\right)+\frac{1}{2}\left(x-x^{(k)}\right)^{T} H\left(x^{(k)}\right)\left(x-x^{(x)}\right) f(x)=f(x(k))+gkT(x−x(k))+21(x−x(k))TH(x(k))(x−x(x))其中, g k = g ( x ( k ) ) = ∇ f ( x ( k ) ) g_k=g\left(x^{(k)}\right)=\nabla f\left(x^{(k)}\right) gk=g(x(k))=∇f(x(k)) 是 f ( x ) f(x) f(x) 的梯度向量在点 x ( k ) x^{(k)} x(k) 的值, H ( x ( k ) ) H\left(x^{(k)}\right) H(x(k)) 是 f ( x ) f(x) f(x) 的海赛矩阵 (Hessian matrix) 在点 x ( k ) x^{(k)} x(k) 的值 H ( x ) = [ ∂ 2 f ∂ x i ∂ x j ] n × n H(x)=\left[\frac{\partial^{2} f}{\partial x_{i} \partial x_{j}}\right]_{n \times n} H(x)=[∂xi∂xj∂2f]n×n - f ( x ) f(x) f(x) 有极值的必要条件是在极值点处一阶导数为 0,即梯度向量为 0。特别的当 H ( x ( k ) ) H\left(x^{(k)}\right) H(x(k)) 是正定矩阵时,函数 f ( x ) f(x) f(x) 的极值为极小值; 我们为了得到一阶导数为 0 的点,下面用牛顿法求解方程。根据二阶泰勒展开,对 ∇ f ( x ) \nabla f\left(x\right) ∇f(x) 在 x ( k ) x^{(k)} x(k) 处展开得(也可以对上述泰勒公式再进行求导)
∇ f ( x ) = g k + H k ( x − x ( k ) ) \nabla f(x)=g_{k}+H_{k}\left(x-x^{(k)}\right) ∇f(x)=gk+Hk(x−x(k))其中, H k = H ( x ( k ) ) \quad H_{k}=H\left(x^{(k)}\right) Hk=H(x(k)), 则
g k + H k ( x ( k + 1 ) − x ( k ) ) = 0 x ( k + 1 ) = x ( k ) − H k − 1 g k \begin{aligned} &g_{k}+H_{k}\left(x^{(k+1)}-x^{(k)}\right)=0 \\ &x^{(k+1)}=x^{(k)}-H_{k}^{-1} g_{k} \end{aligned} gk+Hk(x(k+1)−x(k))=0x(k+1)=x(k)−Hk−1gk对于一元函数,上述迭代公式也可以写成:
x ( k + 1 ) = x ( k ) − f ′ ( x k ) f ′ ′ ( x k ) x^{(k+1)}=x^{(k)}-\frac{f^{\prime}\left(x_{k}\right)}{f^{\prime \prime}\left(x_{k}\right)} x(k+1)=x(k)−f′′(xk)f′(xk)

牛顿法和深度学习
参考:牛顿法和拟牛顿法
- 深度学习中,往往采用梯度下降法作为优化算子,而很少采用牛顿法,主要原因有以下几点:
- (1) 神经网络通常是非凸的,这种情况下,牛顿法的收敛性难以保证,可能被鞍点吸引
- (2) 即使是凸优化,只有在迭代点离全局最优很近时,牛顿法才会体现出收敛快的优势
拟牛顿法 (quasi-Newton method)
- 拟牛顿法的基本思想:在牛顿法的迭代中,需要计算海森矩阵的逆矩阵,这一计算比较复杂,考虑用一个 n n n 阶正定矩阵 G k = G ( x ( k ) ) G_k=G(x^{(k)}) Gk=G(x(k)) 来近似代替 H k − 1 = H − 1 ( x ( k ) ) H_k^{-1}=H^{-1}(x^{(k)}) Hk−1=H−1(x(k)) 或 H k = H ( x ( k ) ) H_k=H(x^{(k)}) Hk=H(x(k))
- 要找到近似的替代矩阵,必定要和 H k H_k Hk 有类似的性质。先看下牛顿法迭代中海森矩阵 H k H_k Hk 满足的条件
- 首先 H k H_k Hk 满足以下关系:取 x = x ( k − 1 ) x=x^{(k-1)} x=x(k−1), 由
∇ f ( x ) = g k + H k ( x − x ( k ) ) \nabla f(x)=g_{k}+H_{k}\left(x-x^{(k)}\right) ∇f(x)=gk+Hk(x−x(k))得
g k − 1 − g k = H k ( x ( k − 1 ) − x ( k ) ) g_{k-1}-g_{k}=H_{k}\left(x^{(k-1)}-x^{(k)}\right) gk−1−gk=Hk(x(k−1)−x(k))记 y k − 1 = g k − g k − 1 , δ k − 1 = x ( k ) − x ( k − 1 ) y_{k-1}=g_{k}-g_{k-1}, \quad \delta_{k-1}=x^{(k)}-x^{(k-1)} yk−1=gk−gk−1,δk−1=x(k)−x(k−1), 则得到拟牛顿条件:
y k − 1 = H k δ k − 1 H k − 1 y k − 1 = δ k − 1 \begin{aligned} &y_{k-1}=H_{k} \delta_{k-1} \\ &H_{k}^{-1} y_{k-1}=\delta_{k-1} \end{aligned} yk−1=Hkδk−1Hk−1yk−1=δk−1 - 其次,假如 H k H_k Hk 是正定的,则显然 H k − 1 H_k^{-1} Hk−1 也是正定的,那么就可以保证牛顿法的搜索方向 − H k − 1 g k -H_{k}^{-1} g_{k} −Hk−1gk 是下降方向,这是因为由 x ( k + 1 ) = x ( k ) − H k − 1 g k x^{(k+1)}=x^{(k)}-H_{k}^{-1} g_{k} x(k+1)=x(k)−Hk−1gk有 x = x ( k ) − λ H k − 1 g k = x ( k ) + λ p k x=x^{(k)}-\lambda H_{k}^{-1} g_{k}=x^{(k)}+\lambda p_{k} x=x(k)−λHk−1gk=x(k)+λpk
则 f ( x ) f(x) f(x) 在 x ( k ) x^{(k)} x(k) 的一阶泰勒展开可近似为 f ( x ) = f ( x ( k ) ) − λ g k T H k − 1 g k f(x)=f\left(x^{(k)}\right)-\lambda g_{k}^{T} H_{k}^{-1} g_{k} f(x)=f(x(k))−λgkTHk−1gk由于 H k − 1 H_{k}^{-1} Hk−1 正定, 故 g k T H k − 1 g k > 0 g_{k}^{T} H_{k}^{-1} g_{k}>0 gkTHk−1gk>0 。当 λ \lambda λ 为一个充分小的正数时, 有 f ( x ) < f ( x ( x ) ) f(x)
- 首先 H k H_k Hk 满足以下关系:取 x = x ( k − 1 ) x=x^{(k-1)} x=x(k−1), 由
- 综合上面两个特性,拟牛顿法将 G k G_{k} Gk 作为 H k − 1 H_{k}^{-1} Hk−1 近似。要求 G k G_{k} Gk 满足同样的条件。首先, 每次迭代矩阵 G k G_{k} Gk 是正定的。同时, G k G_{k} Gk 满足下面的拟牛顿条件:
G k + 1 y k = δ k G_{k+1} y_{k}=\delta_{k} Gk+1yk=δk按照拟牛顿条件,在每次迭代中可以选择更新矩阵 G k + 1 G_{k+1} Gk+1:
G k + 1 = G k + Δ G k G_{k+1}=G_k+\Delta G_k Gk+1=Gk+ΔGk这种选择有一定的灵活性,因此有很多具体的更新方法,下面进行介绍
DFP 算法 (Davidon-Fletcher-Powell Algorithm)
- DFP 算法假设每一步迭代中矩阵 G k + 1 G_{k+1} Gk+1 是由 G k G_k Gk 加上两个附加项构成,即
G k + 1 = G k + P k + Q k G_{k+1}=G_{k}+P_{k}+Q_{k} Gk+1=Gk+Pk+Qk其中, P k P_{k} Pk 与 Q k Q_{k} Qk 是待定矩阵。则
G k + 1 y k = G k y k + P k y k + Q k y k G_{k+1} y_{k}=G_{k} y_{k}+P_{k} y_{k}+Q_{k} y_{k} Gk+1yk=Gkyk+Pkyk+Qkyk为使 G k + 1 G_{k+1} Gk+1 满足拟牛顿条件, 可使 P k P_{k} Pk 与 Q k Q_{k} Qk 满足
P k y k = δ k Q k y k = − G k y k \begin{aligned} &P_{k} y_{k}=\delta_{k} \\ &Q_{k} y_{k}=-G_{k} y_{k} \end{aligned} Pkyk=δkQkyk=−Gkyk可取 P k = δ k δ k T δ k T y k Q k = − G k y k y k T G k y k T G k y k \begin{aligned} P_{k} &=\frac{\delta_{k} \delta_{k}^{T}}{\delta_{k}^{T} y_{k}} \\ Q_{k} &=-\frac{G_{k} y_{k} y_{k}^{T} G_{k}}{y_{k}^{T} G_{k} y_{k}} \end{aligned} PkQk=δkTykδkδkT=−ykTGkykGkykykTGk可得矩阵 G k + 1 G_{k+1} Gk+1 的迭代公式
G k + 1 = G k + δ k δ k T δ k T y k − G k y k y k T G k y k T G k y k G_{k+1}=G_{k}+\frac{\delta_{k} \delta_{k}^{T}}{\delta_{k}^{T} y_{k}}-\frac{G_{k} y_{k} y_{k}^{T} G_{k}}{y_{k}^{T} G_{k} y_{k}} Gk+1=Gk+δkTykδkδkT−ykTGkykGkykykTGk - 可以证明,如果初始矩阵 G 0 G_0 G0 是正定的,则迭代过程中的每个矩阵 G k G_k Gk 都是正定的; 一般取 G 0 = I G_0=I G0=I
BFGS 算法 (Broyden-Fletcher-Goldfard-Shano Algorithm)
- BFGS 算法是最流行的拟牛顿算法。它假设每一步迭代中矩阵 B k + 1 B_{k+1} Bk+1 是由 B k B_k Bk 加上两个附加项构成 (用 B k B_k Bk 逼近海塞矩阵 H k H_k Hk),即
B k + 1 = B k + P k + Q k B_{k+1}=B_{k}+P_{k}+Q_{k} Bk+1=Bk+Pk+Qk其中, P k P_{k} Pk 与 Q k Q_{k} Qk 是待定矩阵。则
B k + 1 δ k = B k δ k + P k δ k + Q k δ k B_{k+1} \delta_{k}=B_{k} \delta_{k}+P_{k} \delta_{k}+Q_{k} \delta_{k} Bk+1δk=Bkδk+Pkδk+Qkδk为使 B k + 1 B_{k+1} Bk+1 满足拟牛顿条件, 可使 P k P_{k} Pk 与 Q k Q_{k} Qk 满足
P k δ k = y k Q k δ k = − B k δ k \begin{aligned} &P_{k}\delta_{k}=y_{k} \\ &Q_{k} \delta_{k}=-B_{k}\delta_k \end{aligned} Pkδk=ykQkδk=−Bkδk可取 P k = y k y k T y k T δ k Q k = − B k δ k δ k T B k δ k T B k δ k \begin{aligned} P_{k} &=\frac{y_{k} y_{k}^{T}}{y_{k}^{T} \delta_{k}} \\ Q_{k} &=-\frac{B_{k} \delta_{k} \delta_{k}^{T} B_{k}}{\delta_{k}^{T} B_{k} \delta_{k}} \end{aligned} PkQk=ykTδkykykT=−δkTBkδkBkδkδkTBk可得矩阵 B k + 1 B_{k+1} Bk+1 的迭代公式
B k + 1 = B k + y k y k T y k T δ k − B k δ k δ k T B k δ k T B k δ k B_{k+1}=B_{k}+\frac{y_{k} y_{k}^{T}}{y_{k}^{T} \delta_{k}} -\frac{B_{k} \delta_{k} \delta_{k}^{T} B_{k}}{\delta_{k}^{T} B_{k} \delta_{k}} Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBk - 可以证明,如果初始矩阵 B 0 B_0 B0 是正定的,则迭代过程中的每个矩阵 B k B_k Bk 都是正定的; 一般取 B 0 = I B_0=I B0=I
- 设
G k = B k − 1 , G k + 1 = B k + 1 − 1 G_{k}=B_{k}^{-1}, \quad G_{k+1}=B_{k+1}^{-1} Gk=Bk−1,Gk+1=Bk+1−1两次应用 Sherman-Morrison 公式, 得
G k + 1 = ( I − δ k y k T δ k T y k ) G k ( I − δ k y k T δ k T y k ) T + δ k δ k T δ k T y k G_{k+1}=\left(I-\frac{\delta_{k} y_{k}^{T}}{\delta_{k}^{T} y_{k}}\right) G_{k}\left(I-\frac{\delta_{k} y_{k}^{T}}{\delta_{k}^{T} y_{k}}\right)^{T}+\frac{\delta_{k} \delta_{k}^{T}}{\delta_{k}^{T} y_{k}} Gk+1=(I−δkTykδkykT)Gk(I−δkTykδkykT)T+δkTykδkδkT称为 BFGS 算法关于 G k G_{k} Gk 的迭代公式- 其中 Sherman-Morrison 公式: 假设 A A A 是 n n n 阶可逆矩阵, u , v u, v u,v 是 n n n 维向量, 且 A + u v T A+u v^{T} A+uvT 也是可逆矩阵, 则:
( A + u v T ) − 1 = A − 1 − A − 1 u v T A − 1 1 + v T A − 1 u \left(A+u v^{T}\right)^{-1}=A^{-1}-\frac{A^{-1} u v^{T} A^{-1}}{1+v^{T} A^{-1} u} (A+uvT)−1=A−1−1+vTA−1uA−1uvTA−1
- 其中 Sherman-Morrison 公式: 假设 A A A 是 n n n 阶可逆矩阵, u , v u, v u,v 是 n n n 维向量, 且 A + u v T A+u v^{T} A+uvT 也是可逆矩阵, 则:
Broyden 类算法 (Broyden’s Algorithm)
- 令由 DFP 算法 G k G_k Gk 的迭代公式得到的 G k + 1 G_{k+1} Gk+1 记作 G D F P G^{DFP} GDFP,由 BFGS 算法 G k G_k Gk 的迭代公式得到的 G k + 1 G_{k+1} Gk+1 记作 G B F G S G^{BFGS} GBFGS,由于 G D F P G^{DFP} GDFP 和 G B F G S G^{BFGS} GBFGS 均满足拟牛顿条件,则两者的线性组合
G k − 1 = α G D F P + ( 1 − α ) G B F G S G_{k-1}=\alpha G^{D F P}+(1-\alpha) G^{B F G S} Gk−1=αGDFP+(1−α)GBFGS也满足拟牛顿条件,而且是正定的。其中, 0 ≤ α ≤ 1 0\leq\alpha\leq 1 0≤α≤1。该类算法称为 Broyden 类算法
mini-batch 学习
mini-batch 学习
- 使用训练数据进行学习,严格来说,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象
- 例如,如果训练数据有 100 个的话,我们就要把这 100 个损失函数的总和作为学习的指标。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式子:

- 通过这样的平均化,可以获得和训练数据的数量无关的统一指标。比如,即便训练数据有 1000 个或 10000 个,也可以求得单个数据的平均损失函数
- 例如,如果训练数据有 100 个的话,我们就要把这 100 个损失函数的总和作为学习的指标。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式子:
- mini-batch 学习:
- 如果遇到大数据,数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为 mini-batch, 小批量),然后对每个 mini-batch 进行学习
- 比如,从 60000 个训练数据中随机选择 100 笔,再用这 100 笔数据进行学习
- 同时也注意到,梯度下降法得到的是局部最优解,因此如果想要得到全局最优解,就需要随机梯度下降法 (SGD, Mini-batch Gradient Descent, 及其变种 Momentum, Adam)
- 如果遇到大数据,数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为 mini-batch, 小批量),然后对每个 mini-batch 进行学习
Batch Gradient Descent vs. Mini-batch Gradient Descent vs. Stochastic Gradient Descent
- 计算所有训练数据的损失进行梯度下降称为 batch gradient descent,取全部训练集中的一部分计算损失进行梯度下降称为 mini-batch gradient descent
- 在进行 batch gradient descent 时,所有训练数据的损失 (loss) 一定是单调递减的
- 而进行 mini-batch gradient descent 时不能保证每一次更新后所有训练数据的损失都下降,但总体的趋势一定是下降的
- 还有更极端的是随机梯度下降法 (Stochastic Gradient Descent),即每次只用一个样本来梯度下降;它的迭代速度很快,但迭代方向变化很大,不能很快的收敛到局部最优解

代码实现
从训练数据中的随机抽取 mini-batch
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size) # 从训练数据中的随机抽取 mini-batch
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
mini-batch 版的损失函数:
# 均方误差
def mean_squared_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
# 转成 one-hot 标签
if t.size != y.size:
tmp = t
t = np.zeros_like(y)
t[np.arange(batch_size), tmp.astype('int64')] = 1
return 0.5 * np.sum((y - t)**2) / batch_size
# 交叉熵误差
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是 one-hot-vector 的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
学习算法的实现
梯度反向传播在之后的博客中介绍,目前先使用简单的数值微分
数值微分
# 中心差分
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)
def _numerical_gradient_1d(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
def numerical_gradient_2d(f, X):
if X.ndim == 1:
return _numerical_gradient_1d(f, X)
else:
grad = np.zeros_like(X)
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_1d(f, x)
return grad
# 支持任意维数
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
# np.nditer: numpy迭代器对象
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
it.iternext()
return grad
def numerical_gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
if __name__ == '__main__':
def function_2(x):
return x[0]**2 + x[1]**2
init_x = np.array([-3.0, 4.0])
lr = 0.1
step_num = 100
x = numerical_gradient_descent(function_2, init_x, lr=lr, step_num=step_num)
print(x)
代码输出:
[-6.11110793e-10 8.14814391e-10]
- 可以看出非常接近f取最小值时的参数 ( 0 , 0 ) (0, 0) (0,0)
神经网络的梯度
- 这里所说的梯度是指损失函数关于权重参数的梯度

- 下面以单层神经网络为例,求出权重参数的梯度
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t) # w 为伪参数,是为了与之前定义的numerical_gradient兼容
dW = numerical_gradient(f, net.W)
print(dW)
学习算法的实现
- (1) 选出 mini-batch
- (2) 计算梯度
- (3) 更新参数
- (4) 不断重复上述步骤
- 下面以一个二层神经网络在 mnist 数据集上训练为例进行代码实现; 下面的代码在进行学习的过程中,会定期地对训练数据和测试数据记录识别精度。这里,每经过一个 epoch,我们都会记录下训练数据和测试数据的识别精度; 代码同时通过
pickle模块进行参数的存储- epoch是一个单位。一个 epoch 表示学习中所有训练数据均被使用过一次时的更新次数。比如,对于 10000 笔训练数据,用大小为 100 笔数据的 mini-batch 进行学习时,重复随机梯度下降法 100 次,所有的训练数据就都被“看过”了。此时,100 次就是一个 epoch
import sys
file_path = __file__.replace('\\', '/')
dir_path = file_path[: file_path.rfind('/')] # 当前文件夹的路径
pardir_path = dir_path[: dir_path.rfind('/')]
sys.path.append(pardir_path) # 添加上上级目录到python模块搜索路径
import numpy as np
from func.gradient import numerical_gradient
from func.activation import sigmoid, softmax, cross_entropy_error, sigmoid_grad
import matplotlib.pyplot as plt
class TwoLayerNet:
"""
2 Fully Connected layers
softmax with cross entropy error
"""
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['w1'] = np.random.randn(input_size, hidden_size) * weight_init_std
self.params['b1'] = np.zeros(hidden_size)
self.params['w2'] = np.random.randn(hidden_size, output_size) * weight_init_std
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
a1 = np.dot(x, self.params['w1']) + self.params['b1']
z1 = sigmoid(a1)
a2 = np.dot(z1, self.params['w2']) + self.params['b2']
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = y.argmax(axis=1)
t = t.argmax(axis=1)
accuracy = np.sum(y == t) / x.shape[0]
return accuracy
def numerical_gradient(self, x, t):
loss = lambda w: self.loss(x, t)
grads = {}
grads['w1'] = numerical_gradient(loss, self.params['w1'])
grads['b1'] = numerical_gradient(loss, self.params['b1'])
grads['w2'] = numerical_gradient(loss, self.params['w2'])
grads['b2'] = numerical_gradient(loss, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['w1'], self.params['w2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['w2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['w1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
if __name__ == '__main__':
from dataset.mnist import load_mnist
import pickle
import os
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=True)
# hyper parameters
lr = 0.1
batch_size = 100
iters_num = 10000
# setting
train_flag = 1 # 进行训练还是预测
pretrain_flag = 0 # 加载上一次训练的参数
pkl_file_name = dir_path + '/two_layer_net.pkl'
train_size = x_train.shape[0]
train_loss_list = []
train_acc_list = []
test_acc_list = []
best_acc = 0
iter_per_epoch = max(int(train_size / batch_size), 1)
net = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
if (pretrain_flag == 1 or train_flag == 0) and os.path.exists(pkl_file_name):
with open(pkl_file_name, 'rb') as f:
net.params = pickle.load(f)
print('params loaded!')
if train_flag == 1:
print('start training!')
for i in range(iters_num):
# 选出mini-batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
# grads_numerical = net.numerical_gradient(x_batch, t_batch)
grads = net.gradient(x_batch, t_batch)
# 更新参数
for key in ('w1', 'b1', 'w2', 'b2'):
net.params[key] -= lr * grads[key]
train_loss_list.append(net.loss(x_batch, t_batch))
# 记录学习过程
if i % iter_per_epoch == 0:
train_acc_list.append(net.accuracy(x_train, t_train))
test_acc_list.append(net.accuracy(x_test, t_test))
print("train acc, test acc | ", train_acc_list[-1], ", ", test_acc_list[-1])
if test_acc_list[-1] > best_acc:
best_acc = test_acc_list[-1]
with open(pkl_file_name, 'wb') as f:
pickle.dump(net.params, f)
print('net params saved!')
# 绘制图形
fig, axis = plt.subplots(1, 1)
x = np.arange(len(train_acc_list))
axis.plot(x, train_acc_list, 'r', label='train acc')
axis.plot(x, test_acc_list, 'g--', label='test acc')
markers = {'train': 'o', 'test': 's'}
axis.set_xlabel("epochs")
axis.set_ylabel("accuracy")
axis.set_ylim(0, 1.0)
axis.legend(loc='best')
plt.show()
else:
print(net.accuracy(x_train[:], t_train[:]))
- 因为数值微分速度实在是太慢了,所以先用误差反向传播来进行梯度下降 (该内容在下一篇讲),下面是运行一段时间后的代码输出,可以看到在测试集上精度不断上升,说明代码工作正常:
start training!
train acc, test acc | 0.09863333333333334 , 0.0958
net params saved!
train acc, test acc | 0.78535 , 0.7914
net params saved!
train acc, test acc | 0.8755833333333334 , 0.8829
net params saved!
train acc, test acc | 0.8984333333333333 , 0.902
net params saved!
train acc, test acc | 0.9081333333333333 , 0.9125
net params saved!
train acc, test acc | 0.9149166666666667 , 0.9181
net params saved!
train acc, test acc | 0.9202666666666667 , 0.9222
net params saved!
train acc, test acc | 0.9244 , 0.9271
net params saved!
train acc, test acc | 0.92815 , 0.9273
net params saved!
train acc, test acc | 0.9319166666666666 , 0.9323
net params saved!
train acc, test acc | 0.9342666666666667 , 0.9351
net params saved!
train acc, test acc | 0.9372833333333334 , 0.9365
net params saved!
train acc, test acc | 0.9393 , 0.9386
net params saved!
train acc, test acc | 0.9423333333333334 , 0.9404
net params saved!
train acc, test acc | 0.94355 , 0.9424
net params saved!
train acc, test acc | 0.9461166666666667 , 0.9437
net params saved!
train acc, test acc | 0.9478666666666666 , 0.9455
net params saved!
- 可以看出网络现在没有出现过拟合现象
