轻量级网络:MobileNet V2
MobileNet V1用一句话总结就是:MobileNet V1就是把VGG中的标准卷积层换成深度可分离卷积就可以了。其核心思想是采用 深度可分离卷积 操作。在相同的权值参数数量的情况下,相较标准卷积操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的。
首先利用3×3的深度可分离卷积提取特征,然后利用1×1的卷积来扩张通道。用这样的block堆叠起来的MobileNetV1既能较少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。
一、MobileNetV1的缺点
1、Depthwise深度卷积层训练出来的卷积核包含很多0
有人在实际使用的时候发现,深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的,如图:

这是为什么?作者认为这是ReLU激活函数的锅。
ReLU做了些啥?最后的结论就是:对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
2、Depthwise卷积的Kernel数取决于上一层的Depth,无法随意改变
Depthwise卷积的Kernel数(Filter数量)取决于上一层的Depth(输出通道数),无法随意改变。
MobileNetV2在Depthwise convolution之前添加一层Pointwise convolution,添加了这一层Pointwise convolution之后,Depthwise convolution的Filter数量取决于之前的Pointwise的通道数。而这个通道数是可以任意指定的,因此解除了3x3卷积核个数的限制。
二、MobileNetV2的核心思想
谷歌:MobileNetV2: Inverted Residuals and Linear Bottlenecks, CVPR 2018.
1、反向残差 Inverted Residuals
通道越少,卷积层的乘法计算量就越小。那么如果整个网络都是低维的通道,那么整体计算速度就会很快。然而,这样效果并不好,没有办法提取到整体的足够多的信息。所以,如果提取特征数据的话,我们可能更希望有高维的通道来做这个事情。MobileNetV2就设计这样一个结构来达到平衡。
MobileNetV2中首先扩展维度,然后用depthwise conv来提取特征,最后再压缩数据,让网络变小。
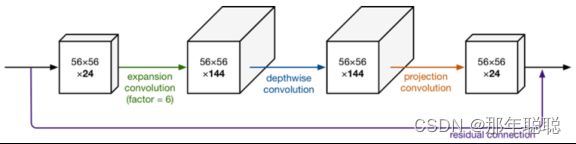
现在还有个问题是,深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征:

我们想像Resnet一样复用我们的特征,所以我们在特定的Block里加入了shortcut结构(残差连接),将输入与输出直接进行相加,这样可以使得网络在较深的时候依旧可以进行训练。这样MobileNetV2的block就是如下图形式:
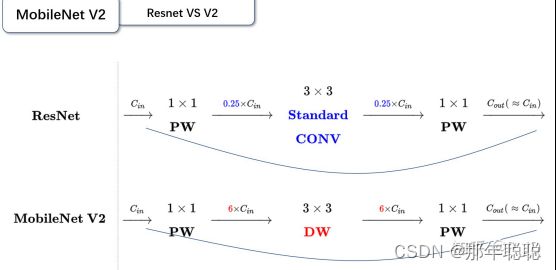
可以发现,都采用了 1×1 -> 3×3 -> 1×1 的模式,以及都使用Shortcut结构。但是不同点呢:
ResNet 先降维 (0.25倍)、卷积、再升维。
MobileNetV2 则是 先升维 (6倍)、卷积、再降维。
刚好V2的block刚好与Resnet的block相反,作者将其命名为Inverted residuals。就是论文名中的Inverted residuals。
2、特定层不使用非线性激活 Linear Bottlenecks
Mobilenetv2认为relu将信息从低纬度到高纬度不会存在信息丢失(反之会存在信息丢失),如下图,所以在expansion layer(1x1 conv进行channel升维)会保留relu6,但是在projection layer(1x1 conv进行channel降维)会取消relu6。

因此,使用Pointwise从低纬度到高纬度转换时仍然使用Relu激活函数,但是由于从高纬度到低纬度转换(V2中的最后一步降维操作)时,会存在信息丢失,所以使用Linear激活函数。
即,MobileNetV2与传统的Separable convolution不同的地方是,第一次Pointwise与Depthwise均使用了非线性激活函数ReLU6,但是第二次Pointwise则不采用非线性激活,保留线性特征。对此作者解释如下:
1. If the manifold of interest remains non-zero volume after ReLU transformation, it corresponds to a linear transformation.
2. ReLU is capable of preserving complete information about the input manifold, but only if the input manifold lies in a low-dimensional subspace of the input space.
三、MobileNet V1和V2的区别

四、MobileNet V2和 ResNet 的区别

五、代码实现
caffe 代码实现:https://github.com/shicai/MobileNet-Caffe
caffe 代码实现(efficent version1):https://github.com/farmingyard/caffe-mobilenet
caffe 代码实现(efficent version2):ttps://github.com/yonghenglh6/DepthwiseConvolution
参考链接:
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3 - 知乎
MobileNetV2 解读 - 高峰OUC - 博客园
https://yinguobing.com/bottlenecks-block-in-mobilenetv2/
MobileNetV1 & MobileNetV2 简介_Man-CSDN博客_mobilenet v1